Sparse set #80
Sparse set #80
Conversation
|
Adding a separate set implementation (akin to |
There was a problem hiding this comment.
Thank you very much for working on this. This is a welcome addition & the implementation looks excellent! 💙
I did a very quick review pass to get things moving; a full review will follow later.
Naming is tricky as usual -- as presented, this implements a dictionary interface, so calling it a set feels weird.
I don't feel SparseSet has anywhere near the same brand recognition as Deque (and I weakly regret going with that name anyway), so I think we should feel free to ignore the status quo and select a name that makes the most sense.
I can think of two possible directions we can go with this: (there may be more -- my imagination is severely limited 😉)
- Keep the dictionary-like API and call the type something like
SparseDictionaryorSparseMap. - Change the API to work more like a set, and keep the
SparseSetname. To make this work as a set, we could constrain theElementtype to something likewhere Element: Identifiable, Element.ID: FixedWidthInteger.
Given that I expect (hope) people wouldn't typically pass around sparse sets, high-level set operations (union, intersection, symmetricDifference etc) seem less important to provide than they were OrderedSet. So the current dictionary-based API seems the right approach to me.
(Note: I have a weird personal hangup about the "sparse" qualifier -- it misleads me into thinking the representation might be space efficient, like is usually the case with, say, sparse matrices. But sparse sets are the opposite of space efficient! 😝 However, this is easy enough to get over, and "sparse" does paint the right picture. Unlike deque, it isn't a shibboleth, either.)
| public var keys: ContiguousArray<Key> { | ||
| _dense._keys |
There was a problem hiding this comment.
ContiguousArray makes a pretty good storage type, but I think it'd be more useful for public properties like this to traffic in regular Array types instead, converting from ContiguousArray as needed. (The conversion from a ContiguousArray to Array is an O(1) operation.)
| public var keys: ContiguousArray<Key> { | |
| _dense._keys | |
| public var keys: [Key] { | |
| Array(_dense._keys) |
(This applies to every public API that takes or returns a ContiguousArray.)
There was a problem hiding this comment.
Yup makes sense. I did wonder why Array was being returned instead of ContiguousArray elsewhere.
There was a problem hiding this comment.
Changes made in in 91b0863
| /// - Complexity: O(1) | ||
| @inlinable | ||
| @inline(__always) | ||
| public var universeSize: Int { _sparse.capacity } |
There was a problem hiding this comment.
Would it make sense to just call this capacity?
There was a problem hiding this comment.
Universe size seems like a completely different thing than capacity. In LLVM's implementation, universe size is actually a template parameter and is the static size of the sparse key array. The dense value vector is dynamically sized and I would usually think of capacity in terms of that.
There was a problem hiding this comment.
Like @milseman says we have two parameters: universeSize which is the size of the sparse storage and capacity which I think of as the the size of the dense storage.
In the current implementation we have an initializer init(minimumCapacity: Int, universeSize: Int? = nil) where we can specify both. If adding a key greater than or equal to universeSize then the sparse storage is resized to accommodate it. Dense storage is backed by ContiguousArray so will increase on size dynamically as needed. universeSize is just a read-only property but it might be useful to add the ability to change the universe size manually after creation.
At the moment there is no capacity property or reserveCapacity(_ minimumCapacity: Int) function but maybe we should add those and / or something like reserveCapacity(_ minimumCapacity: Int, minimumUniverseSize: Int).
In any case we should mention the difference in the documentation as its a possible source of confusion.
There was a problem hiding this comment.
OK, if y'all think universeSize is the right term, then let's go with that!
I don't think we'd want to expose the dense array's capacity as a public property -- it exposes unstable information about allocation behavior, and I think making it public in the stdlib was a mistake that I'd prefer not to emulate in this package.
There is no such issue with reserveCapacity; adding it would probably be a good idea!
| makingHeaderWith: { _ in | ||
| Header(capacity: capacity) | ||
| }) | ||
| newBuffer.withUnsafeMutablePointerToElements { ptr in |
There was a problem hiding this comment.
IIUC this leaves unoccupied positions in the sparse storage uninitialized, which I understand is very deliberate (and desirable), but it could run afoul of runtime analyzers. LLVM decided to fully initialize its sparse buffer for this reason -- we may want to do the same. (Or perhaps make it a package configuration parameter.)
How much worse things would get if we filled this buffer with zeroes by default?
There was a problem hiding this comment.
Yes, the unoccupied positions of the sparse storage are uninitialized for better performance. If we filled the buffer with zeroes then initialization, resizing and copying (COW) operations will be slower. This might not matter much in practice though if users aren't performing these operations frequently.
What do you mean by a package configuration parameter?
There was a problem hiding this comment.
What do you mean by a package configuration parameter?
Oh, I meant a compile-time conditional that we could use in #if statements, like the existing COLLECTIONS_INTERNAL_CHECKS one.
There was a problem hiding this comment.
Just adding a note here in case I forget:
If we are going to be fully initializing the sparse storage then there's a minor optimization we can consider for lookup operations. Details here
|
@swift-ci test |
Not only you I can say, I was actually surprised that it was not :-) ! Googles hash implementation "sparsehash" was exactly space efficient (and fast) while "densehash" was faster (and space inefficient). |
|
Hello, I'm the original author of LLVM's SparseMultiSet and I've always wanted this functionality presented in Swift, but there's some design challenges I'm sure you're facing. I haven't thought about this in years and some of my knowledge might be out of date, but hopefully I can help. LLVM's implementation allows specification of a functor to map keys to the natural numbers, which IIRC was actually a template parameter. Have you thought about how to provide this kind of customization? LLVM's implementation allows specification of the bit-width of the sparse array members, using striding to access elements from the dense vector. E.g. For SparseMultiSet, I went ahead and made the dense vector a kind of custom allocator, since it naturally tended towards building up an in-line free list. But I haven't thought about how that would play out for Swift, which is pickier about uninitialized-yet-stored values. What were you thoughts here? What protocols should we be conforming to? Collection or SetAlgebra? Something more fundamental? IIRC, deletions violating insertion order was a minor (and useful) optimization in LLVM's implementation. But there are many potential ways of performing deletions. Have you thought about preserving insertion order? |
Thanks for the insights, lots to think about for sure. My C++ knowledge is fairly basic so I don't understand too much of the details of the LLVM implementations of SparseSet and SparseMultiSet - please correct me if I've misunderstood your points.
We could constrain the key type (for a dictionary-like implementation) or the element (for a set-like implementation) with protocols. E.g. protocol IntConvertible: Equatable {
var intValue: Int { get }
init(_ value: Int)
}
protocol IndexIdentifiable {
associatedtype IndexType: IntConvertible
var indexId: IndexType { get }
}
struct SparseSet<Element: IndexIdentifiable> {}
struct SparseDictionary<Key: IndexIdentifiable, Value> {}or use the existing
This sounds like a good thing to add.
Sorry, I don't have enough knowledge in this area to give any insights.
The same as
I was under the impression that deletion by filling the gap with the final element is rather fundamental for iteration performance - as opposed to being a minor optimization. What other deletion techniques were considered in LLVM for SparseSet? Could you explain a bit about how iterations and deletions are handled in LLVM's SparseMultiSet? It looks like the dense storage slots contain value data as well as previous and next indices to implement a doubly linked list (or a doubly linked list for each key?). Doing a similar thing for SparseSet could preserve ordering upon deletion but would be impact iteration performance somewhat I guess. I notice that I was thinking we should refine a sparse set implementation before looking into sparse multi set. Is this a good strategy or are there details of sparse multi set that you think we should be considering as they might impact our implementation of sparse set? |
Adding a protocol is a Big Deal -- we can do it if it makes sense to do so, but there must be a really, really good reason for it. In this case, it seems to me we might be able to get away with simply requiring Element to be something like |
|
Ah, I thought that might be the case - we can probably use It does seem like a bigger usability obstacle compared to the other existing collections though. For example let a: OrderedSet<UInt16> = [1, 2, 3, 4] // OK
let b: SparseSet<UInt16> = [1, 2, 3, 4] // Invalid |
|
It seems to me
|
|
Yes, other data structures are probably more suitable than (I wasn't suggesting that |
More specifically, we're interested in types that map to the natural numbers with a known max universe size. We can probably support universe sizes determined at runtime without much issue. I'm not sure what advantages a statically known universe size would give us, except perhaps allowing us different representations to choose from for e.g. small universes. It might be the case that one type could conform in multiple ways, depending on application/domain. IIRC the C++ template parameter is just the mapping function. But, if we make people define wrapper types if they want the non-default mapping for a type, that's not too crazy either.
Probably not, or at least it doesn't seem sufficient for me. If the
Yup, those are very useful properties. Clear is just It might be interesting to store the keys separately from the values in the dense vector, to increase value density. But I've never explored those kinds of ideas (perhaps @lorentey knows the tradeoffs). |
LLVM's SparseSet is a pretty specialized data structure, and SparseMultiSet even more so. A key lookup gives you an iterator which can be used to traverse and update the values for that key (but not values for other keys). Values for all keys are stored flat in the dense vector, but they have a prev/next index to represent the chaining. IIRC it's circular backwards but terminated forwards, because getting to the back from the front is very common (push/pop, etc). Removing a value from that list effectively updates the The value becomes a tombstone and the new head of the free list (which is singly linked). I recall there being good reasons for not swapping with the last element, but I don't recall what they all were precisely. Off the top of my head, it is considerably more complex to swap with the last element, since that element might be part of a different key's chain, meaning you're unlinking and relinking from multiple chains. This would cause an invalidation of iterators derived from unrelated keys (even a seemingly read-only use of an iterator), which would be surprising and is probably the main reason for the free list. SMS is effectively a replacement for I think there's also strong perf reasons in practice. Common programming patterns might have lots of little erase/inserts. Since new tombstones are the new head of the free list, we're reusing the same slots with minimal bookkeeping and without touching more cache lines. Even ignoring that, skipping the extra bookkeeping that SMS requires to move an entry in the dense vector adds up. Iteration in a multi-set is iteration over the values for a given key. While we might suffer from less density in to the presence of tombstones, normal iteration never directly encounters one. If you wanted to iterate over all values, regardless of keys, it's still very fast to skip over tombstones (common strategy in LLVM data structures) and probably still the better choice for performance vs doing extra bookkeeping on every removal. SMS could totally support an explicit garbage-collect operation that would in one pass remove all the tombstones and update relevant book-keeping for any swapped values (probably more efficiently all at once than amortized too). This would improve iteration over all stored values and improve density, depending on how many tombstones there were. I don't believe this functionality was ever needed in practice. |
|
|
||
| @inlinable | ||
| @discardableResult | ||
| internal mutating func removeLast() -> (key: Key, value: Value) { |
There was a problem hiding this comment.
Could be internal mutating func removeLast() -> SparseSet.Element
| @inlinable | ||
| public init<S: Sequence>( | ||
| uniqueKeysWithValues keysAndValues: S | ||
| ) where S.Element == (key: Key, value: Value) { |
There was a problem hiding this comment.
Could be where S.Element == SparseSet.Element as well
Description
Adds a sparse set data structure as suggested in issue #24
Detailed Design
A sparse set is a data structure which represents a set of non-negative integers. Operations such as member, add-member and delete-member are O(1) but this comes at the cost of increased storage space needed. See: An efficient representation for sparse sets (Briggs, Torczon, 1993).
Existing implementations:
There seem to be two implementation approaches:
SparseSet<T>whereTis an (unsigned) integer type. A set-like interface where just integers are stored.SparseSet<Key, Value>whereKeyis an (unsigned) integer type. A dictionary-like interface which can also hold associated values.This is a dictionary-like implementation that closely follows the interface of
OrderedDictionary. Main public interface (see source for symbol documentation).The
keysandvaluesviews, and the multiple subscripts for keys and indices are similar to howOrderedDictionaryis implemented.Compared to
OrderedDictionary:Pros:
Cons:
O(u)whereuis the largest integer key we will be using, plusO(n)wherenis the number of elements in the set. (Roughlyu * MemoryLayout<Key>.stridefor the sparse storage plusn * (MemoryLayout<Key>.stride + MemoryLayout<Value>.stride)for the dense storage.) Typically key types would be:UInt8,UInt16,UInt32.Testing
Tests are included for most code paths.
Performance
Benchmarks are included (
SparseSetBenchmarks), but I haven't updatedLibrary.jsonto include any. Here are some samples I ran:Lookups:
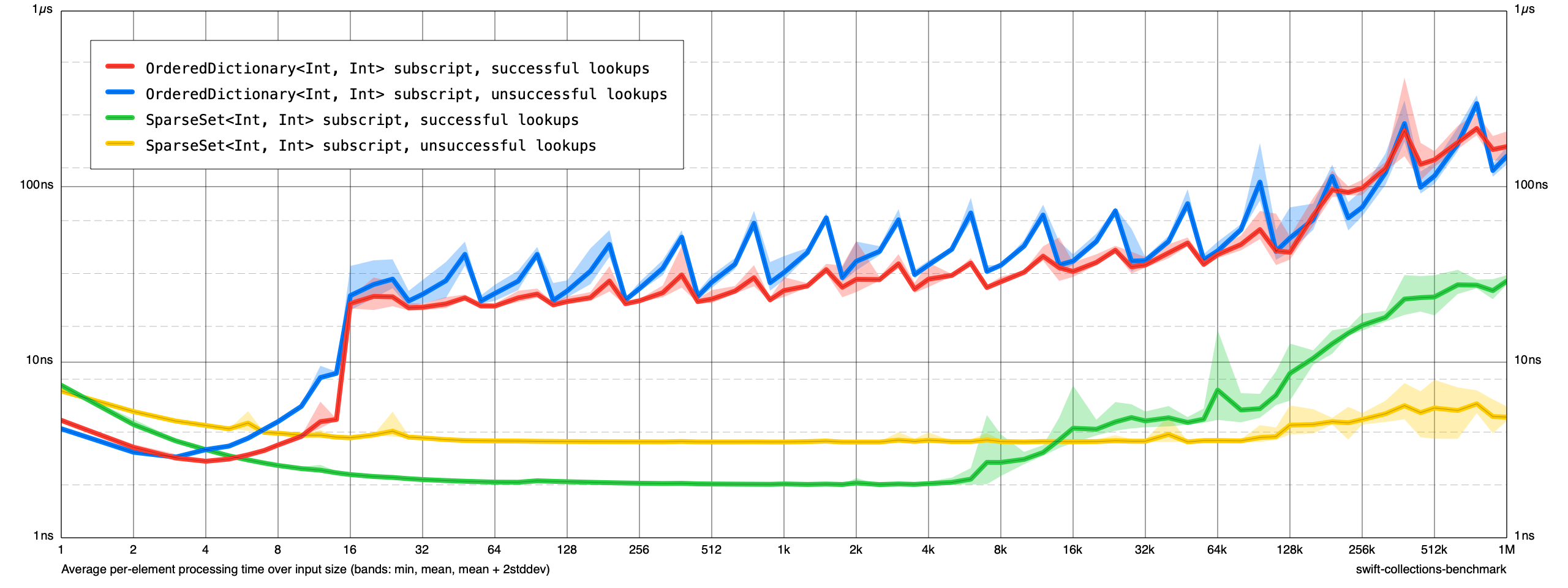
Insertions:
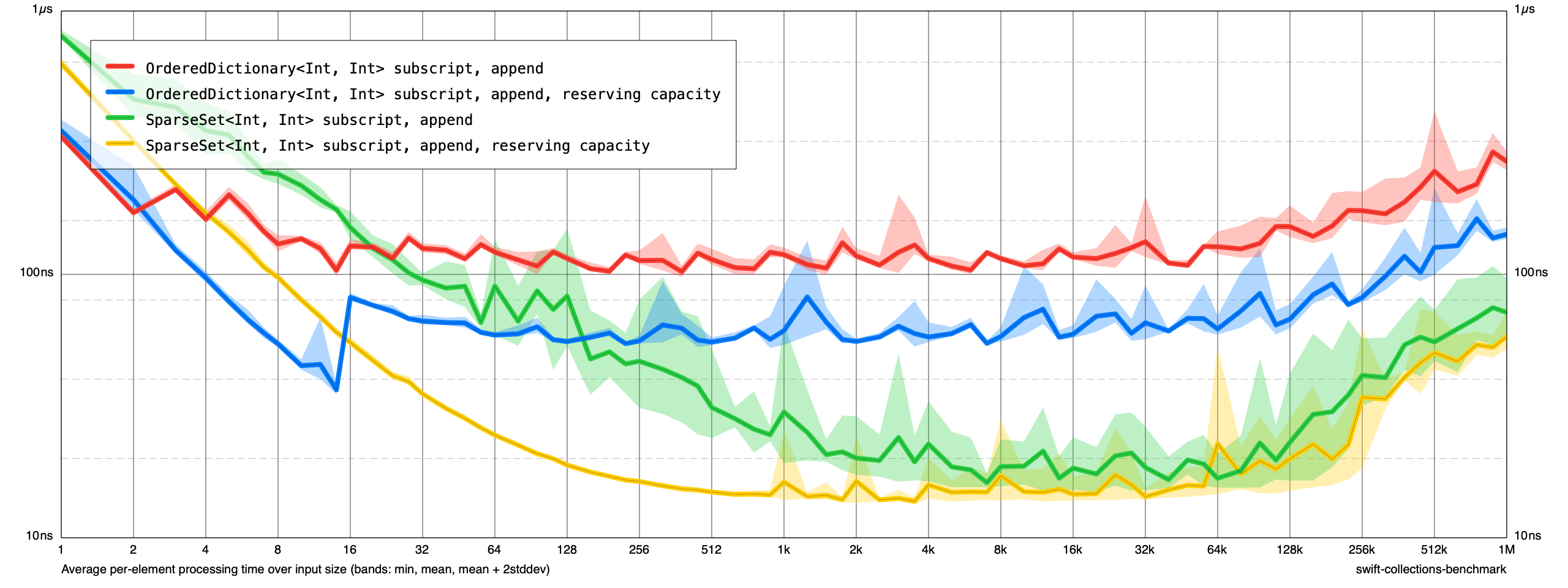
Deletions:
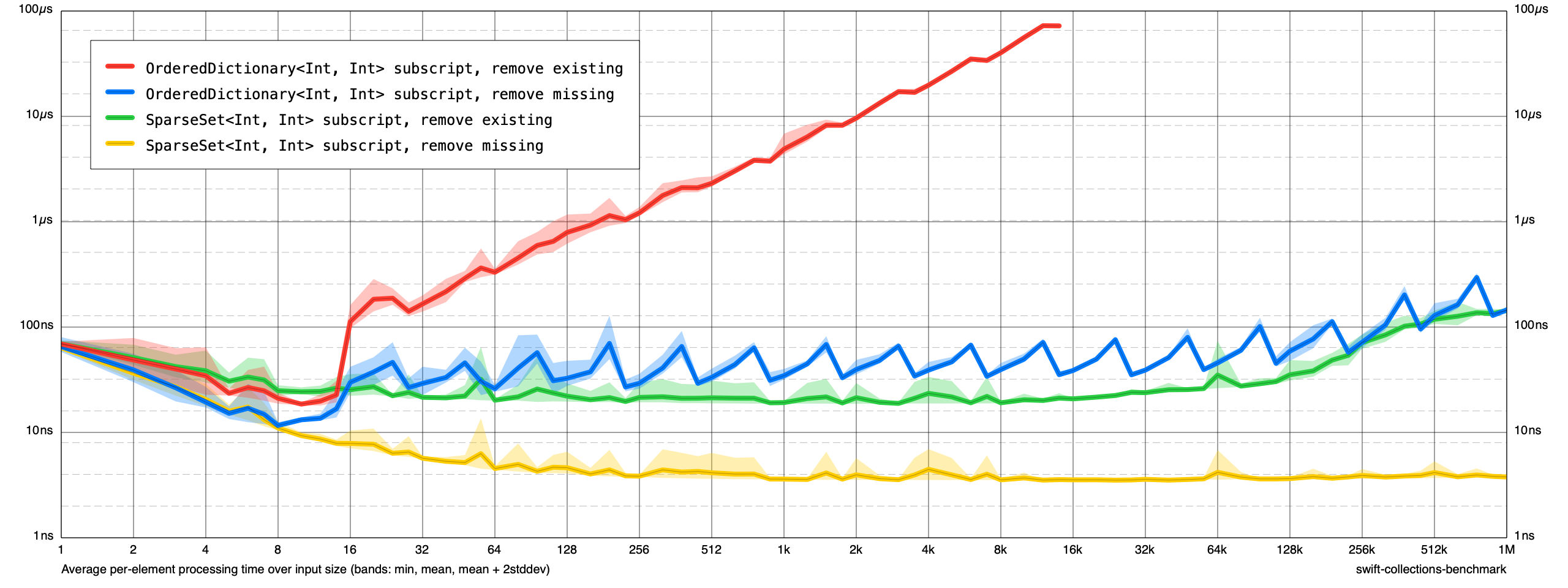
Checklist