A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization
Documentation availiable at https://madgrad.readthedocs.io/en/latest/.
pip install madgrad
Try it out! A best-of-both-worlds optimizer with the generalization performance of SGD and at least as fast convergence as that of Adam, often faster. A drop-in torch.optim implementation madgrad.MADGRAD is provided, as well as a FairSeq wrapped instance. For FairSeq, just import madgrad anywhere in your project files and use the --optimizer madgrad command line option, together with --weight-decay, --momentum, and optionally --madgrad_eps.
The madgrad.py file containing the optimizer can be directly dropped into any PyTorch project if you don't want to install via pip. If you are using fairseq, you need the acompanying fairseq_madgrad.py file as well.
- You may need to use a lower weight decay than you are accustomed to. Often 0.
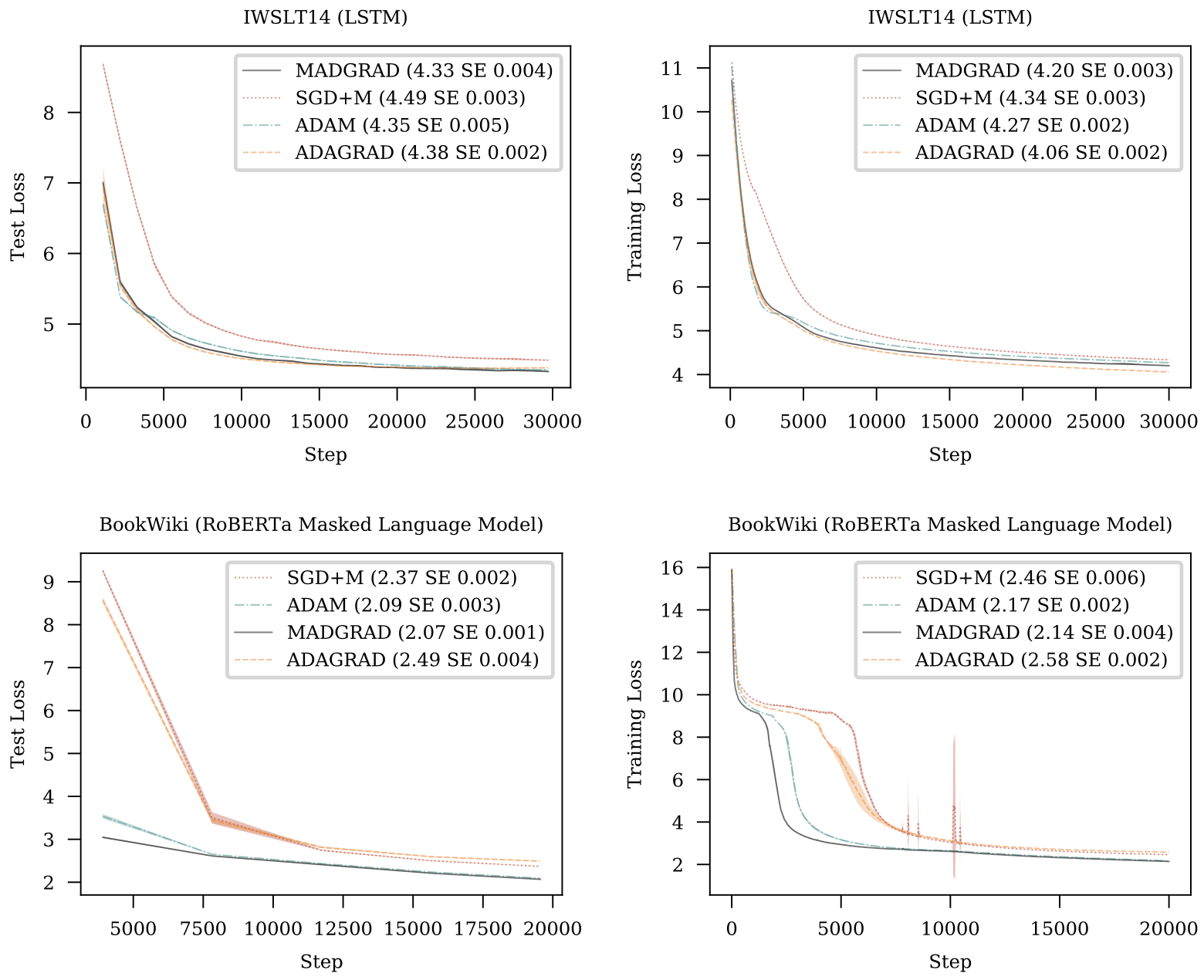
- You should do a full learning rate sweep as the optimal learning rate will be different from SGD or Adam. Best LR values we found were 2.5e-4 for 152 layer PreActResNet on CIFAR10, 0.001 for ResNet-50 on ImageNet, 0.025 for IWSLT14 using
transformer_iwslt_de_enand 0.005 for RoBERTa training on BookWiki usingBERT_BASE. On NLP models gradient clipping also helped.
The mirror descent version of MADGRAD is also included as madgrad.MirrorMADGRAD. This version works extremely well, even better than MADGRAD, on large-scale transformer training. This version is recommended for any problem where the datasets are big enough that generalization gap is not an issue.
As the mirror descent version does not implicitly regularize, you can usually use weight decay values that work well with other optimizers.
We introduce MADGRAD, a novel optimization method in the family of AdaGrad adaptive gradient methods. MADGRAD shows excellent performance on deep learning optimization problems from multiple fields, including classification and image-to-image tasks in vision, and recurrent and bidirectionally-masked models in natural language processing. For each of these tasks, MADGRAD matches or outperforms both SGD and ADAM in test set performance, even on problems for which adaptive methods normally perform poorly.
@misc{defazio2021adaptivity,
title={Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization},
author={Aaron Defazio and Samy Jelassi},
year={2021},
eprint={2101.11075},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
MADGRAD is licensed under the MIT License.