- Intro
- Part - 1 - Simple Neural Network
- Part - 2 - Backpropagation
- Part - 3 - Gradient Descent
- Part - 4 - Text Classifier
အခုနောက်ပိုင်း Machine Learning, Deep Learning, Artificial Neural Network (ANN), Convolutional Neural Network (CNN) စသဖြင့် AI ပိုင်းဆိုင်ရာ နည်းပညာများ ခေတ်စားလှသည်။ စာရေးသူအနေနှင့် ဤကဏ္ဍတွင် တစ်စိုက်မတ်မတ် လေ့လာနေသော ကွန်ပျူတာသိပ္ပံသမား မဟုတ်ခြင်းကြောင့် လည်ကောင်း၊ ခေတ်စားခါစ နည်းပညာများကို ချက်ခြင်း လေ့လာအသုံးချခြင်း မပြုပဲ တည်ငြိမ်ခိုင်မာမှုကို ရရှိလာသည့် အချိန်ထိ စောင့်လေ့ရှိသော အလေ့အထကြောင့် လည်ကောင်း ယခုအချိန်ထိ ထိုနည်းပညာများကို ကောင်းမွန်နှံ့စပ်စွာ သိရှိခြင်း မရှိသေးချေ။
အဘယ်ကြောင့် ခေတ်စားစ နည်းပညာသစ်များကို ချက်ခြင်း မလေ့လာသနည်းဟူမူ၊ ခေတ်စားစ အချို့သော နည်းပညာများသည် လူ့ဘောင် လောကကြီး တစ်ခုလုံး တစ်ခေတ်ဆန်း သွားစေလောက်အောင် ဆက်လက်ထွန်းပေါက် အောင်မြင်သွားကြသော်လည်း အချို့ကမူ နေ့မြင်၍ညပျောက် မနက်ဖြန် ဘယ်ရောက်သွားမှန်းမသိ ဖြစ်တတ်ကြပေသည်။ ထို့ကြောင့် ကိုယ်ရေးကိုယ်တာ များလှသည့်အပြင် အပျင်းထူလှသော စာရေးသူသည် ခေတ်စားတိုင်း မလေ့လာပဲ နေ့မြင်ညပျောက် မဟုတ်တာ သေချာပြီဆိုမှ စလေ့လာသည့် အလေ့အကျင့် ရှိပေသည်။
ယခုအခါတွင် ML/DL အစရှိသော AI နှင့် ဆက်စပ်နည်းပညာများသည် ခေတ်စားစ အဆင့်ကို ကျော်လွန်၍ တစ်ခေတ်ဆန်းစေသည့် အဆင့်ကို ရောက်ရှိလာကြလေပြီ။ ထို့ကြောင့် စတင်လေ့လာရန် သင့်ပြီဟုယူဆ၍ အနည်းငယ် စတင်လေ့လာကြည့်မိသည်။ ထို့သို့ လေ့လာကြည့်ရာတွင် "Hello World" အဆင့် အလွန်ရိုးရှင်း၍ အခြေခံကျလှသော Neural Network သုံး Machine Learning ပရိုဂရမ်ငယ်တစ်ခုကို Python အသုံးပြု ရေးသားပြထားသည့် နမူနာတစ်ခုအား လေ့လာမိလေသည်။
ထိုသို့လေ့လာမိရာတွင်.. စိတ်ကူးပေါက်ပေါက်နှင့် အဆိုပါ Python ပရိုဂရမ်ကို နမူနာယူ၍ မိမိ ရင်းနှီးကျွမ်းကျင်ရာ JavaScript ဖြင့် အလားတူ ပရိုဂရမ်ငယ်တစ်ခု စမ်းသပ်ရေးသား ကြည့်မိသည်။ ထိုသို့ ရေးသားထားသည့် ပရိုဂရမ်ကို စိတ်ဝင်စားသူများ လေ့လာစမ်းသပ်နိုင်ရန် ပြန်လည် မျှဝေလိုစိတ် ဖြစ်မိသည်။ ဤနေရာတွင် Machine Learning နှင့် Neural Network တို့အကြောင်း အကျယ် ချဲ့နိုင်မည် မဟုတ်ပေ။ ချဲ့နိုင်လောက်သည့် ဗဟုသုတ စာရေးသူကိုယ်တိုင်တွင် ပြည့်စုံခြင်း မရှိသေး။ ဤနေရာတွင် ရေးသားထားသည့် ပရိုဂရမ် အကြောင်းကိုသာ အနည်းငယ် ရှင်းပြလိုခြင်း ဖြစ်ပေသည်။
အောက်ပါ Array ကို လေ့လာကြည့်ပါ။
var inputs = [
[0, 0, 1], // -> 0
[1, 1, 1], // -> 1
[1, 0, 1], // -> 1
[0, 1, 1] // -> 0
];ဤ Array ကို Matrix တစ်ခုဟု ရှုမြင်သင့်သည်။ သို့မဟုတ် ရိုးရိုး Array တစ်ခုလိုသာ သဘောထားလိုကလည်း ထားနိုင်သည်။ ပထမ Row တွင် ပါဝင်သော 0, 0, 1 ၏ ရလဒ်သည် 0 ဖြစ်သည်။ ဒုတိယ 1, 1, 1 ၏ ရလဒ်သည် 1 ဖြစ်သည်။ 1, 0, 1 အတွက် ရလဒ် 1 ဖြစ်ပြီး 0, 1, 1 အတွက် ရလဒ် 0 ဖြစ်သည်။ သို့ဆိုလျှင် ဤစာရင်းထဲတွင် မပါဝင်သေးသော 1, 0, 0 (သို့) 0, 1, 0 ၏ရလဒ် မည်သို့ ဖြစ်မည်နည်း? ဤသည်ကို ရှာဖွေ အဖြေထုတ်ပေးနိုင်သော Neural Network သုံး ပရိုဂရမ်ငယ်တစ်ခုကို ရေးသားထားခြင်း ဖြစ်သည်။
ပထမဦးစွာ - အဖြေစာရင်းကို ဤသို့ ကြိုတင်ပြင်ဆင်ထားရှိသည်။
var test_result = [0, 1, 1, 0];ထိုကြောင့် ယခုအခါ နမူနာဒေတာဖြစ်သော inputs နှင့် ၄င်း၏အဖြေဖြစ်သော test_result တို့ကို ရရှိပေပြီ။ ဆက်လက်၍ Synaptic Weights ခေါ် စမှတ်တန်ဖိုးတစ်ခု လိုအပ်သည်။ မူသဘောအမှန်ကို နောက်မှလေ့လာပါ၊ ဤနေရာတွင်တော့ အဆိုပါ Weights ကို "အစမ်းအဖြေ" ဟု သဘောထားပါလေ။ inputs နှင့် weights ကို ဖော်မြူလာတစ်ခုတွင် ထည့်ကြည့်လိုက်လျှင် အဖြေထွက်လာမည်။ အဖြေက မှားချင်းလည်း မှားမည်။ မှန်ချင်လည်းမှန်မည်။ မှားသည့် weights များကို ပယ်၍ မှန်သည့် weights ကို ယူမည် ဖြစ်သည်။
var weights = [ rand(), rand(), rand() ];ဤအစမ်းအဖြေ weights စာရင်းသည် Random တန်ဖိုးများ ဖြစ်သဖြင့် ဤ weights များကို သုံး၍ တွက်ကြည့်လျှင် မှားမှာ သေချာပေသည်။ သို့သော် ကိစ္စမရှိ။ မှန်သည့် (သို့) အမှန်နှင့် နီးစပ်သည့် weights များဖြစ်လာအောင် လိုတိုးပိုလျှော့ လုပ်ကြည့်သွားမည် ဖြစ်သည်။ မှတ်ချက် - rand() သည် -1 နှင့် 1 ကြား Random ကိန်းကဏန်းတစ်ခုကို ထုတ်ပေးအောင် ကြိုတင်ရေးသားထားသော Function ဖြစ်သည်။ ဤနေရာတွင် ထို Function ကို ထည့်မဖော်ပြတော့ပါ။ rand() Function က -1 နှင့် 1 ကြား ကျပန်းကိန်းဂဏန်းကို ပြန်ပေးသည်ဟုသာ မှတ်ပါလေ။
function train(inputs, test_result, iterations) {
for(var i = 0; i < iterations; i++) {
var output = sigmoid( dot( inputs, weights ) );
var error = array_sub(test_result, output);
var adjustment = dot(
T(inputs),
array_multi(
error,
sigmoid_derivative(output)
)
);
weights = array_add(weights, adjustment);
}
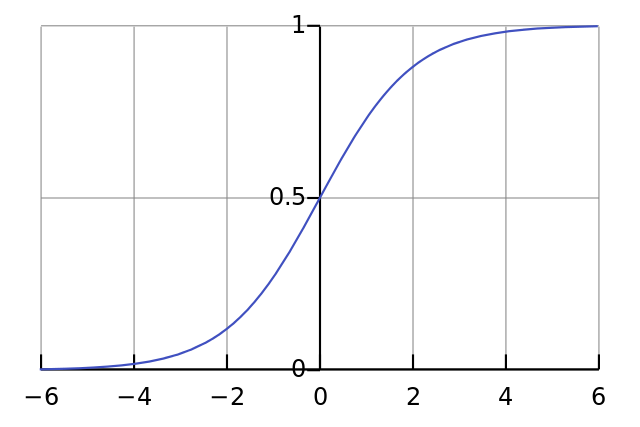
}ဖော်ပြထားသော train() Function သည်၊ နမူနာဒေတာဖြစ်သော inputs, အဖြေစာရင်းဖြစ်သော test_result နှင့် လေ့ကျင့်ရမည့် အကြိမ်ရေ iterations တို့ကို လက်ခံသည်။ ထို့နောက် iterations သတ်မှတ်ချက်အတိုင်း အကြိမ်ကြိမ် လေ့ကျင့်သည်။ ထိုသို့လေ့ကျင့်ရာတွင် သုံးသော sigmoid() Function သည် ပေးလိုက်သော တန်းဖိုးအား 1 နှင့် 0 ကြားတန်ဖိုးဖြစ်အောင် ပြောင်းပေးသော Function ဖြစ်သည်ဟု အလွယ်မှတ်ပါ။
ဥပမာ - sigmoid(5) ဟုဆိုလျှင် 0.9933071490757153 ကိုရရှိပေမည်။ 1 နှင့် 0 ကြား တန်ဖိုးတစ်ခုဖြစ်သည်။
dot() Function သည် Array Matrix နှစ်ခုကို မြှောက်ပေးနိုင်သော Matrix Multiplication လုပ်ငန်းကို ဆောင်ရွက်ပေးသည်။

ကျွန်ုပ်တို့ အထက်တန်းအဆင့် သင်္ချာတွင် သင်ခဲ့ကြဖူးသည်။ သို့သော်.. စာဖတ်သူတော့မသိ.. စာရေးသူတော့ မေ့နေလေပြီ။ လောလောဆယ် ပြန်မလေ့လာ လိုသေးလျှင်၊ ပထမ Array ဖြစ်သော inputs ၏ Row နှင့် ဒုတိယ Random Array ဖြစ်သော weights ၏ Column တို့ကို မြှောက်ပေးသည်ဟု အလွယ်မှတ်နိုင်သည်။
ဤသို့မြှောက်၍ရလာသော တန်ဖိုးကို sigmoid() အကူအညီဖြင့် 1 နှင့် 0 ကြားတန်ဖိုးဖြစ်အောင် ပြောင်းပြီး ရလာသော တန်ဖိုး မှန်မမှန် နောက်တစ်ဆင့်တွင် စစ်ဆေးထားခြင်း ဖြစ်သည်။ လိုရင်းမှာ.. မမှန်လျှင် weights တန်ဖိုးကို အတိုးအလျှော့ လုပ်၍ နောက်တစ်ကြိမ် စမ်းမည်။ အကြိမ်ကြိမ် စမ်းမည်။ မမှန်မချင်း စမ်းသွားမည်။ နောက်ဆုံးတွင် ကြိုပေးထားသည့် အဖြေမှန်နှင့် ကိုက်ညီသော (သို့) နီးစပ်သော weights ကိုရရှိမည် ဖြစ်ပေတော့သည်။
weights တန်းဖိုးကို လိုတိုးပိုလျှော့ ပြောင်းရာတွင် ဖြစ်နိုင်ခြေ ရှိသမျှ ရှိရှိသမျှ တန်ဖိုးအားလုံး တစ်ခုပြီးတစ်ခု လိုက်ပြောင်းခြင်း မဟုတ်ပေ။ Sigmoid Curve ခေါ် S ပုံသဏ္ဍာန် မျဉ်းကွေးထွက်အောင် တွက်၍ တန်ဖိုးအတိုး အလျော့သည် ထိုမျဉ်းကွေးဘောင်ထဲတွင် ဝင်နေအောင် ပြောင်းခြင်းဖြစ်သည်။ sigmoid_derivative() Function က weights အသစ်သည် S Curve ဘောင်ကို မကျော်အောင် ထိမ်းပေးသည့် Function ဖြစ်သည်။
ကျန် Function တစ်ခုဖြစ်သော T() သည် Array Matrix ၏ Row များကို Column ဖြစ်အောင် Transpose လုပ်ပေးသော Function ဖြစ်သည်။
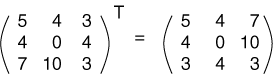
အသေးစိတ် သိရှိလိုပါက ဆက်လက် လေ့လာရပေမည်။ ဤနေရာတွင်တော့ မူလအစ Random weight ဖြင့်စ၍ နမူနာဒေတာအတွက် ကြိုပေးထားသော အဖြေမှန်နှင့် မနီးစပ်မချင်း ထို weights တန်ဖိုးကို ထပ်ခါထပ်ခါ လိုတိုးပိုလျှော့ ပြင်ကြည့်သည်ဟုသာ အလွယ်မှတ်နိုင်သည်။ နောက်ဆုံး ရရှိလာသော weights ကို အသုံးပြုခြင်းအားဖြင့် မူလဒေတာတွင် မပါဝင်သော အလားတူ ဒေတာများကို စီစစ်နိုင်ပေတော့မည်။ နမူနာဒေတာနှင့် weights ကို ဖော်မြူလာထဲ ထည့်လိုက်သောအခါ ကြိုတင်ပေးထားသော အဖြေမှန်နှင့် ကိုက်ညီ (သို့) နီးစပ်သကဲ့သို့ အသစ်ပေးလိုက်သော ဒေတာနှင့် ရရှိထားသော weights ကို ဖော်မြူလာထဲ ထည့်လိုက်လျှင်လည်း အဖြေမှန် (သို့) နီးစပ်သော အဖြေမှန်ကို ရရှိသွားသည့်သဘော ဖြစ်သည်။ ဖော်မြူလာမှာ အောက်ပါအတိုင်း ဖြစ်သည်။
function think(inputs) {
return sigmoid(dot(inputs, weights));
}ဟိုးအထက်တွင် ဖော်ပြခဲ့သော train() Function ကိုသုံး၍ weights ကို ရရှိပြီး ဖြစ်ပါက ဤ think() Function ကို သုံး၍ မူလဒေတာတွင် မပါဝင်သော အချက်အလက်များကို စမ်းသပ်လိုက စတင်စမ်းသပ် ကြည့်နိုင်ပြီဖြစ်သည်။ ဥပမာ -
console.log("Initial Weights: " + weights + "\n");
// Output Example => Initial Weights: -0.30,-0.73,0.37
train(inputs, test_result, 10000);
console.log("Trained Weights: " + weights + "\n");
// Output Example => Trained Weights: 9.67,-0.20,-4.62နမူနာအရ မူလ wights သည် Random ဖြစ်သော်လည်း အကြိမ် 10,000 Train ပြီးသော နောက်တွင် ရရှိလာသော weights ပြောင်းလဲသွားသည်ကို တွေ့ရပေမည်။ ဤကဲ့သို့ ရရှိလာသော weights ကို သုံး၍ ဒေတာသစ်များကို စမ်းသပ်ကြည့်နိုင်သည်။
console.log( think( [[1, 0, 0], [0, 1, 0]] ) );
// Output Example => [ 0.99, 0.44 ]နမူနာအရ 1, 0, 0 အတွက် အဖြေသည် 0.99 ဖြစ်၍ 0, 1, 0 အတွက် အဖြေကမူ 0.44 ဖြစ်နေသည်ကို တွေ့ရပေမည်။ အနီးဆုံးယူလိုက်လျှင် 1, 0, 0 အတွက် အဖြေ 1 ဖြစ်၍ 0, 1, 0 အတွက် အဖြေ 0 ဖြစ်သည်။ ယခုအခါ လေ့ကျင့်ပြီးဖြစ်သော weights ၏ အကူအညီဖြင့် မူလနမူနာ ဒေတာတွင် မပါသော ဒေတာသစ်များကိုပင် အဖြေမှန် ထုတ်ပေးနိုင်သော ပရိုဂရမ်ငယ်တစ်ခုကို ရရှိသွားပေတော့သည်။ အံ့ဖွယ် ကောင်းလေစွတကား...
- မူရင်း Python နမူနာကို ဤနေရာတွင် လေ့လာနိုင်သည်။
- ကျွန်ုပ်၏ JavaScript ကုဒ်အပြည့်အစုံကို ဤနေရာတွင် လေ့လာနိုင်သည်။
မူရင်း Python နမူနာတွင် သင်္ချာဆိုင်ရာ တွက်ချက်မှုများအတွက် Numpy ခေါ် library ကို အသုံးပြု၍ ဖော်ပြထားသဖြင့် စမ်းသပ် ကြည့်နိုင်ရန် Numpy လိုအပ်ပေလိမ့်မည်။ စာရေးသူ၏ JavaScript တွင်မူ ဤကဲ့သို့ Library မျိုးကို အသုံးမပြုပဲ Matrix Multiplication, Transpose စသည့် လိုအပ်သည့် လုပ်ဆောင်ချက်များကို ဆောင်ရွက်ပေးနိုင်သော Helper Function များကို တစ်ပါတည်း ထည့်သွင်း ရေးသားထားသဖြင့် တိုက်ရိုက်စမ်းနိုင်သည်။
လက်ရှိနမူနာဒေတာ inputs နှင့် ရလဒ် test_result တို့မှာ အောက်ပါအတိုင်းဖြစ်သည်။
var inputs = [
[0, 0, 1], // -> 0
[1, 1, 1], // -> 1
[1, 0, 1], // -> 1
[0, 1, 1] // -> 0
];သေချာလေ့လာကြည့်လိုက်ပါ။ Matrix ၏ ပထမ Column တန်ဖိုး 1 ဖြစ်လျှင် အဖြေ 1 ဖြစ်နေသည်။ ဤ Pattern ကို ကျွန်ုပ်တို့ ဦးနှောက်က အလွယ်တစ်ကူ တွေးဆတွေ့မြင်ရန် မခက်ခဲသကဲ့သို့ ပရိုဂရမ်အတွက်လည်း မခက်ခဲသည့်သဘော ဖြစ်သည်။ ထိုနမူနာဒေတာအတွက် ရလဒ်ကို ဤသို့ ပြင်ဆင်ကြည့်လိုက်မည်။
var inputs = [
[0, 0, 1], // -> 0
[1, 1, 1], // -> 0
[1, 0, 1], // -> 1
[0, 1, 1] // -> 1
];မူလကဲ့သို့ အဖြေက ပထမ Column ပေါ်သို့ တိုက်ရိုက်သက်ရောက်နေခြင်း မရှိတော့။ ကျွန်ုပ်တို့ ဦးနှောက်အတွက် တွေးဆကြည့်ရန် ခက်ခဲသွားသကဲ့သို့ ပရိုဂရမ်အတွက်လည်း အဖြေမှန် ထုတ်ပေးနိုင်ရန် ပိုမိုခက်ခဲသွားပေပြီ။ ယခုအတိုင်း ပြန်စမ်းကြည့်လျှင် ကျွန်ုပ်တို့၏ ပရိုဂရမ်က ပြန်ပေးသောအဖြေ မမှန်တော့သည်ကို တွေ့ရမည်ဖြစ်သည်။
ဒေတာနှင့် အဖြေ လုံးဝ သက်ဆိုင်ခြင်း မရှိသည်တော့ မဟုတ်။ နောက်တစ်ကြိမ် သေချာပြန်ကြည့်လျှင် တွေ့ရနိုင်ပေသည်။ ပထမ Column နှင့် ဒုတိယ Column တန်ဖိုးတို့ တူလျှင် အဖြေ 0 ဖြစ်၍ မတူလျှင် အဖြေ 1 ဖြစ်နေခြင်းဖြစ်သည်။ ဤ Pattern ကို ကျွန်ုပ်တို့ ဦးနှောက်က တွေးဆနိုင်သကဲ့သို့ ပရိုဂရမ်ကလည်း အဖြေမှန် ထုတ်ပေးနိုင်အောင် ပြင်ဆင်ကြည့်မည် ဖြစ်သည်။
မူလပရိုဂရမ်တွင် Neuron တစ်ခုနှင့် Layer တစ်ခုသာ ပါဝင်သည်။ လက်တွေ့တွင် Artificial Neural Network တစ်ခု၏ ဖွဲ့စည်းပုံမှာ အောက်ပါအတိုင်း ဖြစ်နိုင်သည်။

Neuron ပေါင်းများစွာပါဝင်၍ Layer အဆင့်ဆင့်ကို ဖြတ်သန်း စီစစ်ရသည့်သဘော ဖြစ်သည်။ အထက်တွင် ဆိုခဲ့ပြီးသကဲ့သို့ပင်၊ ဤနေရာတွင် ထိုသဘောသဘာဝများကို ရှင်းလင်း ဖော်ပြနိုင်မည် မဟုတ်ပေ။ ရေးသားထားသည့် ကုဒ်အကြောင်းကိုသာ စိတ်ဝင်စားသူများ ကုဒ်နှင့် ဤစာ နှိုင်းယှဉ်လေ့လာနိုင်စေရန် ရှင်းလင်း ဖော်ပြမည်ဖြစ်သည်။ Layer တစ်ခုသာ သုံးထားသော မူလနမူနာတွင် weights တစ်ခုသာ ပါဝင်သော်လည်း Layer နှစ်ခု အသုံးပြုမည့် ယခုနမူနာတွင် weights နှစ်ခု ပါဝင်ရမည်ဖြစ်သည်။
var weights_zero = nj.array( rand(3, 4) );
var weights_one = nj.array( rand(4, 1) );နမူနာဒေတာသည် Row (၄) ခုနှင့် Column (၃) ခုပါဝင်သော Array Matrix တစ်ခုဖြစ်သည်။ ထို ဒေတာ Matrix ကို စီစစ်နိုင်ရန် weights_zero အား Row (၃) ခုနှင့် Column (၄) ခုပါဝင်သော Random Array Matrix အဖြစ် သတ်မှတ်ထားသည်။ ပထမနမူနာ၏ Weight ကဲ့သို့ Flat Array မဟုတ်တော့ပဲ Array Matrix ဖြစ်သွားသည်။ ဤသဘောကို Hidden Layers ဟု ခေါ်သည်။ လက်တွေ့စမ်းသပ်ကြည့်ရာ၊ Hidden Layers များလျှင် အဖြေပိုတိကျလာသည်ကို တွေ့ရသည်။
weights_zero နှင့် inputs ဒေတာကို Matrix Multiplication နှင့် မြှောက်လိုက်သည့်အခါ Row (၄) ခုရှိ၍ Column (၁) ခုရှိသော ရလဒ်ကို ရရှိမည်ဖြစ်သည်။ ထိုရလဒ်နှင့် ဆက်လက်တွဲဖက် အလုပ်လုပ်ရန် weights_one ကို Row (၄) ခုနှင့် Column (၁) ခုရှိသော Random Array Matrix တစ်ခုအဖြစ် ဆက်လက်ကြေငြာ သတ်မှတ်ထားသည်ကို တွေ့နိုင်သည်။ အကယ်၍ weights_zero တွင် Hidden Layers များ ထပ်တိုးခဲ့ပါက weights_one ကိုလည်း လိုက်ဖက်အောင် တိုးပေရန် လိုအပ်ပေသည်။ ဥပမာ -
var weights_zero = nj.array( rand(3, 8) );
var weights_one = nj.array( rand(8, 1) );မှတ်ချက် - နမူနာကုဒ်တွင် တွေ့ရသော nj ဆိုသည်မှာ Numpy ကို နမူနာယူ ဖန်တီးထားသော NumJs ခေါ် JavaScript Library ဖြစ်သည်။ မူလနမူနာတွင် သင်္ချာဆိုင်ရာ တွက်ချက်မှုများအတွက် လိုအပ်သည့် Function များကို တစ်ပါတည်း ထည့်သွင်းရေးသားသော်လည်း၊ ဤ ဆက်လက်ဖော်ပြမည့် နမူနာတွင် ကိုယ်တိုင် မရေးတော့ပဲ NumJs ကို အသုံးပြုထားသည်။
function train(inputs, test_result, iterations) {
for(var i = 0; i < iterations; i++) {
var layer_zero = inputs;
var layer_one = nj.sigmoid( layer_zero.dot(weights_zero) );
var layer_two = nj.sigmoid( layer_one.dot(weights_one) );
var layer_two_error = test_result.subtract(layer_two);
// Backpropagation (sending back layer_two errors to layer_one)
var layer_two_delta = layer_two_error.multiply( curve(layer_two) );
var layer_one_error = layer_two_delta.dot( weights_one.T );
var layer_one_delta = layer_one_error.multiply( curve(layer_one) );
// Adjusting weights
weights_one = weights_one.add( layer_one.T.dot(layer_two_delta) );
weights_zero = weights_zero.add( layer_zero.T.dot(layer_one_delta) );
}
}train() Function တွင် မည်သည့် စီစစ်မှုမျှ မလုပ်ရသေးသည့် inputs ကို layer_zero ဟု သတ်မှတ်ထားသည်။ ထို့နောက်၊ ထို layer_zero ကို weights_zero နှင့် မြှောက်ချလိုက်သည်။ ရလဒ် Matrix ကို sigmoid() Function အကူအညီဖြင့် 0 နှင့် 1 ကြားတန်ဖိုးများသာ ပါဝင်သော Matrix ဖြစ်အောင် ပြောင်းသည်။ ထိုရလဒ် Matrix ကို layer_one ဟု သတ်မှတ်ထားသည်။ ဆက်လက်၍ layer_one ကို weights_one နှင့် မြှောက်ပြီး ရလဒ်ကို layer_two ဟု သတ်မှတ်သည်။
ထို့နောက်၊ layer_two အား test_result နှင့် နှိုင်းယှဉ်၍ (နှုတ်၍) စီစစ်သည်။ ရရှိလာသည့် error Matrix ကို S Curve ဘောင်မကျော်အောင် curve() Function ဖြင့် မြှောက်သည်။ ပြီးနောက် ထို layer_two ၏ error နှင့် weight_one ကို မြှောက်ခြင်းအားဖြင့် layer_one အတွက် error ကိုရရှိသည်။ ဤနည်းစနစ်ကို Backpropagation ဟု ခေါ်သည်။ လိုရင်းမှာ၊ Layer Two ၏ Error အား Layer One ထံ နောက်ပြန်ပေးပို့၍ အလုပ်လုပ်စေခြင်း ဖြစ်သည်။
မှတ်ချက် - substract(), add(), multiply() စသည့် Array Matrix များကို ပေါင်း နှုတ်မြှောက်စား လုပ်ပေးနိုင်သော Function များနှင့် sigmoid Function တို့ကို NumJs မှ ရယူ အသုံးပြုထားသည်။ curve() Function မှာမူ NumJs တွင် ပါဝင်ခြင်းမရှိ၍ သီးခြား Function တစ်ခုအဖြစ် ထည့်သွင်း ရေးသားထားသည်ကို ကုဒ်အပြည့်အစုံ လေ့လာရာတွင် သတိပြုပါ။
ထို့နောက် ပထမနမူနာကဲ့သို့ပင် ရရှိလာသော ရလဒ်ကို အသုံးပြု၍ Weights များကို ပြုပြင်ညှိနှိုင်း လိုက်သည်။ ဤနည်းဖြင့် အကြိမ်ကြိမ် စီစစ်လိုက် ညှိနှိုင်းလိုက်နှင့် နောက်ဆုံးတွင် အဖြေမှန်နှင့် အနီးစပ်ဆုံး ထုတ်ပေးနိုင်သော Weights များကို ရရှိမည်ဖြစ်သည်။ ရရှိလာသည့် Weight များကို သုံး၍ စမ်းသပ်နိုင်ရင် think() Function ကို အောက်ပါအတိုင်း ရေးသားထားသည်။
function think(inputs) {
var layer_one = nj.sigmoid( inputs.dot(weights_zero) );
var layer_two = nj.sigmoid( layer_one.dot(weights_one) );
return layer_two;
}မစမ်းသပ်မှီ train() Function ကို သုံး၍ Iteration အကြိမ်ရေ 60,000 ခန့်ဖြင့် Weight အမှန်များ ရအောင် လေ့ကျင့်ရပေမည်။
train(inputs, test_result, 60000);ထို့နောက် အောက်ပါအတိုင်း စမ်းသပ်ကြည့်နိုင်မည်ဖြစ်သည်။
var test_data = [
[1, 0, 0],
[1, 1, 0]
];
console.log( think( nj.array(test_data) ) );
// Output Example => array([[0.94562], [0.00223]])1, 0, 0 အတွက် အဖြေမှန် 1 (0.95) ဖြစ်၍ 1, 1, 0 အတွက် အဖြေမှန် 0 (0.002) ဖြစ်ကြောင်း မှန်ကန်စွာ စီစစ်နိုင်သည့် ပရိုဂရမ်တစ်ခုကို ရရှိသွားပြီ ဖြစ်ပေတော့သည်။
- အပိုင်း (၂) JavaScript ကုဒ်အပြည့်အစုံကို ဤနေရာတွင် လေ့လာနိုင်သည်။
- အပိုင်း (၂) အတွက် ကိုးကားဆောင်းပါးကို ဤနေရာတွင် လေ့လာနိုင်သည်။
- နမူနာတွင် အသုံးပြုထားသော NumJs ကို ဤနေရာတွင် လေ့လာနိုင်သည်။
လက်ရှိပရိုဂရမ်အား စွမ်းဆောင်ရည်ပိုမို ကောင်းမွန်စေရန် Optimize လုပ်၍ရနိုင်သည့် နည်းစနစ်အမျိုးမျိုး ရှိသေးသည်။ ၄င်းတို့ထဲမှ Gradient Descent နည်းစနစ်အား အသုံးပြု၍ ပို၍အမှားနည်းသော စနစ်တစ်ခု ဖြစ်လာစေရန် ပြင်ဆင်ဖြည့်စွက်မည်။
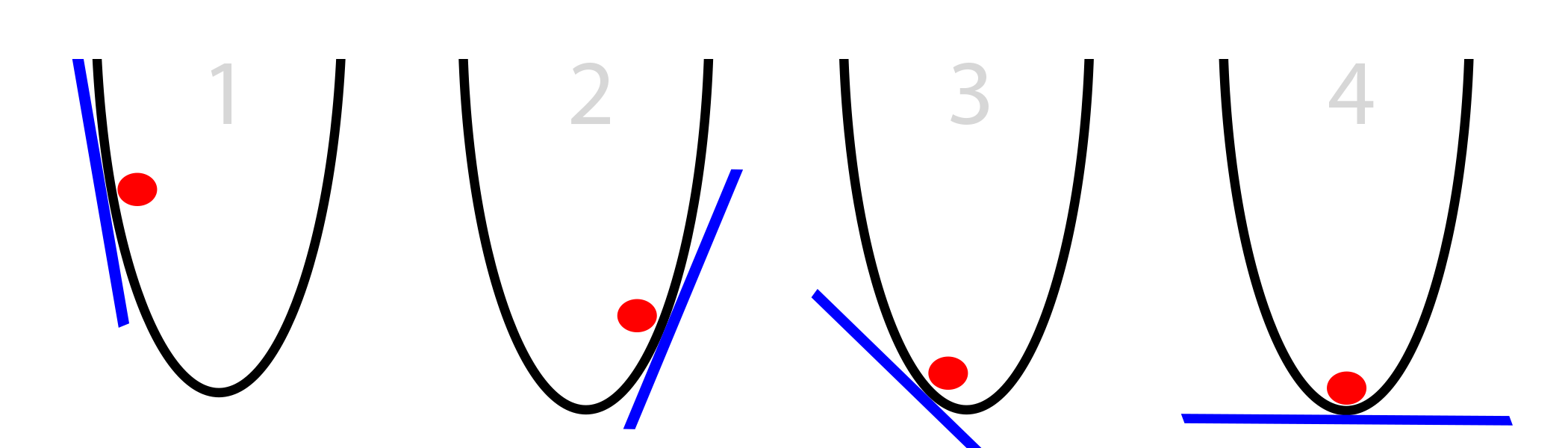
Gradient Descent သည် သီအိုရီသဘောအရ ကျယ်ပြန့်သော်လည်း လက်တွေ့ သဘောအနှစ်ချုပ်မှာ တန်ဖိုးကို အတိုးအလျှော့ ပြုလုပ်ကြည့်ခြင်းအားဖြင့် ပိုမိုကောင်းမွန်သည့် ရလဒ်ကို ရရှိစေခြင်းဖြစ်သည်။ Part - 2 တွင် ရေးသားခဲ့သည့် ကုဒ်ကိုပင် ဆက်လက် အသုံးပြုမည်ဖြစ်ပြီး ပထမဆုံးပြင်ဆင်ချက်မှာ alpha ခေါ် တန်ဖိုးတစ်ခု သတ်မှတ်လိုက်ခြင်းပင် ဖြစ်သည်။ Weights တန်ဖိုးများ ချိန်ညှိရာတွင် မူလကကဲ့သို့ Matrix Multiplication သက်သက် မဟုတ်တော့ပဲ alpha တန်ဖိုးကို ထည့်ကစားသွားရန် ရည်ရွယ်သည်။
var alpha = 10;လက်ရှိနမူနာအတွက် အကောင်းဆုံးရလဒ်ကိုပေးသည့် alpha တန်ဖိုးမှာ 10 ဖြစ်သည်ကို စမ်းသပ်သိရှိပြီးဖြစ်သည့်အတွက် အသုံးပြုထားခြင်းဖြစ်သည်။ လက်တွေ့တွင် alpha တန်ဖိုး အတိုးအလျှော့ ပြုလုပ်၍ အကောင်းဆုံးရလဒ် ရရှိစေသည့် တန်ဖိုးကို စမ်းသပ်ဖော်ထုတ်ရန် လိုအပ်ပေသည်။
ထို့နောက် Weights များ ချိန်ညှိမှုကို ယခုကဲ့သို့ ပြင်ဆင်လိုက်သည်။
weights_one = weights_one.add(
layer_one.T.dot(layer_two_delta).multiply(alpha)
);
weights_zero = weights_zero.add(
layer_zero.T.dot(layer_one_delta).multiply(alpha)
);မူလက Weights များချိန်ညှိရာတွင် လက်ရှိ Weights Matrix တွင် အသစ်ရရှိလာသည့် တန်ဖိုးများကို ပေါင်းထည့်ခြင်း ဖြစ်သော်။ ထိုတန်ဖိုးကိုပင် alpha နှင့် မြှောက်လိုက်ခြင်း ဖြစ်သည်။
စာရေးသူ၏ စမ်းသပ်မှုအရ မူလ Part 2 တွင် ဖော်ပြခဲ့သည့် ပရိုဂရမ်ဖြင့် လေ့ကျင့်ရာတွင် ရရှိသည့် error များမှာ အောက်ပါအတိုင်းဖြစ်သည်။
00000 - Error: 0.5000135194530013
10000 - Error: 0.010626371915259706
20000 - Error: 0.00726000807089573
30000 - Error: 0.005833823291177704
40000 - Error: 0.005001455307140716
50000 - Error: 0.004440934900653816
အနိမ့်ဆုံး Error မှာ 0.004 ဖြစ်သည်။ Gradient Descent နည်းစနစ်ဖြင့် ပြင်ဆင်၍ Optimize ပြုလုပ်ထားသည့် ဤပရိုဂရမ်သစ်ဖြင့် လေ့ကျင့်ရာတွင် ရရှိသည့် error များမှာ အောက်ပါအတိုင်းဖြစ်သည်။
00000 - Error: 0.49890257729692866
10000 - Error: 0.0028158347351834893
20000 - Error: 0.0017176682103336883
30000 - Error: 0.0013349032801991025
40000 - Error: 0.0011258896811994434
50000 - Error: 0.000989941835100877
အနိမ့်ဆုံး Error မှာ 0.0009 ဖြစ်၍ သိသိသာသာ ပို၍ အမှားနည်းသွားသည့် သဘောပင်ဖြစ်တော့သည်။
- အပိုင်း (၃) JavaScript ကုဒ်အပြည့်အစုံကို ဤနေရာတွင် လေ့လာနိုင်သည်။
- အပိုင်း (၃) အတွက် ကိုးကားဆောင်းပါးကို ဤနေရာတွင် လေ့လာနိုင်သည်။
ဤနေရာတွင်ဖော်ပြထား နည်းစနစ်တို့ကိုပင် အသုံးပြု၍ Text Classification ပရိုဂရမ်တစ်ခုကို ဖန်တီးတည်ဆောက်ထားသည်။ လေ့လာကြည့်ပါ။
ထိုပရိုဂရမ်တွင် နမူနာဒေတာကို (Sentence) များနှင့် နမူနာအဖြေ Class များကို အသံထွက်အလိုက် (Syllable) ပိုင်းဖြတ်၍ လိုအပ်သည့် Input/Output Matrix များဖြစ်အောင် တည်ဆောက်ပြီးနောက် Matrix Multiplication, Backpropagation, Gradient Descent စသည်တို့ကိုပင် အသုံးပြုထားသည်။
ပေးလာသည့် စာအကြောင်း (Sentence) သည် မည်သည့်စာအမျိုးအစား (Class) ဖြစ်သနည်း ခွဲခြားပေးနိုင်သော လက်တွေ့အသုံးချနိုင်သည့် စနစ်တစ်ခုဖြစ်သည်။
ကျေးဇူးတင်ပါသည်။