An in-depth study outline for Google Associate Cloud Engineer Certification Exam. The date engineering part is left bank, because the certification covers only the basic knowledge of that area, however it is still worth a look at on one's own.
- Creating projects: By default, when an organization is created, every user in the domain is granted that permission
- gcloud config set project Enabling APIs. Some are enabled by default, but most others, including GCE, is not.
- Check project-wide quota: gcloud compute project-info describe --project myproject
Check quota in a region:
gcloud compute regions describe [REGION]
- gcloud auth list to see the currently available accounts.
- gcloud config set account to set the active account
- gcloud info display information about the current gcloud environment, including config and log directory locations.
- Organization -> Folder -> Project -> Resources
- To grant a role: gcloud add-iam-policy-binding [RESOURCE-NAME] --member user:[USER-EMAIL] --role [ROLE-ID]
- To get IAM policy of a project: gcloud projects get-iam-policyPROJECT_ID [--filter= EXPRESSION ] [--limit= LIMIT ][--page-size= PAGE_SIZE ] [--sort-by=[FIELD ,…]] [GCLOUD_WIDE_FLAG … ] E.g. To get IAM policy of a certain service account: gcloud projects get-iam-policy <YOUR GCLOUD PROJECT> \ --flatten="bindings[].members" \ --format='table(bindings.role)' \ --filter="bindings.members:<YOUR SERVICE ACCOUNT>"
- Create a role from an existing role gcloud iam roles copy [--dest-organization= DEST_ORGANIZATION ] [--dest-project= DEST_PROJECT ][--destination= DESTINATION ] [--source= SOURCE ] [--source-organization= SOURCE_ORGANIZATION ][--source-project= SOURCE_PROJECT ] [GCLOUD_WIDE_FLAG … ]
- Compute Engine default service account [PROJECT_NUMBER]-compute@developer.gserviceaccount.com
- App Engine default service account PROJECT_ID @appspot.gserviceaccount.com
- Monitoring, logging, error reporting, debugger, trace, profiler (these two are free). https://cloud.google.com/stackdriver/pricing
- Stackdriver monitoring agent a collectd-based daemon that gathers system and application metrics from virtual machine instances. Without the agent Monitoring can access CPU utilization, some disk traffic metrics, network traffic, and uptime information.
- Compute engine: need to install
- App Engine standard has built-in Monitoring support. Agents are not needed.
- App Engine flexible environment has pre-installed agents with special configurations.
- GKE has Legacy Stackdriver by default, since when creating a cluster the --enable-cloud-monitoring flag is automatically set. To enable the Stackdriver Kubernetes Monitoring (Beta) set the flag on --enable-stackdriver-kubernetes the creation of the cluster.
- Stackdriver logging agent has similar scenarios as monitoring agent.
- Stackdriver logging retention periods are either 30 or 400 days. https://cloud.google.com/logging/quotas#logs_retention_periods
- Stackdriver logs can be exported by writing a query that selects the log entries you want to export, and choosing a destination in Cloud Storage, BigQuery, or Cloud Pub/Sub.
- CloudAudit Logs maintains three audit logs for each project, folder, and organization: Admin Activity, Data Access, and System Event. To view the logs you must have role of Logging/Logs Viewer or Project/Viewer. Audit log name looks like: projects/[PROJECT_ID]/logs/cloudaudit.googleapis.com%2Factivity
- Customer metrics metrics defined by users. Use the Stackdriver Monitoring API to create custom metrics and to add time series data to them.
- IAM roles. To change the billing account of a project, it has to be Project Owner or Billing Account Administrator. Project Billing Manager can also link/unlink the project to/from a billing account. Project Billing User and Billing Account User can link the project to a billing account. Billing Account Administrator -> CEO/CTO, Billing Account Viewer -> CFO, Billing Account User -> Dev, Project Owner -> CTO/Dev
- Charging cycle: "You'll be charged when your balance reaches $1000.00 or 30 days after your last automatic payment, _ whichever comes first _ ."
- Monthly billing: Costs are charged on a regular monthly cycle.
- Threshold billing: Costs are charged when your account has accrued a specific amount.
- gcloud beta billing projects linkPROJECT_ID--billing-account= ACCOUNT_ID [GCLOUD_WIDE_FLAG … ]
- Set budgets and alerts.Either on a billing account (multiple projects)or on a single project.
- Billing data can be exported to a csv or json file in GCS, or to BigQuery.
- After installing, run gcloud init, which does authorization and configuration.
- Common commands.
- gcloud config…
- gcloud config configurations manage the set of gcloud named configurations
- gcloud config configurations activate activates an existing named configuration
- gcloud compute instances list list Google Compute Engine instances (note the --filter flag)
- gcloud projects add-iam-policy-bindingPROJECT_ID--member= MEMBER --role= ROLE [GCLOUD_WIDE_FLAG … ]
- gcloud deployment-manager deployments
- Compute Engine is, basically, kind of everything else, or even all of those things if you want. It's VM. So you have full control to do whatever you need to do to connect things together.
- Global, regional, and zonal resources https://cloud.google.com/compute/docs/regions-zones/global-regional-zonal-resources
- Cloud SDK commands:
- gcloud compute instances create/list/start/stop
- Best IaaS option for compute and provides fine grained control
- Machine types. n1- standard / highmem / highcpu / ultramem / megamem - CPU numbers.Note highecpu has less memory compared to standard with the same CPU numbers. N1-ultramem-160 has 160 vCPUs and 3.75TB memory.
Custom machine types are also supported. Shutting down an instance has a 90s alert. Custom types can have up to 96 vCPUs and 624GB memory.
- Add GPU to instances. To an existing instance, it must be stopped first; or starting a new instance in which GPU libraries have been installed or will be installed.
- All vCPUs, GPUs, and GB of memory are charged a minimum of 1 minute. After 1 minute, instances are charged in 1 second increments.
- Storage options are: zonal and regional persistent disks, local SSD and cloud storage. Add persistent disk, either HD or SSD. Attach, format, then mount. A persistent disk can also be resized.
- Persistent disks are storage service that are attached to VMs in Compute Engine or Kubernetes Engine. Persistent disks provide block storage on solid-state drives (SSDs) and hard disk drives (HDDs). SSDs are often used for low-latency applications where persistent disk performance is important. SSDs cost more than HDDs.
- Local SSDs have higher throughput and lower latency than standard persistent disks or SSD persistent disks. The data that you store on a local SSD persists only until the instance is stopped or deleted.
- SSH to individual instance (or RDP port:3389 to Windows instance).
- OS login. Set enable-oslogin in the instance metadata. Grant necessary IAM roles to the user/ service account.
- Add SSH key to instance metadata.
- Add the keys to the instances one at a time:
gcloud compute instances add-metadata
- Or add the keys to project metadata in case of multiple instances:
gcloud compute project-info add-metadata --metadata-from-file ssh-keys=[LIST_PATH].
It's only for advanced users who are unable to use other tools such as OS Login to manually manage SSH keys.
- Instance types can be changes (Stop the instance and change it's machine type. It's the way to update the instance memory size, either make customised change to the memory or select another machine type).
- Create snapshots of the persistent disk, even while they are attached to running instances. Unlike Compute Engine instances and persistent disks, snapshots are a global resource. Snapshots can be used to move an instancebetween zones(regions).
- Creating a custom image is good for reusing compute engine even across projects. Uncheck "Delete boot disk when instance is deleted" and then shut down the instance to create an image. Such an image can be uploaded to GCS and shared between projects.
- Live migration keeps the virtual machine instances running even when a host system event occurs, such as a software or hardware update. It migrates the running instances to another host in the same zone rather than requiring your VMs to be rebooted.
- Startup scripts can be used to perform automated tasks every time your instance boots up. It's specified through the metadata server, using startup script metadata keys.
- A project has a default compute engine service account to [PROJECT_NUMBER]-compute@developer.gserviceaccount.com
with role Project Editor. However this service account is only enabled to an instance if it's created via gcloud or console, not via API. Tochange the service account of an existing instance, the instance needs to be stopped. gcloud compute instances set-service-accountINSTANCE_NAME [--zone= ZONE ] [--scopes=[SCOPE ,…] | --no-scopes] [--service-account= SERVICE_ACCOUNT | --no-service-account][GCLOUD_WIDE_FLAG … ]
- All vCPU, GPU and memory resources are charged a minimum of 1 minute, after that per 1 second increment.
- Preemptible VMs.
- Managed instance groupsare suitable for stateless serving workloads (such as a website frontend) and for batch, high-performance, or high-throughput compute workloads (such as image processing from a queue).
- Auto healing. A managed instance group will automatically recreate an instance that is not RUNNING.
- Health checking are used to monitor managed instance groups are similar to the health checks used for load balancing, but it proactively signal to delete and recreate instances that becomeUNHEALTHY instead of direct traffic away from non-responsive instances and toward healthy instances.
- Load balancing. A codelab. <- do it!
- Auto scaling
- Unmanaged instance groups contain heterogeneous instances. Can't think of a scenario you should use it.
- An instance template is a global resource that is not bound to a zone or a region, though zonal resources specified in an instance template (e.g. zonal persistent disk) restricts the template to the zone where that resource resides.
- A VM instance can be assigned external and internal IP address. To communicate between instances on the same VPC , you can use an instance's internal IP addresses. To communicate with the Internet or instances outside of the same VPC network (unless there's a VPN), you must use the instance's external IP address.
- Static IP addresses are assigned to a project long term until they are explicitly released, and remain attached to a resource until they are explicitly detached.
- Ephemeral IP addresses remain attached to a VM instance only until the VM is stopped and restarted or the instance is terminated
- Communicating between instances in the same VPC network can use the internal DNS name [INSTANCE_NAME].([ZONE]).c.[PROJECT_ID].internal
- VPCs are global resource. Subnets are regional resources. Resources within a VPC network can communicate with one another using internal IPs.
- When an auto mode network is created, one subnet with 10.128.0.0/9 IP range from each region is automatically created within it.
- When a custom mode network is created, no subnets are automatically created.
- You can switch a network from auto mode to custom mode, but can't do it the other way round.
- To add a subnet to an existing VPC: gcloud compute networks subnets create [SUBNET_NAME] --network=[NETWORK] --range=[PRIMARY_RANGE] --region=[REGION]
- A subnet's IP range can be expanded by modifying its subnet mask, e.g. modify 10.1.2.0/24 to 10.1.2.0/20 to decrease its mask to 20 bits.
gcloud compute networks subnets expand-ip-range [SUBNET_NAME] --region=[REGION] --prefix-length=[PREFIX_LENGTH]
- To reserve a static external IP address: gcloud compute addresses create [ADDRESS_NAME] [--region [REGION] | --global ] [--ip-version [IPV4 | IPV6]]
- To reserve a static internal IP address gcloud compute addresses create [ADDRESS_NAME] [[ADDRESS_NAME]..] --region [REGION] --subnet [SUBNETWORK] --addresses [IP_ADDRESS]
- Shared VPC allows an organization to connect resources from multiple projects to a common VPC network so they can communicate with each other with internal IPs from that network. Shared VPC is hosted in a host project, with service projects attached to it.
- Network tags allow you to make firewall rules and routes applicable to specific VM instances.
- VPC monitoring and logging. For network monitoring, forensics, real-time security analysis, and expense optimization, you should use VPC Flow Logs, which record a sample of network flows sent from and received by VM instances. Flow logs can be viewed in Stackdriver Logging.
- Cloud Interconnect provides low latency, highly available connections that enable you to reliably transfer data between your on-premises and Virtual Private Cloud networks. Dedicated provides a direct physical connection between your on-premises network and Google's network. Partner provides connectivity between your on-premises and GCP VPC networks through a supported service provider.
- Load balancing: how to choose
- HTTP(S) LB: global, Target Proxy -> URL map -> Backend Service -> health check. A codelab. <- do it!
- SSL Proxy LB: global, SSL connections are terminated at the load balancing layer then proxied to the closest available instance group
- SSL certificates: https://cloud.google.com/load-balancing/docs/ssl-certificates
- TCP Proxy LB: global, TCP connection is terminated at the load balancing layer, then proxied to the closest available instance group
- Network TCP/UDP LB: regional, based on incoming IP protocol data,forwarding rules that point to target pools. It preserves IP address.
- Internal TCP/UDP LB: reginal, internal, distributes traffic among VM instances in the same region in a VPC network using a private internal IP address
- Create a VPN: A codelab.
- Create the target VPN gateway object.
- Reserve a regional external (static) IP address.
- Create three forwarding rules. These rules instruct GCP to send ESP (IPSec), UDP 500, and UDP 4500 traffic to the gateway. The forwarding rules forward traffic arriving on the external IP to the VPN gateway.
- Create the tunnels between the VPN gateways.
- Create a static route for each remote IP range of the on-premises network to forward local traffic to the VPN.
- GAE is regional. Its region cannot be changed once set. gcloud app describe --project <projectId>
- Standard environment: sandbox, rapid scaling, Python, Java, Node JS, PHP, Go
- Flexible environment: containers on VM, consistent traffic, experience regular traffic fluctuations, or meet the parameters for scaling up and down gradually.
- Instances are the basic building blocks of App Engine, providing all the resources needed to successfully host your application. Instances are resident or dynamic. A dynamic instance starts up and shuts down automatically based on the current needs. A resident instance runs all the time, which can improve your application's performance. If you use manual scaling for an app, the instances it runs on are resident instances. If you use either basic or automatic scaling , your app runs on dynamic instances.
- To deploy your web service to App Engine, you need an app.yaml file.
Deploy a service:
- With --no-promote flag gcloud app deploy --project PROJECT_ID --version VERSION_ID --no-promote
- Check the new version at http:// VERSION_ID.default. YOUR_PROJECT_ID.appspot.com
- Migrate the traffic to the new version
- Use traffic splitting to specify a percentage distribution of traffic across two or more of the versions within a service based on IP addresses, cookies or randomly. gcloud app services set-traffic serv1 --splits v1=.4,v2=.6
- Logs written to stdout are automatically collected and can be viewed in Stackdriver.
- A cluster consists of at least one cluster master and multiple worker machines called nodes.
- The cluster master runs the Kubernetes control plane processes, including the Kubernetes API server, scheduler, and core resource controllers.The master is the unified endpoint for your cluster.
- A node runs the services necessary to support the Docker containers that make up your cluster's workloads. These include the Docker runtime and the Kubernetes node agent (kubelet) which communicates with the master and is responsible for starting and running Docker containers scheduled on that node.
- To create:
gcloud container clusters create [CLUSTER_NAME] automatically authenticated kubectl for you
- To view: gcloud container clusters describe [CLUSTER_NAME]
- To upgrade: gcloud container clusters upgrade [CLUSTER_NAME]
- To resize: gcloud container clusters resize [CLUSTER_NAME] --node-pool [POOL_NAME] --size [SIZE]
- To enable auto-scaling: gcloud container clusters create [CLUSTER_NAME] --num-nodes 30 --enable-autoscaling --min-nodes 15 --max-nodes 50 [--zone [COMPUTE_ZONE]]
- To enable node auto-upgrade : gcloud container clusters create [CLUSTER_NAME] --zone [COMPUTE_ZONE] --enable-autoupgrade
- To enable node auto-repairing: gcloud container clusters create [CLUSTER_NAME] --zone [COMPUTE_ZONE] --enable-autorepair
- Cluster access for kubectlcan be configured by setting the current context in Kubernetes' kubeconfig file. Additionally, you can run kubectl commands against a specific cluster using the cluster flag. To switch the current context to my-cluster: gcloud container clusters get-credentials [CLUSTER_NAME]
- A cluster typically has one or more nodes, which are the worker machines that run your containerized applications and other workloads. A node poolis a group of nodes within a cluster that all have the same configuration. kubectl describe node [NODE_NAME]
- Pods are the smallest, most basic deployable objects in Kubernetes. A Pod represents a single instance of a running process in your cluster. Pods contain one or more containers, such as Docker containers. Generally create a set of identical Pods, called replicas, to run your application kubectl get pods kubectl delete
- Deployments represent a set of multiple, identical Pods with no unique identities. They are for stateless applications that use ReadOnlyMany or ReadWriteMany volumes mounted on multiple replicas, but are not well-suited for workloads that use ReadWriteOnce volumes.
- To create: kubectl apply -f [DEPLOYMENT_FILE]
- To inspect: kubectl get[(-o|--output=)json|yaml... kubectl describe deploymentsTo see in which order Pods are brought up and are removed
- To update:
- Rolling update menu in console
- kubectl apply -f [DEPLOYMENT_FILE]
- kubectl setupdate the Pod specification's image, resources, or selector fields
- kubectl edit to update a deployment directly from editor
- to roll back the update: kubectl rollout undo
- to inspect a rollout: kubectl rollout
- To scale: kubectl scale deployment [DEPLOYMENT_NAME] --replicas [NUMBER_OF_REPLICAS]
- To autoscale (based on CPU utilization): kubectl autoscale deployment my-app --max 6 --min 4 --cpu-percent 50
- To delete: kubectl delete deployment [DEPLOYMENT_NAME]
- StatefulSets represent a set of [Pods] with unique, persistent identities and stable hostnames that GKE maintains regardless of where they are scheduled. They are designed to deploy stateful applications to persistent storage, and are suitable for deploying Kafka, MySQL, Redis etc.
- DaemonSets are useful for deploying ongoing background tasks that you need to run on all or certain nodes, and which do not require user intervention. E.g. storage daemons like ceph, log collection daemons like fluentd, and node monitoring daemons like collectd.
- ConfigMaps are useful for storing and sharing non-sensitive, unencrypted configuration information.
- Secrets are secure objects which store sensitive data , such as passwords, OAuth tokens, and SSH keys, in your clusters. kubectl create secret [TYPE] [NAME] [DATA]
- Service is to group a set of Pod endpoints into a single resource. In a Kubernetes cluster, each Pod has an internal IP address. With a Service, you get a stable IP address that lasts for the life of the Service. A Service also provides load balancing.
A service can either be created by writing and run a manifest, or it can be done by exposing the Deployment. There are five types of services:
- ClusterIP (default): Internal clients send requests to a stable internal IP address.]
- NodePort: Clients send requests to the IP address of a node on one or more nodePort values that are specified by the Service.
- LoadBalancer: Clients send requests to the IP address of a network load balancer.
- ExternalName: Internal clients use the DNS name of a Service as an alias for an external DNS name.
- Headless: You can use a headless service in situations where you want a Pod grouping, but don't need a stable IP address.
- https://cloud.google.com/kubernetes-engine/docs/how-to/exposing-apps Create a Service by using kubectl expose to expose a Deployment: kubectl expose deployment my-deployment --name my-cip-service --type ClusterIP --protocol TCP --port 80 --target-port 8080 kubectl expose deployment my-deployment-50001 --name my-lb-service --type LoadBalancer --port 60000 --target-port 50001
- Monitoring and logging: When creating a cluster, you have Legacy Stackdriver support by default, but to alternatively select Stackdriver Kubernetes Monitoring support for your new cluster, add the --enable-stackdriver-kubernetes option. The intent of Stackdriver Kubernetes Monitoring is to provide a single option that enables improved support for both Stackdriver Monitoring and Stackdriver Logging in your clusters.
gcloud beta container clusters create [CLUSTER_NAME] --zone=[ZONE] --project=[PROJECT_ID]--cluster-version=1.10 --enable-stackdriver-kubernetes
- Codelab resources: <- do it! Hello Node Kubernetes Codelab Orchestrating the Cloud with Kubernetes Codelab Google Kubernetes Engine codelab (scaling involved)
- Google Cloud Functions is a serverless execution environment for building and connecting cloud services. Cloud Functions can be written using JavaScript, Python 3, or Go runtimes on Google Cloud Platform.
- Events are things that happen within your cloud environment that you might want to take action on.
- HTTP:POST,PUT,GET,DELETE, andOPTIONS
- Cloud Storage
- Google.storage.object.finalize This event is sent when a new object is created
- Google.storage.object.delete
- Google.storage.object.archive
- google.storage.object.metadataUpdate
- Cloud Pub/Sub
- Cloud Firestore
- Firebase (Realtime Database, Storage, Analytics, Auth)
- Stackdriver Logging—forward log entries to a Pub/Sub topic by creating a sink. You can then trigger the function.
- A trigger is a declaration that you are interested in a certain event or set of events.
- HTTP --trigger-http
- Google Cloud Storage --trigger-bucket BUCKET_NAME
- Google Cloud Pub/Sub --trigger-topic TOPIC_NAME
- Other sources (e.g. Firebase) --trigger-event EVENT_TYPE --trigger-resource RESOURCE
- gcloud functions deploy NAME --runtime RUNTIME** TRIGGER**[FLAGS...]
-
A configuration is a YAML file that lists each of the resources you want to create and its respective resource properties. Each resource must contain name, type (e.g. compute.v1.instance) and properties. A configuration can contain templates, which are essentially parts of the configuration file that has been abstracted into individual building blocks. A template is written in Python or Jinja2.
-
Creating a deployment: gcloud deployment-manager deployments create my-first-deployment --config vm.yaml
-
List the deployments: gcloud deployment-manager deployments list
-
Get the information of the deployment by describing the resources:
gcloud deployment-manager deployments describe my-first-deployment
- Update a deployment:
- Edit the configuration file
- Preview the changes gcloud deployment-manager deployments update deployment-with-startup-script --config config-with-many-templates.yaml --preview
- Get a description of the proposed changes to previous deployment:
gcloud deployment-manager resources describe the-first-vm --deployment deployment-with-startup-script
- Commit the update gcloud deployment-manager deployments update deployment-with-startup-script
- Unstructured data, binary large-object storage
- Objects are immutable, and new versions overwrite old unless you turn on versioning.
- Gcloud command (note all the commands are gsutil ):
- Create a new bucket: gsutil mb gs://[BUCKET_NAME]/
- Changing storage class: gsutil rewrite -s [STORAGE_CLASS] gs://[PATH_TO_OBJECT]
- Upload objects: gsutil cp [OBJECT_LOCATION] gs://[DESTINATION_BUCKET_NAME]/
- If you have a large number of files to transfer you might want to use the top-level gsutil -m option (see gsutil help options), to perform a parallel (multi-threaded/multi-processing) copy: gsutil -m cp -r dir gs://my-bucket
- Storage classes all have milliseconds access time. The only differences are the storage cost goes down, but the retrieval cost goes up:
- Multi-Regional Storage: frequently accessed, such as web content. most available.
- Regional Storage: in the same region as the service that uses the data. E.g. compute engine, virtual machines, or Kubernetes engine clusters.
- Nearline Storage: 30-day minimum storage duration, access once a month or less. Data backup. Data retrieval costs. E.g. continuously adding files to cloud storage and planning to access those files once a month for analysis.
- Coldline Storage: 90-day minimum storage duration. No more than once per year. Disaster recovery. Data retrieval costs. Higher per operation cost.
- Standard Storage: Users that create a bucket without specifying a default storage class see the bucket's default storage class listed asStandard Storage in the API. Standard Storage is equivalent to Multi-Regional Storage when the associated bucket is located in a multi-regional location. Standard Storage is equivalent to Regional Storage when the associated bucket is located in a regional location.
- A lifecycle management configuration to a bucket. The configuration contains a set of rules which apply to current and future objects in the bucket. When an object meets the criteria of one of the rules, Cloud Storage automatically performs a specified action on the object, e.g. delete objects created before January 1, 2013.
- Access control https://cloud.google.com/storage/docs/access-control/
- IAM: A Cloud IAM policy applied to your project defines the actions that users can take on all objects** or buckets** within your project. A Cloud IAM policy applied to a single bucket defines the actions that users can take on that specific bucket and objects within it. Project-level roles and bucket-level roles don't affect each other.
- ACL: use ACLs if you need to customize access to individual objects within a bucket, since Cloud IAM permissions apply to all objects within a bucket. An ACL consists of one or more entries, where each entry grants permissions (READER, WRITER, OWNER) to a scope.
- Signed URL provides limited permission and time to make a request, allowing users without credentials to perform specific actions on a resource. It is used when not requiring users to have a Google account to access GCS.
- Making individual objects in the bucket publicly readable. gsutil acl ch -u AllUsers:R gs://[BUCKET_NAME]/[OBJECT_NAME]
- To make all objects in a bucket publicly readable:gsutil iam ch allUsers:objectViewer gs://[BUCKET_NAME]
- Hosting static website: Create a CNAME record that points to c.storage.googleapis.com https://cloud.google.com/storage/docs/hosting-static-website
- The most commonly set metadata is Content-Type (also known as media type), which allows browsers to render the object properly.
- There is a maximum size limit of 5 TB for individual objects stored in Cloud Storage
- Data transfer:
- Online transfer
- Storage transfer service: schedule and manage batch transfers to cloud storage from another cloud provider (e.g. AWS) from a different cloud storage region or from an HTTPs endpoint
- Transfer appliance
- Fully-managed service that provides MySQL (1st generation up to 500G, 2nd generation up to 10 TB) and PostgreSQL (up to 10 TB storage) only
- It's regional.
- If an HA-configured instance becomes unresponsive, Cloud SQL automatically switches to serving data from the failover replica. This is called a failover. High availability configuration for MySQL Second Generation instances is made up of a primary instance (master) in the primary zone and a failover replica in the secondary zone. The failover replica is configured with the same database flags, users (including root) and passwords, authorized applications and networks, and databases as the primary instance.
- Aread replica is a copy of the master that reflects changes to the master instance in almost real time. It gives additional read capacity. Read replicas do not provide failover capability. To provide failover capability for a Second Generation instance, see Configuring an Instance for High Availability.
- Backups provide a way to restore your Cloud SQL instance to recover lost data or recover from a problem with your instance. Cloud SQL retains up to 7 automated backups for each instance.
- An instance can be restored from a backup or performing a point-in-time recovery (PITR). Point-in-time recovery enables you to recover an instance to a specific point in time. To perform a point-in-time recovery, your source instance must have Automate backups and Enable binary logging selected.
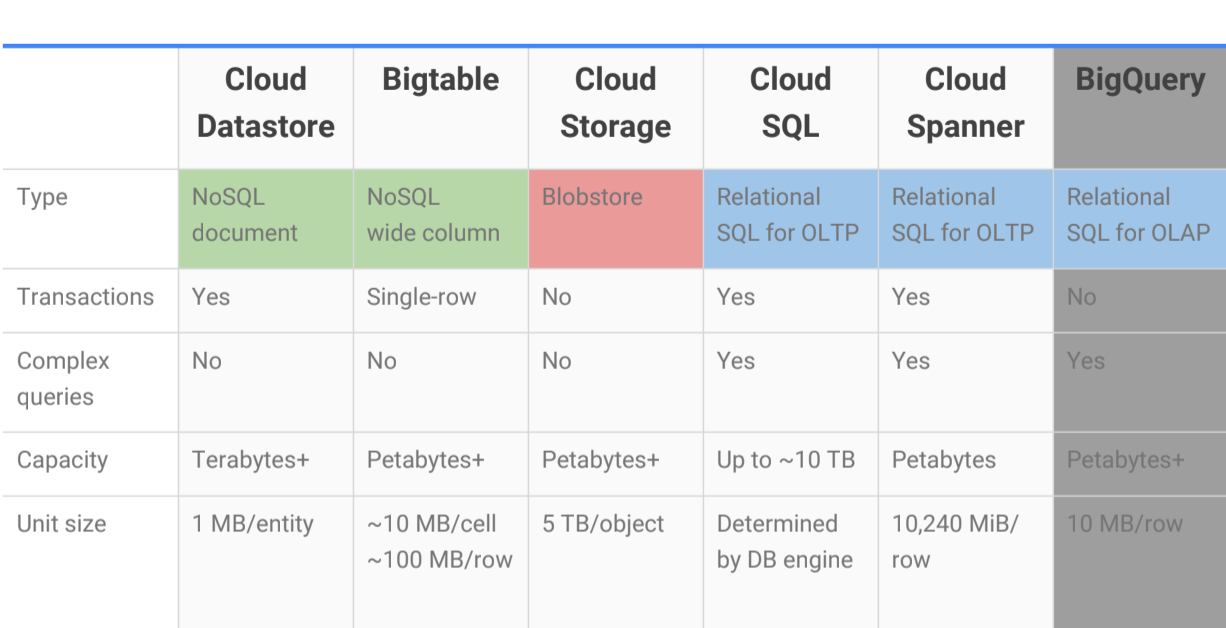
- Global transactional consistency, schemas, SQL, automatic synchronous replication for high availability and pedabytes of capacity. E.g. financial applications and inventory applications.
- Very expensive
- NoSQL, structured data, highly scalable.
- Free daily quota
- NoSQL (HBase): not all the rows need to have the same columns; sparsely populated rows. Highly scalable. E.g. streaming data.
- Enterprise data warehouse with SQL and fast ad-hoc queries.
- BigQuery stores data in the Capacitor columnar data format, and offers the standard database concepts of tables, partitions, columns, and rows
- Permissions can be granted at organization or project level, but can also be granted at dataset level. Also note the IAM roles, especially bigquery.jobUser and bigquery.user are different.
https://cloud.google.com/bigquery/docs/access-control
- bigquery.jobUser can run or cancel jobs
- Bigquery.user can run or cancel jobs, enumerate datasets within a project and allow the creation of new datasets
- Storage costs and query costs
- Active and long-term storage costs
- On-demand and flat-rate query costs

{kind=link}