Project Website: https://abdulhameed.me/projects/covid19tweetsanalysis
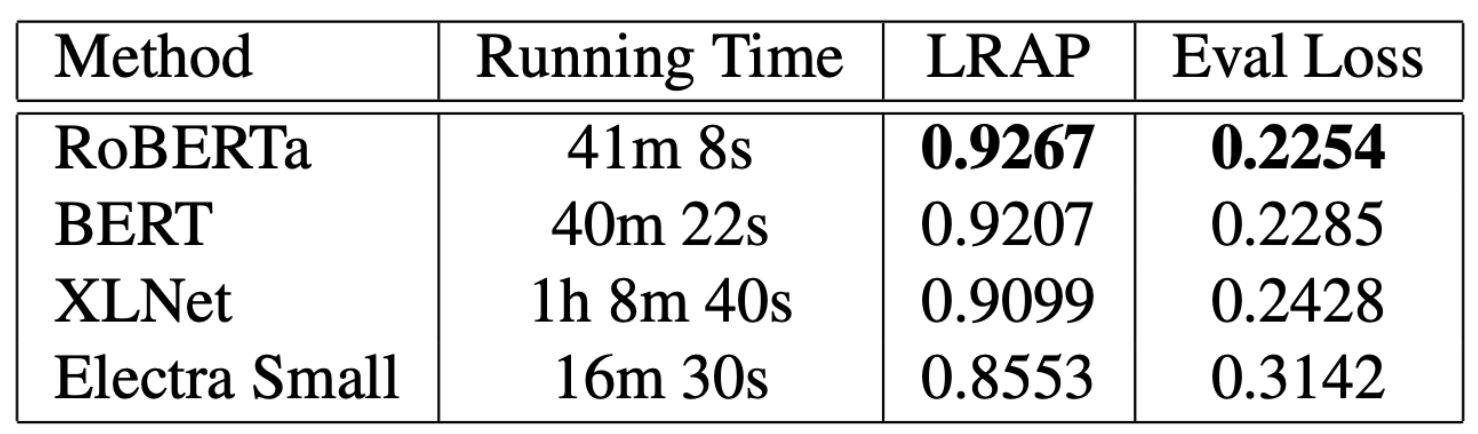
Understanding the public sentiment and perception in a healthcare crisis is essential for developing appropriate crisis management techniques. While some studies have used Twitter data for predictive modelling during COVID-19, fine-grained sentiment analysis of the opinion of people on social media during this pandemic has not yet been done. In this study, we perform an in-depth, fine-grained sentiment analysis of tweets in COVID-19. For this purpose, we perform supervised training of four transformer language models on the downstream task of multi-label classification of tweets into seven tone classes: [confident, anger, fear, joy, sadness, analytical, tentative]. We achieve a LRAP (Label Ranking Average Precision) score of 0.9267 through RoBERTa. This trained transformer model is able to correctly predict, with high accuracy, the tone of a tweet. We then leverage this model for predicting tones for 200,000 tweets on COVID-19. We then perform a country-wise analysis of the tone of tweets, and extract useful indicators of the psychological condition about the people in this pandemic.
https://drive.google.com/file/d/1KKSx2lTGIz8hDnqWLS_wxO8oqEnZeTQP/view?usp=sharing
https://drive.google.com/drive/folders/1VXXgZnBNNuq1PeLXon7Bjl1EOZeBigdB?usp=sharing
To load this model, first install transformers library (from source) and simpletransformers library:
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
pip install "simpletransformers"==0.34.4
Then load the model (replace /foldername with the path of the downloaded model):
from simpletransformers.classification import MultiLabelClassificationModel
model = MultiLabelClassificationModel('roberta', '/foldername', args={})
To predict tone of any new text:
df = df.text.apply(lambda x: x.replace('\n', ' ')).tolist()
preds, outputs = model.predict(df)
predicted_tones = pd.DataFrame(outputs, columns=['anger','fear','joy','sadness','analytical','confident', 'tentative'])
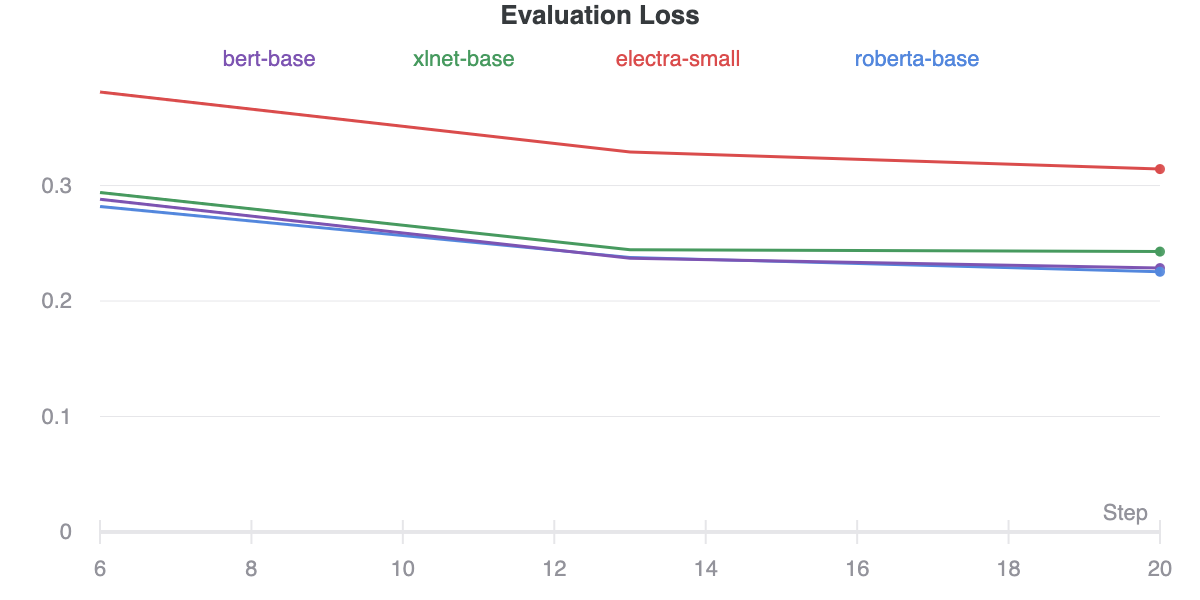
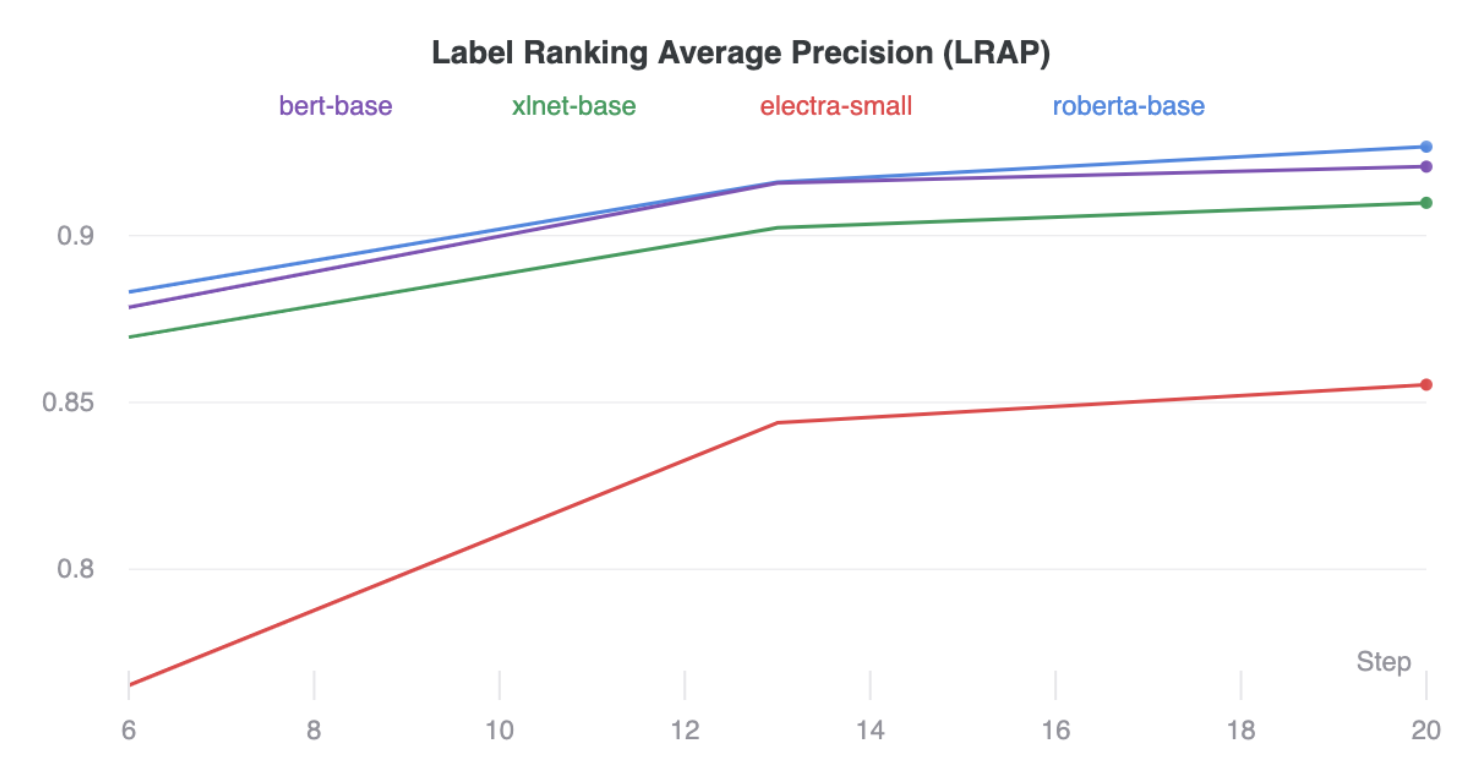
| Evaluation Loss | Label Ranking Average Precision (LRAP) |
|---|---|
 |
 |