![]()
Triggered by the Data Science hype, many companies started working on the topic but only few are really successfull. The main barrier is the gap between the expectations of the stakeholders and the actual value delivered by models, as well as the lack of information over incoming data, in terms of both data quality and the processes producing them. In addition, projects require a very interdisciplinar team, including system administrators, engineers, scientists, as well as domain experts. Consequently, a significant investment and a clear strategy are necessary to succeed.
Moreover, typical lambda architectures (i.e. one that combines a streaming layer to a batch one) bring in significant complexity and potential technical gaps. Whilst continuous-integration and deployment (CICD) can automate and speed up to a great extent (using unit and integration tests, as well as frequent releases) the software development cycle, generally data scientists tend to work in a different workflow, and are often operating aside the rest of the team with consequent information gaps and unexpected behaviors upon changes on the data they use and the models they produced.
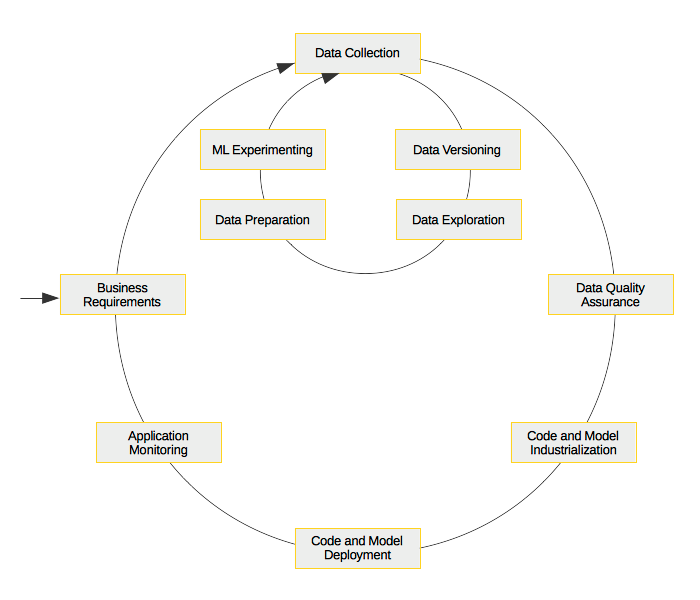
In this setup, waste of resources is the norm.
The goal is therefore to enforce DataOps practices and provide a complete - cloud native -(or cloud-provider agnostic) architecture to develop data analytics applications:
- Data ingestion
* logs - Confluent Kafka ecosystem
* sensor data - AMQP and MQTT protocols (e.g. RabbitMQ) - Data storage and versioning
* local S3 datalake (e.g. minio)
* data versioning (i.e. pachyderm) - Data processing
* batch processing (e.g. Dask, Spark)
* stream processing (e.g. KSQL and Kafka streams, Spark Streaming, Flink) - Monitoring of distributed services
* metrics - timeseries database and dashboarding tool (e.g. prometheus and graphana)
* logs - Elastic stack - Data Exploration
* spawnable development environments (e.g. Jupyterhub) - Experiment tracking
* model training, benchmarking and versioning
* versioning of development environment - Model serving
* collection of model performance and user interaction (e.g. AB testing)
Data-Mill already provides:
- K8s setup
* Local (i.e. Minikube, MicroK8s)
* Remote (experimental) (i.e. AWS, GKE) - Networking
* Load Balancers for bare-metal clusters
* Overlay Network
* Application Gateways - Setup of common components
* Ingestion (e.g. kafka, RabbitMQ)
* Persistent storage (e.g. s3, ArangoDB, InfluxDB, Cassandra)
* Data Versioning (e.g. Pachyderm)
* Processing (e.g. dask, spark, flink)
* Exploration Environment (e.g. JupyterHub)
* Text Analytics (e.g. elasticsearch)
* BI Dashboarding (e.g. superset)
* ML model versioning and benchmarking, as well as project management (e.g. mlflow)
* ML model serving (e.g. Seldon-core)
* Monitoring (e.g. prometheus, Grafana) - Data Science Environments
* Scientific Python Environment
* PySpark Environment
* Keras/Tensorflow Environment
* Keras/Tensorflow GPU Environment - Example Applications
* Access to services - notebooks
* Batch processing
* Stream processing
The Data Mill logo reflects the purpose of a team embarking on a data science project. The Mill is the place where farmers bring their wheat to produce flour and finally bread. As such, it is the most important place in a village to process raw material and obtain added value, Food. The inner Star is a 8-point one, this is generally used to represent the Polar Star, historically used for navigation.
- Select a target folder e.g. user home
export DATA_MILL_HOME=$HOME
- Download and run installation script to the target directory
wget https://raw.githubusercontent.com/data-mill-cloud/data-mill/master/install.sh --directory-prefix=$DATA_MILL_HOME
cd $DATA_MILL_HOME
sudo chmod +x install.sh
./install.sh
rm install.sh
This downloads the latest version of data-mill at $DATA_MILL_HOME and copies the run.sh to the /usr/local/bin to make it callable from anywhere.