[BEAM-8376] Google Cloud Firestore Connector - Add Firestore V1 Write Operations #14261
Conversation

|
R: @chamikaramj |
.../google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreDoFn.java
Outdated
Show resolved
Hide resolved
.../google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreDoFn.java
Outdated
Show resolved
Hide resolved
...le-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreIOOptions.java
Outdated
Show resolved
Hide resolved
...rm/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreStatefulComponentFactory.java
Outdated
Show resolved
Hide resolved
...io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreV1.java
Outdated
Show resolved
Hide resolved
.../io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/RpcQosImpl.java
Outdated
Show resolved
Hide resolved
.../io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/RpcQosImpl.java
Outdated
Show resolved
Hide resolved
.../google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/RpcQosOptions.java
Outdated
Show resolved
Hide resolved
...-platform/src/test/java/org/apache/beam/sdk/io/gcp/firestore/BaseFirestoreV1WriteFnTest.java
Outdated
Show resolved
Hide resolved
|
|
||
| Write write = FirestoreProtoHelpers.newWrite(); | ||
| BatchWriteRequest expectedRequest = BatchWriteRequest.newBuilder() | ||
| .setDatabase("projects/testing-project/databases/(default)") |
There was a problem hiding this comment.
Does this need to be parametrized on ENV_GOOGLE_CLOUD_PROJECT? Same on the other test cases.
There was a problem hiding this comment.
not in this case, the unit tests are all in process and use mocks for all RPCs.
|
Thanks for the review @danthev! JavaDocs can be generated locally by running the following from you projects base dir: |
There was a problem hiding this comment.
Javadoc LGTM, you'll just need to add a package-info.java to get a Javadoc for the package generally.
...io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreV1.java
Outdated
Show resolved
Hide resolved
...io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreV1.java
Outdated
Show resolved
Hide resolved
...io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreV1.java
Outdated
Show resolved
Hide resolved
...io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreV1.java
Outdated
Show resolved
Hide resolved
...java/io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/RpcQos.java
Outdated
Show resolved
Hide resolved
...java/io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/RpcQos.java
Outdated
Show resolved
Hide resolved
.../io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/RpcQosImpl.java
Outdated
Show resolved
Hide resolved
.../io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/RpcQosImpl.java
Outdated
Show resolved
Hide resolved
|
Run Java PreCommit |
|
Run Spotless PreCommit |
...io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreIO.java
Show resolved
Hide resolved
...io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreV1.java
Show resolved
Hide resolved
buildSrc/src/main/groovy/org/apache/beam/gradle/BeamModulePlugin.groovy
Outdated
Show resolved
Hide resolved
buildSrc/src/main/groovy/org/apache/beam/gradle/BeamModulePlugin.groovy
Outdated
Show resolved
Hide resolved
| import org.apache.beam.sdk.transforms.windowing.BoundedWindow; | ||
|
|
||
| /** | ||
| * Base class for all {@link DoFn} defined in the Firestore Connector. |
There was a problem hiding this comment.
Are you sure this will be the base class for all DoFns used by source and sink ? A DoFn can include any generic functionality and many sources/sinks break up functionality into multiple DoFns due to various reasons (readability, modularity, persistence of input, etc.)
There was a problem hiding this comment.
It is true for all of the DoFn which are stateful and have a lifecycle that must be managed. For the DoFn which perform RPCs, Setup is for the RpcQos management which we want to live longer than an individual bundle, and StartBundle is where we create the RPC clients based on the PipelineOptions from StartBundleContext#getPipelineOptions().
This base class also serves as an upper bound for the unit tests where all DoFn are checked to ensure they are serializable as well as performing some common mocking which is used across the majority of tests (e.g. StartBundleContext, ProcessContext, Credentials etc).
There are a few DoFn which will be added in the "Read" PR to follow which directly extend DoFn and only implement a @ProcessElement method as they are otherwise stateless.
I'll update the comment on this class to call out that it is specifically for Stateful DoFn.
| * The default behavior is to fail a bundle if any single write fails with a non-retryable error. | ||
| * <pre>{@code | ||
| * PCollection<Write> writes = ...; | ||
| * PDone sink = writes |
There was a problem hiding this comment.
Returning PDone from a sink is an anti-pattern since users will not be able to continue the pipeline (for example, write to system X after writing to Firestore). We should think of some useful PCollection that we can return from the Firestore sync. If nothing else, this can just be 'null' values (per-window) or the original input PCollection.
There was a problem hiding this comment.
This is in addition to providing an optional dead letter queue via .withDeadLetterQueue()? Is there a good example to follow for something like this? I got the PDone from the datastore connector.
There was a problem hiding this comment.
I think still returning DoFn (even for the general case) is an anti-pattern. Some sources (including Datastore) currently do this but we'd like to change such sources. See following thread.
https://lists.apache.org/thread.html/r1fa3599ef9c0034d2bfa0614012bc864ce7b296228d8cf804c931065%40%3Cuser.beam.apache.org%3E
There was a problem hiding this comment.
I've read through both of the threads you linked and I'm leaning toward following the PCollection<TypeDescribingWhatIsComplete> from the threads.
I would Refactor BatchWrite to return a PCollection<NewWriteResultType> instead of PDone.
Two different things jump to mind for the NewWriteResultType and I'm curious if you think I should pick one over the other?
WriteSuccessSummarywhich would contain a simple summary of theBatchWriteincluding the number of writes, and the number of bytes.public final class WriteSuccessSummary { private final int numWrites; private final long numBytes; }
WriteSuccesswhich would be emitted for each processed Write and include theWrite, and theWriteResultandStatusfrom Firestorepublic static final class WriteSuccess implements Serializable { private final Write write; private final WriteResult writeResult; private final Status status; }
I'm personally leaning toward number 1 as it follows the SQL pattern and reduces the amount of data in the pipeline reducing any overhead if it is ignored.
There was a problem hiding this comment.
I think the question to ask is what information will be more valuable for a Firestore user.
The pattern is:
"Generate data to write" -> "Write to firestore" -> "Do something else with the result"
I think most users will find failed results more useful but continuation when there are no failures is also important.
I don't think you should worry about performance too much in either case. Overhead when the returned PCollection is ignored should be minimum for all major runners.
There was a problem hiding this comment.
I've refactored things to use the WriteSuccessSummary approach and pushed the commit.
| * <pre>{@code | ||
| * PCollection<Write> writes = ...; | ||
| * PDone sink = writes | ||
| * .apply(FirestoreIO.v1().write().batchWrite().build()); |
There was a problem hiding this comment.
Please make sure that these examples show any required parameters.
There was a problem hiding this comment.
They do, the RpcQosOptions is the only optional parameter to these write builders.
| * Alternatively, if you'd rather output write failures to a Dead Letter Queue add | ||
| * {@link BatchWrite.Builder#withDeadLetterQueue() withDeadLetterQueue} when building your writer. | ||
| * <pre>{@code | ||
| * PCollection<Write> writes = ...; |
There was a problem hiding this comment.
One option might be to return a WriteResult with getters to get a regular result PCollection or a dead-letter queue. We have something like that for BigQuery sink.
There was a problem hiding this comment.
Looking at https://github.com/apache/beam/blob/master/sdks/java/io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/bigquery/WriteResult.java#L79-L107 it seems that the PCollections off of WriteResult are mutually exclusive and dependent on how it was constructed. I believe the builders I have accomplish the same functionality and are typed allowing for a compilation validation rather than a runtime validation.
There was a problem hiding this comment.
Note that there WriteResult is an output (not that we return a PCollection).
I'm not saying you should do that it was just an example.
See here for a previous discussion on this and various options.
https://lists.apache.org/thread.html/d1a4556a1e13a661cce19021926a5d0997fbbfde016d36989cf75a07%40%3Cdev.beam.apache.org%3E
|
|
||
| @Override | ||
| public PDone expand(PCollection<com.google.firestore.v1.Write> input) { | ||
| input.apply("batchWrite", ParDo.of(new DefaultBatchWriteFn(clock, firestoreStatefulComponentFactory, rpcQosOptions, CounterFactory.DEFAULT))); |
There was a problem hiding this comment.
Are writes to Firestore idempotent ? Note that bundles of this write step may fail and may be retried by the runner. So if the writes are not idempotent you'll have to handle this to prevent duplicate data from being written.
There was a problem hiding this comment.
Writes to firestore are generally idempotent, there are a few narrow cases where a precondition can be specified on an individual write (something like perform and update as long as the updatedAt matches timeX). If a precondition fails, firestire will respond with a failure status for that individual write, and if the dead letter queue is used will be output as an individual WriteFailure{write, writeResult, status}
| * Licensed to the Apache Software Foundation (ASF) under one | ||
| * or more contributor license agreements. See the NOTICE file | ||
| * distributed with this work for additional information | ||
| * regarding copyright ownership. The ASF licenses this file |
There was a problem hiding this comment.
It should be possible to trigger this IT from the PR to make sure it passes. Lemme know if you need help with this.
There was a problem hiding this comment.
I'm not sure how to trigger the ITs for the PR. They do need to run against a project that has a Firestore Native Mode database, otherwise they will be skipped (currently Firestore Native Mode and Datastore are mutually exclusive in a project).
|
I've fixed the spotless and firetore related failures in "Run Java PreCommit". |
|
reopening to rerun tests |
e2b7a39
to
75ee8eb
Compare
|
In another PR, I upgraded the version of the libraries-bom to 20.0.0 which has com.google.cloud:google-cloud-firestore:2.2.5. This may affect this PR. |
|
Thanks for the heads up @suztomo It shouldn't have a material impact to this PR. My changes to the gradle config are using the version from libraries-bom already, so I'd expect things to merge pretty easily and I can do that when I rebase and squash things before merging. |
61d5e97
to
c285ec4
Compare
|
Sorry about the delay here. Lemme know if this is ready for another look. |
|
Run Java PreCommit |
|
Run Java_Examples_Dataflow PreCommit |
|
@chamikaramj Any preference related to this comment? #14261 (comment) Other than that, someone from the Firestore Backend team should be taking a look and posting a review soon. |
| * Determines batch sizes based on past performance. | ||
| * | ||
| * <p>It aims for a target response time per RPC: it uses the response times for previous RPCs and | ||
| * the number of documents contained in them, calculates a rolling average time-per-document, and |
There was a problem hiding this comment.
So this doesn't take document sizes into account, right? I'm not really advocating for taking size into account, mostly just curious how sensitive this might be to fluctuations in average document size across batches.
There was a problem hiding this comment.
Correct, right now it is only tracking number of documents not the size of those documents. It could be extended if we felt so inclined to do so at some point.
| distributionFactory.get(RpcQos.class.getName(), "qos_rampUp_availableWriteCountBudget"); | ||
| } | ||
|
|
||
| int getAvailableWriteCountBudget(Instant instant) { |
There was a problem hiding this comment.
IIUC, this computation is at the worker-second granularity and does not account for behavior in past seconds or of other workers? So if workers are slower than sending 1 request per second, would this suppress overall write rate across workers to be lower than budgeted by 555? In practice did you achieve something close to 555?
There was a problem hiding this comment.
Correct, this only tracks data for up to one second. In the case of this ramp up calculation we're not taking past performance into consideration (instead the write batcher and adaptive throttler take care of that). This class is only attempt to limit based on the 555 budget and what has been used within that specific one-second window.
The budget value grows relative to the firstInstant captured, so even if a worker is only sending a request every 5 seconds the budget calculation will still be for the next time window. If the worker is sending more than one request a second, then it will decrement from the budget and be throttled until the next second if budget has been exhausted for the specific second.
For hintMaxNumWorkers = 1 the budget will fill along this line.
I've got a test org.apache.beam.sdk.io.gcp.firestore.RpcQosSimulationTest#writeRampUp_shouldScaleAlongTheExpectedLine which runs a series of operations against the RampUp to ensure values fall on the expected line.
There was a problem hiding this comment.
This is a screenshot of a job that ran for ~90min where we can see the growth steps for the the ramp up budget (the teal line/square line). Since this is aggregated across all workers it's not as exact as each of the 5 minute windows a single worker would see, but does show the progression.
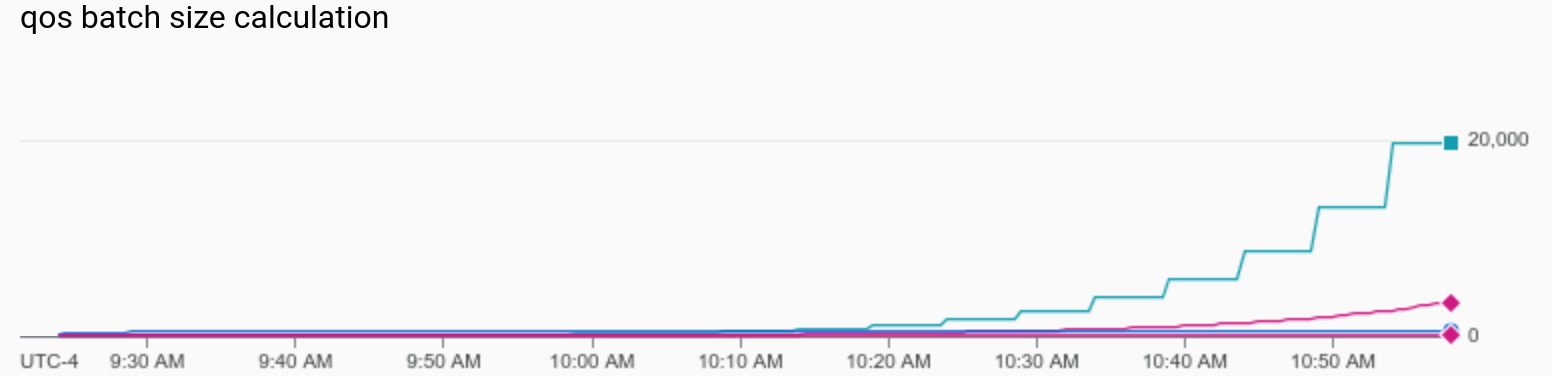
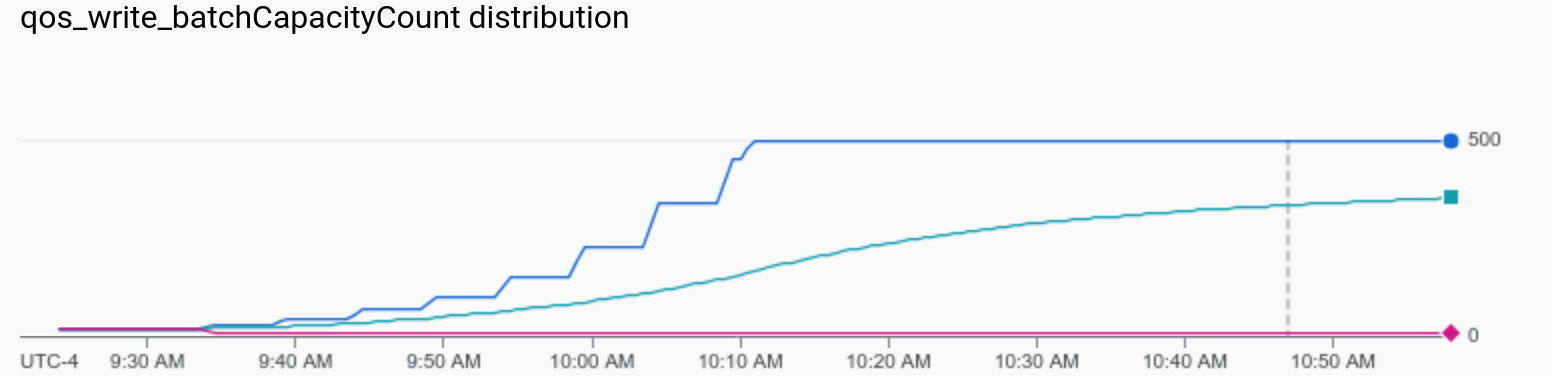
For the same job we can see the actual (aggregated) min/mean/max batchCapacityCount over the duration of the job. We can see the steps pretty clearly on the left before capping out at 500, while at the same time the ramp up budget keeps increasing all the way up to almost 20k by the end of the job.
.../io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/RpcQosImpl.java
Outdated
Show resolved
Hide resolved
...le-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/FirestoreV1WriteFn.java
Outdated
Show resolved
Hide resolved
| @@ -204,7 +210,8 @@ public boolean awaitSafeToProceed(Instant instant) throws InterruptedException { | |||
| state.checkActive(); | |||
| Duration shouldThrottleRequest = at.shouldThrottleRequest(instant); | |||
| if (shouldThrottleRequest.compareTo(Duration.ZERO) > 0) { | |||
| logger.info("Delaying request by {}ms", shouldThrottleRequest.getMillis()); | |||
| long throttleRequestMillis = shouldThrottleRequest.getMillis(); | |||
| logger.debug("Delaying request by {}ms", throttleRequestMillis); | |||
There was a problem hiding this comment.
This is when the adaptive throttler backs off, right? I think I'd tend toward an INFO log here, and a due to previous failures in the message.
There was a problem hiding this comment.
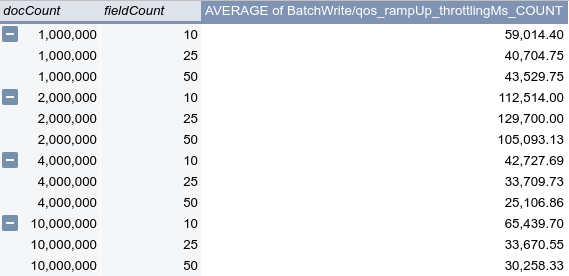
I dropped it to debug after adding the diagnostic distribution qos_adaptiveThrottler_throttlingMs so as not to blow out logs as this scenario can happen thousands of times for a job.
This screenshot shows the average number of times the adaptive throttler throttled grouped by docCount and fieldCount.

There was a problem hiding this comment.
Is throttlingMs always reported, or does it hinge on that flag? As long as a user can easily find out what's happening that's fine.
There was a problem hiding this comment.
throttlingMs is always reported, it is the magic metric which the job is able to use to signal to the platform that the job is running but it's slowish for a reason.
| @@ -344,7 +354,8 @@ public boolean awaitSafeToProceed(Instant instant) throws InterruptedException { | |||
| Optional<Duration> shouldThrottle = writeRampUp.shouldThrottle(instant); | |||
| if (shouldThrottle.isPresent()) { | |||
| Duration throttleDuration = shouldThrottle.get(); | |||
| getLogger().debug("Still ramping up, Delaying request by {}ms", throttleDuration.getMillis()); | |||
| long throttleDurationMillis = throttleDuration.getMillis(); | |||
| getLogger().debug("Still ramping up, Delaying request by {}ms", throttleDurationMillis); | |||
There was a problem hiding this comment.
Same here with INFO logs. If there's a better way that's fine too, what's important is that it's not too hard for the user to find out if they're being throttled by ramp-up or the adaptive throttler.
There was a problem hiding this comment.
Similar to adaptive throttler, this can happen a lot
.../io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/firestore/RpcQosImpl.java
Outdated
Show resolved
Hide resolved
|
@chamikaramj Both SRE and the Backend team have approved the changes, I've removed the |
|
Run Java PreCommit |
|
Run SQL PreCommit |
|
Run Java PreCommit |
* add com.google.cloud:google-cloud-firestore:2.2.4 * add com.google.api.grpc:grpc-google-cloud-firestore-v1:2.2.4 * add com.google.api.grpc:proto-google-cloud-firestore-v1:2.2.4
In preparation, this change adds common classes used by each of the three sub-components of the Firestore Connector. The three sub-components to follow are: 1. Firestore v1 Read operations 2. Firestore v1 Write operations 3. Firestore SDK Adapter ### General Common classes * FirestoreDnFn: base DoFn for all Firestore DoFn * FirestoreIO: DSL Entry point * FirestoreIOOptions: Those options which are configurable at the PipelineOptions level * FirestoreStatefulComponentFactory: Factory for those components used by DoFn which are stateful and provides a mockable boundary in unit tests * JodaClock: Simplistic clock interface which provides a mockable boundary ### Integration Tests A GCP Service account with read & write permissions for Cloud Firestore is required and the `GOOGLE_APPLICATION_CREDENTIALS` environment variable should be configured to point to the service account file. Alternatively, the integration test suite can be ran against the Cloud Firestore emulator by setting `FIRESTORE_EMULATOR_HOST` to the host-port of the running Cloud Firestore Emulator, and setting `GOOGLE_CLOUD_PROJECT` to the name of the project that will be used by the emulator. All integration tests are integrated with JUnit tests lifecycle and will have any documents or collections created during the course of a test run cleaned up after the test finishes running (regardless of success). See the `org.apache.beam.sdk.io.gcp.firestore.it.FirestoreTestingHelper` JUnit rule for more details.
In preparation, this change adds RPC QoS classes used by the Firestore v1 Read and Write operations. ### Rpc Quality of Service (QoS) In an effort to not overwhelm the live Cloud Firestore service, client side RPC Quality of Service has been built into FirestoreV1. All requests: attempted, successful and failed are recorded and used to determine the rate at which requests are sent to Cloud Firestore. In the case of `Write` requests, writes are enqueued and flushed once a batch size threshold is reached, or a bundle finishes. A combination of Adaptive Throttling[1], 500/50/5 Ramp Up[2] and historical batch throughput are used to determine the maximum size of a batch. Per RPC Method metrics will be surfaced allowing for insight into the values that feed into the QoS System. For each RPC Method the following counters are available: * throttlingMs * rpcFailures * rpcSuccesses * rpcStreamValueReceived [1] https://sre.google/sre-book/handling-overload/#client-side-throttling-a7sYUg [2] https://cloud.google.com/firestore/docs/best-practices#ramping_up_traffic
fcfd0e5
to
988aee2
Compare
|
Run Java_Examples_Dataflow PreCommit |
|
Run Python PreCommit |
|
Run Java PostCommit |
|
Run Java_Examples_Dataflow PreCommit |
|
Run Python PreCommit |
|
Awesome, thanks @chamikaramj! I'll squash all the commits and cleanup the commit message today. |
… Operations Entry point for accessing Firestore V1 read methods is `FirestoreIO.v1().write()`. Currently supported write RPC methods: * `BatchWrite` ### Unit Tests No external dependencies are needed for this suite A large suite of unit tests have been added to cover most branches and error scenarios in the various components. Test for input validation and bounds checking are also included in this suite. ### Integration Tests Integration tests for each type of RPC is present in `org.apache.beam.sdk.io.gcp.firestore.it.FirestoreV1IT`. All of these tests leverage `TestPipeline` and verify the expected Documents/Collections are all operated on during the test.
3ac65e2
to
a7e327c
Compare
|
Failures in All of my commits have been cleaned up and are marked with the jira issue for the feature and should be ready to merge. |
|
Run Java PreCommit |
|
Run Java PostCommit |
|
Run Java PreCommit |
|
BTW did you confirm that new ITs get captured by "Run Java PostCommit" ? |
|
Don't see the new tests here: https://ci-beam.apache.org/job/beam_PostCommit_Java_PR/710/testReport/ |
|
Run PostCommit_Java_Dataflow |
|
I've dug into the missing integration tests running. The integration tests are currently using junit assumptions to skip running if the client isn't able to bootstrap and unfortunately this fact isn't being reported in the tests runs seemingly due to gradle/gradle#5511 . I'll prepare a separate PR with a fix to not use assumptions and update the gradle config to run Firestore tests against a project which has a Firestore native mode database present. |
|
Run Java PreCommit |
|
@BenWhitehead what was the rationale for using the |
|
@willbattel After digging into the implementation of the Firestore connector, it became apparent that the Firestore SDK's model wouldn't be a good fit for use in the connector. (None of the model is Serializable, and there is no separation between data and operations which would have made it difficult to update the Firestore SDK to be beam compatible.) So here we've opted to use the gRPC client itself and forgo the Firestore SDK. The Additionally the SRE team in particular wanted to build more client side traffic controls into the beam connector to ensure it is well behaved, since beam is so easy to scale up really fast. So in this sink, we have the 500/50/5 ramp up budgeting, adaptive throttling in conjunction with dynamic throughput base batch sizing which are not features which are supported by the Firestore SDK. Secondarily, the |
First PR in a series of PRs to add sources and sinks for Google Cloud Firestore.
This PR adds a sink for writing Documents to Cloud Firestore. This PR also
includes common code that is shared between the sources and Firestore SDK
adapter which will be added in follow up PRs. (If desired I can split the common
code into a separate PR, but I thought it wouldn't make much sense without the
context of it being used).
Each commit has a detailed commit message, however a brief summary of the 4
commits included in this PR are as follows:
Gradle
Add Google Cloud Firestore dependencies. Version 2.2.4+ is needed for all dependencies
which include bugfixes and the necessary grpc client, protos and bootstraping
code.
Common Classes
A set of base classes which underpin the added PTransforms and DoFns that will
make up the connector. This change also includes the base classes used in the
unit and integration test suites which are present for each component of the
connector.
RPC QoS Classes
All read and write RPC Operations are managed in coordination with the RPC QoS
layer. Attempt counts, backoff amounts, batch sizing, success, failure metrics,
throttling are all managed here.
Firestore v1 Write Operations
Add PTransforms for writing to Cloud Firestore via the BatchWrite API. There are
two implementations which only differ in what happens when an error is
encountered. The first implementation will throw an exception if an error is
encountered, whereas the second implementation will output a failure object
(functioning similar to a dead letter queue).
Integration Tests
The integration test suite will only run if
GOOGLE_APPLICATION_CREDENTIALSorFIRESTORE_EMULATOR_HOSTare present in the environment. The project the testsrun against must have a Firestore in Native mode
database configured (Firestore in Native Mode and Firestore in Datastore Mode cannot
both be present in the same project at this time). All integration tests are self
contained and do not depend on preconfigured external state, and clean up after
themselves.
A future PR will be created for sources, and another PR for a Firestore SDK
adapter which both will leverage the common code added in this PR.
Reviewers
R: @chamikaramj
R: @jlara310 (Firestore Technical Writer)
R: @clement (Firestore Dataplane TL)
R: @danthev (Firestore SRE)
Thank you for your contribution! Follow this checklist to help us incorporate your contribution quickly and easily:
R: @username).[BEAM-XXX] Fixes bug in ApproximateQuantiles, where you replaceBEAM-XXXwith the appropriate JIRA issue, if applicable. This will automatically link the pull request to the issue.CHANGES.mdwith noteworthy changes.See the Contributor Guide for more tips on how to make review process smoother.
Post-Commit Tests Status (on master branch)
Pre-Commit Tests Status (on master branch)
See .test-infra/jenkins/README for trigger phrase, status and link of all Jenkins jobs.
GitHub Actions Tests Status (on master branch)
See CI.md for more information about GitHub Actions CI.