Home
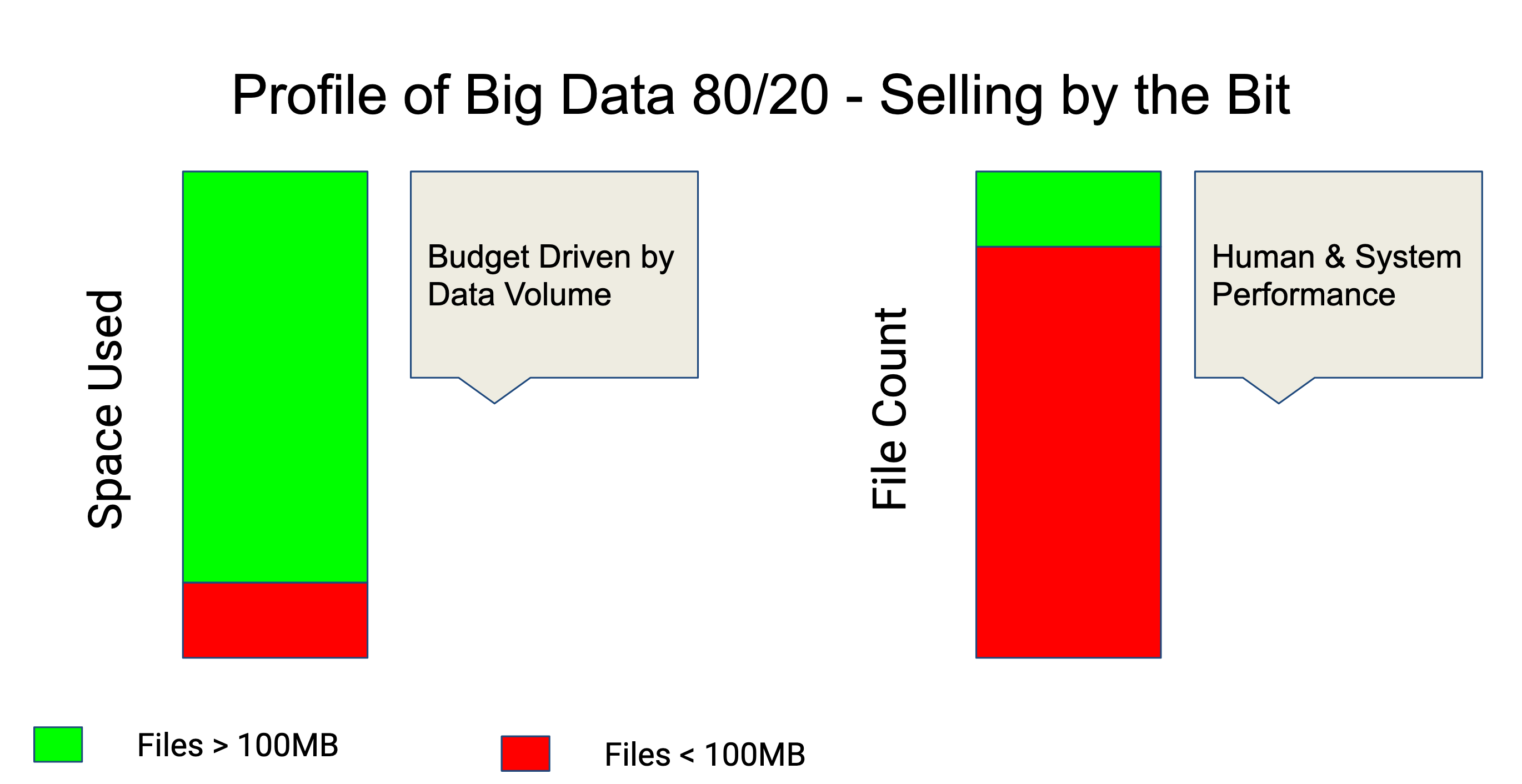
Data follows and 80/20 rule, 20% of files hold 80% of data. Many storage services sell by the total data stored, but many lower cost offerings such as HPSS, AWS Glacier, etc. are very sensitive to file (object) count. Thus projects with 1M small source files, and 100 huge data files (video, 4k images, NetCDF etc) have the worse case of large data volumes and large number of files.
The goal of archivetar is to reduce the file count drastically but not waste time reading large data files that are acceptable for these systems in their current format.
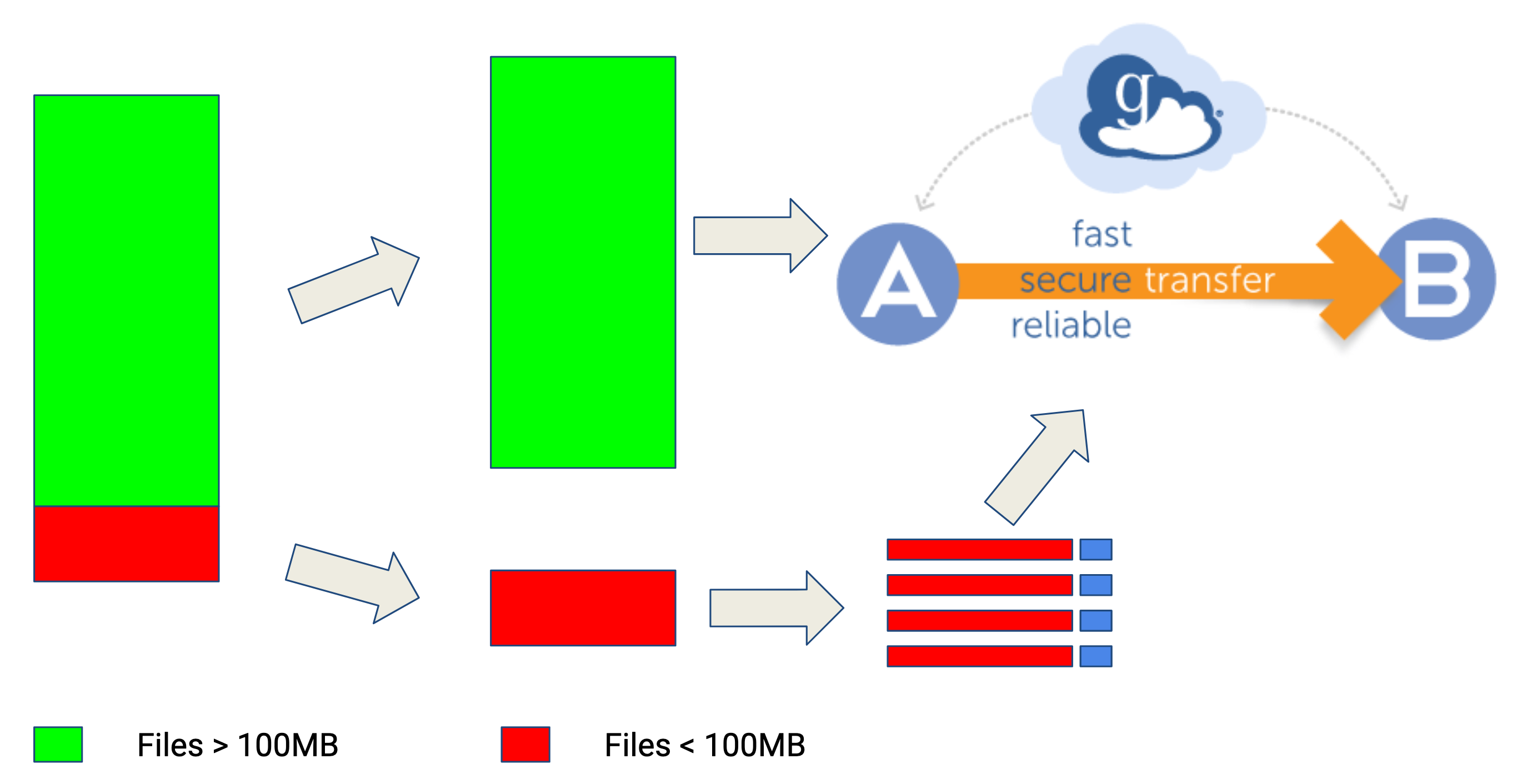
- Sort files into small and large
- Optionally Start uploading large files
- Sort small files into multiple tars of target size
- Tar small file lists in parallel
- Upload tars as they complete
- Optionally delete small files