Design Machine Translation Engine for Vietnamese using Transformer Architecture from paper Attention Is All You Need. Give us a star if you like this repo.
Model Explanation:
- Slide:
- Transformer Encoder: Check out here
- Transformer Decoder (Updating)
Author:
- Github: bangoc123
- Email: protonxai@gmail.com
This library belongs to our project: Papers-Videos-Code where we will implement AI SOTA papers and publish all source code. Additionally, videos to explain these models will be uploaded to ProtonX Youtube channels.
Architecture:
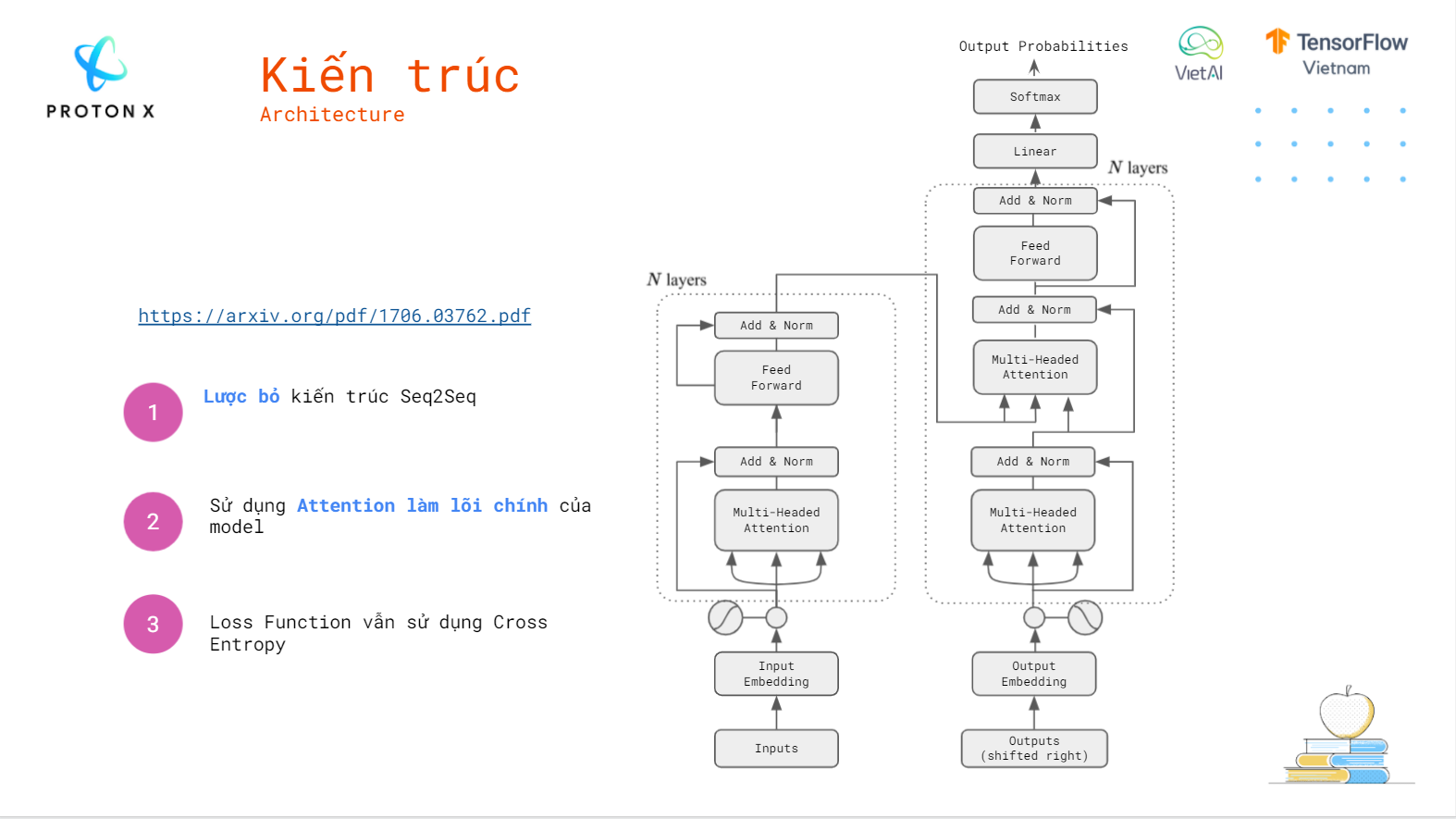
[Note] You can use your data to train this model.
-
Make sure you have installed Miniconda. If not yet, see the setup document here.
-
cdintotransformerand use command lineconda env create -f environment.ymlto set up the environment -
Run conda environment using the command
conda activate transformer
Design train dataset with 2 files:
- train.en
- train.vi
For example:
| train.en | train.vi |
|---|---|
| I love you | Tôi yêu bạn |
| ... | .... |
You can see mocking data in ./data/mock folder.
Training script:
python train.py --epochs ${epochs} --input-lang en --target-lang vi --input-path ${path_to_en_text_file} --target-path ${path_to_vi_text_file}Example: You want to build English-Vietnamese machine translation in 10 epochs
python train.py --epochs 10 --input-lang en --target-lang vi --input-path ./data/mock/train.en --target-path ./data/mock/train.viThere are some important arguments for the script you should consider when running it:
input-lang: The name of the input language (E.g. en)target-lang: The name of the target language (E.g. vi)input-path: The path of the input text file (E.g. ./data/mock/train.en)target-path: The path of the output text file (E.g. ./data/mock/train.vi)model-folder: Saved model pathvocab-folder: Saved tokenizer + vocab pathbatch-size: The batch size of the datasetmax-length: The maximum length of a sentence you want to keep when preprocessingnum-examples: The number of lines you want to train. It was set small if you want to experiment with this library quickly.d-model: The dimension of linear projection for all sentence. It was mentioned in Section3.2.2on the page 5n: The number of Encoder/Decoder Layers. Transformer-Base sets it to 6.h: The number of Multi-Head Attention. Transformer-Base sets it to 6.d-ff: The hidden size of Position-wise Feed-Forward Networks. It was mentioned in Section3.3activation: The activation of Position-wise Feed-Forward Networks. If we want to experimentGELUinstead ofRELU, which activation was wisely used recently.dropout-rate. Dropout rate of any Layer. Transformer-Base sets it to 0.1eps. Layer Norm parameter. Default value: 0.1
After training successfully, your model will be saved to model-folder defined before
-
Bugs Fix:In this project, you can see that we try to compile all the pipeline into
tf.keras.Modelclass inmodel.pyfile and usingfit functionto train the model. Unfortunately, there are few critical bugs we need to fix for a new release.- Fix exporting model using save_weights API. (Currently, the system is unable to reload checkpoint for some unknown reasons.)
-
New Features:
Reading files Pipeline (Release Time: 06/07/2021)- Adapting BPE, Subwords Tokenizer (Release Time: Updating...)
- Use Beam Search for better-generating words (Release Time: Updating...)
- Set up Typing weights mode (Release Time: Updating...)
When you want to modify the model, you need to run the test to make sure your change does not affect the whole system.
In the ./transformer folder please run:
pytestIf you have any issues when using this library, please let us know via the issues submission tab.