UM4: Unified Multilingual Multiple Teacher-Student Model for Zero-Resource Neural Machine Translation
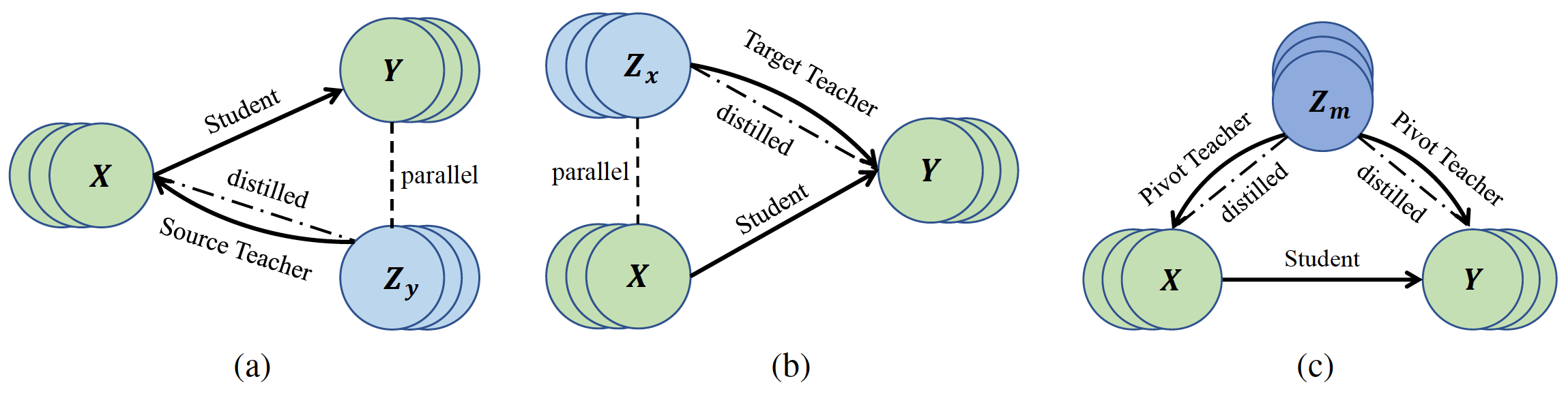
Most translation tasks among languages belong to the zero-resource translation problem where parallel corpora are unavailable. Multilingual neural machine translation (MNMT) enables one-pass translation using shared semantic space for all languages compared to the two-pass pivot translation but often underperforms the pivot-based method. In this paper, we propose a novel method, named as Unified Multilingual Multiple teacher-student Model for NMT (UM4). Our method unifies source-teacher, target-teacher, and pivot-teacher models to guide the student model for the zero-resource translation. The source teacher and target teacher force the student to learn the direct source to target translation by the distilled knowledge on both source and target sides. The monolingual corpus is further leveraged by the pivot-teacher model to enhance the student model. Experimental results demonstrate that our model of 72 directions significantly outperforms previous methods on the WMT benchmark.
- Download
- Download Here (training set; test set; spm model; dictionary): Google Drive
- Raw Training/Test Data & SPM (SentencePiece) model & Multilingual Dictionary
- Overview
- Multilingual dataset with 9 languages and 56 zero-resource translation directions.
- English (En), French (Fr), Czech (Cs), German(De), Finnish (Fi), Estonian (Et), Romanian (Ro), Hindi(Hi), and Turkish (Tr).
- English (En) is treated as the pivot language. The other 8 languages form (8 * (8 - 1)) = 56 zero-resource translation directions.
- Bitext Data
- All the bitext training data (e.g., Fr-En, Ro-En, En-Hi) are from the WMT benchmark of recent years.
- For 72 = (9 * (9 - 1)) translation directions of 9 languages, TED Talk dataset is used as the valid and test sets.
- Monolingual Data
- The English monolingual data is collected from NewsCrawl and randomly sample 1 million English sentences.
Statistics of the original pivot corpora (for training) from the WMT benchmark of 8 language pairs:
| Language | #Bitext | Training | Valid |
|---|---|---|---|
| Fr (French) | 10.0M | WMT15 | Newstest13 |
| Cs (Czech) | 10.0M | WMT19 | Newstest16 |
| De (German) | 4.6M | WMT19 | Newstest16 |
| Fi (Finnish) | 4.8M | WMT19 | Newstest16 |
| Et (Estonian) | 0.7M | WMT18 | Newstest18 |
| Ro (Romanian) | 0.5M | WMT16 | Newstest16 |
| Hi (Hindi) | 0.26M | WMT14 | Newstest14 |
| Tr (Turkish) | 0.18M | WMT18 | Newstest16 |
Statistics of the size of the distilled training corpora generated by our method:
| X-Y | Fr | Cs | De | Fi | Et | Ro | Hi | Tr |
|---|---|---|---|---|---|---|---|---|
| Fr | - | 20.3M | 14.6M | 14.8M | 10.7M | 10.5M | 10.3M | 10.2M |
| Cs | 20.3M | - | 14.9M | 15.1M | 11.0M | 10.8M | 10.5M | 10.5M |
| De | 14.6M | 14.9M | - | 9.5M | 5.3M | 5.2M | 4.9M | 4.8M |
| Fi | 14.8M | 15.1M | 9.5M | - | 5.5M | 5.4M | 5.1M | 5.0M |
| Et | 10.7M | 11.0M | 5.3M | 5.5M | - | 1.2M | 1.0M | 0.9M |
| Ro | 10.5M | 10.8M | 5.2M | 5.4M | 1.2M | - | 0.8M | 0.7M |
| Hi | 10.3M | 10.5M | 4.9M | 5.1M | 1.0M | 0.8M | - | 0.4M |
| Tr | 10.2M | 10.5M | 4.8M | 5.0M | 0.9M | 0.7M | 0.4M | - |
cd UM4
pip install --editable ./- For faster training install NVIDIA's apex library:
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" \
--global-option="--deprecated_fused_adam" --global-option="--xentropy" \
--global-option="--fast_multihead_attn" ./- Training with the Source and Target Teacher:
TEXT=/path/to/data-bin/
MODEL=/path/to/model/
python -m torch.distributed.launch \
--nproc_per_node=8 --nnodes=4 --node_rank=${OMPI_COMM_WORLD_RANK} \
--master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} train.py ${TEXT} \
--save-dir ${MODEL} --arch "transformer_vaswani_wmt_en_de_big" --task "translation_multi_simple_epoch" \
--sampling-method "linear" --sampling-temperature 5.0 --min-sampling-temperature 1.0 \
--encoder-langtok "tgt" --langtoks '{"main":("tgt",None)}' --langs "fr,cs,de,fi,et,ro,hi,tr" \
--lang-pairs "fr-cs,fr-de,fr-fi,fr-et,fr-ro,fr-hi,fr-tr,cs-fr,cs-de,cs-fi,cs-et,cs-ro,cs-hi,cs-tr,de-fr,de-cs,de-fi,de-et,de-ro,de-hi,de-tr,fi-fr,fi-cs,fi-de,fi-et,fi-ro,fi-hi,fi-tr,et-fr,et-cs,et-de,et-fi,et-ro,et-hi,et-tr,ro-fr,ro-cs,ro-de,ro-fi,ro-et,ro-hi,ro-tr,hi-fr,hi-cs,hi-de,hi-fi,hi-et,hi-ro,hi-tr,tr-fr,tr-cs,tr-de,tr-fi,tr-et,tr-ro,tr-hi" \
--share-all-embeddings --max-source-positions 512 --max-target-positions 512 \
--criterion "label_smoothed_cross_entropy" --label-smoothing 0.1 \
--optimizer adam --adam-betas '(0.9, 0.98)' --lr-scheduler inverse_sqrt --lr 5e-4 \
--warmup-init-lr 1e-07 --stop-min-lr 1e-09 --warmup-epoch 5 --warmup-updates 4000 \
--max-update 10000000 --max-epoch 24 --max-tokens 4096 --update-freq 4 --score-size 4 \
--seed 1 --log-format simple --skip-invalid-size-inputs-valid-test \
--fp16 --truncate-source --virtual-epoch-size 100000000 2>&1 | tee -a ${MODEL}/train.log- Training with the Source, Target, and Pivot Teacher:
TEXT=/path/to/data-bin/
PSEUDO_TEXT=/path/to/pseudo-data-bin/
MODEL=/path/to/model/
python -m torch.distributed.launch \
--nproc_per_node=8 --nnodes=4 --node_rank=${OMPI_COMM_WORLD_RANK} \
--master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} train.py ${TEXT} \
--save-dir ${MODEL} --arch "transformer_vaswani_wmt_en_de_big" --task "translation_multi_simple_epoch" \
--sampling-method "linear" --sampling-temperature 5.0 --min-sampling-temperature 1.0 \
--encoder-langtok "tgt" --langtoks '{"main":("tgt",None),"pseudo":("tgt",None)}' --langs "fr,cs,de,fi,et,ro,hi,tr" \
--lang-pairs "fr-cs,fr-de,fr-fi,fr-et,fr-ro,fr-hi,fr-tr,cs-fr,cs-de,cs-fi,cs-et,cs-ro,cs-hi,cs-tr,de-fr,de-cs,de-fi,de-et,de-ro,de-hi,de-tr,fi-fr,fi-cs,fi-de,fi-et,fi-ro,fi-hi,fi-tr,et-fr,et-cs,et-de,et-fi,et-ro,et-hi,et-tr,ro-fr,ro-cs,ro-de,ro-fi,ro-et,ro-hi,ro-tr,hi-fr,hi-cs,hi-de,hi-fi,hi-et,hi-ro,hi-tr,tr-fr,tr-cs,tr-de,tr-fi,tr-et,tr-ro,tr-hi" \
--share-all-embeddings --max-source-positions 512 --max-target-positions 512 \
--criterion "label_smoothed_cross_entropy" --label-smoothing 0.1 \
--optimizer adam --adam-betas '(0.9, 0.98)' --lr-scheduler inverse_sqrt --lr 5e-4 \
--warmup-init-lr 1e-07 --stop-min-lr 1e-09 --warmup-epoch 5 --warmup-updates 4000 \
--max-update 10000000 --max-epoch 24 --max-tokens 4096 --update-freq 4 --score-size 4 \
--seed 1 --log-format simple --skip-invalid-size-inputs-valid-test \
--fp16 --truncate-source --virtual-epoch-size 100000000 \
--extra-data {'pseudo':'${PSEUDO_TEXT}'} --extra-lang-pairs {'pseudo':'fr-cs,fr-de,fr-fi,fr-et,fr-ro,fr-hi,fr-tr,cs-fr,cs-de,cs-fi,cs-et,cs-ro,cs-hi,cs-tr,de-fr,de-cs,de-fi,de-et,de-ro,de-hi,de-tr,fi-fr,fi-cs,fi-de,fi-et,fi-ro,fi-hi,fi-tr,et-fr,et-cs,et-de,et-fi,et-ro,et-hi,et-tr,ro-fr,ro-cs,ro-de,ro-fi,ro-et,ro-hi,ro-tr,hi-fr,hi-cs,hi-de,hi-fi,hi-et,hi-ro,hi-tr,tr-fr,tr-cs,tr-de,tr-fi,tr-et,tr-ro,tr-hi'} 2>&1 | tee -a ${MODEL}/train.log- Beam Search: (during the inference) beam size = 5; length penalty = 1.0.
- Metrics: the case-sensitive detokenized BLEU using sacreBLEU:
- BLEU+case.mixed+lang.{src}-{tgt}+numrefs.1+smooth.exp+tok.13a+version.1.3.1
- Bilingual Pivot translates source to target via pivot language using two single-pair NMT models trained on each pair. (Joint Training for Pivot-based Neural Machine Translation)
- Multilingual Pivot leverages a single multilingual NMT model trained in all available directions for pivot translation. (Multilingual Neural Machine Translation for Zero-Resource Languages)
- Multilingual shares the same vocabulary of all languages and prepends the language symbol to the source sentence to indicate the translation directions. (Google's Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation)
- Teacher-Student uses the pivot-target translation model to teach the source-target translation model. (A Teacher-Student Framework for Zero-Resource Neural Machine Translation)
- Monolingual Adapter tunes adapter of each language for zero-shot translation based on a pretrained multilingual model. (Monolingual Adapters for Zero-Shot Neural Machine Translation)
- MTL proposes a multi-task learning (MTL) framework including the translation task and two denoising tasks. (Multi-task Learning for Multilingual Neural Machine Translation)
- BT: back translation. (Improving Neural Machine Translation Models with Monolingual Data)
28 high-to-low zero-resource directions, trained on Parallel Data (Bitext):
| X (High) to Y (Low) | Fr-Fi | Cs-Fi | Cs-Ro | Cs-Hi | De-Et | Fi-Et | Fi-Ro | Fi-Tr | Avg (8) | Avg (28) |
|---|---|---|---|---|---|---|---|---|---|---|
| Bilingual Pivot | 13.5 | 13.4 | 15.2 | 2.6 | 13.4 | 12.7 | 13.1 | 3.2 | 10.9 | 9.5 |
| Multilingual Pivot | 12.5 | 11.9 | 16.1 | 6.9 | 14.8 | 13.3 | 14.0 | 5.3 | 11.9 | 11.2 |
| Multilingual | 3.8 | 10.2 | 12.6 | 5.1 | 12.5 | 12.0 | 10.7 | 4.0 | 8.9 | 8.1 |
| Teacher-Student | 13.0 | 13.6 | 16.4 | 7.1 | 15.6 | 14.6 | 14.6 | 5.0 | 12.5 | 10.9 |
| Monolingual Adapter | 8.2 | 10.7 | 14.3 | 5.9 | 12.1 | 12.6 | 12.4 | 4.8 | 10.1 | 9.2 |
| MTL | 6.0 | 9.0 | 13.0 | 6.0 | 14.3 | 12.0 | 11.7 | 4.6 | 9.6 | 8.9 |
| UM4 (w/o pivot-teacher) | 13.8 | 13.9 | 16.8 | 7.3 | 16.3 | 14.9 | 15.1 | 5.4 | 12.9 | 11.8 |
28 high-to-low zero-resource directions, trained on Parallel and Monolingual Data (Bitext + MonoData):
| X (High) to Y (Low) | Fr-Fi | Cs-Fi | Cs-Ro | Cs-Hi | De-Et | Fi-Et | Fi-Ro | Fi-Tr | Avg (8) | Avg (28) |
|---|---|---|---|---|---|---|---|---|---|---|
| Bilingual Pivot + BT | 13.9 | 13.4 | 16.3 | 6.9 | 15.3 | 13.7 | 13.6 | 4.8 | 12.2 | 11.0 |
| Multilingual Pivot + BT | 13.5 | 12.6 | 16.0 | 6.7 | 14.8 | 13.3 | 14.0 | 5.6 | 12.1 | 11.2 |
| Multilingual + BT | 7.5 | 10.2 | 14.4 | 5.7 | 12.5 | 12.9 | 10.7 | 5.3 | 9.9 | 9.4 |
| Teacher-Student + BT | 13.6 | 13.0 | 16.6 | 6.8 | 15.2 | 14.8 | 15.2 | 5.5 | 12.6 | 11.6 |
| Monolingual Adapter + BT | 10.8 | 7.6 | 15.1 | 5.0 | 15.4 | 14.1 | 14.1 | 5.4 | 10.9 | 10.0 |
| MTL + BT | 10.6 | 9.0 | 13.5 | 5.4 | 12.7 | 12.8 | 12.8 | 5.2 | 10.3 | 8.0 |
| UM4 | 14.1 | 14.1 | 17.1 | 7.4 | 16.2 | 15.0 | 15.8 | 5.9 | 13.2 | 12.4 |
28 low-to-high zero-resource directions, trained on Parallel Data (Bitext):
| X (Low) to Y (High) | Fr-Fi | Cs-Fi | Cs-Ro | Cs-Hi | De-Et | Fi-Et | Fi-Ro | Fi-Tr | Avg (8) | Avg (28) |
|---|---|---|---|---|---|---|---|---|---|---|
| Bilingual Pivot | 15.5 | 15.3 | 11.0 | 14.6 | 16.8 | 11.8 | 10.0 | 5.8 | 12.6 | 11.1 |
| Multilingual Pivot | 14.6 | 16.3 | 12.9 | 15.1 | 18.2 | 14.0 | 15.7 | 9.9 | 14.6 | 13.6 |
| Multilingual | 11.4 | 12.5 | 10.1 | 12.1 | 15.6 | 10.7 | 7.2 | 5.2 | 10.6 | 9.2 |
| Teacher-Student | 16.0 | 17.9 | 14.1 | 16.0 | 19.1 | 15.1 | 16.4 | 11.0 | 15.7 | 13.6 |
| Monolingual Adapter | 11.8 | 14.7 | 11.5 | 13.1 | 16.4 | 12.2 | 11.7 | 7.8 | 12.4 | 10.4 |
| MTL | 11.7 | 15.1 | 10.1 | 13.0 | 16.1 | 12.5 | 10.4 | 7.0 | 12.0 | 10.4 |
| UM4 (w/o pivot-teacher) | 16.6 | 18.5 | 14.2 | 16.3 | 19.9 | 15.4 | 17.1 | 11.3 | 16.2 | 14.7 |
28 low-to-high zero-resource directions, trained on Parallel and Monolingual Data (Bitext + MonoData):
| X (Low) to Y (High) | Fr-Fi | Cs-Fi | Cs-Ro | Cs-Hi | De-Et | Fi-Et | Fi-Ro | Fi-Tr | Avg (8) | Avg (28) |
|---|---|---|---|---|---|---|---|---|---|---|
| Bilingual Pivot + BT | 15.0 | 17.0 | 12.3 | 16.0 | 18.6 | 13.9 | 14.6 | 9.0 | 14.6 | 13.8 |
| Multilingual Pivot + BT | 16.2 | 17.4 | 12.8 | 15.8 | 19.4 | 14.2 | 16.7 | 10.4 | 15.4 | 14.1 |
| Multilingual + BT | 13.6 | 16.3 | 12.3 | 14.9 | 16.1 | 12.7 | 12.1 | 8.6 | 13.3 | 11.3 |
| Teacher-Student + BT | 16.6 | 19.0 | 13.8 | 16.5 | 20.0 | 15.0 | 16.8 | 10.9 | 16.1 | 14.3 |
| Monolingual Adapter + BT | 13.8 | 13.8 | 11.6 | 15.6 | 11.7 | 13.7 | 13.4 | 9.6 | 12.9 | 10.8 |
| MTL + BT | 12.8 | 16.6 | 11.5 | 13.9 | 17.0 | 13.0 | 14.2 | 8.7 | 13.5 | 11.7 |
| UM4 | 17.6 | 19.6 | 14.3 | 17.2 | 20.7 | 15.6 | 17.5 | 11.5 | 16.8 | 15.1 |
Ablation study on different teachers. "Avg (56)" denotes the average BLEU points of 56 zero-resource translation directions.
| Source | Target | Mono | Fr-De | De-Ro | Et-Ro | Avg (56) |
|---|---|---|---|---|---|---|
| ✓ | . | . | 21.3 | 17.0 | 14.5 | 12.3 |
| . | ✓ | . | 21.4 | 16.2 | 15.2 | 13.0 |
| . | . | ✓ | 22.5 | 17.2 | 15.4 | 12.7 |
| . | ✓ | ✓ | 22.4 | 17.5 | 15.8 | 13.4 |
| ✓ | . | ✓ | 22.3 | 16.5 | 14.6 | 12.6 |
| ✓ | ✓ | . | 21.7 | 17.5 | 15.6 | 13.3 |
| ✓ | ✓ | ✓ | 22.8 | 17.7 | 16.4 | 13.7 |
- arXiv: https://arxiv.org/abs/2207.04900
- IJCAI Anthology: https://www.ijcai.org/proceedings/2022/618
@inproceedings{um4,
title = {UM4: Unified Multilingual Multiple Teacher-Student Model for Zero-Resource Neural Machine Translation},
author = {Yang, Jian and Yin, Yuwei and Ma, Shuming and Zhang, Dongdong and Wu, Shuangzhi and Guo, Hongcheng and Li, Zhoujun and Wei, Furu},
booktitle = {Proceedings of the Thirty-First International Joint Conference on
Artificial Intelligence, {IJCAI-22}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
editor = {Lud De Raedt},
pages = {4454--4460},
year = {2022},
month = {7},
note = {Main Track},
doi = {10.24963/ijcai.2022/618},
url = {https://doi.org/10.24963/ijcai.2022/618},
}Please refer to the LICENSE file for more details.
If there is any question, feel free to create a GitHub issue or contact us by Email.