This container was created due to problems with the official image to run on ARM environments like Raspberry Pi and MacBook with M1
With this container, you can run Spark code with Python or Scala and use AWS Glue context and AWS libraries
For example, You can do the following:
- Create DynamicFrame
- Read and write in S3
- Read tables in Athena
- Use AWS Services
- Etc
Docker image in DockerHub: aws-glue-local-interpreter
- Aws-cli
- MacOS :
brew install awscli - Ubuntu :
sudo apt-get install awscli - Windows : AWS docs
- MacOS :
- You must have AWS credentials in the path:
~/.aws
- config
- credentials
~/.aws/config[default]
region = us-east-1
output = json
~/.aws/credentialsaws_access_key_id = XXXXXXXXXXXXXXXXXXXXXXXX
aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXXX
If you would like to check the access to S3:
aws s3 ls
You should get a list of buckets in S3.
- By bash command
- With docker-compose
Both using:
docker run -p 8888:8888 -v ~/.aws:/root/.aws:ro --name aws-glue-local-interpreter anthonypernia/aws-glue-local-interpreter
It will create the container was-glue-local-interpreter and a volume to share path ~/.aws in /root/.aws to use the same credentials
Must have a file name:
- docker-compose.yml
With this content
version: '3'
services:
aws-glue-local-interpreter:
image: "anthonypernia/aws-glue-local-interpreter"
volumes:
- ~/.aws:/root/.aws
- ~/aws-glue-developments:/root/developments ##(OPTIONAL)
ports:
- "8888:8888"
Then, you need to use:
docker-compose up
You can add another volume where the script will be stored and edited locally and executed in the container. in this case, the folder "aws-glue-developments" is used.
When the container is running, go to :
And you should see a Jupyter notebook running.
Using the VSCODE Remote Development extension, we could launch VScode inside the container
Create a notebook and run the code:
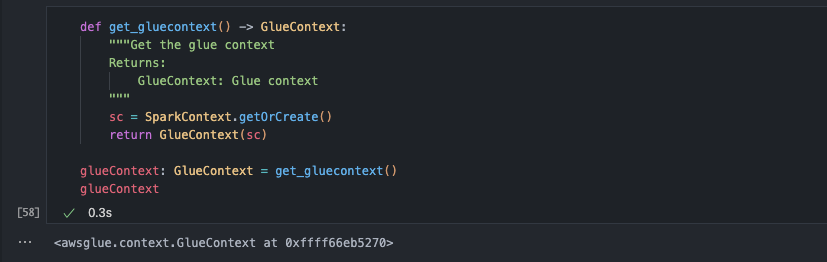
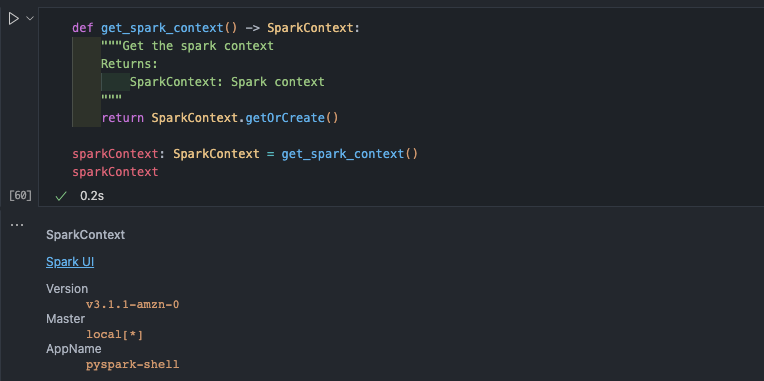
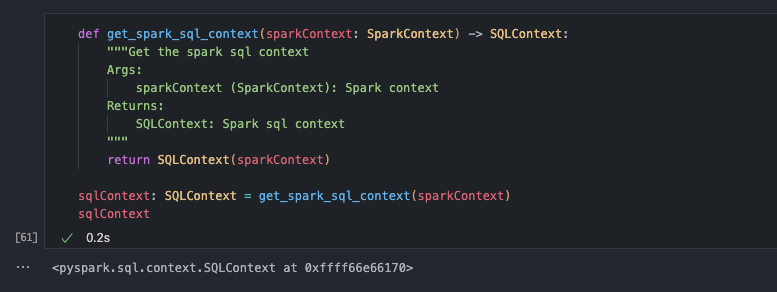
from pyspark import SparkContext from awsglue.context import GlueContext from pyspark.sql import SQLContextdef get_gluecontext() -> GlueContext: """Get the glue context Returns: GlueContext: Glue context """ sc = SparkContext.getOrCreate() return GlueContext(sc)def get_spark_context() -> SparkContext: """Get the spark context Returns: SparkContext: Spark context """ return SparkContext.getOrCreate()def get_spark_sql_context(sparkContext: SparkContext) -> SQLContext: """Get the spark sql context Args: sparkContext (SparkContext): Spark context Returns: SQLContext: Spark sql context """ return SQLContext(sparkContext)glueContext: GlueContext = get_gluecontext() sparkContext: SparkContext = get_spark_context() sqlContext: SQLContext = get_spark_sql_context(sparkContext)
After creating the contexts:
from awsglue.dynamicframe import DynamicFrame from pyspark.sql import DataFramedef create_df_from_path(glueContext: GlueContext, path: str, format_file: str) -> DynamicFrame: """Create a dataframe from a path Args: glueContext (GlueContext): Glue context path (str): Path to read format_file (str): Format of the file Returns: DynamicFrame: DynamicFrame """ return glueContext.create_dynamic_frame_from_options(connection_type = "s3", connection_options = {"paths": [path]}, format = format_file)def create_spark_df_from_path(sqlContext: SQLContext, path: str, format_file: str) -> DataFrame: """Create a spark dataframe from a path Args: sqlContext (SQLContext): Spark sql context path (str): Path to read format_file (str): Format of the file Returns: DataFrame: Spark dataframe """ return sqlContext.read.format(format_file).load(path)path: str = "s3://awsglue-datasets/examples/us-legislators/all/memberships.json" format_file: str = "json"df: DynamicFrame = create_df_from_path(glueContext, path, format_file)spark_df: DataFrame = create_spark_df_from_path(sqlContext, path, format_file)

def write_spark_df(df: DataFrame, bucket: str, key: str) -> None: """Write a dataframe to S3 in parquet format Args: df (DataFrame): Dataframe to write bucket (str): S3 bucket key (str): S3 key """ df.write.parquet(f"s3://{bucket}/{key}", mode="overwrite")bucket: str = "example-bucket-demo-aws" key: str = "test-folder-output" write_spark_df(spark_df, bucket, key)
