A convolutional neural network for hiding videos inside other videos.It is implemented in keras/tensorflow using the concepts of deep learning, steganography and encryption.
Steganography is the practice of concealing a secret message within another, ordinary, message.The messages can be images, text, video, audio etc. In modern steganography, the goal is to covertly communicate a digital message. The main aim of steganogrpahy is to prevent the detection of a hidden message. It is often combined with cryptography to improve the security of the hidden message.Steganalysis is the study of detecting messages hidden using steganography (breaking); this is analogous to cryptanalysis applied to cryptography.Steganography is used in applications like confidential communication, secret data storing, digital watermarking etc.
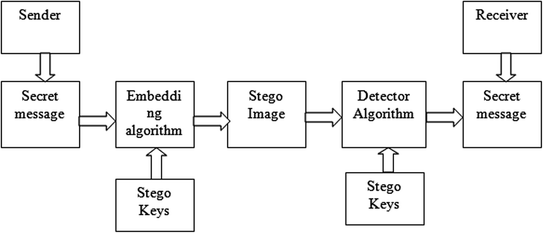
1. Basic Working Model
Steganography on images can be broadly classified as spatial domain steganography and frequency domain steganography.In spatial domain, algorithms directly manipulate the values (least significant bits) of some selected pixels. In frequency domain, we change some mid-frequency components in the frequency domain.These heuristics are effective in the domains for which they are designed, but they are fundamentally static and therefore easily detected.We can evaluate a steganographic technique or algorithm by using performance and qualtiy metrics like capacity, secrecy, robustness, imperceptibility, speed, applicabilty etc.
Here we plan to extend the basic implementation from the paper 'Hiding images in plain sight: Deep steganography' to videos, i.e we will train a model for hiding videos within other videos using convolutional neural networks.Also, we will incorporate additional block-shuffling as an encryption method for added security and other image enhancement techniques for improving the output quality.
The implementation will be done using keras, with tensorflow backend.Also, we will be using random images from imagenetdataset for training the model.We will use 50000 images (RGB-224x224) for training and 7498 images for validation.
- Tensorflow(>=1.14.0), Python 3
- Keras(>=2.2.4)
- Opencv(>3.0), PIL, Matplotlib
Our main goal is to hide a full size (N*N RGB) color image within another image of the same size. Deep neural networks are simultaneously trained to create the hiding and revealing processes and are designed to specifically work as a pair. The technique used is image compression through auto-encoding networks.The trained system must learn to compress the information from the secret image into the least noticeable portions of the cover image and then, it must learn how to extract and reconstruct the same information from the encoded message, with minimum loss.
Here is the basic architecture diagram

2. Basic Architecture
We train the hiding and reveal networks simultaneously in the form of an autoencoder, using keras.The model has two inputs corresponding to a pair of secret and cover image and two outputs corresponding to their inputs .Since we are using a autoencoder based architecture, the labels are same as their corresponding inputs.
The network consists of three parts viz. Prepare block, Hide block, Reveal block.In prepare block, we transform the color-based pixels to more useful features for succinctly encoding the images. We then hide this transformed image inside the input cover image using the hide block, to generate the container image.Finally, in the reveal block we decode the container image to produce the secret output.Therefore, the training graph has two inputs and two outputs.
Training Graph

We use a weighted L2 loss function along with Adam optimizer for training the model.The model is trained for 100 epochs suing a batch size of 8.
Loss: L(c, c 0 , s, s 0 ) = ||c − c 0 || + β||s − s 0 ||
Here c and s are the cover and secret images respectively, and β is how to weigh their reconstruction errors
To ensure that the networks do not simply encode the secret image in the LSBs, a small amount of noise is added to the output of the second network (e.g. into the generated container image) during training.
After the training, we split the trained model into two: hide network and reveal network (we remove noise layer).The hide network has two inputs corresponding to secret and cover image and one output corresponding to the container image. The reveal network takes the container image as input and reveals(decodes) the secret image as output.
Hide Network

Reveal Network

The hide network is used by the sender; while the reveal network is supposed to be used by the receiver.The receiver has access only to the container image.In addition to the normal steganographic hiding mechanism, we also encrypt(block shuffle) our secret images for added security.Therefore , both the sender and the receiver shares a symmetric key for encrypting/decrypting the shuffled secret message. The encryption is performed by the sender on the input secret image; whereas the decryption is performed by the receiver on the final decode image.
Finally images/video are enhanced by applying Non-local Means Denoising algorithm and Unsharp Masking(USM) filter.
- Download the imagenet dataset and put them in data folder.
- Select a random subset of images from the imagenet dataset.
- Resize all the images to 224*224(RGB) size.
- Split the dataset into training and validation subsets.
Also ensure the that evaluation images(RGB:224x224) are stored in the directory dataset/eval_data.
dataset
├── eval_data
├── train_data
│ └── train
└── val_data
└── validation
Configure the filepaths and batch-size in train.py, if needed.
After ensuring the data files are stored in the desired directories, run the scripts in the following order.
1. python train.py # Train the model on training dataset
2. python eval.py dataset/eval_data checkpoints/steg_model-06-0.03.hdf5 # Evaluate the model on evaluation dataset
3. python test.py test/testdata.npy checkpoints/steg_model-06-0.03.hdf5 # Test the model on test dataset
4. python split_model.py checkpoints/steg_model-06-0.03.hdf5 # Split the model into hide and reveal networks- Use image_hide.py & image_reveal.py to test the models on images.
- Use video_hide.py & video_reveal.py to test the models on videos.
- Use enhance.py for enhancing the output secret video.
It took about 1 week for training the model on the entire dataset using a GTX 1060 (6GB),with a batch size of 6.

Sample results for a pair of input images - Secret & Cover
Inputs: Secret and Cover

Outputs: Secret and Cover

Trian MSE: 0.03, Test MSE: 0.02
Sample results for a pair of input videos - Secret & Cover
Inputs: Secret and Cover


Outputs: Secret and Cover


- Since the model has two inputs and two outputs we use a custom generator to feed the model with input images and labels from the dataset directory.In this autoencoder based approach, we feed the input images(two) to the model from the same directory with different seed values.The ouput labels for the model will be the corresponding (two)input images of the model, in each iteration.
- To implement the custom loss function we need to calculate the hide and reveal loss separately and add them up using custom loss weights. Also, we need to pass these loss functions as custom objects for prediction at runtime.
- Once the model is trained together, we need to split them into hide and reveal networks.We can easily the separate the encoder (initial block) form the parent model by specifying the required intermediate layer as its final output layer.On the other hand, for the decoder part we need to create a new input layer and connect it to the lower layers(with weights). This can be accomplished by re-initializing these layers(with same name) and reloading the corresponding weights from the parent model.
- Since the current model support only lossless formats, we need to ensure that the output container image is not modified before decoding.Also, make sure you save the container video using an uncompressed(lossless) codec/format eg:-Huffman HFYU, Lagarith LAGS etc.
- You can use a permutation based block shuffling technique for encrypting your input secret images. Basically you divide the image into blocks of fixed size and permute them according to a predefined sequence(shared secret key) before hiding them using the model. The receiver can finally decode the secret image from the model(reveal) output using this secret key.
- To monitor the training progress and visualize the images during the training, we need to implement a custom tensorboard image logger, since keras does not have a built-in image logger(or use matplotlib).
- Use learning rate decay and higher batch size(better GPU) for faster training and/or convergence.
- Make sure you don't use a "relu" activation on the final layers corresponding to the model outputs.
- Don't forget to denormalize the final output images for viewing, if you have normalized the input images during training process.
- Accuracy has little meaning in case of autoencoder networks, since we ares essentially performing a regression task.We can use MSE or KL divergence(on unseen data) as metrics to evaluate the performance of an autoencoder.
- Change error metric from MSE to SSIM
- Train the model with Lab colour space
- Use bigger images for training(513x513)
- Support for lossy image and video formats
- Improve the accuracy and quality of video
- Support for hiding synthetic images(not natural)
- Make the model resistant to noise and affine transformations
- Try GAN based adversarial training, for improving imperceptibility
- Implement custom technique for hiding pixels across multiple frames using temporal information
Version 1.0
Anil Sathyan
- Hiding images in plain sight: Deep steganography
- https://github.com/harveyslash/Deep-Steganography
- https://towardsdatascience.com/nips-2017-google-hiding-images-in-plain-sight-deep-steganography-with-interactive-code-e5efecae11ed
- https://www.pyimagesearch.com/2018/06/04/keras-multiple-outputs-and-multiple-losses/
- https://machinelearningmastery.com/keras-functional-api-deep-learning/
- http://theorangeduck.com/page/neural-network-not-working
- https://gist.github.com/gyglim/1f8dfb1b5c82627ae3efcfbbadb9f514
- https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_photo/py_non_local_means/py_non_local_means.html
- https://stackoverflow.com/questions/52800025/keras-give-input-to-intermediate-layer-and-get-final-output
- https://keras.io/models/model/