** The progress thus far are preliminary results. I am still in the process of rigorous validation of the efficiency of this deep learning model **
I came across this network while studying about Attention mechanisms and found the architecture really intriguing. After reading the paper, "Residual Attention Network for Image Classification", by Fei Wang et al., I put myself to task to implement it to understand the network more in-depth.
To give a brief summary of the paper, a Residual Attention Network (RAN) is a convolutional neural network that incorporates both attention mechanism and residual units, a component that utilizes skip-connections to jump over 2–3 layers with nonlinearities (e.g. ReLU in CNNs) and batch normalizations. It's prime feature is the attention module.
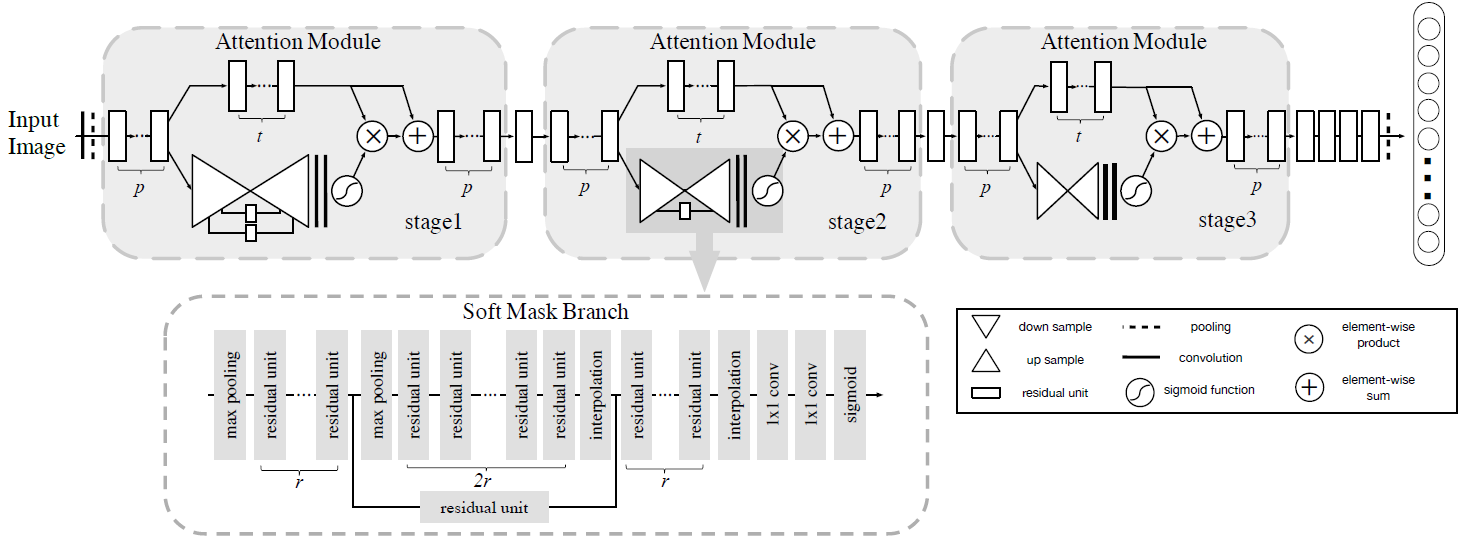
Figure: Full Architecture
The RAN is built by stacking Attention Modules, which generate attention-aware features that adaptively change as layers move deeper into the network.

Figure: Attention Module
The composition of the Attention Module includes two branches: the trunk branch and the mask branch.
-
Trunk Branch performs feature processing with Residual Units
-
Mask Branch uses bottom-up top-down structure softly weight output features with the goal of improving trunk branch features
- Bottom-Up Step: collects global information of the whole image by downsampling (i.e. max pooling) the image
- Top-Down Step: combines global information with original feature maps by upsampling (i.e. interpolation) to keep the output size the same as the input feature map
Once the actions are completed, the features extracted from the respective branches are combined together using the team's novel Attention Residual Learning formula. This is used to train very deep Residual Attention Networks so that it can be easily scaled up to hundreds of layers without a drop in performance. Thus, increasing Attention Modules leads to consistent performance improvement, as different types of attention are captured extensively.
I've certainly glossed over a lot of details within the paper, so I'd definitely recommend reading that.
Once I gained a solid understanding of the RAN, I utilized Keras to put it to action. For my use case, I trained the model to classify cats vs dogs image data. For the results of this, you can find the notebook here .
To put it short, the network consistently improved despite being very deep. This cats vs dogs classification was a small example, however. I plan on utilizing this network in further studies to examine its power and report back to the world.
Paper: “Residual Attention Network for Image Classification” https://arxiv.org/pdf/1704.06904.pdf
Authors: Wang, Fei and Jiang, Mengqing and Qian, Chen and Yang, Shuo and Li, Cheng and Zhang, Honggang and Wang, Xiaogang and Tang, Xiaoou
Github: https://github.com/fwang91/residual-attention-network
Paper: "Deep Residual Learning for Image Recognition" https://arxiv.org/pdf/1512.03385.pdf
Paper: "Identity Mappings in Deep Residual Networks" https://arxiv.org/pdf/1603.05027.pdf
Authors: Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
Github: https://github.com/qubvel/residual_attention_network
- Though our final implementation is ultimately different, I was able to get a more solid understanding of the network thanks to the github user, qubvel. Thanks!