[TOC]
Spring Cloud Dataflow 是基于原生云对 Spring XD 的重新设计,该项目目标是简化大数据应用的开发。 Cloud- Dataflow 简化了专注于数据流处理的应用程序的开发和部署,它的体系结构包含的主要概念有:微服务应用程序、Data Flow Server 和运行时环境,Cloud Dataflow 为基于微服务的分布式流处理和批处理数据通道提供了一系列模型和最佳实践。
- Cloud Dataflow 是一个用于开发和执行大范围数据处理其模式包括ETL,批量运算和持续运算的统一编程模型和托管服务。
- 对于在现代运行环境中可组合的微服务程序来说,Spring Cloud Dataflow是一个原生云可编配的服务。使用Spring Cloud Dataflow,开发者可以为像数据抽取,实时分析,和数据导入/导出这种常见用例创建和编配数据通道 (data pipelines)。
- Spring XD 的流处理和批处理模块的重构分别是基于 Spring Cloud Stream 和 Spring Cloud Task/Batch 的微服务程序。这些程序现在都是自动部署单元而且他们原生的支持像 Cloud Foundry、Apache YARN、Apache Mesos和Kubernetes 等现代运行环境。
- Spring Cloud Dataflow 为基于微服务的分布式流处理和批处理数据通道提供了一系列模型和最佳实践。
wget https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v1.7.4.RELEASE/spring-cloud-dataflow-server-local/docker-compose.yml可以自定义docker-compose.yml配置文件内容:
- 使用RabbitMQ替换Apache Kafka作为消息中间件;
- 使用MySQL代替DataFlow默认的H2 database;
- 要使用redis作为后端启用实时数据流分析,则需要在docker-compose中添加redis的配置。
在Linux系统中启动docker-compose服务:
bash> DATAFLOW_VERSION=1.7.4.RELEASE docker-compose up -d在windows环境中启动docker-compose服务:
C:> set DATAFLOW_VERSION=1.7.4.RELEASE
C:> docker-compose up -d注意:有时由于docker的版本比较低,启动docker-compose是会提示version:'3'不支持,可以选择升级docker的版本 或者将 docker-compose.yml文件的首行的版本号调整为version:'2'
docker-compose服务启动之后,可以通过访问http://127.0.0.1:9393/dashboard进行Dataflow管理界面:
# 从maven镜像中心获取spring-cloud-dataflow-server-local-1.7.4.RELEASE.jar
bash> wget https://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-server-local/1.7.4.RELEASE/spring-cloud-dataflow-server-local-1.7.4.RELEASE.jar
# 从镜像中心获取spring-cloud-dataflow-shell-1.7.4.RELEASE.jar
bash> wget https://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-shell/1.7.4.RELEASE/spring-cloud-dataflow-shell-1.7.4.RELEASE.jar在本地运行spring-cloud-dataflow-server-local-1.7.4.RELEASE.jar,启动后访问http://127.0.0.1:9393/dashboard也可以进入到管理界面。在使用jar包进行启动时需要在本地环境需要启动MySQL、Kafka、Redis等服务。
bash> java -jar spring-cloud-dataflow-server-local-1.7.4.RELEASE.jar
虽然Cloud Dataflow提供了管理界面用于操作数据流,管理task任务,但有时并不是很高效。通过cloud-dataflow-shell可以完成图形化界面相同的工作,如register application,deploy stream,deploy task等等。可以在本地启动spring-cloud-dataflow-shell-1.7.4.RELEASE.jar完成与管理界面相同的工作。
bash> java -jar spring-cloud-dataflow-shell-1.7.4.RELEASE.jar如果cloud-dataflow-server和cloud-dataflow-shell没有在同一个host下,可以将shell指向数据服务器的url地址:
bash> dataflow config server `http://192.168.100.86`
bash> Successfully targeted `http://192.168.100.86`
dataflow:> 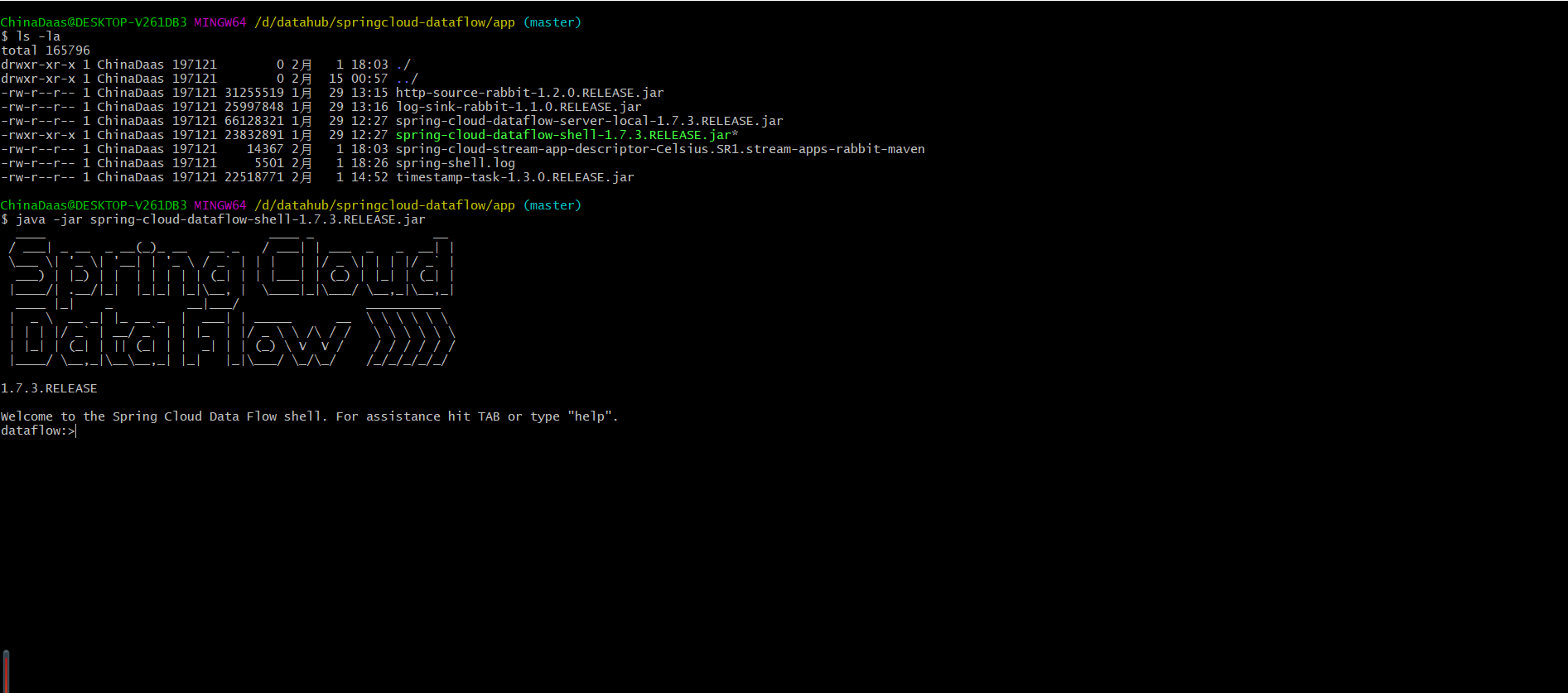
默认情况下应用不会自动注册,如果想要注册所有和kafka集成的开箱即用的流应用,可以使用如下命令注册应用:
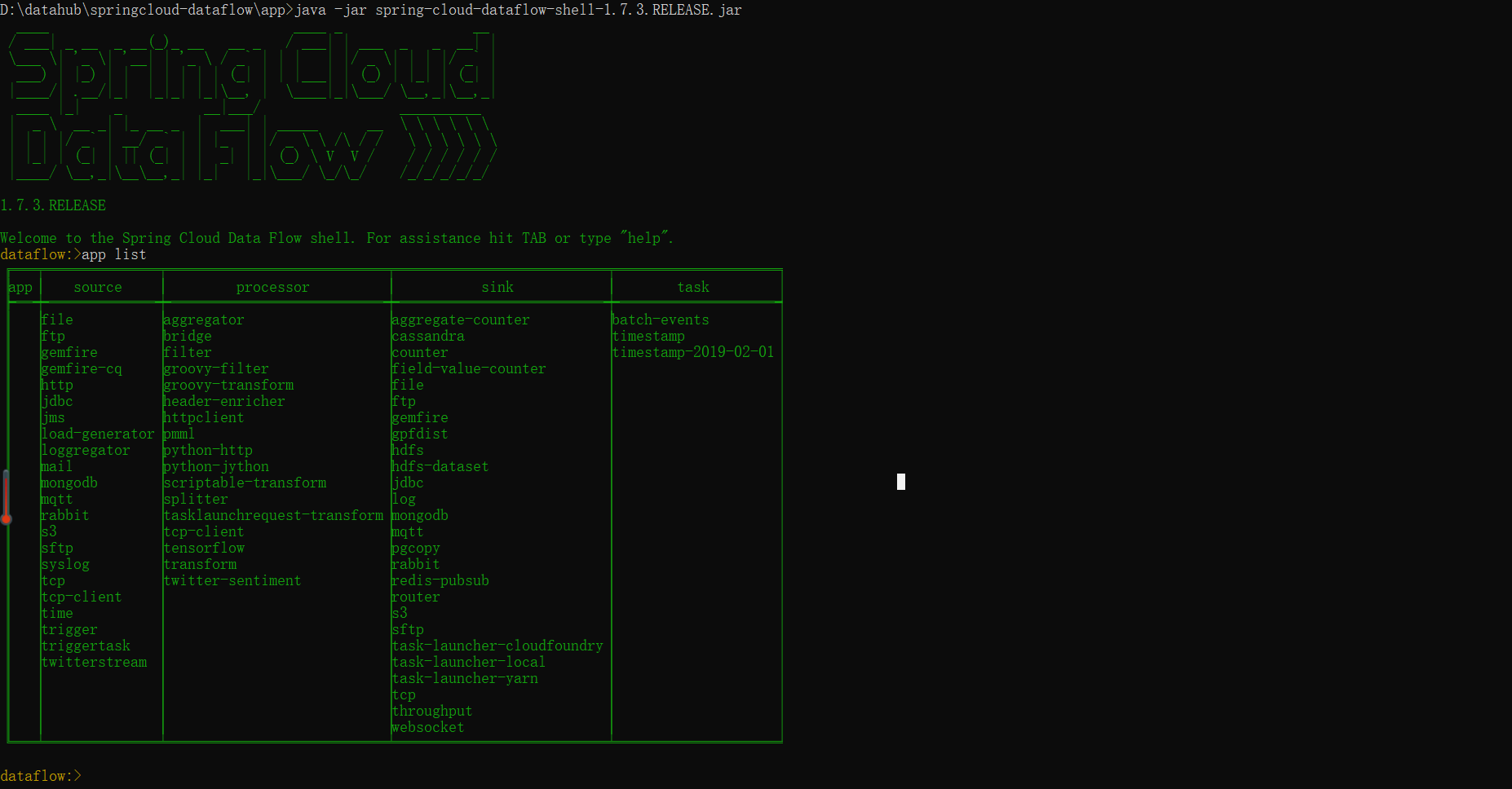
dataflow:> app import --uri `http://bit.ly/Bacon-RELEASE-stream-applications-kafka-10-maven`- app list: 查看当前
Dataflow注册的所有应用信息:
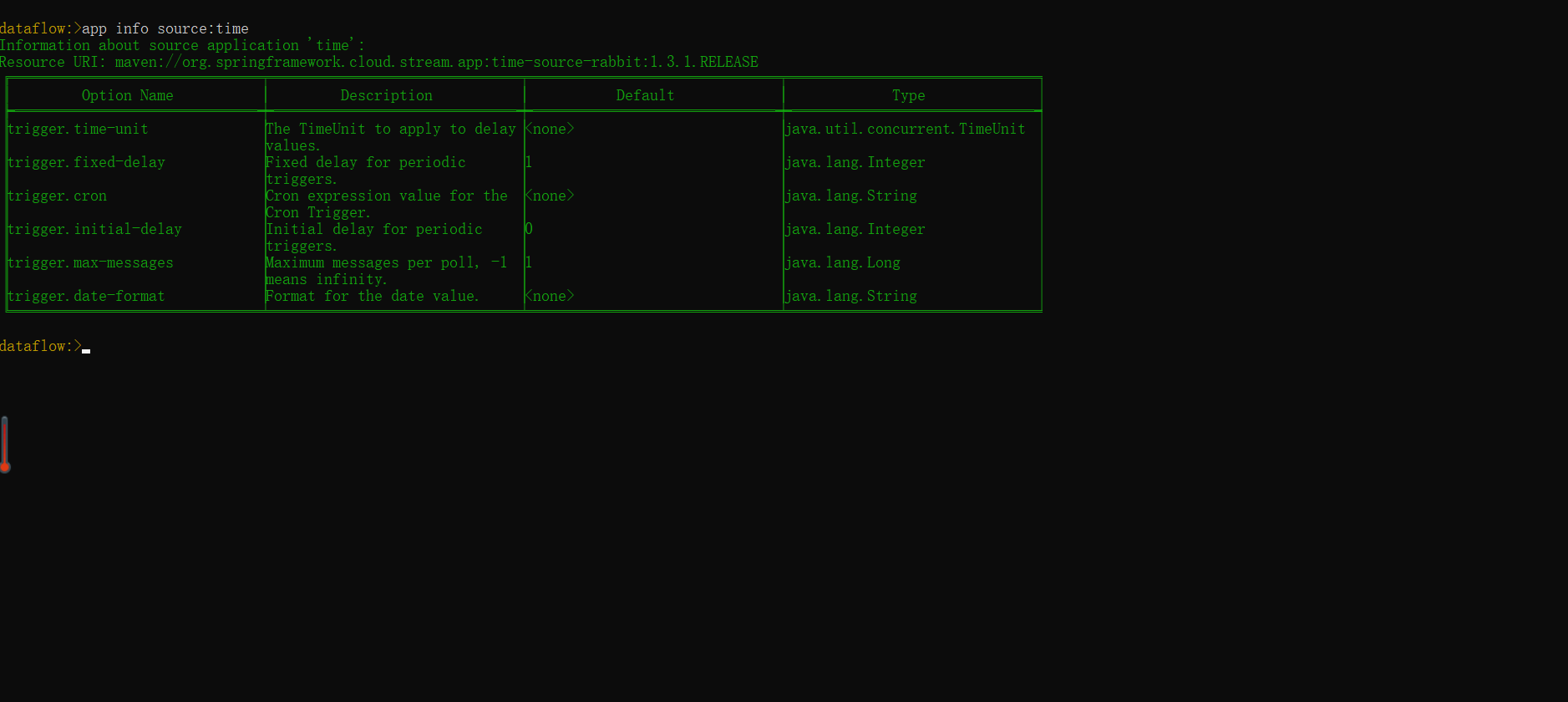
- app info: 查看
time应用的基本信息(app info source:time):
- __app register: __ 向
Dataflow中注册应用信息,Dataflow注册应用主要有两种方式:通过jar的路径注册、通过maven仓库地址注册应用信息:
# 通过指定app.jar的路径进行注册,在windows系统上不易使用
dataflow:>app register --type source --name my-app --uri file://root/apps/my-app.jar# 从maven镜像中心注册pose-estimation-processor-rabbit应用
#(若为本地应用 可以通过maven install 安装在本地仓库,之后再向dataflow中进行注册)
dataflow:>app register --type processor --name pose-estimation --uri maven://org.springframework.cloud.stream.app:pose-estimation-processor-rabbit:2.0.2.BUILD-SNAPSHOT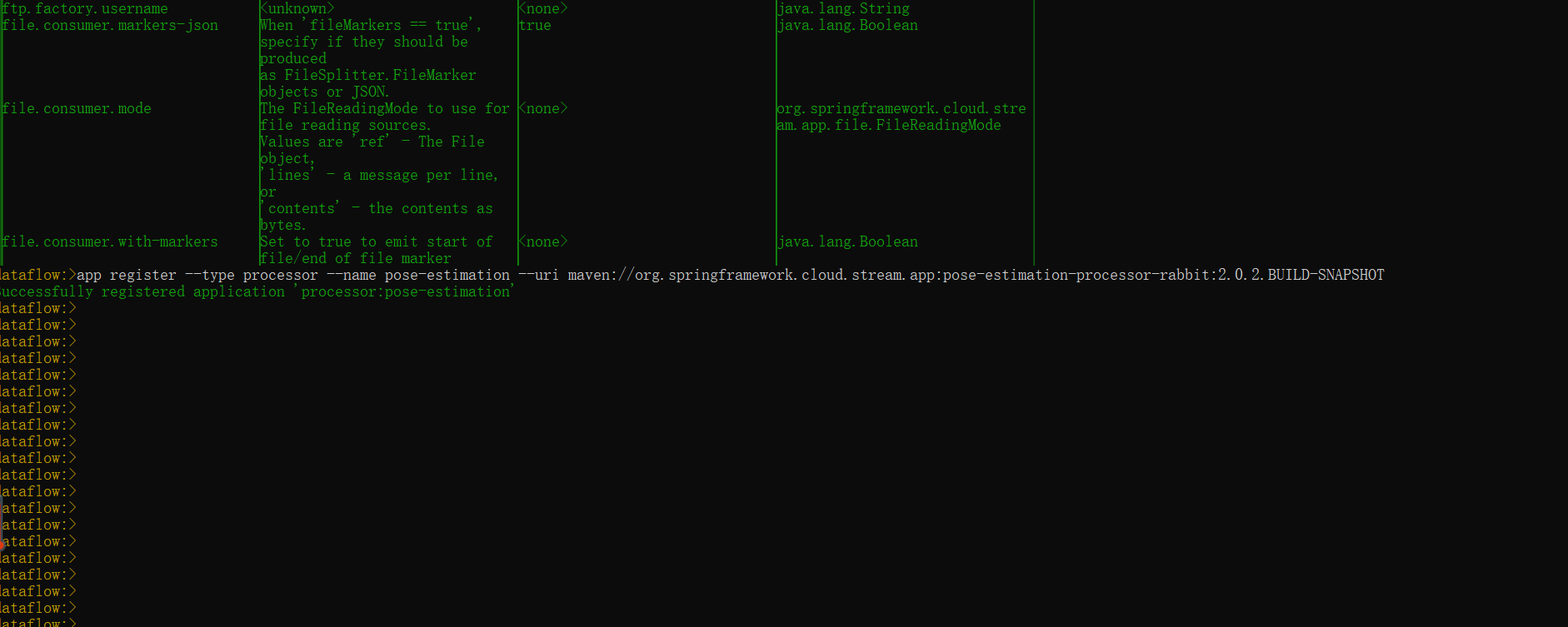
- __app unregister: __ 从
Cloud Dataflow中移除已经注册的应用app:
dataflow:> app unregister --type sink --name gemfire
dataflow:> Successfully unregistered application 'gemfire' with type 'sink'- help: 查看
Cloud Dataflow中所有指令的用法:
dataflow:> help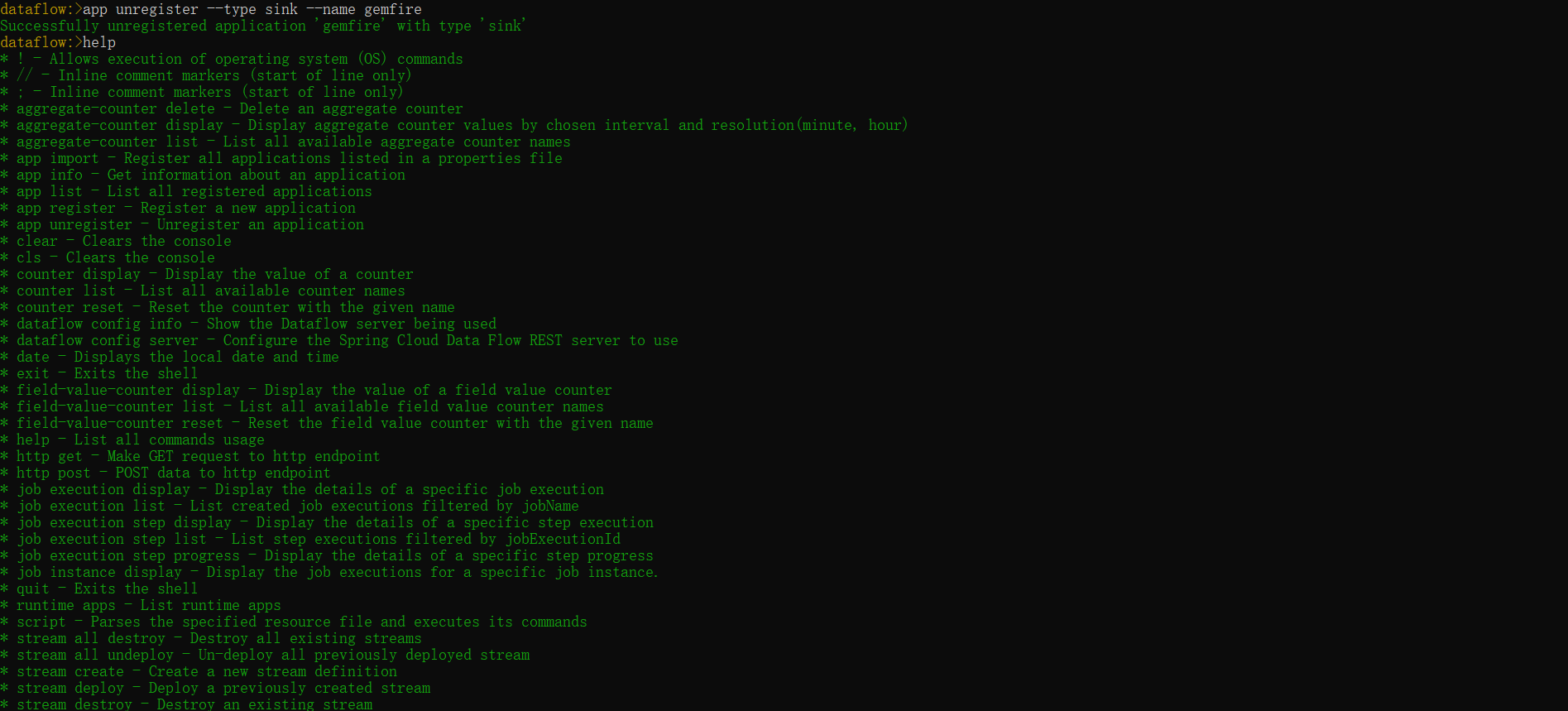
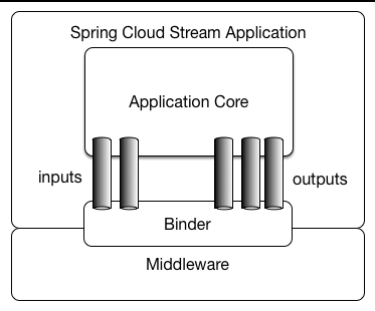
SpringCloud Stream介绍: Spring Cloud Stream是创建消息驱动微服务应用的框架,Spring Cloud Stream基于Spring Boot建立独立的生产级Spring应用程序,并使用Spring Integration提供与消息代理的连接,主要用于分布式系统中微服务组件之间通信。Spring Cloud Stream 目前提供了与RabbitMQ、Apache Kafka消息中间件的整合。
Spring Cloud Stream应用模型: Spring Cloud Stream由一个中立的中间件内核组成。Spring Cloud Stream会注入输入和输出的channels,应用程序通过这些channels与外界通信,而channels则是通过一个明确的中间件Binder与外部Brokers连接。
根据Spring Cloud Stream App Starters文档内容,下载log-sink-kafka-10-1.3.0.RELEASE.jar,time-source-kafka-10-1.3.0.RELEASE.jar(在运行环境需要启动Kafka);
# 启动time-source-kafka,在启动参数中指定消息输出消息的队列
bash> java -jar time-source-kafka-10-1.3.0.RELEASE.jar --spring.cloud.stream.bindings.output.destination=ticktock
# 启动log-sink-kafka,在启动参数中指定接收消息的队列
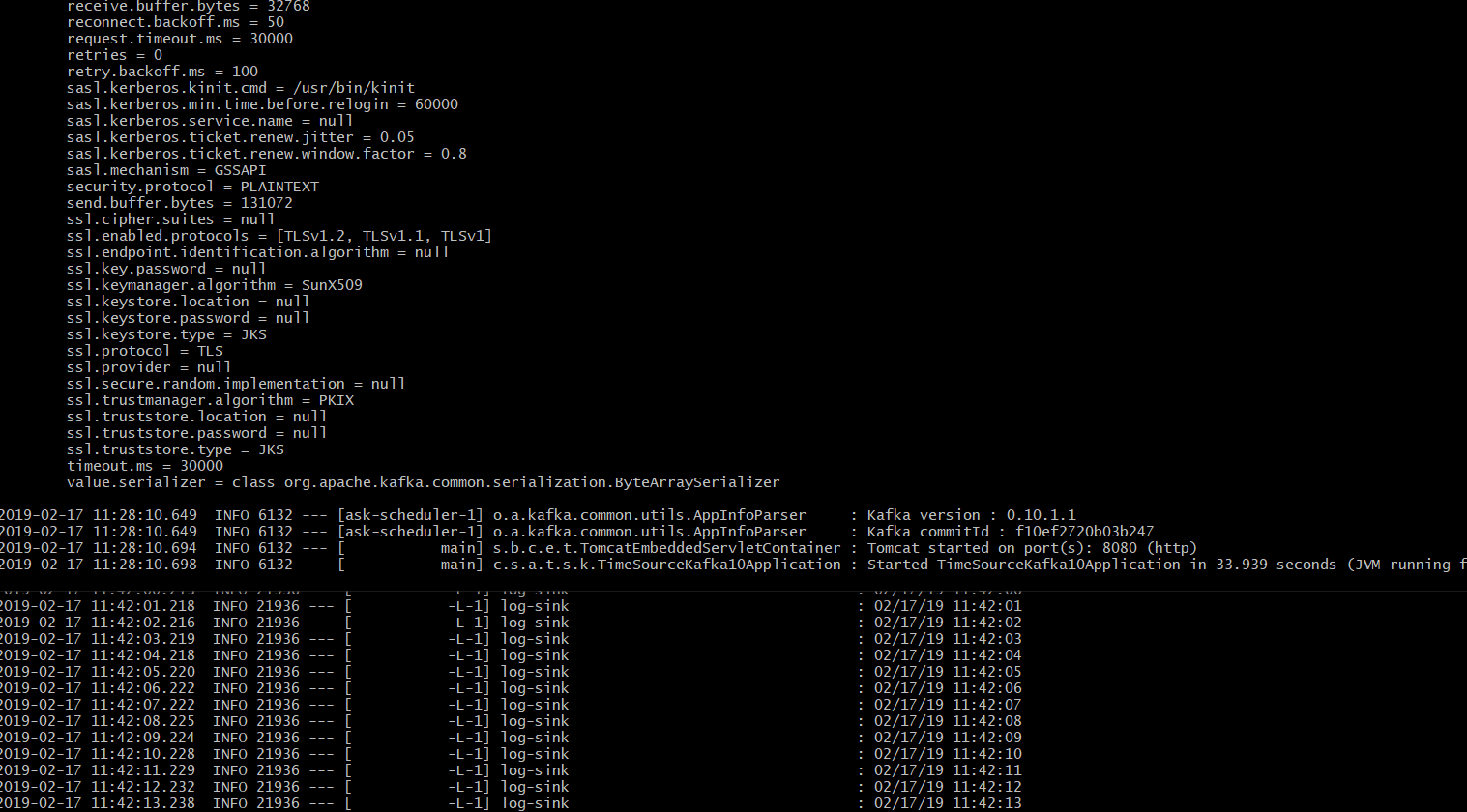
bash> java -jar log-sink-kafka-10-1.3.0.RELEASE.jar --spring.cloud.stream.bindings.input.destination=ticktock --server.port=8081启动应用后,可以观察到log-sink-kafka在控制台上一直在打印当前系统时间(消费Kafka消息队列中消息):
- source: 数据源主要用于向消息中间件中发送消息,需要指定消息的输出地址(指定
output.destination); - processor: 从消息中间件中消费消息,之后对消息进行中间处理,之后将消息发送到指定的输出队列(同时指定
input.destination和output.destination); - sink: 从消息中间件中指定消息队列中消费消息(指定
input.destination);
在Cloud Dataflow中可以对Spring Cloud Stream App进行自定义流式处理。使用Cloud Dataflow示例:对于source.http应用接收8787端口的请求,对数据进行简单处理后,将其发送到kafka消息队列,sink.jdbc从kafka中消费消息,并且将数据存放到Mariadb数据库中;
- 启动kafKa、zookeeper以及mariadb
# 启动spring-cloud-dataflow-server-local-1.7.4.RELEASE.jar
bash> java -jar spring-cloud-dataflow-server-local-1.7.4.RELEASE.jar
# 在Docker中启动Mariadb数据库
bash> docker run -p 3307:3306 --name mariadb -e MYSQL_ROOT_PASSWORD=root -d mariadb:10.2
# 启动spring-cloud-dataflow-shell工具
bash> java -jar spring-cloud-dataflow-shell-1.7.4.RELEASE.jar
# 启动本地zookeeper以及apache Kafka
C:> zkServer
D:> .\bin\windows\kafka-server-start.bat .\config\server.properties- 连接到mariadb创建
test数据库以及names数据表
# 通过docker命令连接maridb数据库
bash> docker exec -it [maridb-container-id] bash
bash> mysql -uroot -proot
# 创建数据库test并创建数据表names
create database test;
use test;
create table names ( name varchar(255) );- 向
Cloud Dataflow中注册Spring Cloud Stream应用(source.http、sink.jdbc),使用Cloud Dataflow的DSL实现数据流定义:
# 向cloud-dataflow中注册source.http
dataflow> app register --type source --name http --uri maven://org.springframework.cloud.stream.app:http-source-kafka-10:1.3.1.RELEASE
# 向cloud-dataflow中注册sink.jdbc
dataflow> app register --type sink --name jdbc --uri sink.jdbc=maven://org.springframework.cloud.stream.app:jdbc-sink-kafka-10:1.3.1.RELEASE
# 通过Cloud-Dataflow DSL发布数据流,请求`http 8787`端口并验证请求结果
stream create --name mysqlstream --definition "http --server.port=8787 | jdbc --tableName=names --columns=name --spring.datasource.driver-class-name=org.mariadb.jdbc.Driver --spring.datasource.url='jdbc:mysql://localhost:3307/test' --spring.datasource.username=root --spring.datasource.password=root" --deploy
# 通过stream list查看mysqlstream发布状态,如果发布成功会在status显示Successful deployed
dataflow> stream list
# 在dataflow中向http应用发送请求数据,如果请求发送成功会显示[202 accepted];同时在Maridb进行验证是否有记录插入数据表;
dataflow> http post --contentType 'application/json' --target `http://localhost:8787` --data "{\"name\": \"Dataflow\"}"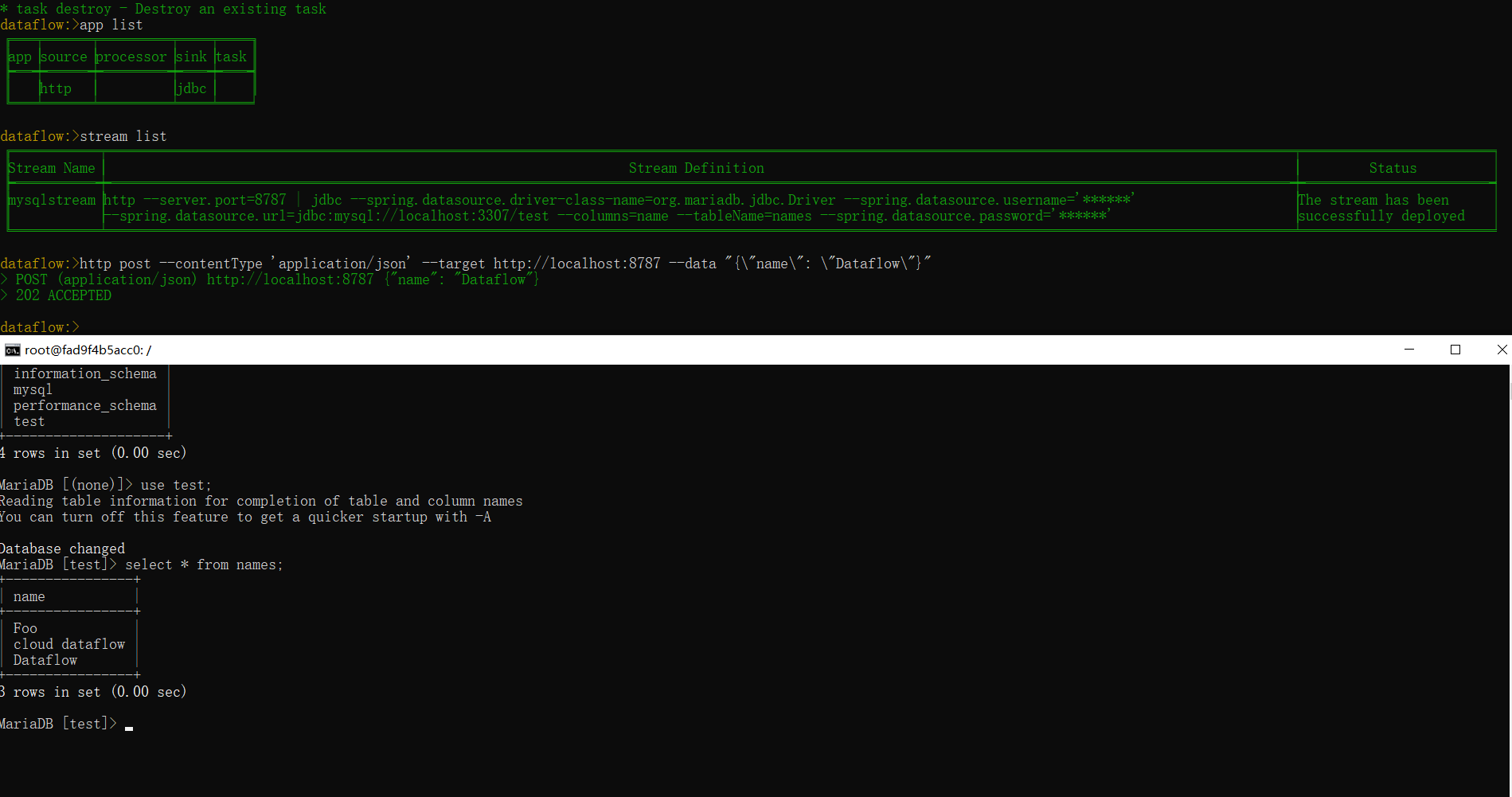
- Source App: 下面可以看到一个简单的Source应用程序,在
@InputChannelAdapter注释的帮助下,使得程序可以将产生的消息发送到spring.cloud.stream.bindings.output.destination配置的输出channel中,@EnableBinding注解触发Spring Cloud Stream配置;
@SpringBootApplication
@EnableBinding(Source.class)
public class SourceApp {
private Logger LOGGER = LoggerFactory.getLogger(SourceApp.class);
public static void main(String[] args) {
SpringApplication.run(SourceApp.class, args);
}
@InboundChannelAdapter(value = Source.OUTPUT)
public String source() {
String date = new Date().toString();
LOGGER.info("Source app input date: [{}]", date);
return date;
}
}- Processor App: processor类型的应用主要用于从
channel1中消费消息,同时将产生的消息发送到channel2中:
@SpringBootApplication
@EnableBinding(Processor.class)
public class ProcessorApp {
private static final Logger LOGGER = LoggerFactory.getLogger(ProcessorApp.class);
public static void main(String[] args) {
SpringApplication.run(ProcessorApp.class, args);
}
@ServiceActivator(inputChannel = Processor.INPUT, outputChannel = Processor.OUTPUT)
public String transform(String payload) {
LOGGER.info("Processor received message: [{}]", payload);
return payload + " processed";
}
}- Sink App: Sink类型的应用主要借助于
@StreamListener注解从input-channel中消费消息:
@SpringBootApplication
@EnableBinding(Sink.class)
public class SinkApp {
private static final Logger LOGGER = LoggerFactory.getLogger(SinkApp.class);
public static void main(String[] args) {
SpringApplication.run(SinkApp.class, args);
}
@StreamListener(Sink.INPUT)
public void sinkLog(String message) {
LOGGER.info("sink-app receive message: [{}]", message);
}
}Stream DSL使用基于unix的Pipeline(管道符)语法定义流,该语法使用“管道”来连接多个命令ls -l | grep key | less 在Unix中的less获取ls -l进程的输出并将其结果传递给grep key指定作为输入,grep的输出又被发送到less指令作为输入。 每个| symbol将左侧命令的标准输出连接到右侧命令的标准输入,将数据从左到右流过管道。
在Spring Cloud data-flow中,注册的Stream App作用就如Unix命令一样,每一个管道符通过消息中间件(RabbitMQ、Kafka)连接产生消息和消费消息的应用程序;
创建Stream的语法:
# 在--definition:定义流处理 --name:定义数据流的名称
dataflow:>stream create --definition "http --port=8090 | log" --name myhttpstream在部署应用以及应用运行过程中难免会出现异常,这时需要查看应用的运行日志,在Cloud Dataflow中可以在 管理页面中 'Runtime-> application'找到应用的运行日志:
在Cloud Dataflow可以对当前Stream流中的数据进行实时分析,在 使用Cloud Dataflow进行数据分析功能时需要启动Redis服务。目前支持3种分析的维度:
Counter: 统计应用从消息队列中接收到消息的数量,其会将统计结果存放在Redis缓存中;Field Value Counter: 统计从消息队列中某个字段的所有不重复的字段值;Aggregate Counter: 统计接收到的消息的总数量,不过会分别以分钟、小时、天、月为单位存储结果;
# docker启动redis服务
bash> docker run -p 6379:6379 --name redis-dataflow -d redis:latest
# 在cloud-dataflow中注册field-value-counter应用
dataflow> app register --type sink --name field-value-counter --uri maven://org.springframework.cloud.stream.app:field-value-counter-sink-kafka-10:1.3.1.RELEASE
# 创建进行实时数据分析的Stream流
stream create http_analystic --definition ":mysqlstream.http > field-value-counter --fieldName=name --name=httpfield" --deploy创建http_analystic数据流之后可以,通过dataflow-shell向mysqlstream中发送请求:
# 向mysqlstream中发送请求数据
dataflow> http post --contentType 'application/json' --target http://localhost:8787 --data "{\"name\": \"Dataflow\"}"
# 查看当前field-value-counter分析列表
dataflow> field-value-counter list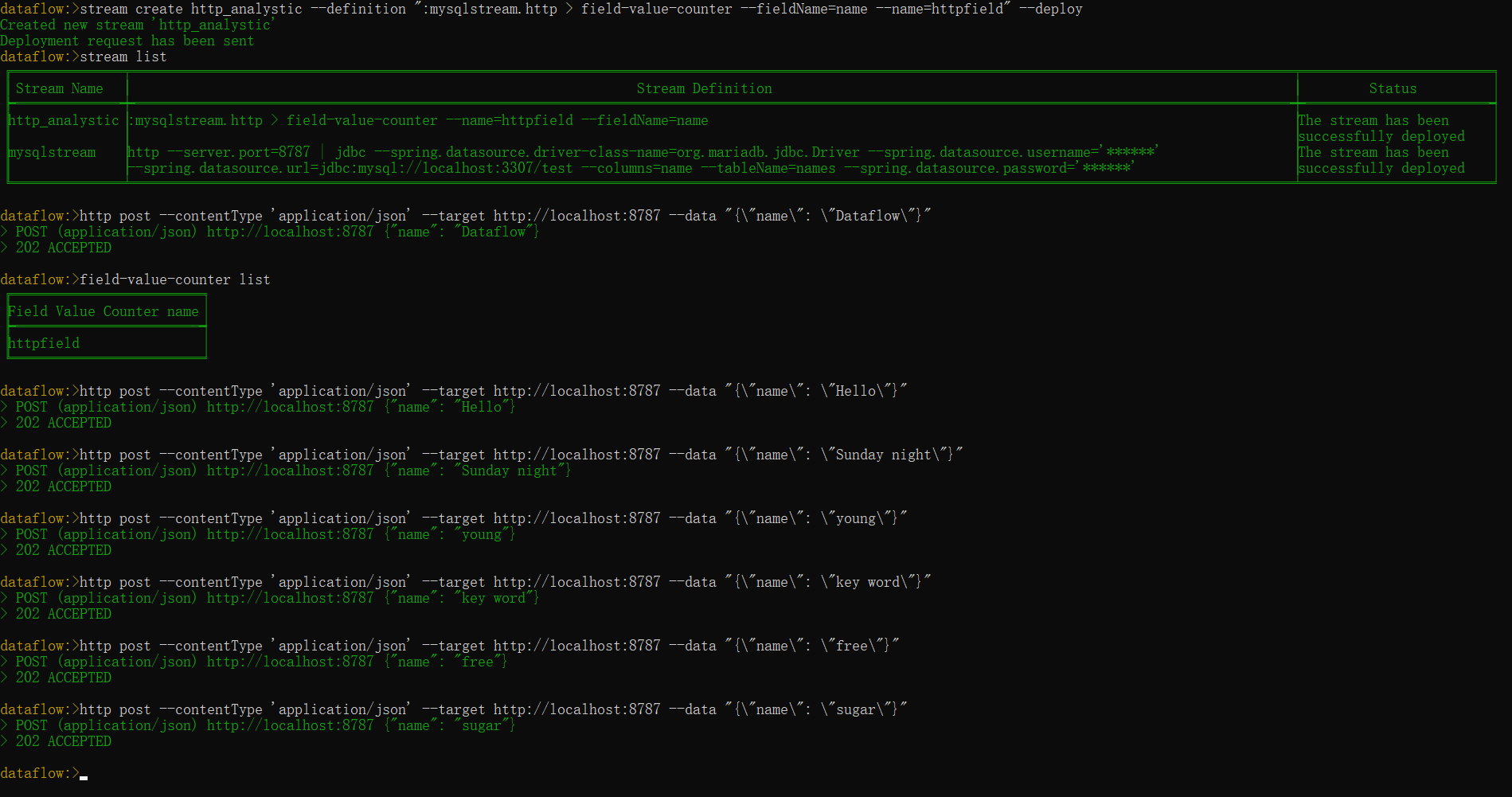
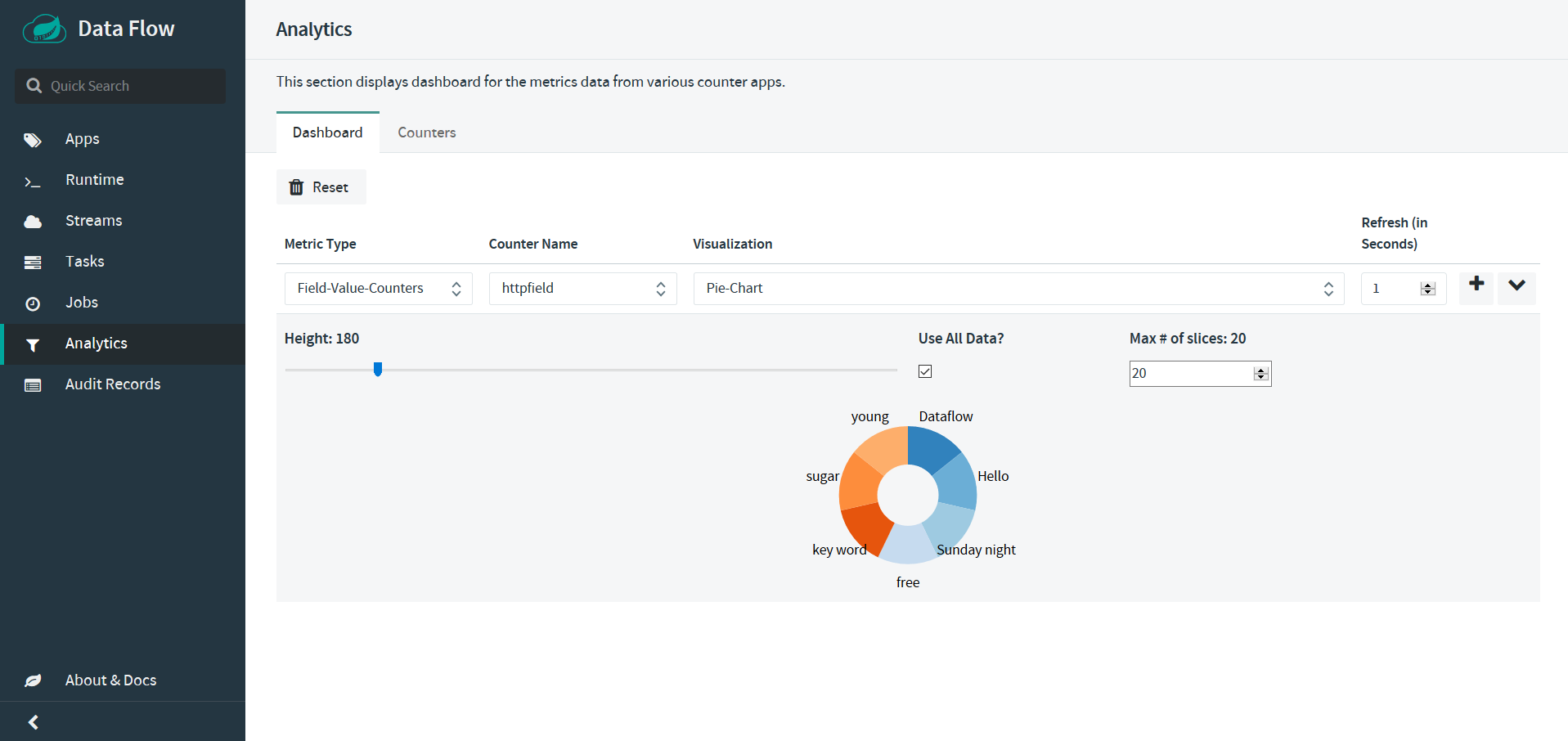
在data flow的管理界面查看分析结果,Analystic | Dashboard,在Metric Type选项选择Field Value Counters ,Counter Name选项选择httpfield,Visualization选项选择Pie Chart,最后结果如下图所示:在饼状图中展示了发送给http应用程序name字段所有不重复的字段值;
SpringCloud Task介绍: Spring Cloud Task 主要解决微服务中周期短的的任务以及任务调度的工作,比如“每间隔一段时间对任务进行重新执行、或者在每天的特定时刻执行任务等等”。一个任务通常作为后台进程来执行,在Spring Cloud Task中常常使用@EnableTask注解启用其功能,用户常常在主进程中发起一个任务,当任务结束时该进程也终止。一个任务通常需要记录其开始时间startTime、结束时间endTime以及任务最终执行状态exit code。Cloud Dataflow中Task的实现主要是基于Spring Cloud Task项目的。
创建一个Spring Cloud Task程序(依赖于spring-cloud-starter-task)
@EnableTask
@SpringBootApplication
public class MyTask {
public static void main(String[] args) {
SpringApplication.run(MyTask.class, args);
}
}向Cloud Dataflow中注册一个task应用:
dataflow> app register --type task --name timestamp --uri maven://org.springframework.cloud.task.app:timestamp-task:1.3.0.RELEASE创建一个Task任务,指定task任务的--name属性
dataflow> task create timestamp-task --definition "timestamp --format=\"yyyy\""
Created new task 'timestamp-task'
# 使用task list查看创建的任务
dataflow> task list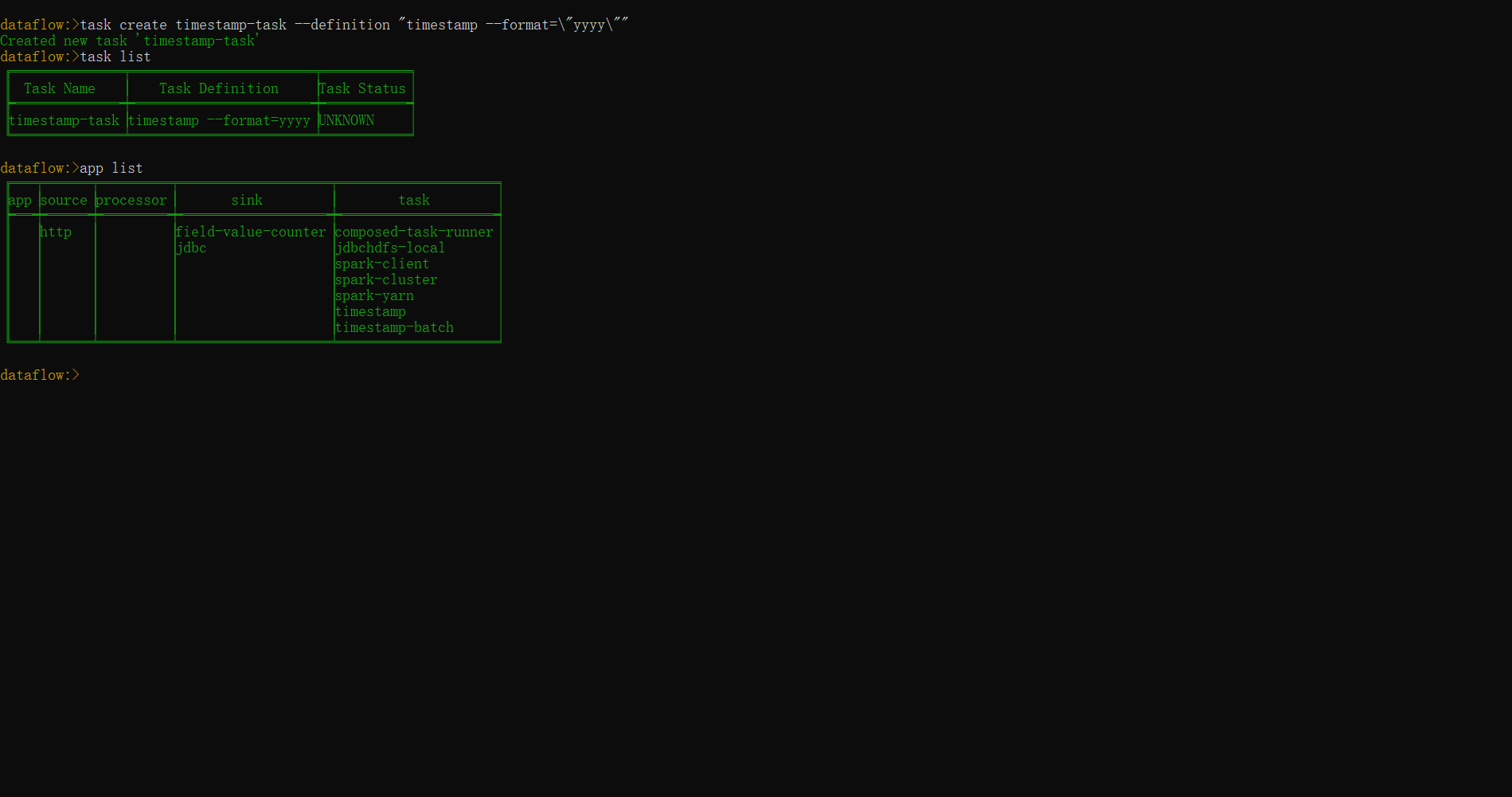
发起一个任务:一个任务可以通过Restful Api或者Cloud Dataflow shell命令行进行触发,在命令行中输入task launch [task-name]可以触发这个任务:
dataflow:> task launch timestamp-task
Launched task 'timestamp-task'
# 也可以在触发task任务时指定任务参数[--arguments]
dataflow:> task launch timestamp-task --arguments "--server.port=8080 --custom=value"
# 其他task触发的任务本身属性可以通过`--properties`配置进行设置
dataflow:> task timestamp-task --properties "deployer.timestamp.custom1=value1,app.timestamp.custom2=value2"查看任务的执行情况:一旦一个任务执行了,任务执行的状态会放在关系型数据库中。其中包含的字段名称包括:TaskName,Start Time,End Time, Exit Code,Exit Message,Last Updated Time,parameters等多个字段;
# 查看所有task任务执行状态
dataflow:> task execution list
# 查看特定task任务更详细信息内容
dataflow:> task execution status --id [taskId]
# 销毁特定的task任务
dataflow:> task destory timestamp-task
# 验证特定的task任务(有时候一个task任务中可能包含多个应用,可以对app register时的注册地址是否有效进行验证)
dataflow:> task validate timestamp-task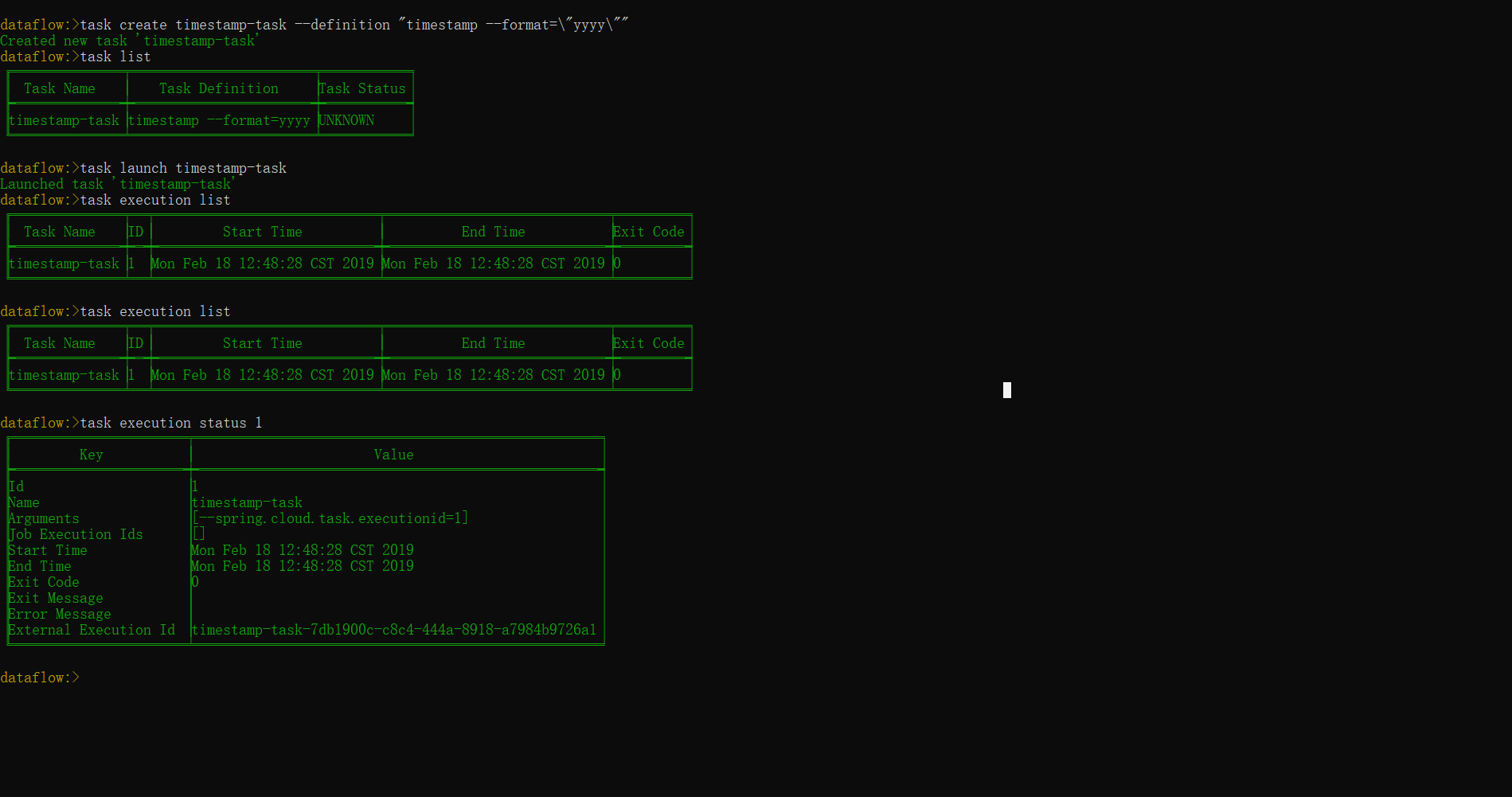
Spring Cloud Task数据流允许用户创建一个有向图,图中的每个节点都是一个任务应用程序。这是通过对组合任务使用DSL来完成的。可以通过Restful API、Spring Cloud Dataflow Shell或Spring Cloud Dataflow UI创建复合任务。
- 向
Cloud-Dataflow中注册composed-task-runner应用
dataflow:> app register --name composed-task-runner --type task --uri maven://org.springframework.cloud.task.app:composedtaskrunner-task:1.1.0.RELEASE- 注册多个
task应用,创建一个composed-task任务并执行
# 向cloud-dataflow中注册spark-yarn task应用程序
dataflow:> app register --name spark-yarn --type task --uri maven://org.springframework.cloud.task.app:spark-yarn-task:1.3.0.RELEASE
# 向cloud-dataflow中注册timestamp task应用程序
dataflow:> app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:1.3.0.RELEASE
# 创建一个composed task
dataflow:> task create composed-task --definition "spark-yarn && timestamp"
# 启动创建的composed-task任务
dataflow:> task launch composed-task
# 使用task list命令查看当前注册的所有应用
dataflow:> task list
# 使用task execution list可以查看composed-task任务的执行状态
dataflow:> task execution list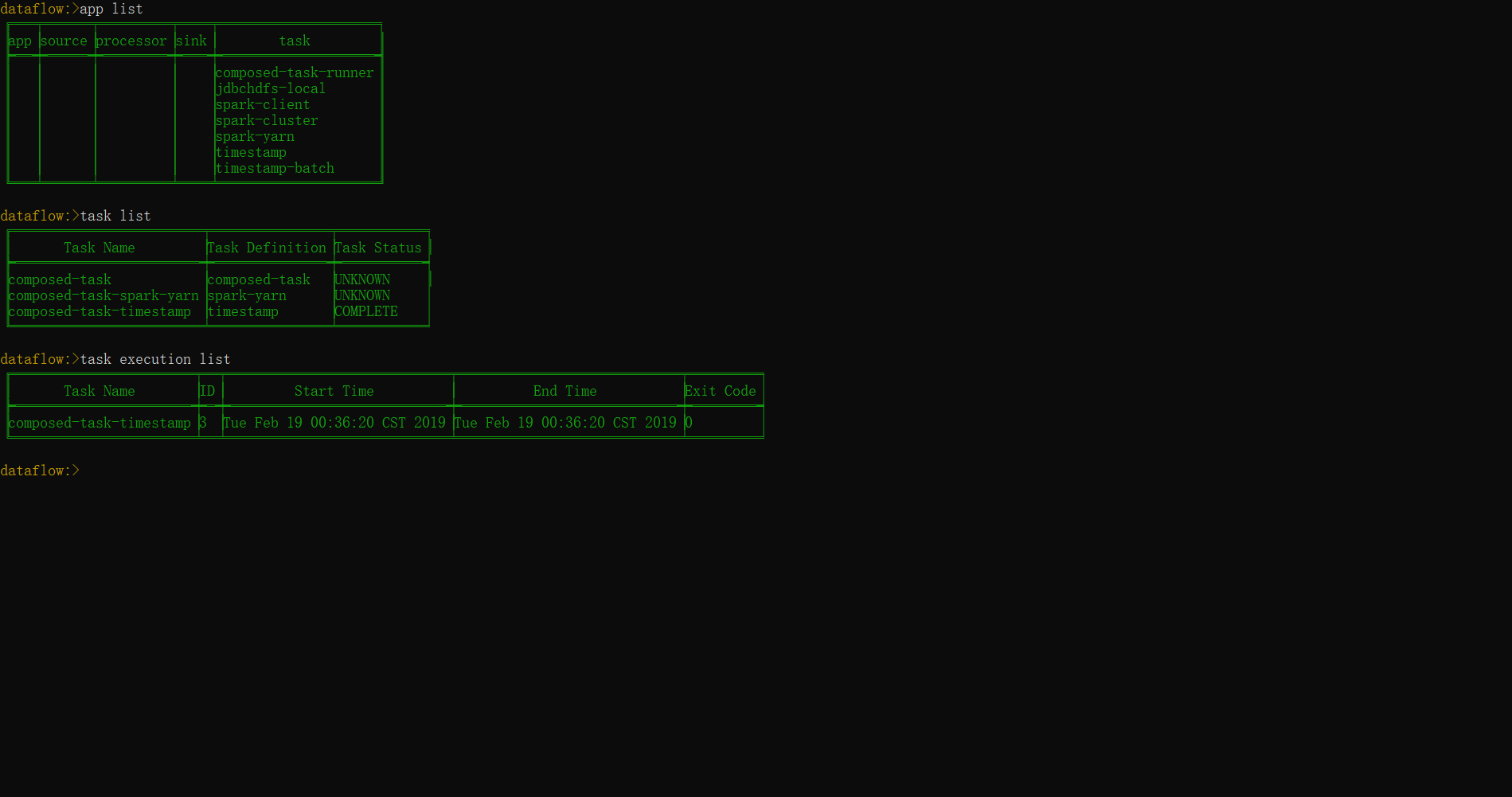
在launch composed task任务时,可以通过app.<composed task definition name>.<child task app name>.<property>的方式设置子任务的属性。
# 在执行task任务时设置timestamp.format属性的值
dataflow:> task launch composed-task --properties "app.composed-task.timestamp.format=YYYY"
# 同样也可以在task任务执行时设置deployer属性
dataflow:> task launch composed-task --properties "deployer.composed-task.spark-yarn.memory=2048m,app.composed-task.mytimestamp.timestamp.format=HH:mm:ss"销毁一个composed-task以及停止一个composed-task任务,对于停止一个已经启动的composed-task任务,可以在Dataflow-UI界面上选择Jobs | Stop the Job(针对要进行停止的task任务)
# 销毁之前已经创建的composed-task任务
dataflow:> task destroy composed-task
# 在销毁composed-task任务之后,执行task list就看不到已经注销的应用
dataflow:> task list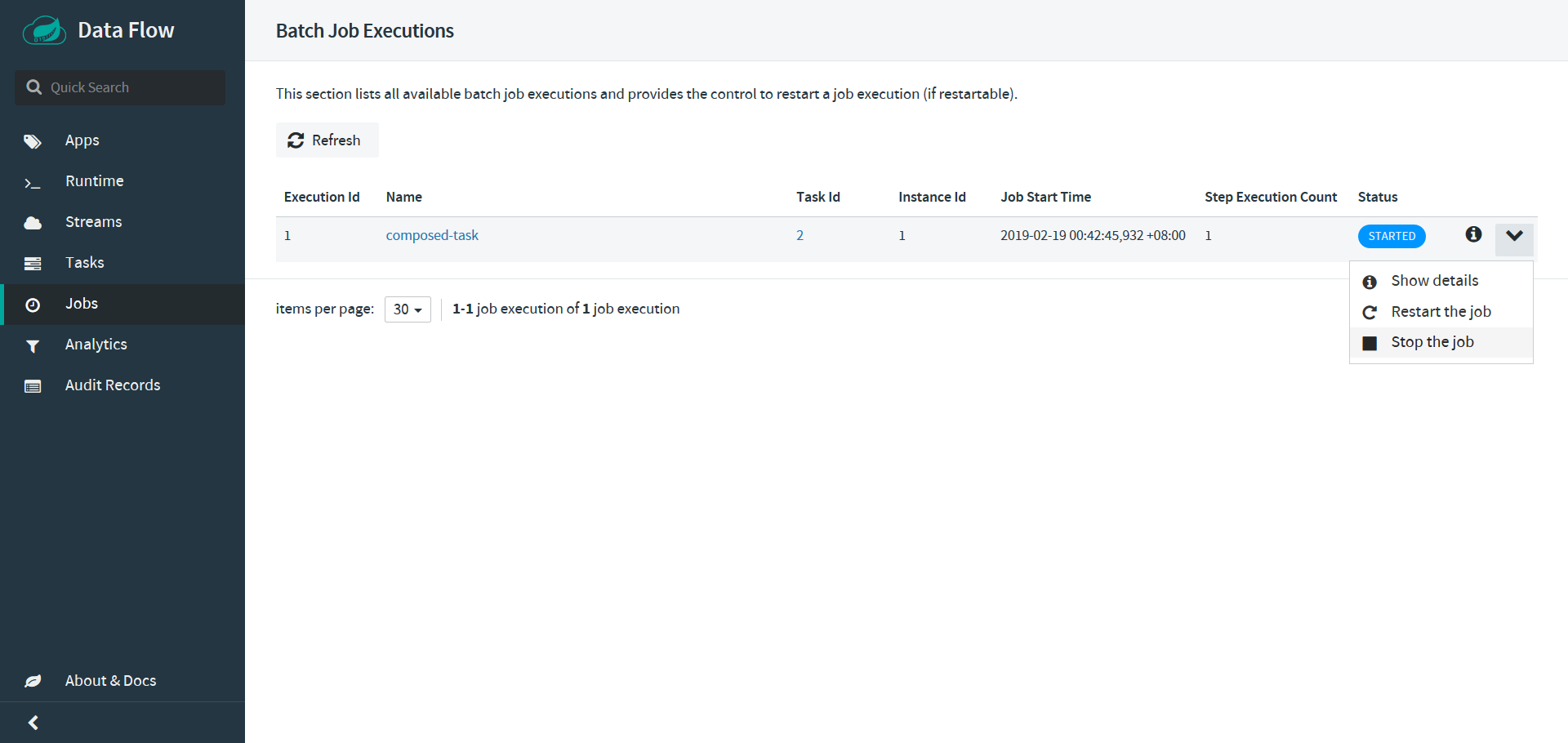
- 当
task1执行成功后再执行task2,有依赖条件的composed task,通常使用&&操作符表示这种关系。
# 只有task1成功执行完成才会执行task2
dataflow:> task create composed-task --definiton "task1 && task2"
- 当
task1任务执行状态Failed时执行bar应用,执行状态为Completed则执行baz应用,当task1任务执行状态为其它时则该composed task任务执行结束;
dataflow:> task create composed-task --definition "task1 'Failed' -> bar 'Completed' -> baz"
# 可以使通配符'*'表示其它所有情况
dataflow:> task create composed-task --definition "task1 'Failed' -> bar '*' -> baz"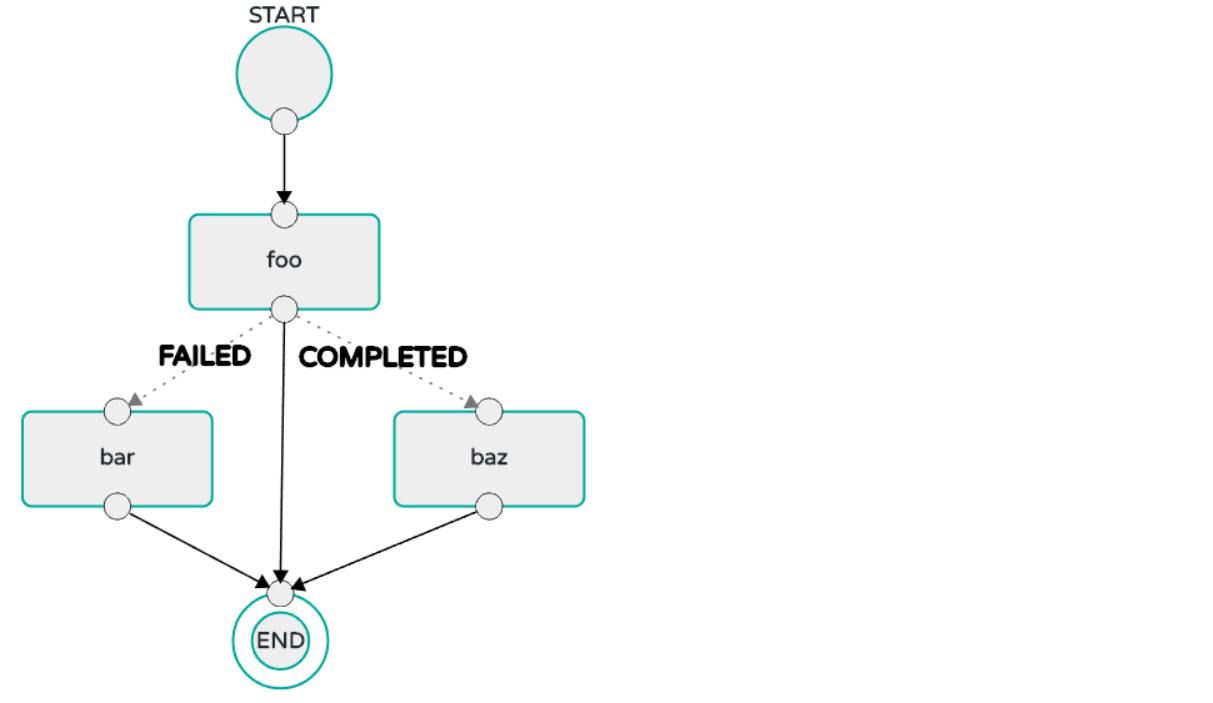
- 并行执行
task任务,使用< || >表示
# foo、bar、baz 3个task任务可以并行执行
dataflow:> task create parallel-task --definition "<foo || bar || baz>" 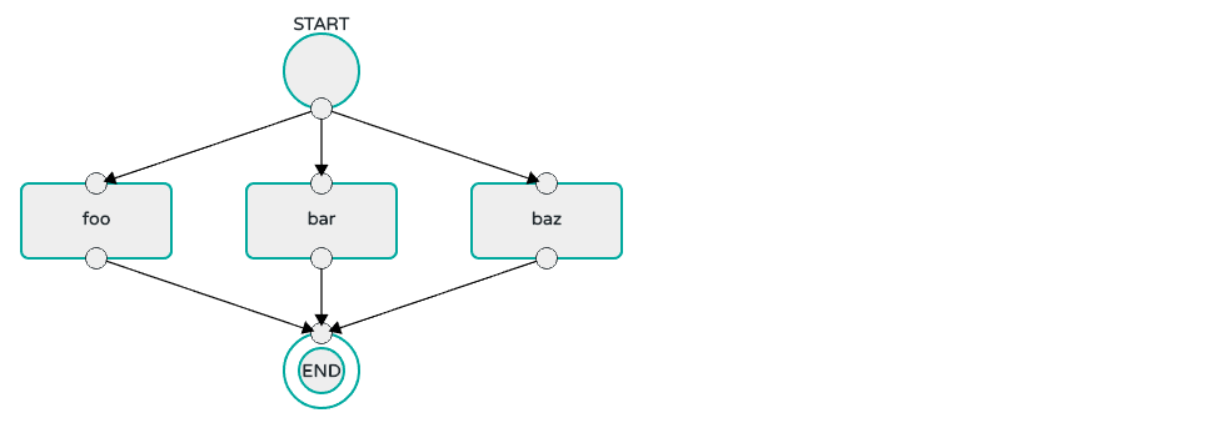 4.
4. foo、bar、baz应用可以并行执行,等全部执行完成后,可以并行执行qux、quux任务
dataflow:> task create my-split-task --definition "<foo || bar || baz> && <qux || quux>"'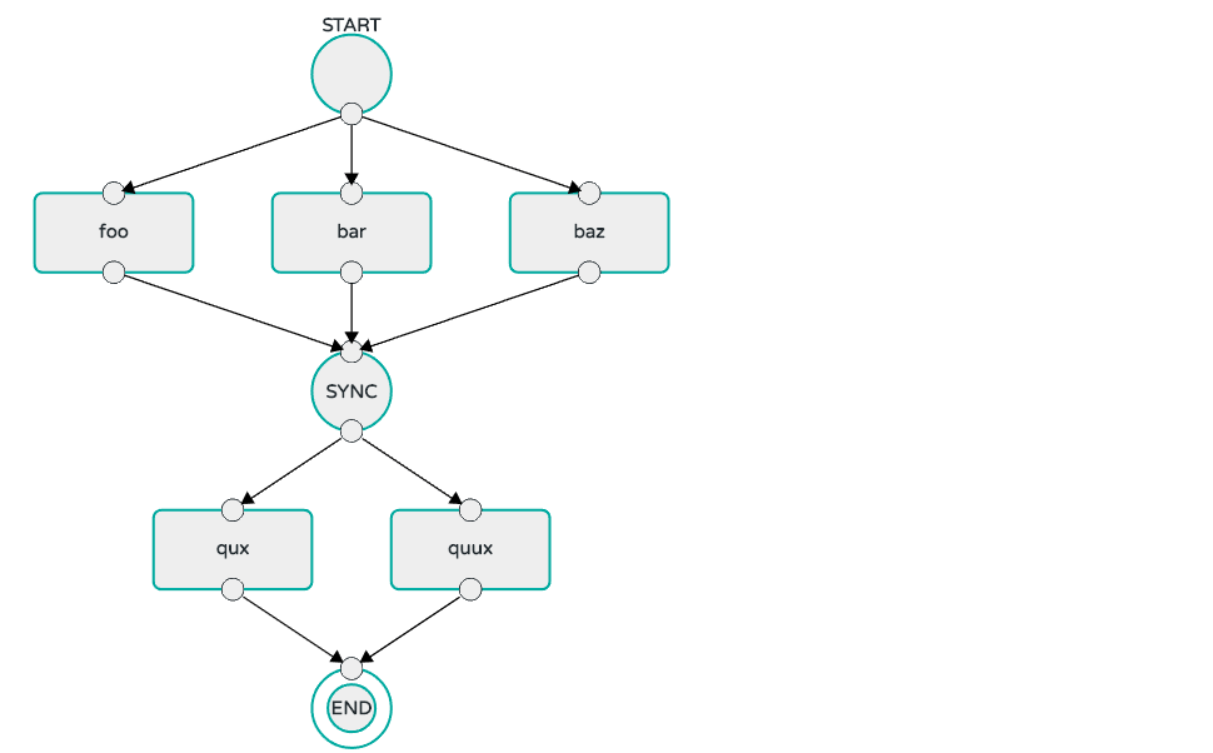
Cloud Dataflow在基于Spring Cloud Stream之上增强了对于Stream的数据流管理,Cloud Dataflow提供的DSL可以自定义数据流,同时其提供的实时数据分析功能也可以对数据流内容进行实时监控,其自身的DSL对于数据流处理提供了很大的灵活性。
对于Task任务的管理,Cloud Dataflow提供了后台管理UI可以很方便管理应用,同时其自身的DSL可以轻松处理多个任务之间的依赖关系,对于任务的管理提供了很大的灵活性,像一些离线的应用都可以放到Cloud Dataflow中对其进行统一管理。