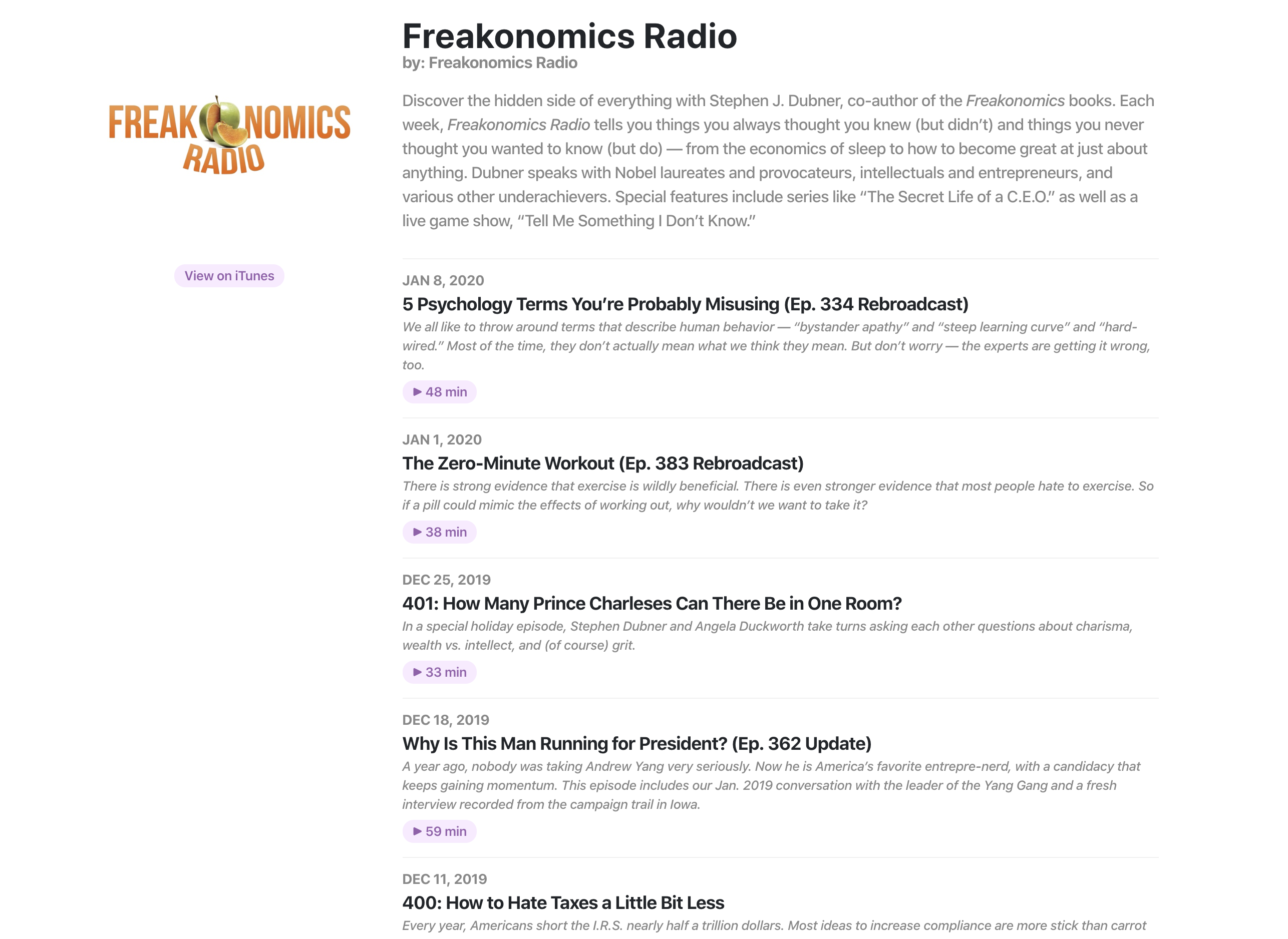
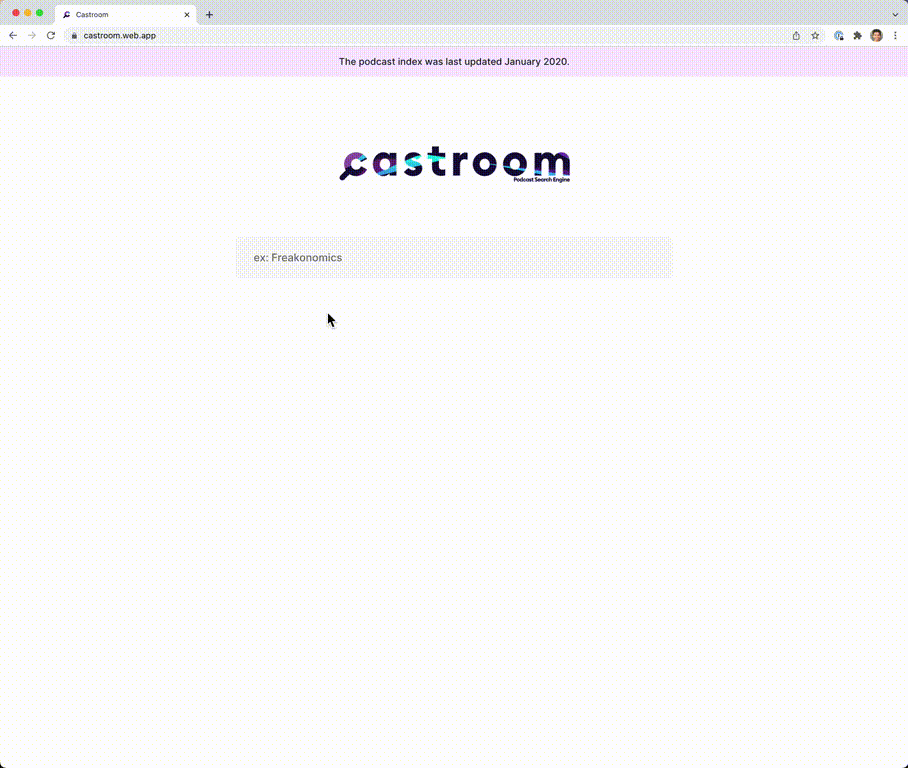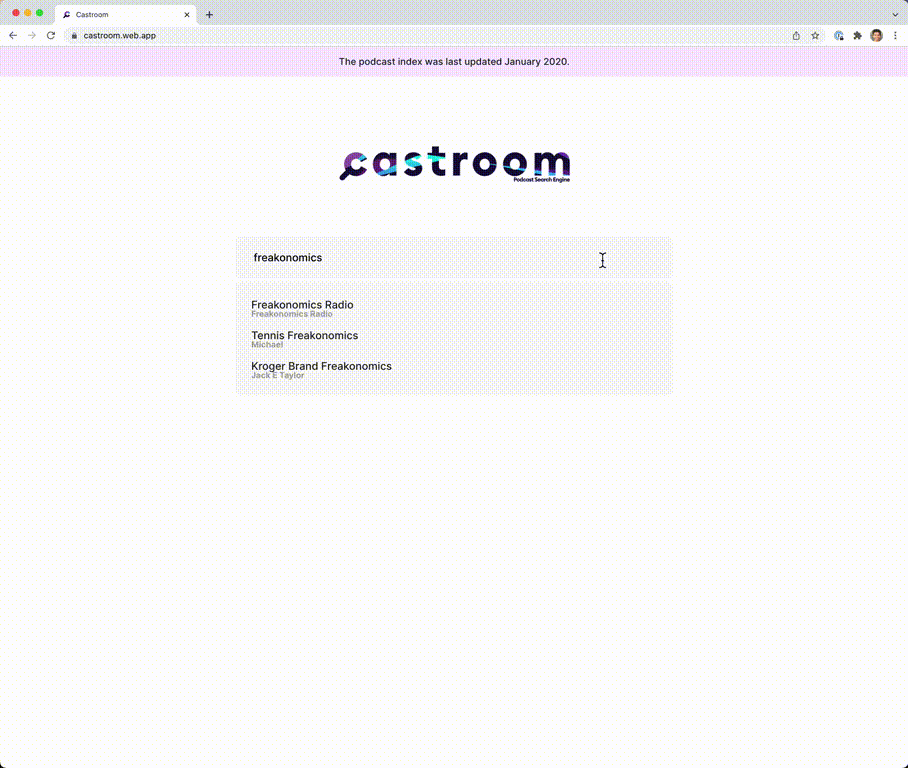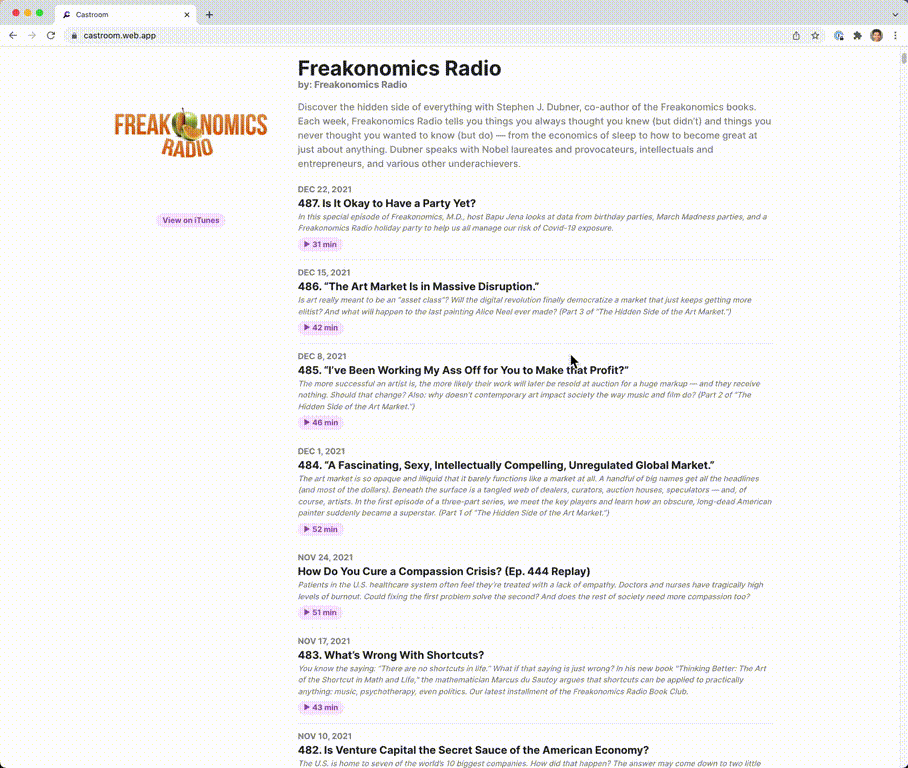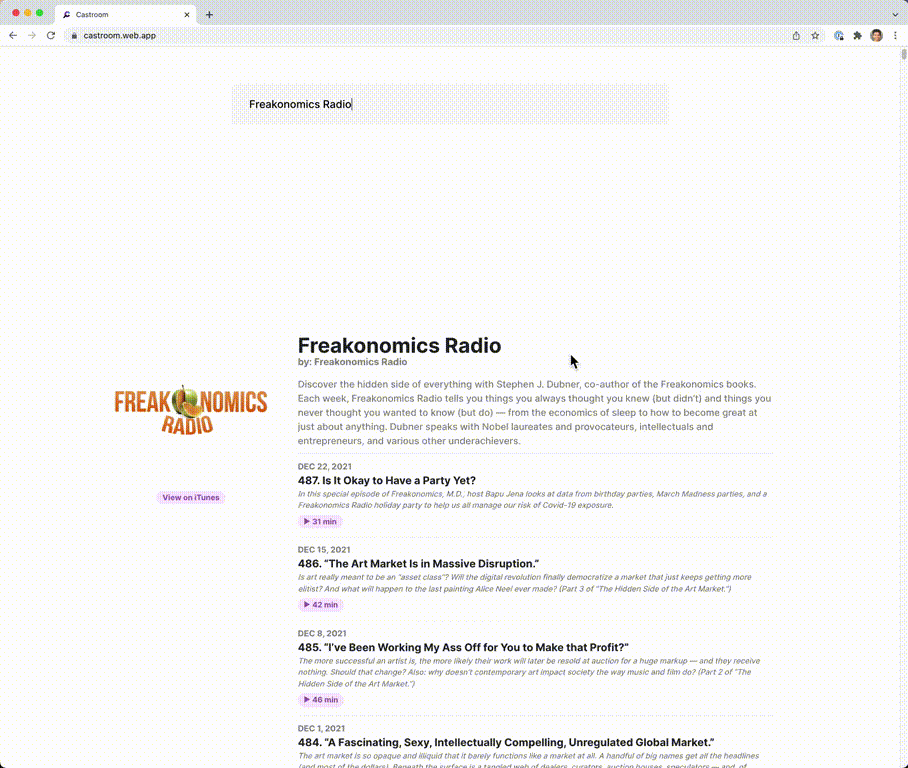
Castroom is a podcast search engine. It was primarily made to learn how to make a distributed web crawler using Kubernetes. It is capable of gathering hundreds of thousands of podcasts within a few hours, and can easily be scaled up even more with one simple command.
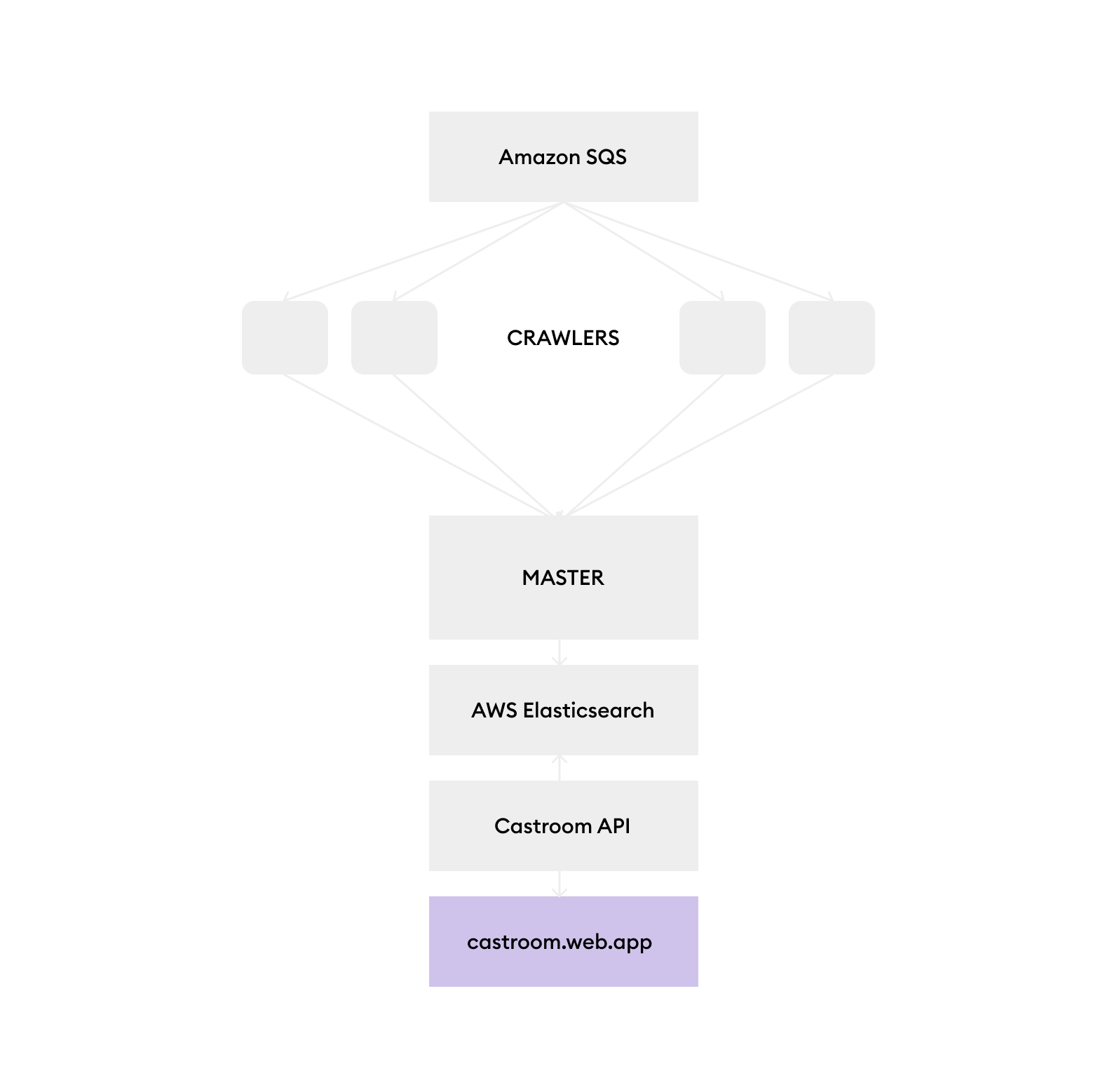
- coordinates all the
crawlerjobs - maintains a local cache (using LevelDB) to prevent the same URL from being crawled multiple times
- receives data from the
crawlernodes and pushes to the queue - the
crawlernodes send all data to this node after crawling a website - send the data to ElasticSearch on completion
- managed by Google Kubernetes Engine
- crawls iTunes podcast pages and sends batched data to the
masternode for caching - goes through a proxy to bypass certain restrictions
- managed by Google Kubernetes Engine
- provides endpoints for querying Elasticsearch and retrieving podcast Feed information
- hosted on Heroku
- frontend for the search engine
- managed by Firebase Hosting
- Docker
- Google Kubernetes Engine
- Amazon Simple Queue Service
- Amazon Elasticsearch Service
- Heroku
- Firebase Hosting
- React
- Node.js
- LevelDB
- Datadog