This repo makes it easy to train language models on PyTorch/TPU. It relies on two libraries, PyTorch/XLA to run PyTorch code on TPUs, and pytorch-transformers for the language models implementation.
To use TPUs, all your computations happen on Google Cloud. Use the command ctpu to instantiate a TPU
ctpu up -tf-version=pytorch-0.5 -name=[lm_tpu] -tpu-size=[v3-8] -tpu-only -zone=[us-central1-a] -gcp-network=[default] -project=[my_proj] [-preemptible]
-
Replace the parameters in square prackets with the right values for you. Make sure to get the
zone,gcp-network,preemptible,projectright, especially if you are using credit from TFRC. -
The
-tf-version=pytorch-0.5argument is very important. It specifies that this TPU will be used to run PyTorch code (not Tensorflow code). It uses the prereleasepytorch-0.5, which has many bug fixes that are not in the prereleasepytorch-0.1. Also, don't usepytorch-nightlyas it changes frequntly and might introduce breaking changes. -
Our code only supports Cloud TPUs (v2-8 and v3-8), and not the larger TPU pods. We will add support for those in the future.
-
It is easier to use the
ctpucommand than using the Google Cloud console interface.ctpuautomatically finds an IP for the TPU
-
In addition to the Cloud TPU, you also need a VM. Follow the instructions in PyTorch/XLA to create a VM that has PyTorch/XLA Image.
-
ssh to the VM created in the previous step
-
Clone the code, activate conda and set TPU IP
git clone https://github.com/allenai/tpu_pretrain.git
cd tpu_pretrain
conda env list
conda activate pytorch-0.5 # use the prerelease pytorch-0.5
export XRT_TPU_CONFIG="tpu_worker;0;$TPU_IP_ADDRESS:8470" # where $TPU_IP_ADDRESS is the IP of the Cloud TPU created above
- To test that everything is working fine, run the mnist example
cd /usr/share/torch-xla-0.1/pytorch/xla
python test/test_train_mnist.py
cd /code
python -m pretrain --pregenerated_data data/pregenerated_training_data/ --output_dir finetuned_roberta_base --epochs 4 --bert_model roberta-base --train_batch_size 24
It fine tunes the roberta-base model on the sample pregenerated training data on data/pregenerated_training_data/. Each epoch will take around 15 minutes. Notice that the first few steps are usually slower than the rest because the TPU compiles the graph in the first steps, then use the cached compiled one for subsequent steps.
The pretraining code assumes pregenerated training data, which is generated by the script pytorch_transformers_lm_finetuning/pregenerate_training_data.py. This script is adopted from the one on pytorch-transformers with some modefications. It takes as input raw text and outputs the format needed for the pretraining script. The input format
is a glob of text files, each one has one sentence per line, and an empty line as document separator.
python pytorch_transformers_lm_finetuning/pregenerate_training_data.py --train_corpus "data/sentences_150k.txt" --output data/pregenerated_training_data --bert_model roberta-base --do_whole_word_mask --epochs_to_generate 2 --max_seq_len 512 --max_predictions_per_seq 75
-
If your corpus is one large file, please split it into smaller files before generating the training data, each is not more than 500K sentences.
-
If you have large number of files, consider using the argument
--num_workers x.
-
Switch to the MP interface discussed here. This is expected to speedup the code by around 1.5x-2x
-
Add support for TPU pods to scale up training. The change is mainly to figure out how to distribute the training data over the machines (for example, this)
-
The first few steps are slow. This is because the TPU node is compiling the computation graph.
-
If you get a random OOM for no reason, try restarting the TPU node.
-
Profiling tools are not available yet. The profiling tools made for tf don't work for TPU nodes running PyTorch/XLA.
-
Use the flag
--one_tputo run your code on a single TPU core. This makes it easy to put breakpoints in your code for debugging. -
TPUs use static graph. Any PyTorch function that results into a dynamic graph will slow down performance considerably.
-
Trips from TPU to CPU is very slow, so functions like
.item()are very slow. That's why this code reports the loss sporadically. -
Use the flag
--tpu_reportto print the TPU metric report. The report is usually helpful for debugging.
We compared the performance of TPUs/GPUs on PyTorch/Tensorflow, and the table below summarizes the results.
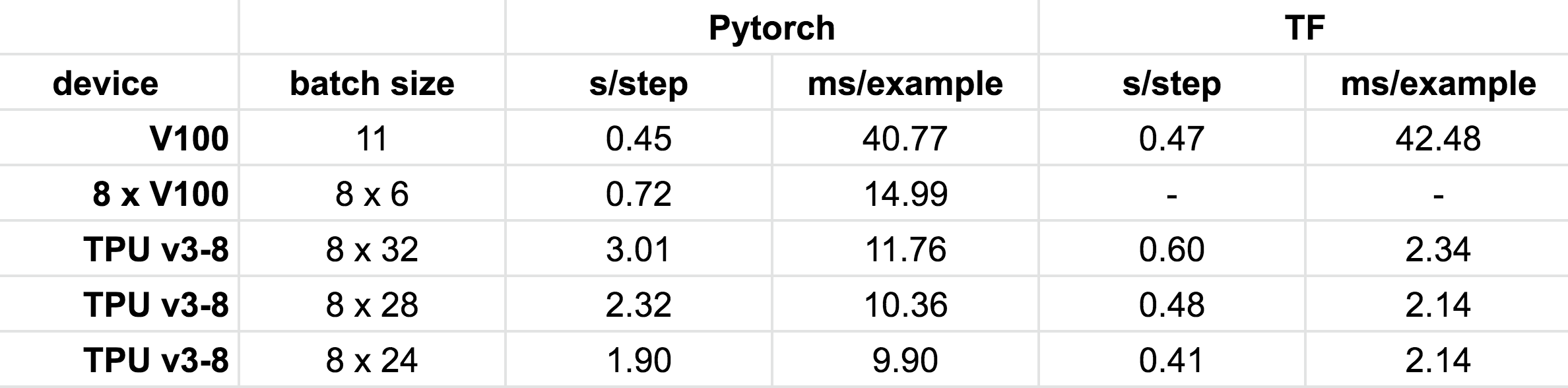
The performance numbers show that:
1- TPU v3-8 (the smallest TPU which has 8 cores) is faster than 8 V100 GPUs that have the same amount of memory
2- Running PyTorch on TPUs is still 5x slower than Tensorflow. Switching to the MP interface should reduce this gap. Reaching the same level of performance will likely require some model-specific tuning.