Creates a decryption of a Vigenere cipher using statistical methods.
A vigenere cipher is way of encoding and decoding using polyalphabetic substitution. The wikipedia page for it explains the base concept fairly well: https://en.wikipedia.org/wiki/Vigen%C3%A8re_cipher.
There are two way to decrypt in this program:
System.out.println(DecryptUnknownKeyLength.decryptForAllKeys(encryptedInput, Language.FRENCH));And
DecryptUnknownLanguage.decryptUnknownLanguage(encryptedInput);The first method is excellent if you already know the language (aka much faster).
This program supports decryption in several languages: English, French, German, Dutch, Danish, Portuguese, Spanish, and Italian. These languages can only be decrypted if they were encrypted using just the 26 letters of the English alphabet.
A typical single substitution cipher (Caesar Cipher) can be easily broken using a statistical analysis of the alphabet. The idea is to test each shift of the key; the key whose decryption has alphabet frequencies which closely match that of English (or desired language), that key is the answer. This simple analysis is done using the chi-squared formula.
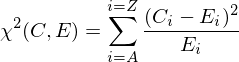
The "C" stands for the actual count of a certain letter in the encrypted string. The "E" stands for the expected frequency of the letter. For instance, if there are 100 characters in the encrypted string and the theoretical frequency (0-1) of the letter is .167, then "E" would be 16.7. In essense, the chi square formula is checking the amount of error in letter frequency (real - theoretical) as a pecentage of the theoretical frequency. The shift that produces the lowest sum is the correct key value. Read more about it here: Chi Sqaured Explanation
The Vigenere cipher is harder to crack than the Caesar cipher. The longer key ensures a more flat distribution of letters which makes it impervious to an pure chi-squred attack. The graph below demonstrates this concept with the right graph (Vigenere Cipher) having a flatter distribution then the left graph (Caesar Cipher).
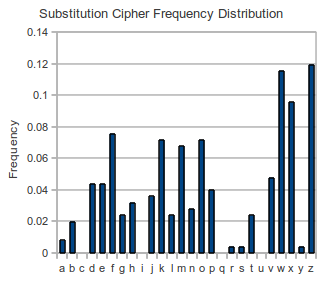
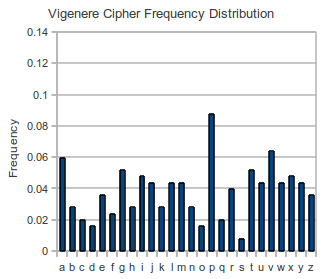
In order to break the Vigenere cipher, the cipher must be broken into smaller substrings. These substrings have a normal distribution which can then be attacked with the Chi-squared formula. The number of substrings is determined by the key length. For example, a key length of 5 is broken into 5 substrings. I used a combination of two methods to find the key length.
The index of coincidence is a good way to estimate the key length. The index of coincidence desecribes the probability that two letters are alike. For a Vignere cipher, that probablity is lower across the entire string. But when the substrings are tested for each key length, the key length where the average index of coincidence for each substring is near 0.067 is likely the correct key length.
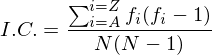
There is a variation on the index of coincidence to provide a close estimate of the actual key. This method works best when the key is short. The reason this method was used vs a pure index of coincidence is that it doesn't require several calulations across several key lengths. It uses the index of coincidence for the entire string. The equation used is shown below:

The answer of the Friedman method must be further refined in order to consistently and currently find the key length. The way this program accomplishes that task is by using the twist method. It starts out with a twist of C:

The c is the frequency of each letter and is from 0-1. These frequencies are ordered, split in half, and each half is summed. The smaller sum is subtracted from the larger sum. The smaller the twist, the flatter the frequency. This twist is done for each substring and the twists are summed for each key length.

The M is the encoded message and m is the key length attempt. The idea is to find where the value m where T is at its maximum. The problem with this base method is that it does provide a way to determine the key length vs its multiples. For example, 5 is the key length but m=10 has a higher T value. Therefore, an improvement on the method called twist plus was used in this program. It looks for the key length that is preceeded by the greatest increase.


The m that has the greatest twist plus answer is generally the key length.