[SPARK-48027][SQL] InjectRuntimeFilter for multi-level join should check child join type #46263
Conversation
…eck child join type
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
Outdated
Show resolved
Hide resolved
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
Outdated
Show resolved
Hide resolved
| @@ -120,34 +132,49 @@ object InjectRuntimeFilter extends Rule[LogicalPlan] with PredicateHelper with J | |||
| hasHitSelectiveFilter = hasHitSelectiveFilter || isLikelySelective(condition), | |||
| currentPlan, | |||
| targetKey) | |||
| case ExtractEquiJoinKeys(_, lkeys, rkeys, _, _, left, right, _) => | |||
| case ExtractEquiJoinKeys(joinType, lkeys, rkeys, _, _, left, right, _) => | |||
| // Runtime filters use one side of the [[Join]] to build a set of join key values and prune | |||
| // the other side of the [[Join]]. It's also OK to use a superset of the join key values | |||
| // (ignore null values) to do the pruning. | |||
There was a problem hiding this comment.
I'm glad we described the idea in the comments. It's clear that for certain join types, the join child output is not a superset of the join output for transitive join keys.
| // Runtime filters use one side of the [[Join]] to build a set of join key values and prune | ||
| // the other side of the [[Join]]. It's also OK to use a superset of the join key values | ||
| // (ignore null values) to do the pruning. | ||
| // We assume other rules have already pushed predicates through join if possible. | ||
| // So the predicate references won't pass on anymore. | ||
| if (left.output.exists(_.semanticEquals(targetKey))) { | ||
| extract(left, AttributeSet.empty, hasHitFilter = false, hasHitSelectiveFilter = false, |
There was a problem hiding this comment.
Let's clarify the expected strategy a bit more: For the exact join key match, like the left table here, it's always OK to generate the runtime filter using this left table, no matter what the join type is. This is because left table always produce a superset of output of the join output regarding the left keys.
For transitive join key match, it's different. The right table here does not always generate a superset output regarding left keys. Let's look at an example
left table: 1, 2, 3
right table, 3, 4
left outer join output: (1, null), (2, null), (3, 3)
left keys: 1, 2, 3
So we can't use right table to generate runtime filter.
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
Show resolved
Hide resolved
| hasHitFilter = false, hasHitSelectiveFilter = false, currentPlan = right, | ||
| targetKey = newTargetKey) | ||
| } | ||
| if (canExtractLeft(joinType)) { |
There was a problem hiding this comment.
As I explained at https://github.com/apache/spark/pull/46263/files#r1582495367 , we don't need this check here.
There was a problem hiding this comment.
Extract equi join condition, make sense. the ELSE branch also need to remove canExtractLeft, right?
| } | ||
| } else if (right.output.exists(_.semanticEquals(targetKey))) { | ||
| extract(right, AttributeSet.empty, hasHitFilter = false, hasHitSelectiveFilter = false, | ||
| currentPlan = right, targetKey = targetKey).orElse { | ||
| if (canExtractRight(joinType)) { |
There was a problem hiding this comment.
I think the code is wrong here. We only need this extra check for transitive join keys. In this branch, it's the left table.
There was a problem hiding this comment.
Looks like we can just canPruneLeft and canPruneRight, it's have the same rule
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
Outdated
Show resolved
Hide resolved
…mizer/InjectRuntimeFilter.scala
|
the last commit only changes code comment, merging to master, thanks! |
|
@AngersZhuuuu can you create a backport PR for 3.5? it has conflicts. |
https://issues.apache.org/jira/browse/SPARK-44649 bring this issue, only on branch-4.0, no need to backport to 3.5 |
…eck child join type
### What changes were proposed in this pull request?
In our prod we meet a case
```
with
refund_info as (
select
b_key,
1 as b_type
from default.table_b
),
next_month_time as (
select /*+ broadcast(b, c) */
c_key
,1 as c_time
FROM default.table_c
)
select
a.loan_id
,c.c_time
,b.type
from (
select
a_key
from default.table_a2
union
select
a_key
from default.table_a1
) a
left join refund_info b on a.loan_id = b.loan_id
left join next_month_time c on a.loan_id = c.loan_id
;
```
In this query, it inject table_b as table_c's runtime bloom filter, but table_b join condition is LEFT OUTER, causing table_c missing data.
Caused by
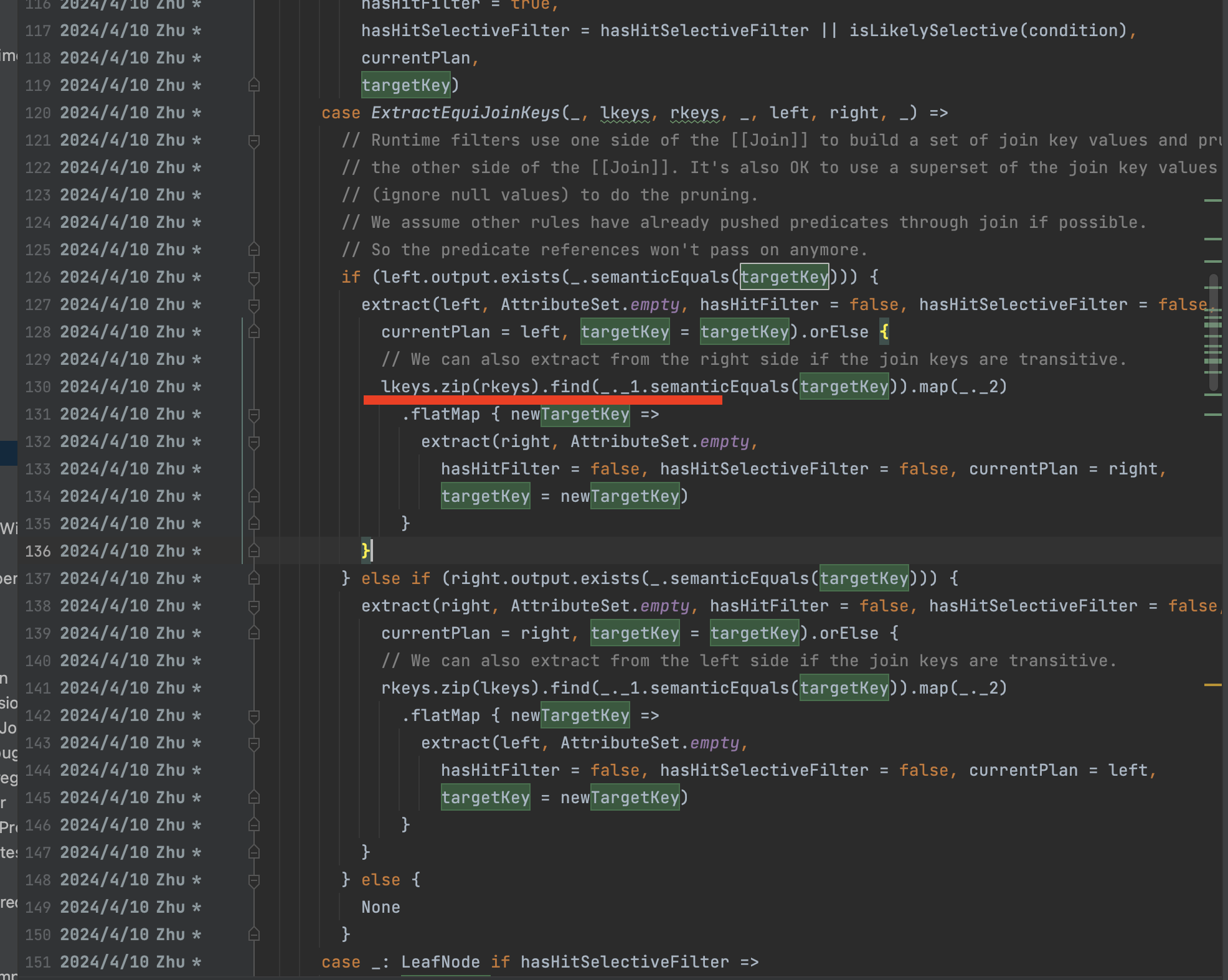
InjectRuntimeFilter.extractSelectiveFilterOverScan(), when handle join, since left plan (a left outer join b's a) is a UNION then the extract result is NONE, then zip left/right keys to extract from join's right, finnaly cause this issue.
### Why are the changes needed?
Fix data correctness issue
### Does this PR introduce _any_ user-facing change?
Yea, fix data incorrect issue
### How was this patch tested?
For the existed PR, it fix the wrong case
Before: It extract a LEFT_ANTI_JOIN's right child to the outside bf3....its not correct
```
Join Inner, (c3#45926 = c1#45914)
:- Join LeftAnti, (c1#45914 = c2#45920)
: :- Filter isnotnull(c1#45914)
: : +- Relation default.bf1[a1#45912,b1#45913,c1#45914,d1#45915,e1#45916,f1#45917] parquet
: +- Project [c2#45920]
: +- Filter ((isnotnull(a2#45918) AND (a2#45918 = 5)) AND isnotnull(c2#45920))
: +- Relation default.bf2[a2#45918,b2#45919,c2#45920,d2#45921,e2#45922,f2#45923] parquet
+- Filter (isnotnull(c3#45926) AND might_contain(scalar-subquery#48719 [], xxhash64(c3#45926, 42)))
: +- Aggregate [bloom_filter_agg(xxhash64(c2#45920, 42), 1000000, 8388608, 0, 0) AS bloomFilter#48718]
: +- Project [c2#45920]
: +- Filter ((isnotnull(a2#45918) AND (a2#45918 = 5)) AND isnotnull(c2#45920))
: +- Relation default.bf2[a2#45918,b2#45919,c2#45920,d2#45921,e2#45922,f2#45923] parquet
+- Relation default.bf3[a3#45924,b3#45925,c3#45926,d3#45927,e3#45928,f3#45929] parquet
```
After:
```
Join Inner, (c3#45926 = c1#45914)
:- Join LeftAnti, (c1#45914 = c2#45920)
: :- Filter isnotnull(c1#45914)
: : +- Relation default.bf1[a1#45912,b1#45913,c1#45914,d1#45915,e1#45916,f1#45917] parquet
: +- Project [c2#45920]
: +- Filter ((isnotnull(a2#45918) AND (a2#45918 = 5)) AND isnotnull(c2#45920))
: +- Relation default.bf2[a2#45918,b2#45919,c2#45920,d2#45921,e2#45922,f2#45923] parquet
+- Filter (isnotnull(c3#45926))
+- Relation default.bf3[a3#45924,b3#45925,c3#45926,d3#45927,e3#45928,f3#45929] parquet
```
### Was this patch authored or co-authored using generative AI tooling?
NO
Closes apache#46263 from AngersZhuuuu/SPARK-48027.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? This PR propose to add comments for the other code branch. ### Why are the changes needed? #46263 missing the comments for the other code branch. ### Does this PR introduce _any_ user-facing change? 'No'. ### How was this patch tested? N/A ### Was this patch authored or co-authored using generative AI tooling? 'No'. Closes #46536 from beliefer/SPARK-48027_followup. Authored-by: beliefer <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
What changes were proposed in this pull request?
In our prod we meet a case
In this query, it inject table_b as table_c's runtime bloom filter, but table_b join condition is LEFT OUTER, causing table_c missing data.
Caused by

InjectRuntimeFilter.extractSelectiveFilterOverScan(), when handle join, since left plan (a left outer join b's a) is a UNION then the extract result is NONE, then zip left/right keys to extract from join's right, finnaly cause this issue.
Why are the changes needed?
Fix data correctness issue
Does this PR introduce any user-facing change?
Yea, fix data incorrect issue
How was this patch tested?
For the existed PR, it fix the wrong case
Before: It extract a LEFT_ANTI_JOIN's right child to the outside bf3....its not correct
After:
Was this patch authored or co-authored using generative AI tooling?
NO