This repository contains work done as part of the 2022 edition of the Full Stack Deep Learning course. The team contributing to this work consisted of @zacbouhnik, @PawPod, @fsmitskamp and @davanstrien.
tl;dr this project develops a machine learning model which can tell you whether a page of a historical book contains an illustration or not.


If you want to get straight to the outputs of this project you can find the datasets, models and demos on our Hugging Face hub organisation (https://huggingface.co/ImageIN).
We have two demos for the project:
If you want to run the model locally against a directory of images, you can also use the model(s) we trained via flyswot. For example to predict all .png images in a directory images you can run:
flyswot predict directory images/ /Users/dvanstrien/Desktop --image-formats .png --model-id ImageIN/convnext-base-224_finetuned_on_ImageIn_annotationsThis will generate a CSV report saved at /Users/dvanstrien/Desktop with the predicted labels for each image.
Over the past couple of decades libraries, archives, museums, and other organisations have increasingly digitised content they hold. This includes a large number of digitised books. Some of these books contain illustrations, it would be nice to be able to identify pages which contain illustrations so that:
- you know what (if any) other machine learning models you might use on that page (Optical character Recognition, layout detection etc.)
- so you can extract datasets of visual content from books
- as part of an image search pipeline
- so you can look at nice pictures more easily
- ...
For this project we primarily used data from the Internet Archive.
| Dataset | Description |
|---|---|
| ImageIN/IA_unlabelled | This a dataset of pages from historic digitised books held by the Internet Archive. To increase the presence of illustrations in downstream datasets the words 'illustration' are used in the intial search |
| ImageIn_annotations | This dataset is sampled from the full unlabelled dataset and contains hand annotated labels indicating if a page is 'illustrated' or 'not-illustrated' |
| ImageIN/IA_loaded | This is a subset of ImageIN/IA_unlabelled where images have been loaded into the dataset from their URLs. This is done to avoid having to rerun this step when developing/applying labelling functions |
| ImageIN/unlabelled_IA_with_snorkel_labels | This dataset contains the data from ImageIN/IA_loaded with weak labels applied using Snorkel (see below for more details) |
The project has a number of enablers and constrains which informed the approach taken.
- Open access data: libraries, archives and museums make large amounts of their data available under permissive licences (primarily Creative Commons)
- IIIF (more on this below)
- Existing metadata: existing metadata for collections items can enable filtering and retrieval of relevant material more easily.
- Labelled data: there exists neither a large dataset for this task (that we're aware of).
- Computation for inference: libraries, archives and museums have a broad range of computational resources available. Whilst some have GPU clusters, or can access these via cloud providers, this is not the case for all institutions.
Our approach aims to balance the enablers and the constrains outlined above.
- Snorkel is used for helping generate labels using labelling functions
- Weights and Biases is used for tracking model training
- 🤗 datasets is used for processing our data and moving it between machines via the Hugging Face hub
- 🤗 transformers: we use transformer implementation of the computer vision models we use and the
Trainerclass for model training. - IIIF: see below
IIIF (International Image Interoperability Framework), is
a way to standardize the delivery of images and audio/visual files from servers to different environments on the Web where they can then be viewed and interacted with in many ways. source
It's beyond the scope of this README to explain all of the aspects of this standard. https://iiif.io/get-started/how-iiif-works/ provides a good starting point to learning more about IIIF.
One thing that you may be inevitability wondering is whether anyone actually uses this standard.

In contrast to many standards, IIIF has seen wide adoption particularly in the cultural heritage sector. Users include; the British Library, Brown University Digital Repository, David Rumsey Map Collection, Europeana, Harvard Art Museum, Internet Archive...
Basically a lot of organisations are adopting IIIF. There are two particular components of this standard that will be of interest to us for this project.
IIIF includes an image API specification. Let's take a look at an example IIIF URL from the Internet Archive
https://iiif.archivelab.org/iiif/memoirslettersof01bernuoft$10/full/full/0/default.jpg
This image is what we get back if we load this URL

If we take a look at the specification for the image API we see that the URL structure contains information about how we want to have the image we're interested in returned to us.
{scheme}://{server}{/prefix}/{identifier}/{region}/{size}/{rotation}/{quality}.{format}
For example, we can specify that we want the same image, but scaled to 250 pixels wide and rotated 180 degrees
https://iiif.archivelab.org/iiif/memoirslettersof01bernuoft$10/full/250,/180/default.jpg
If we load this URL we get this image

This is helpful for a number of reasons:
- we can request an image closer to the size we'll need for model training/inference. Many computer vision models expect images to be much smaller in size than the default images we'd get back from the Internet Archive (or other institutions). Often images are very large/high-resolution to start with but we don't necessarily need this for computer vision uses.
- this smaller image scaling is done on the server supplying the image. This means we can request an image close to the size we need and only receive the data we need. This makes requesting images quicker.
- since this URL is structured we can use it to identify the source it came from. This can mean less book keeping will be required for linking predictions back to other metadata systems (more on this below)
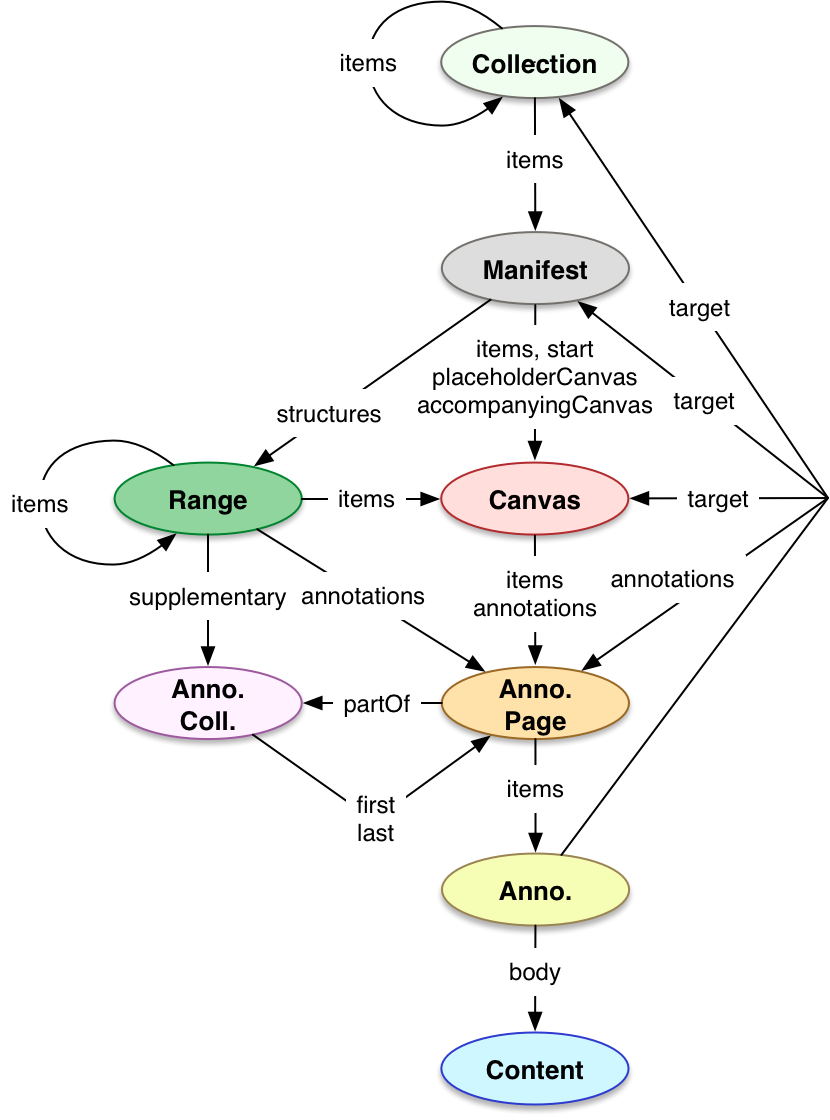
Access to digital representations of objects is a fundamental requirement for many research activities, for the transmission of cultural knowledge, and for the daily pursuits of every web citizen. Ancient scrolls, paintings, letters, books, newspapers, films, operas, albums, field recordings, and computer generated animations are compound objects: they can have many parts, and complex structures. These resources may also bear the written or spoken word, and this linguistic content is often as important as the visual or audible representation.
Collections of both digitized physical objects and much born-digital content benefit from a standardized description of their structure, layout, and presentation mode. This document specifies this standardized description of the collection or compound object, using a JSON format. Many different rich and dynamic user experiences can be implemented, presenting content from across collections and institutions.
A visual representation of this:
{kind=link}
{kind=link}
{kind=link}
We won't be able to get your head fully around this standard here, instead we'll focus on a quick example. We'll work with this manifest https://iiif.archivelab.org/iiif/exhibitorsherald99unse/manifest.json.
This manifest is a JSON document. The document has the following keys:
[
"@context",
"@id",
"@type",
"attribution",
"cover",
"description",
"label",
"logo",
"metadata",
"related",
"seeAlso",
"sequences",
"thumbnail",
"viewingHint"
]If we dig further into the sequences key, we get to an array that contains page images (you'll notice that we have IIIF image URLs).
[
{
"@context": "http://iiif.io/api/image/2/context.json",
"@id": "https://iiif.archivelab.org/iiif/exhibitorsherald99unse/canvas/default",
"@type": "sc:Sequence",
"canvases": [
{
"@context": "http://iiif.io/api/presentation/2/context.json",
"@id": "https://iiif.archivelab.org/iiif/exhibitorsherald99unse$0/canvas",
"@type": "sc:Canvas",
"description": "",
"height": 4159,
"images": [
{
"@context": "http://iiif.io/api/image/2/context.json",
"@id": "https://iiif.archivelab.org/iiif/exhibitorsherald99unse$0/annotation",
"@type": "oa:Annotation",
"motivation": "sc:painting",
"on": "https://iiif.archivelab.org/iiif/exhibitorsherald99unse$0/annotation",
"resource": {
"@id": "https://iiif.archivelab.org/iiif/exhibitorsherald99unse$0/full/full/0/default.jpg",
"@type": "dctypes:Image",
"format": "image/jpeg",
"height": 4159,
"service": {
"@context": "http://iiif.io/api/image/2/context.json",
"@id": "https://iiif.archivelab.org/iiif/exhibitorsherald99unse$0",
"profile": "https://iiif.io/api/image/2/profiles/level2.json"
},
"width": 2758
}
}
],
"label": "p. ",
"width": 2758
},
]This means that the manifest for a book can be used to generate URLs for all the book page images, this means we can also use models created as part of this project to identify all the illustrated pages in a particular book or set of books.