1. 数据集
以超市交易为数据集,所有商品的项集为
I = {bread, beer, cake, cream, milk, tea}某条交易如
Ti = {bread, beer, milk}简化为
Ti = {a, b, d}data.txt数据集样本如下
a, d, e,f
a, d, e
c, e
e, f
...2. 算法实现
使用经典的Apriori算法,依次扫描交易记录集,计算出 k-候选集Ck 然后去除支持度sup小的项集获得 k-频繁集Lk, 只计算到 3-频繁集 ,最后计算管理规则可信度即可。
第k个候选集只会从k-1频繁集中的各项目组合连接,然后扫描记录集,以获取Ck中各项集的支持度。

1. 数据集
使用身高体重指数分为胖瘦两个分类,数据自己生成见 *data_generation.py 比较简陋。
数据集样本如下
184 77 fat
189 81 fat
178 75 fat
...2.算法实现
调用python实现的类库,比较简单
from sklearn import tree
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
...
# 数据拆分,80%训练,20%测试
x_train, x_test, y_train, y_test=train_test_split(x, y, test_size = 0.2,random_state=0)
# 使用DecisionTreeClassifier建立模型并训练
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(x_train, y_train)
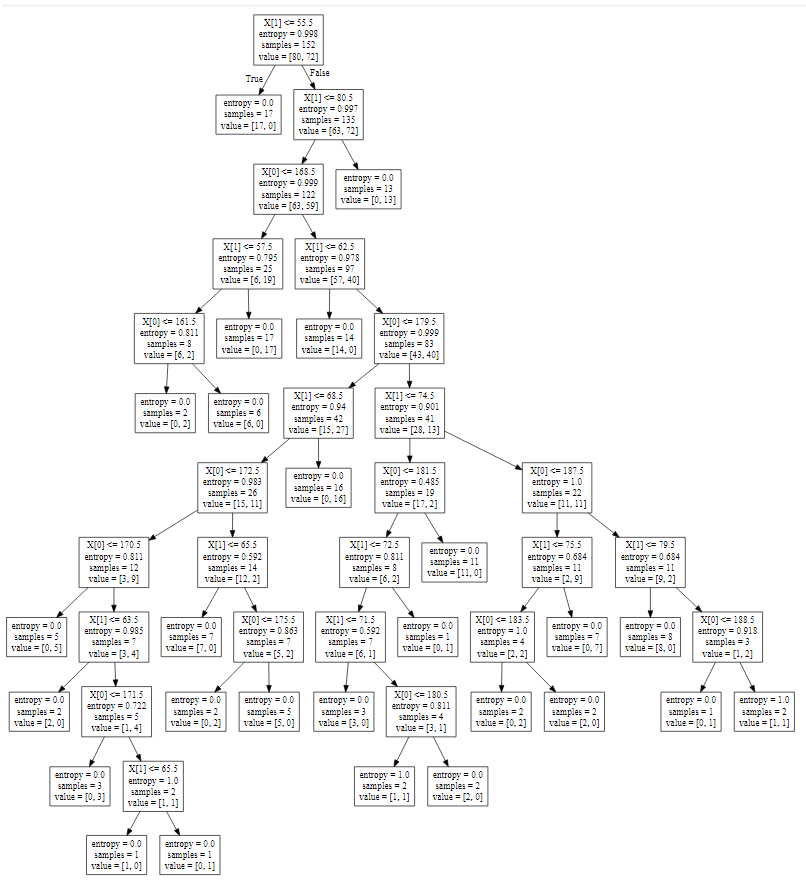
...打印后同时保持决策树到文件 *tree.dot,通过dot命令可以生产决策树图形(或者在线转换
# 保存决策树为dot文件,后续图形处理
with open("tree.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
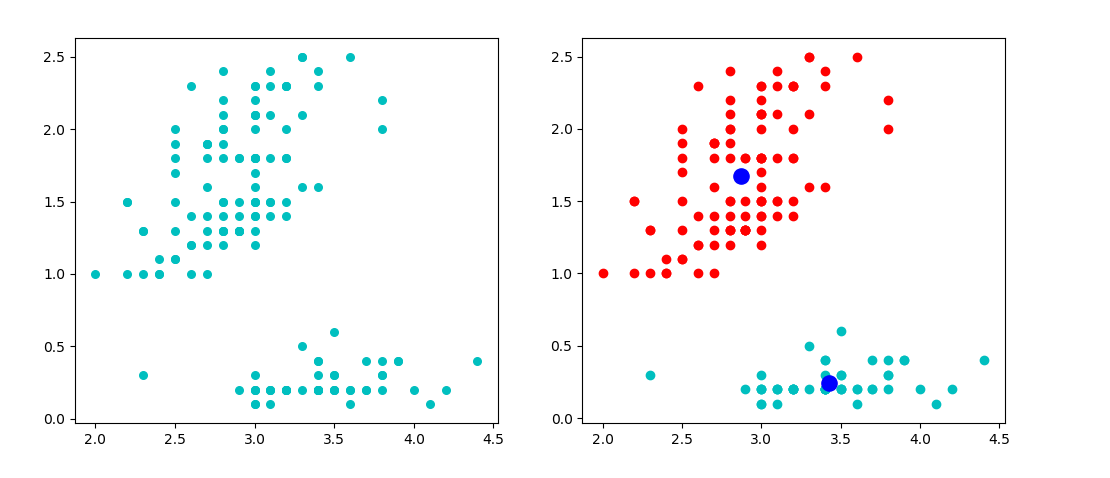
数据集采用python类库有名的iris坐标点集
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data, iris.target数据集样本如下
[1.5 0.2]
[3.2 0.2]
[3.1 0.2]
[4.6 0.2]
...2. 算法实现
K-means算法需要先指定要分成k类,数据样本只有熟悉,没有类别。
大概步骤:
- 从数据集X从随机选取k个数据样本作为聚类的初始化代表点,每一个代表点表示一个类别。
- 对于数据集中的任一样本点,都计算它与这k个初始化代表点的距离(d可用欧氏距离),然后划分到距离最近的分类中去。完成一次聚类
- 划分好数据后,计算每个聚类的均值,并将之作为该聚类的新代表点,因此得到k个新代表点。
- 和第二步一样,再继续计算每个点到代表点的距离,划分到距离最小的类
- 重复3和4,直到各个聚类不再发生变化(样本点划分固定了),即误差平方和准则函数的值达到最优。