


Information is crucial to the function of a democratic society where well-informed citizens can make rational political decisions. While in the past political entities were primarily utilizing newspaper and later television to inform the public, with the rise of the Internet and online social media, the political arena has transformed into a more complex structure. So, it is essential to see how people on the Internet, particularly on Twitter, think about the presidential election candidates.
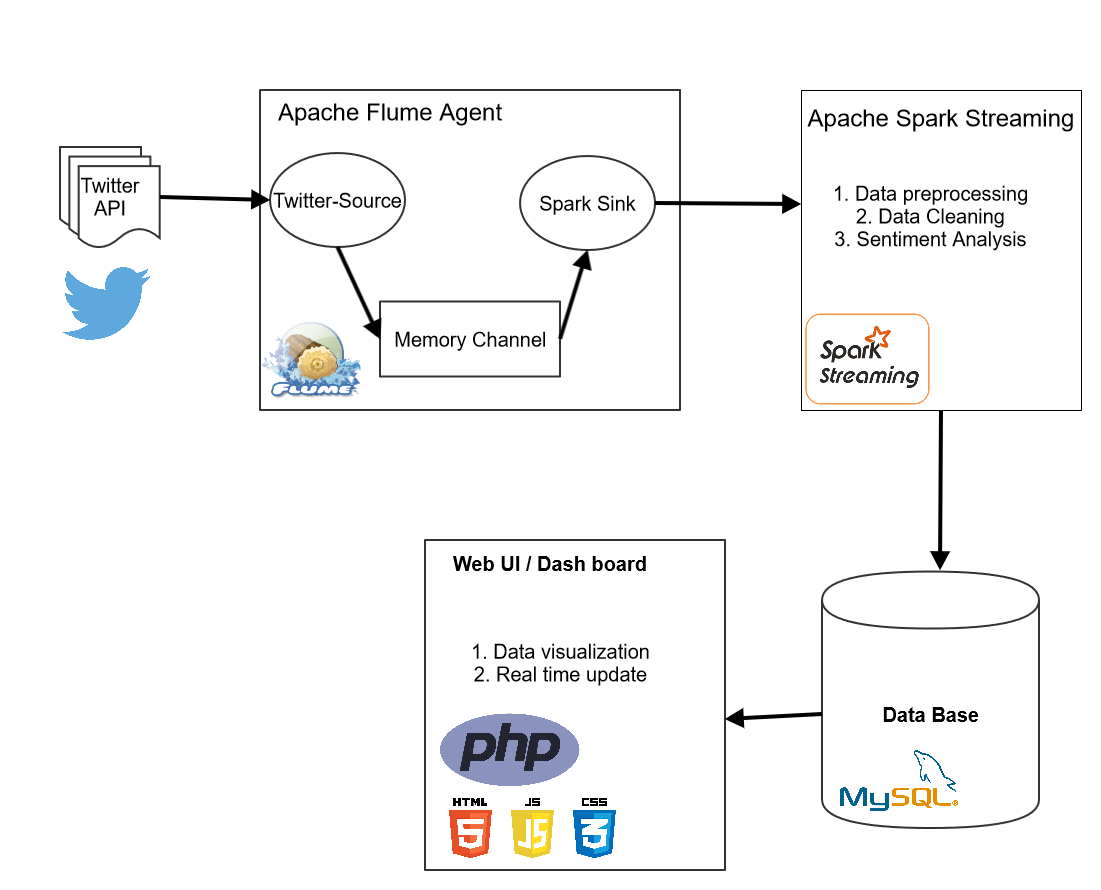
This is the back-end implementation of this project
To get a local copy up and running follow these simple steps.
- VPS with CentOS, so the analysis dashboard can also work. Local VM can also be used as proof of concept.
- Twitter API
- Install/configure Apache Flume and Apache Spark on VPS correctly, make sure using CDH version of Flume.
- Make sure $FLUME_HOME/lib has the following .jar files:
- Create Flume configuration file twitter.conf in $FLUME_HOME/conf
- Make sure $SPARK_HOME/jar has the following .jar files:
- ejml-0.23.jar here
- fastjson-1.2.73.jar here
- mysql-connector-java-5.1.47.jar here
- stanford-corenlp-3.5.1.jar here
- stanford-corenlp-3.5.1-models.jar here
- Install IDEA and Scala plugin on your local computer.
- Clone the project to local computer, load all the repositories on the pom.xml, and Maven build the Twitter_Flume_SparkStreaming-1.0-SNAPSHOT.jar.
- Create new dir /root/lib on VPS, and upload the Twitter_Flume_SparkStreaming-1.0-SNAPSHOT.jar.
- Start MySQL service
- Create new table 'tweets' using (
create table tweets ( id INT(100) AUTO_INCREMENT PRIMARY KEY, time VARCHAR(200), name VARCHAR(100), text TEXT, sentiment VARCHAR(30), source VARCHAR(100) );)
- Start Flume service in $FLUME_HOME/bin, using this command:
(
nohup ./flume-ng agent \ --conf ./root/app/apache-flume-1.6.0-cdh5.7.0-bin/conf/ \ -f /root/app/apache-flume-1.6.0-cdh5.7.0-bin/conf/twitter.conf \ Dflume.root.logger=DEBUG,console -n TwitterAgent >flume.log 2>&1 &) - Start Spark Service in $SPARK_HOME/bin, using this command:
(
nohup ./spark-submit \ --class Stefanzhang.com.Twitter \ --master local[2] \ --name Twitter \ --packages org.apache.spark:spark-streaming-flume_2.11:2.2.0 \ /root/lib/Twitter_Flume_SparkStreaming-1.0-SNAPSHOT.jar tweets [DB Password] [Host IP] [Flume Port] >spark.log 2>&1 &) - Logs will be output into flume.log and spark.log for debug.
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
Distributed under the MIT License. See LICENSE for more information.
Xiaofeng(Stefan) Zhang - xzhang23@wpi.edu
Project Link: https://github.com/StefanZhang/TwitterRealTimeAnalysis