AlmaBetter Verfied Project - AlmaBetter School

Developed a regression model using algorithms such as Random Forest and XGBoost to predict the hourly demand of bikes.Performed hyperparameter tuning techniques and achieved R2 score of 92% using XGBoost model and reduced the public waiting time significantly.
This Project includes 2 executable files, 1 text files ,1 h5 file as well as 1 directories as follows:
- Bike_Sharing_Demand_Prediction_Apoorva_KR.ipynb - Includes all functions required for classification operations and generates the model.h5 file after execution.
- final_individual_notebook_Bike_Sharing_Demand_Prediction_Apoorva_KR.ipynb - after execution, evaluation is done on the unseen data as in confusion_matrix.txt.
- model.h5 - Model contains information about the predictions of the train set, continous value.
- result.txt - Contains information about the MSE and adjusted R2 of the test set.
- Dataset - Includes all dataset for the training phase and testing phase of the model in the csv format.

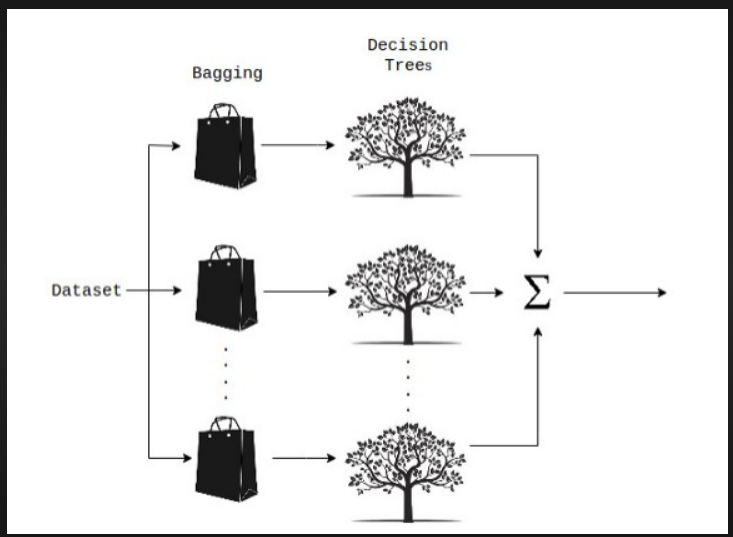
Regression is the other task performed by a random forest algorithm. A random forest regression follows the concept of simple regression. Values of dependent (features) and independent variables are passed in the random forest model.
In a random forest regression, each tree produces a specific prediction. The mean prediction of the individual trees is the output of the regression. This is contrary to random forest classification, whose output is determined by the mode of the decision trees’ class.
Although random forest regression and linear regression follow the same concept, they differ in terms of functions. The function of linear regression is y=bx + c, where y is the dependent variable, x is the independent variable, b is the estimation parameter, and c is a constant. The function of a complex random forest regression is like a blackbox.
XGBoost is a powerful approach for building supervised regression models. The validity of this statement can be inferred by knowing about its (XGBoost) objective function and base learners. The objective function contains loss function and a regularization term. It tells about the difference between actual values and predicted values, i.e how far the model results are from the real values. The most common loss functions in XGBoost for regression problems is reg:linear, and that for binary classification is reg:logistics. Ensemble learning involves training and combining individual models (known as base learners) to get a single prediction, and XGBoost is one of the ensemble learning methods. XGBoost expects to have the base learners which are uniformly bad at the remainder so that when all the predictions are combined, bad predictions cancels out and better one sums up to form final good predictions.
The order of execution of the program files is as follows:
1) final_individual_notebook_Bike_Sharing_Demand_Prediction_Apoorva_KR.ipynb
This file must be executed, to define all the functions and variables required for regression operations which leads to the production of the model.h5 file. and to evaluate the model performance on unseen data
< Apoorva KR > | Avid Learner | Data Scientist | Machine Learning Engineer | Deep Learning enthusiast
Contact me for Data Science Project Collaborations
'Regression Model to Predict Bike Sharing Demand'. [Online].
Available: https://medium.com/@Nivitus./mobile-price-prediction-using-machine-learning-fa9cab6fb242
'Random Forest Regression '. [Online].
Available:https://towardsdatascience.com/random-forest-regression-5f605132d19d /
Youtube.com,'Bike Sharing Demand Analysis (Regression) | Machine Learning | Python'. [Online].
Available: https://www.youtube.com/watch?v=P77bDN7qAlc&t=545s
End to end Case Study: Bike-sharing demand prediction'. [Online].
Available:https://towardsdatascience.com/end-to-end-case-study-bike-sharing-demand-dataset-53201926c8db