基于UniLM思想、融检索与生成于一体的BERT模型。
权重下载:https://github.com/ZhuiyiTechnology/pretrained-models
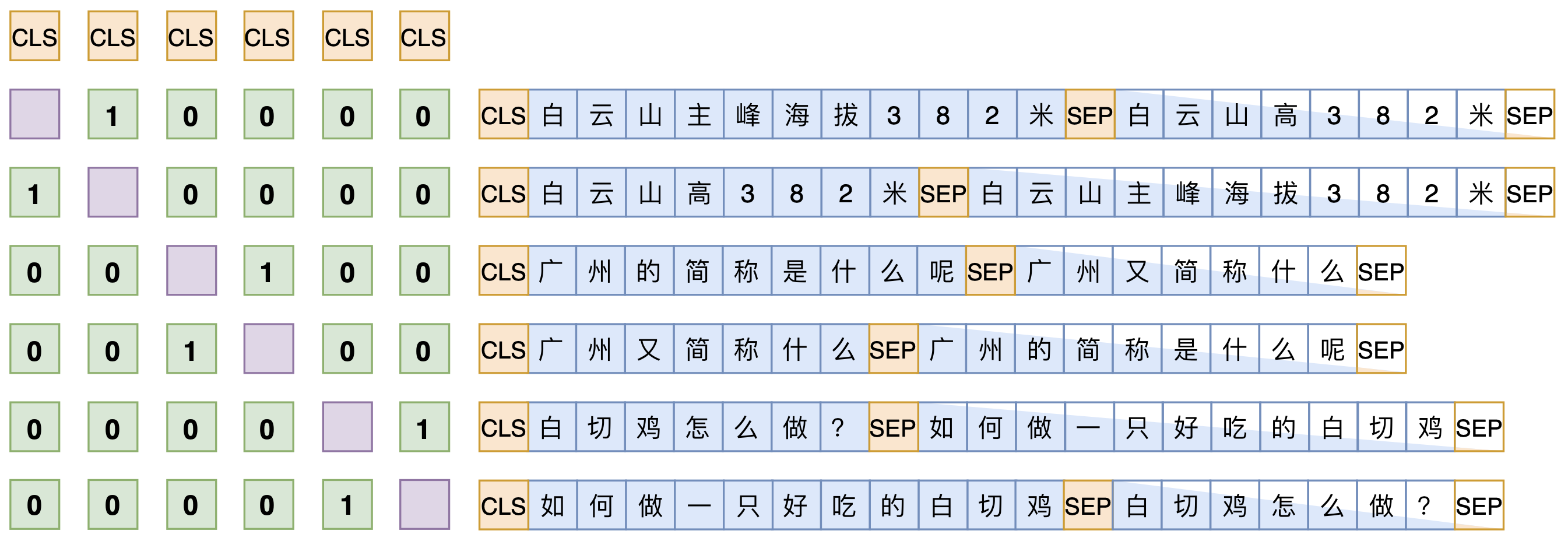
假设SENT_a和SENT_b是一组相似句,那么在同一个batch中,把[CLS] SENT_a [SEP] SENT_b [SEP]和[CLS] SENT_b [SEP] SENT_a [SEP]都加入训练,做一个相似句的生成任务,这是Seq2Seq部分。
另一方面,把整个batch内的[CLS]向量都拿出来,得到一个bxd的句向量矩阵V(b是batch_size,d是hidden_size),然后对d维度做l2归一化,得到新的V,然后两两做内积,得到bxv的相似度矩阵VV^T,接着乘以一个scale(我们取了30),并mask掉对角线部分,最后每一行进行softmax,作为一个分类任务训练,每个样本的目标标签是它的相似句(至于自身已经被mask掉)。说白了,就是把batch内所有的非相似样本都当作负样本,借助softmax来增加相似样本的相似度,降低其余样本的相似度。
详细介绍请看:https://kexue.fm/archives/7427
tensorflow 1.14 + keras 2.3.1 + bert4keras 0.7.7
Bibtex:
@techreport{simbert,
title={SimBERT: Integrating Retrieval and Generation into BERT},
author={Jianlin Su},
year={2020},
url="https://github.com/ZhuiyiTechnology/simbert",
}追一科技:https://zhuiyi.ai