Unstructured data like doc, pdf, ePub is lengthy to search and filter for desired information. We need to go through every file manually for finding information. It is very time consuming and frustrating. It doesnt need to be done this way if we can use high computing power to achieve much faster content retrieval.
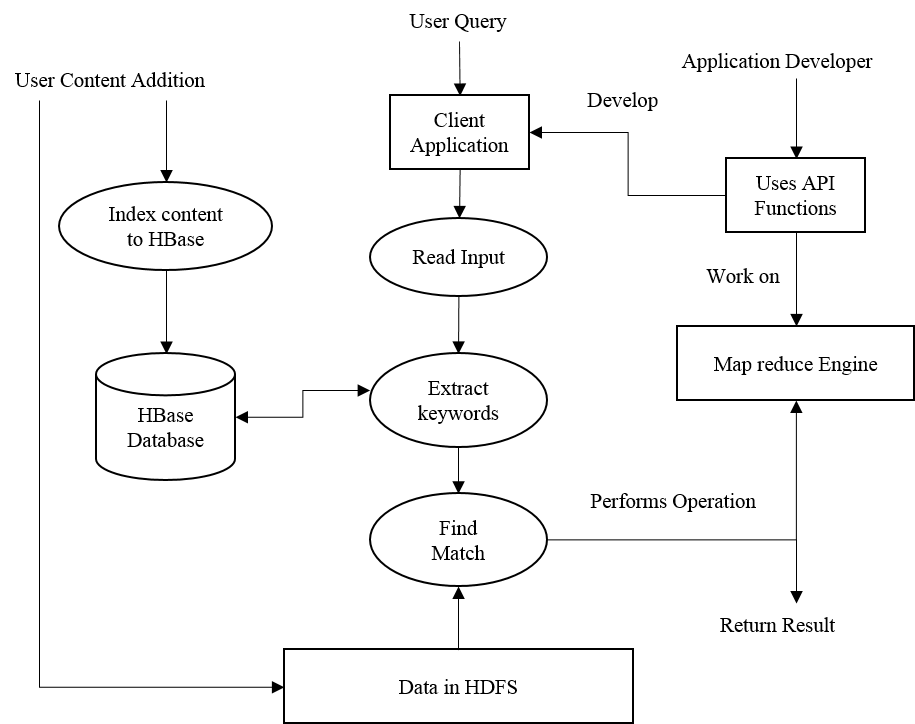
We can use features of big data management system like Hadoop to organize unstructured data dynamically and return desired information. Hadoop provides features like Map Reduce, HDFS, HBase to filter data as per user input. Finally we can develop Hadoop Addon for content search and filtering on unstructured data. This addon will be able to provide APIs for different search results and able to download full file, part of files which are actually related to that topic. This Addon can be used by other industries and government authorities to use Hadoop for their data retrieval as per their requirement.
Current Systems Focus on Search by Title, Author, etc. Which Is time consuming and finding relevant content from those documents is tedious task. So there is a need of such a system which shall find the relevant con tents to the end user.
Here objective is to find the relevant content from the huge number of PDF files present on Hadoop Distributed File System (HDFS)
Refer doc for detail documentation

If you want to contribute, please read the contribution guidelines.