
This is a distributed service, consisting of multiple isolated processes which can count the number of items, grouped by tenants that are delivered through an HTTP restful interface.
| Resource | Description |
|---|---|
POST /items |
add new items |
GET /items/tenantID/count |
return number of items for given tenant |
Build & run coordinator with 3 counters
$ make up or specify different number of counters
$ make up COUNTERS=5or if you want to debug
$ make devRun tests
$ make test Show logs from containers
$ make log Run system simulation
$ make simulate You can copy example config file to .env and change values in it
$ cp .env.dist .env# Http port on which coordinator server will listen
HTTP_PORT=8080
# Debugger port
DEBUG_PORT=40000- Coordinator which provides an RESTful API.
Nnumber of counters which can be called only from coordinator itself.
The requirements are focused mostly on data consistency and handling child node failures.
I decided to choose one matching scenario described in the given article (http://book.mixu.net/distsys/abstractions.html).
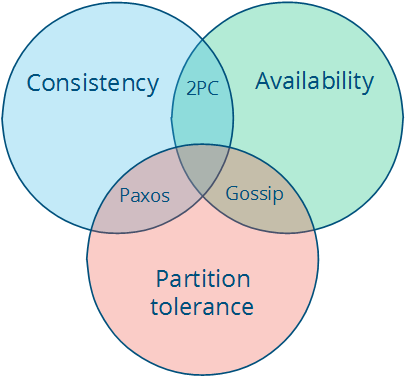
APdesign was not the case because of the consistency requirement.CPcannot be fully achieved with only one callable main coordinator. Mechanism to choosing one of the counters as master after coordinator failure would be something worth consideration.CAand Two-Phase commit protocol approach is something I choose for this system.
Disadvantages
- Request is synchronous (blocking).
- Possibility of deadlock between transactions.
- It is not partition tolerant.
The above drawback may lead to system performance bottleneck too. It is sacrifice of efficiency.
Using this approach it was also possible to achieve three of the ACID principles: atomicity, consistency and read-write isolation.
- When a new counter instance is added it sends request to coordinator to obtain data from other counters.
- If a counter goes down and recover it will get data the same way. This ensures data consistency.
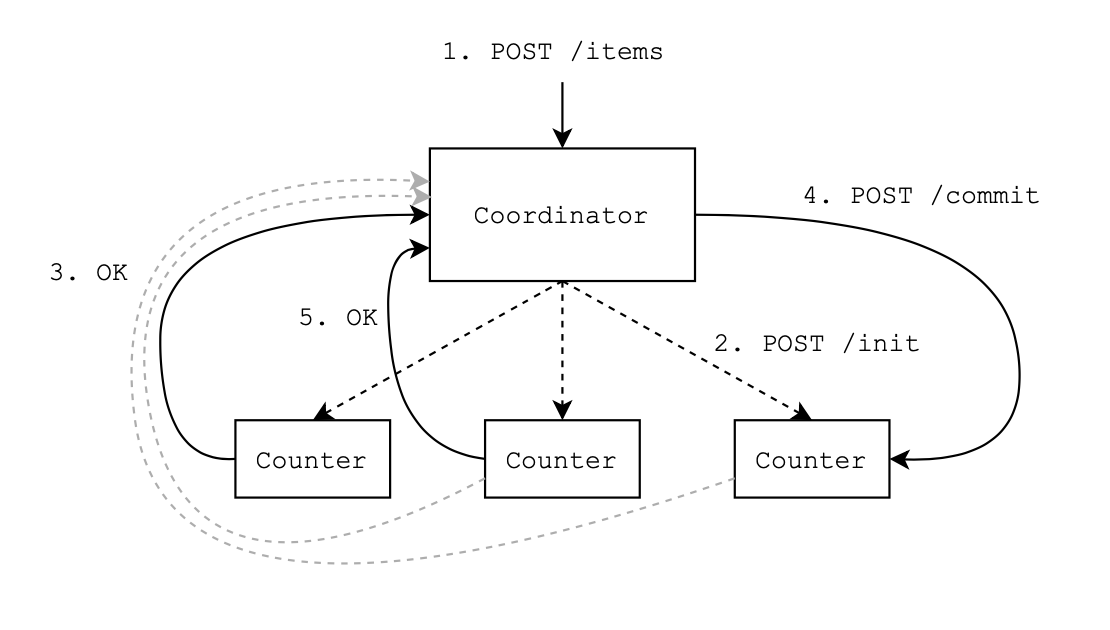
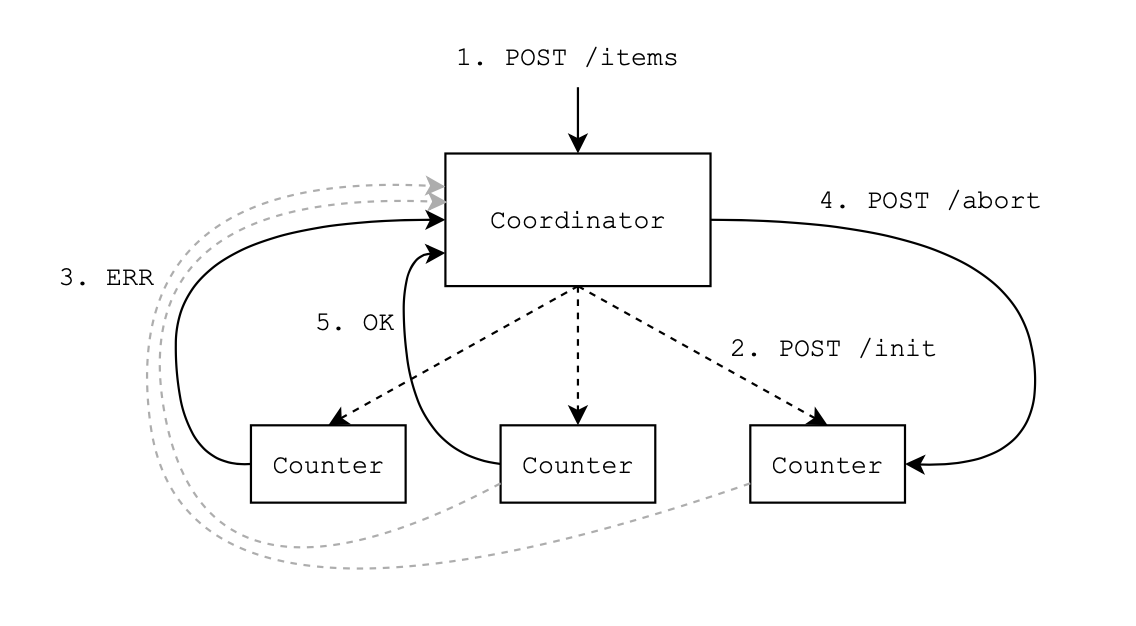
- Coordinator sends unique message to
allcounters. - Counters must make a decision if they can save items.
- If one or more counters refuse
allwill receive request to forget about previous message.
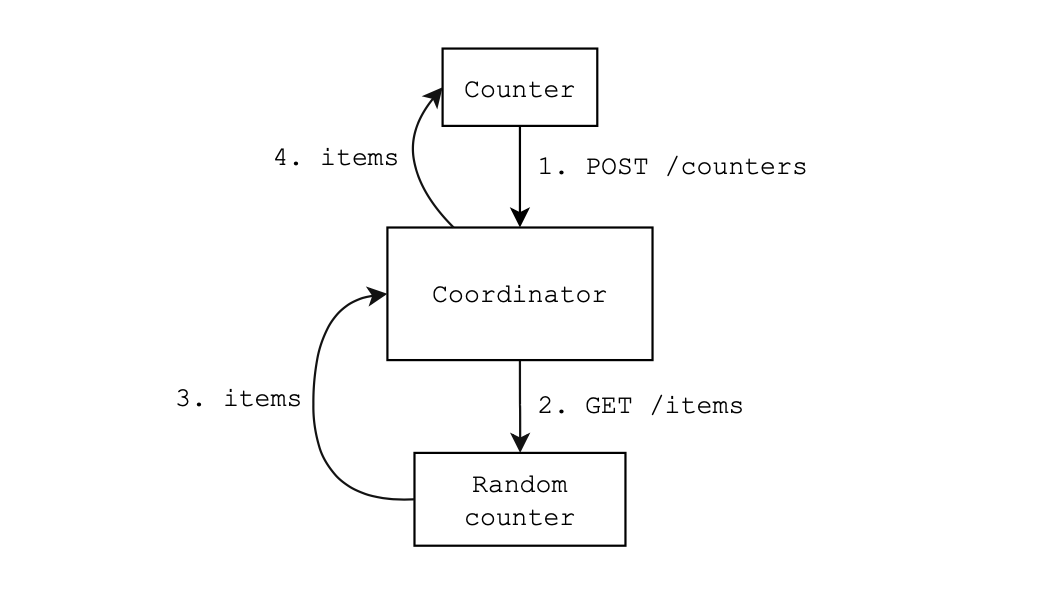
- To get count coordinator sends request to one random counter.
- Docker handles requests balancing in that case. It will not call dead nodes.
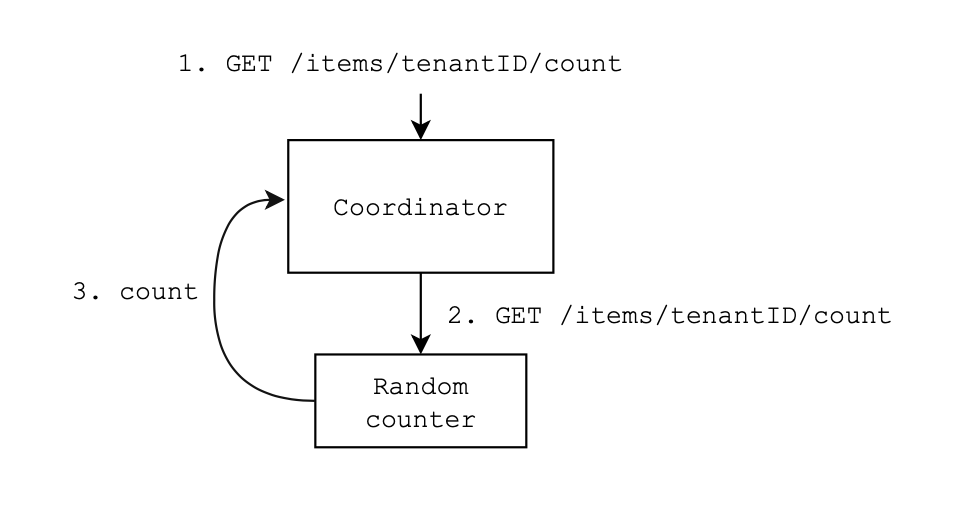
- Coordinator performs counters health checks every 10 seconds.
Todo: make health check interval configurable. - If a counter not respond or respond with an error it is marked as dead and it is not query-able.
- After 4 more unsuccessful responses coordinator removes that counter.
Todo: make number of recovery tries configurable. - Docker performs coordinator health checks every 30 seconds.
- RPC or sockets could be used instead of HTTP for communication between coordinator and counters.
- Different distributed algorithm like paxos or raft could be implemented for our system to be partition tolerant.