IQN #139
IQN #139
Conversation
Results comparison
|




|
@qgallouedec Thank you for adding this. I wanted to report that for me it works well and I was able to adapt it to implement the paper Self-Imitation Advantage Learning New replay buffer to store discounted returns ( and updated training loop: The extra parameters I found immediately that SAIL-IQN performs nicely on sparse rewards so am quite happy with my initial results but by no means has my testing been thorough. |
|
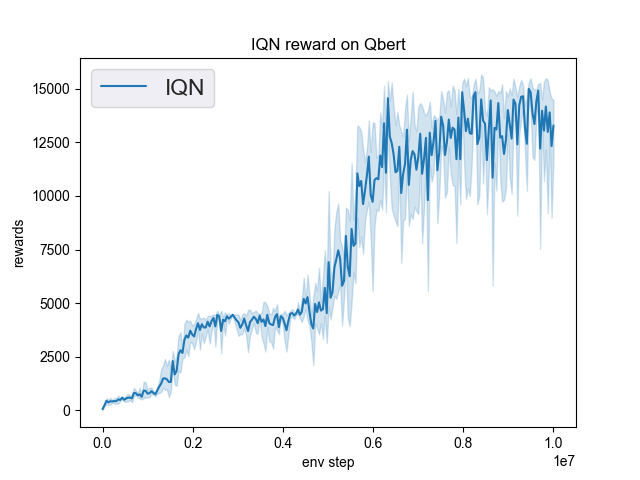
Thanks for your feedback @emrul! This PR is still draft because I can't replicate exactly the results of the paper for Qbert. I don't know if it's a hyperparameter problem or something else, I'm still looking. I think SIL (and probably maybe SAIL) would fit in SB3-contrib. However, it would be best to discuss it in a dedicated issue. I'll open it right away. |
|
Thanks @qgallouedec - I didn't know there's a reproduction issue, I will look into this also - I compared your implementation with the Dopamine one and the Medipexel/pytorch port of that and it looked quite different. I will dig in to see where they differ and feedback if I find anything to assist. |
Description
Context
Types of changes
Checklist:
make format(required)make check-codestyleandmake lint(required)make pytestandmake typeboth pass. (required)Note: we are using a maximum length of 127 characters per line