A High Level Deep Learning library made from scratch (just using numpy/cupy). Backprop is fully automated. Just specify layers, loss function and optimizers. Model will backpropagate itself. Just made to learn deep working and backpropogation of CNNs and various machine learning algorithms. Deriving and making it gave alot of insight to how it all works. Will keep adding new networks and algorithms in future.
python3 -m pip install git+https://github.com/ShivamShrirao/dnn_from_scratch.gitOr for development
git clone https://github.com/ShivamShrirao/dnn_from_scratch.git
python3 -m pip install -e dnn_from_scratchCheck Examples and Implementations below.
| Descriptions | Repository Link |
|---|---|
| Basic CNNs and ANNs on CIFAR,MNIST... | https://github.com/ShivamShrirao/dnn_scratch_basic_implementations |
| Basic GANs | https://github.com/ShivamShrirao/GANs_from_scratch |
| Deep Q learning | https://github.com/ShivamShrirao/deep_Q_learning_from_scratch |
from nnet_gpu.network import Sequential
from nnet_gpu.layers import Conv2D,MaxPool,Flatten,Dense,Dropout,BatchNormalization,GlobalAveragePool
from nnet_gpu import optimizers
from nnet_gpu import functions
import numpy as np
import cupy as cpAdd each layer to the Sequential model with parameters.
model=Sequential()
model.add(Conv2D(num_kernels=32,kernel_size=3,activation=functions.relu,input_shape=(32,32,3)))
model.add(Conv2D(num_kernels=32,kernel_size=3,stride=(2,2),activation=functions.relu))
model.add(BatchNormalization())
# model.add(MaxPool())
model.add(Dropout(0.1))
model.add(Conv2D(num_kernels=64,kernel_size=3,activation=functions.relu))
model.add(Conv2D(num_kernels=64,kernel_size=3,stride=(2,2),activation=functions.relu))
model.add(BatchNormalization())
# model.add(MaxPool())
model.add(Dropout(0.2))
model.add(Conv2D(num_kernels=128,kernel_size=3,activation=functions.relu))
model.add(Conv2D(num_kernels=128,kernel_size=3,stride=(2,2),activation=functions.relu))
model.add(BatchNormalization())
# model.add(GlobalAveragePool())
# model.add(MaxPool())
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(128,activation=functions.relu))
model.add(BatchNormalization())
model.add(Dense(10,activation=functions.softmax))Shows each layer in a sequence, shape, activations and total, trainable, non-trainable parameters.
model.summary()⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽⎽
Layer (type) Output Shape Activation Param #
==========================================================================================
- InputLayer(InputLayer) (None, 32, 32, 3) echo 0
__________________________________________________________________________________________
0 Conv2D(Conv2D) (None, 32, 32, 32) relu 896
__________________________________________________________________________________________
1 Conv2D(Conv2D) (None, 16, 16, 32) relu 9248
__________________________________________________________________________________________
2 BatchNormalization(Batc (None, 16, 16, 32) echo 128
__________________________________________________________________________________________
3 Dropout(Dropout) (None, 16, 16, 32) echo 0
__________________________________________________________________________________________
4 Conv2D(Conv2D) (None, 16, 16, 64) relu 18496
__________________________________________________________________________________________
5 Conv2D(Conv2D) (None, 8, 8, 64) relu 36928
__________________________________________________________________________________________
6 BatchNormalization(Batc (None, 8, 8, 64) echo 256
__________________________________________________________________________________________
7 Dropout(Dropout) (None, 8, 8, 64) echo 0
__________________________________________________________________________________________
8 Conv2D(Conv2D) (None, 8, 8, 128) relu 73856
__________________________________________________________________________________________
9 Conv2D(Conv2D) (None, 4, 4, 128) relu 147584
__________________________________________________________________________________________
10 BatchNormalization(Bat (None, 4, 4, 128) echo 512
__________________________________________________________________________________________
11 Dropout(Dropout) (None, 4, 4, 128) echo 0
__________________________________________________________________________________________
12 Flatten(Flatten) (None, 2048) echo 0
__________________________________________________________________________________________
13 Dense(Dense) (None, 128) relu 262272
__________________________________________________________________________________________
14 BatchNormalization(Bat (None, 128) echo 512
__________________________________________________________________________________________
15 Dense(Dense) (None, 10) softmax 1290
==========================================================================================
Total Params: 551,978
Trainable Params: 551,274
Non-trainable Params: 704
model.compile(optimizer=optimizers.adam,loss=functions.cross_entropy,learning_rate=0.001)- Iterative (optimizers.iterative)
- SGD with Momentum (optimizers.momentum)
- Rmsprop (optimizers.rmsprop)
- Adagrad (optimizers.adagrad)
- Adam (optimizers.adam)
- Adamax (optimizers.adamax)
- Adadelta (optimizers.adadelta)
- Conv2D
- Conv2Dtranspose
- MaxPool
- Upsampling
- Flatten
- Reshape
- Dense (Fully connected layer)
- Dropout
- BatchNormalization
- Activation
- InputLayer (just placeholder)
- functions.cross_entropy_with_logits
- functions.mean_squared_error
- sigmoid
- elliot
- relu
- leakyRelu
- elu
- tanh
- softmax
Backprop is fully automated. Just specify layers, loss function and optimizers. Model will backpropagate itself.
logits=model.fit(X_inp,labels,batch_size=128,epochs=10,validation_data=(X_test,y_test))or
logits=model.fit(X_inp,iterator=img_iterator,batch_size=128,epochs=10,validation_data=(X_test,y_test))logits=model.predict(inp)model.save_weights("file.dump")model.load_weights("file.dump")| Accuracy | Loss |
|---|---|
 |
 |
What the CNN sees


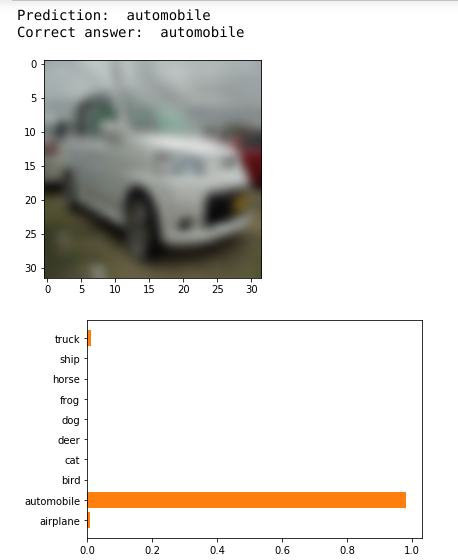
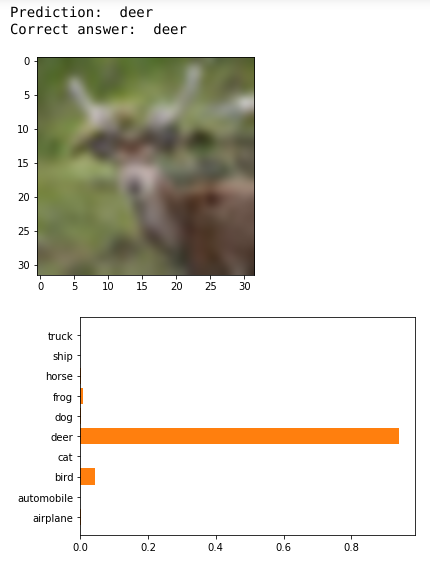

Layer 1

- RNN and LSTM.
- Translate weights to be used by different libraries.
- Write proper tests.
- Auto Differentiation.
- Mixed precision training.
- Multi GPU support. (It still can be done with cupy, just needs proper wrappers)
- Start a server process for visualizing graphs while training.
- Comments.
- Lots of performance and memory improvement.
- Complex architecture like Inception,ResNet.
CS231n: Convolutional Neural Networks for Visual Recognition.
Original Research Papers. Most implementations are based on original research papers with bit improvements if so.
And a lot of researching on Google.