A music streaming company, Sparkify, has decided that it is time to introduce more automation and monitoring to their data warehouse ETL pipelines and come to the conclusion that the best tool to achieve this is Apache Airflow.
The source data resides in S3 and needs to be processed in Sparkify's data warehouse in Amazon Redshift. The source datasets consist of JSON logs that tell about user activity in the application and JSON metadata about the songs the users listen to.

airflow-data-pipeline
│ README.md # Project description
│ docker-compose.yml # Airflow containers description
│ requirements.txt # Python dependencies
| dag.png # Pipeline DAG image
│
└───airflow # Airflow home
| |
│ └───dags # Jupyter notebooks
│ | │ s3_to_redshift_dag.py # DAG definition
| | |
| └───plugins
│ │
| └───helpers
| | | sql_queries.py # All sql queries needed
| |
| └───operators
| | | data_quality.py # DataQualityOperator
| | | load_dimension.py # LoadDimensionOperator
| | | load_fact.py # LoadFactOperator
| | | stage_redshift.py # StageToRedshiftOperator
- Install Python3
- Install Docker
- Install Docker Compose
- AWS account and Redshift cluster
git clone https://github.com/brfulu/airflow-data-pipeline.git
cd airflow-data-pipeline
python3 -m venv venv # create virtualenv
source venv/bin/activate # activate virtualenv
pip install -r requirements.txt # install requirements
Everything is configured in the docker-compose.yml file. If you are satisfied with the default configurations you can just start the containers.
docker-compose up
Go to http://localhost:8080
Username: user
Password: password
-
Click on the Admin tab and select Connections.
-
Under Connections, select Create.
-
On the create connection page, enter the following values:
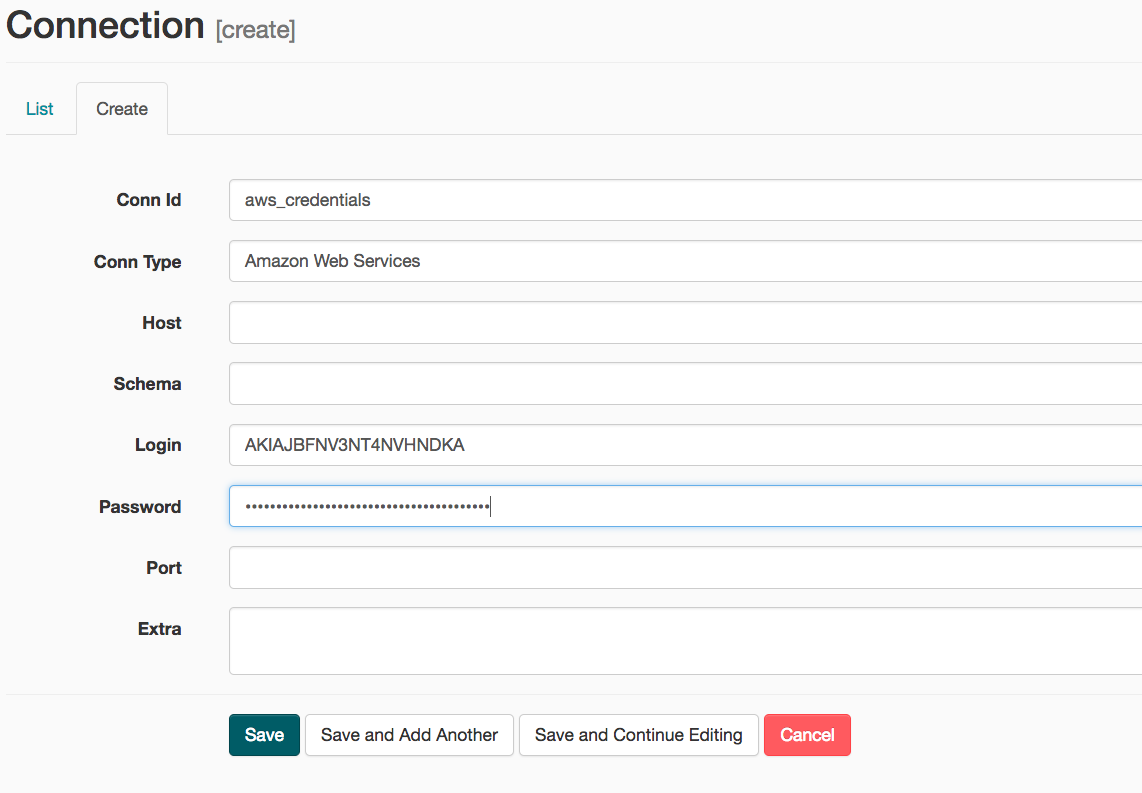
- Conn Id: Enter aws_credentials.
- Conn Type: Enter Amazon Web Services.
- Login: Enter your Access key ID from the IAM User credentials.
- Password: Enter your Secret access key from the IAM User credentials.
Once you've entered these values, select Save and Add Another.
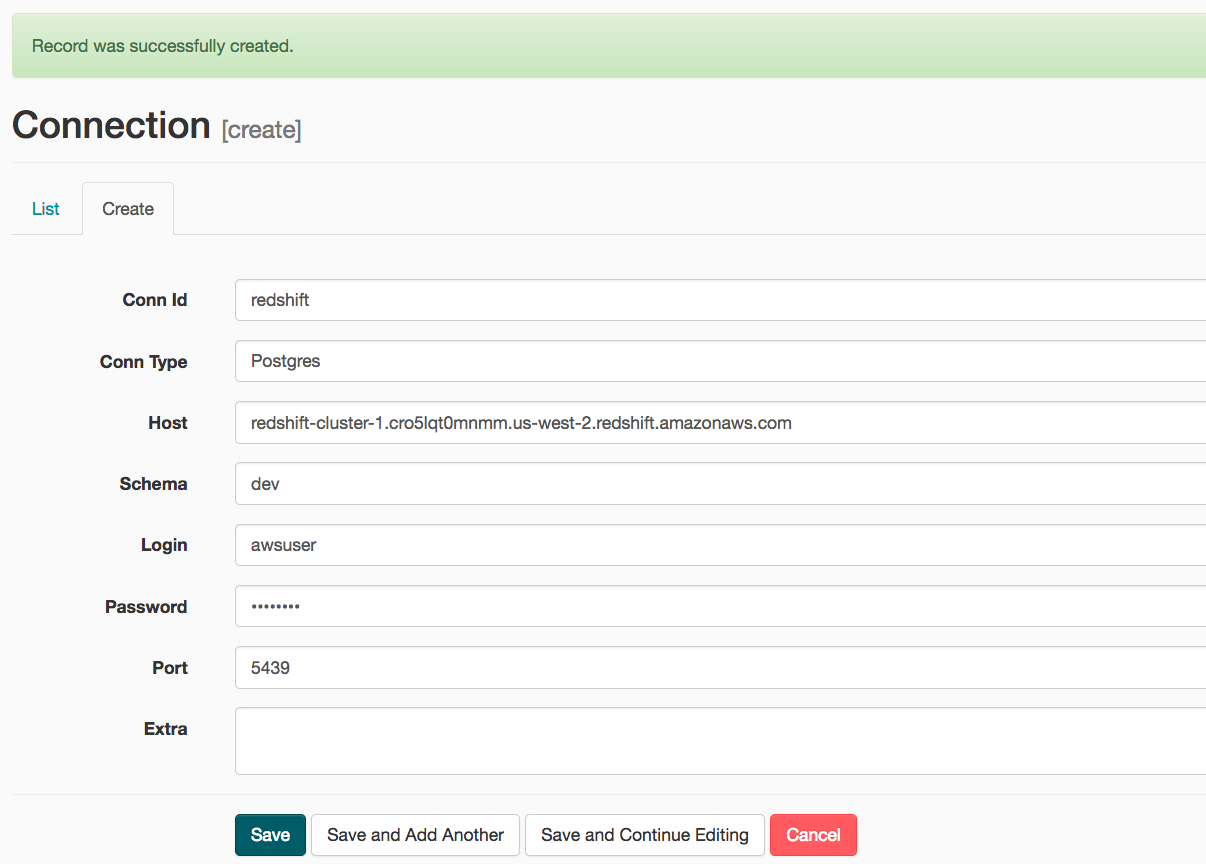
- On the next create connection page, enter the following values:
- Conn Id: Enter redshift.
- Conn Type: Enter Postgres.
- Host: Enter the endpoint of your Redshift cluster, excluding the port at the end.
- Schema: Enter dev. This is the Redshift database you want to connect to.
- Login: Enter awsuser.
- Password: Enter the password you created when launching your Redshift cluster.
- Port: Enter 5439.
Once you've entered these values, select Save.
Start the DAG by switching it state from OFF to ON.
Refresh the page and click on the s3_to_redshift_dag to view the current state.
The whole pipeline should take around 10 minutes to complete.
