论文:https://arxiv.org/abs/2310.05209
Xiaoran Liu, Hang Yan, Shuo Zhang, Chenxin An, Xipeng Qiu, Dahua Lin
School of Computer Science, Fudan University
Shanghai AI Lab
知乎:https://zhuanlan.zhihu.com/p/660073229
代码、权重、评测 coming soon
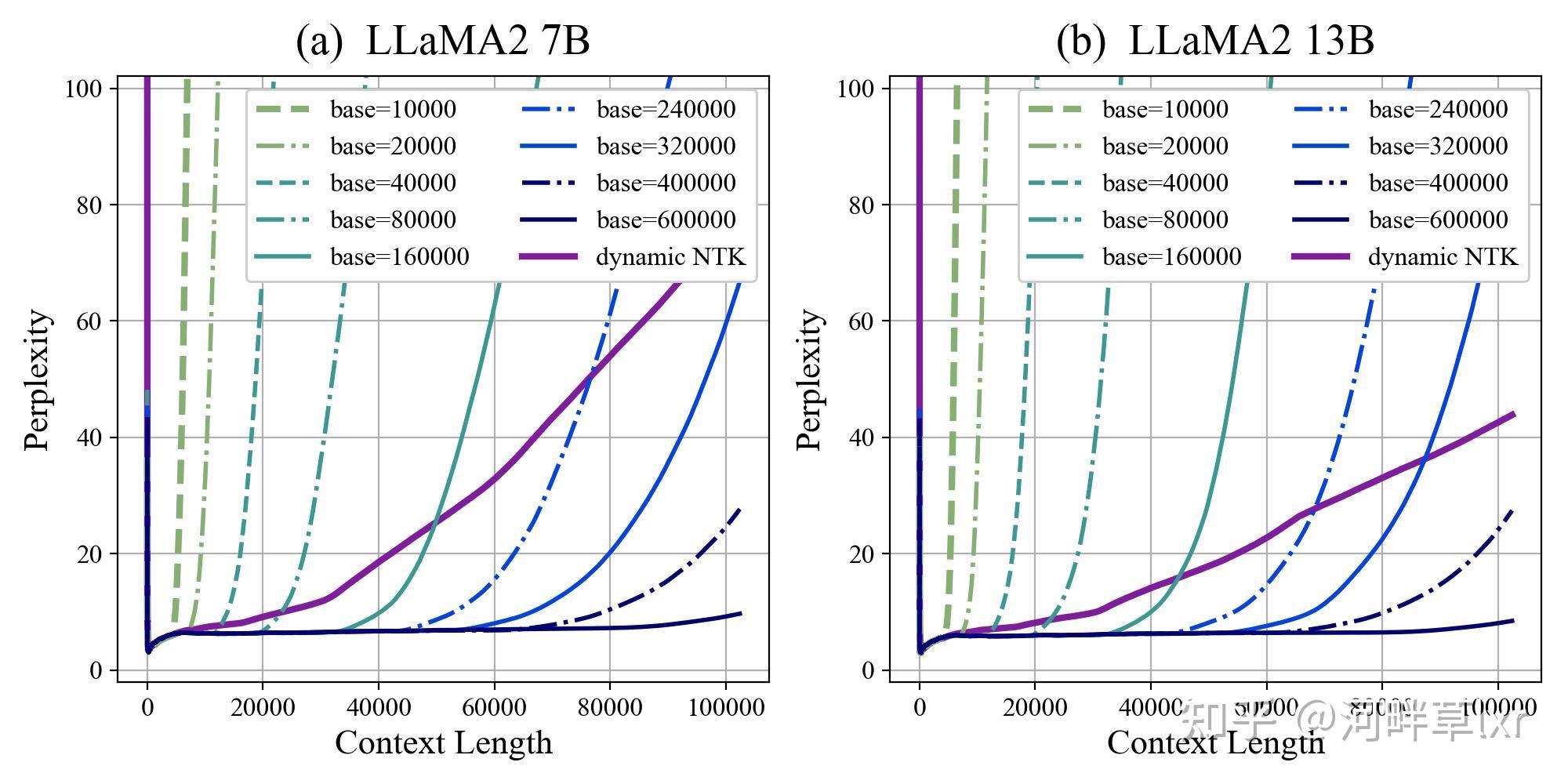
放大base,即使在原始长度(4K)文本上续训,也能显著的改进模型的外推效果,展现出以下的特点:
- 模型的外推效果很好,甚至可以直接外推超过续训长度;这个效果和Code LLaMA使用16K续训但取得了100K长度的外推是相一致的。
- 模型外推存在一个明显的上界,在这个范围内以内,模型语言建模的困惑度和准确率基本保持在一个稳定的范围内。但是一旦超过一个界限以后,模型的外推表现会严重的退化,表现在困惑度和准确率出现急剧的上升。
- 模型的外推效果随base的变化稳步提升,并且随base变化比较均匀,随着base增大,模型能够稳定地外推到更长的词窗。
- 相较于dynamic NTK,base放大并续训的方法,在超过外推上界后的崩坏趋势是远远超过dyanmic NTK的退化速度的;因此,对于放大base并续训,超过外推上界后的效果总是会落后于dynamic NTK的。但是在外推上界之内,该方案的效果是远远好于dynamic NTK的。
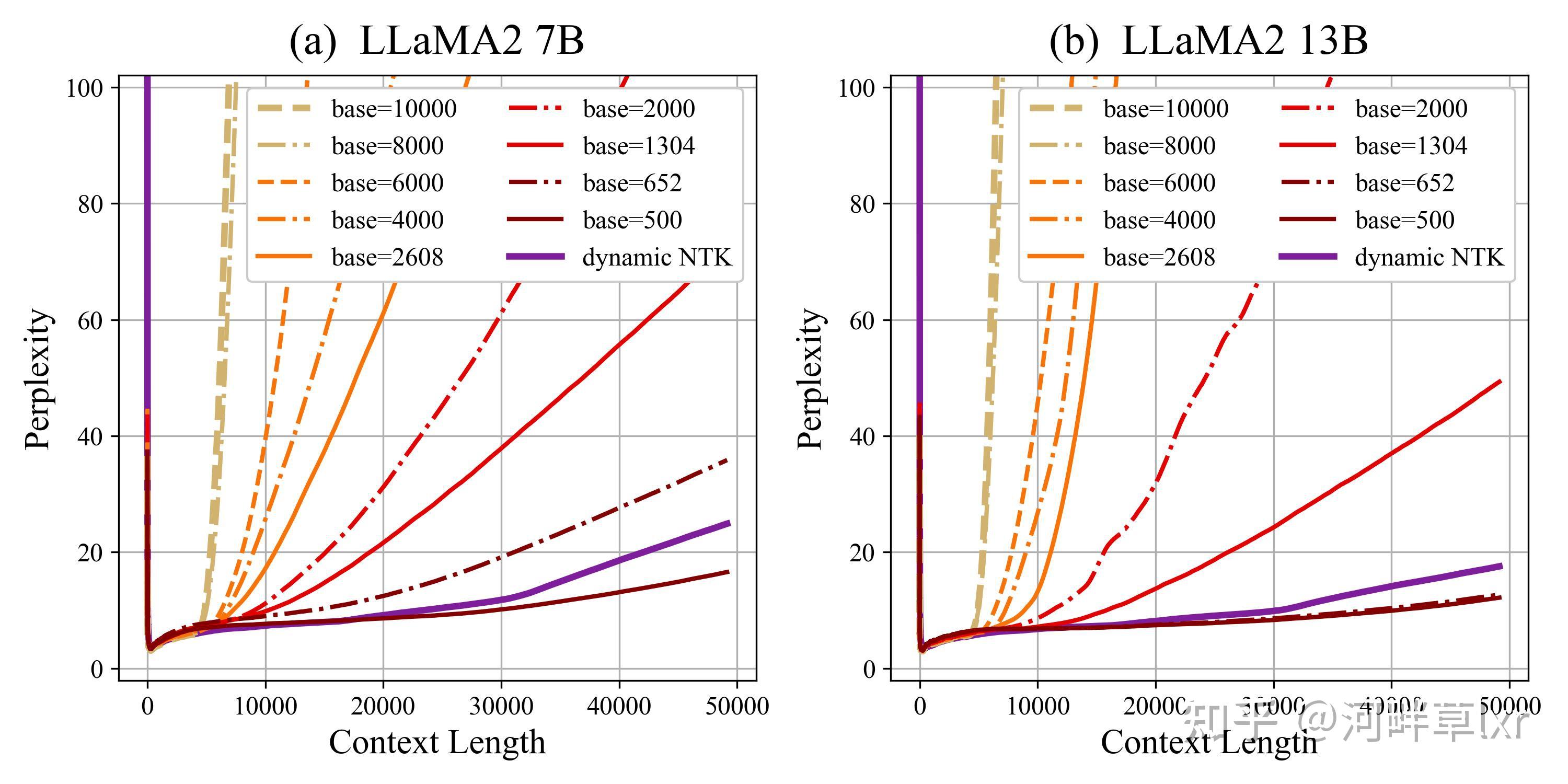
缩小base,并在原始训练长度(4K)文本上续训,仍然取得了显著的外推效果提升,展现出以下的特点:
- 模型可以外推,但超过训练长度后,模型的困惑度仍然会上升,但是上升的会比较平坦;并且base越小上升越慢,曲线越平缓。
- 模型外推并不存在一个明显的上界,模型语言建模的困惑度和准确率始终随上下文长度增加稳步退化。
- 模型的外推效果随base的变化并不是一个均匀的过程,base在2608至652区间中,提升加速显著,并且在base取500时最终超过dynamic NTK方案。
- 相较于dynamic NTK,虽然对于10000至652的绝大多数base,其效果都无法超过dynamic NTK,但是当base取到足够小之后,其外推曲线会足够平缓以至于在50K乃至更长长度一致优于dynamic NTK。
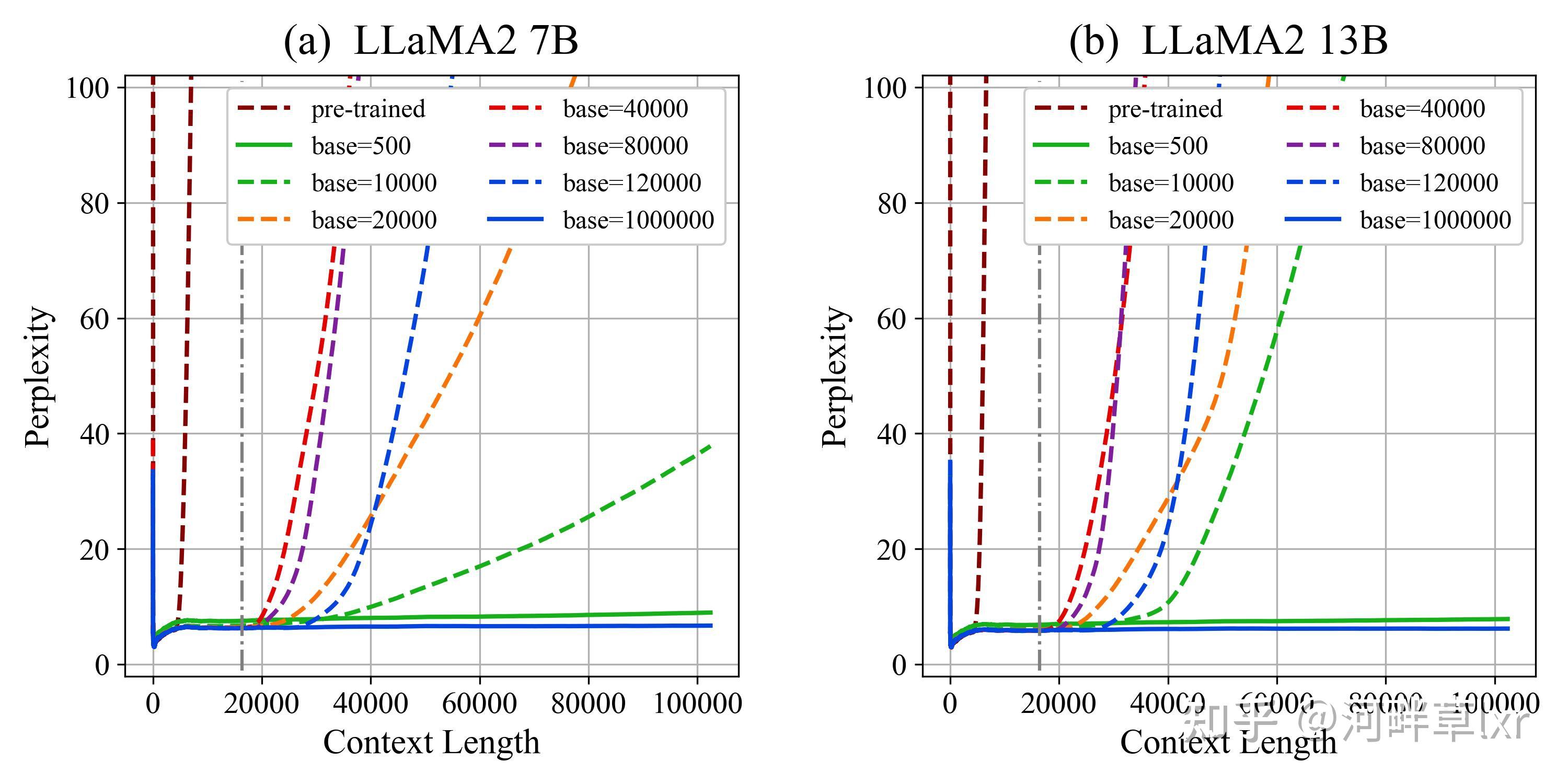
放大或缩小base,并在16K长文本上续训,外推效果显著提升,相较于原始长度续训,展现出以下的特点:
- base越小外推效果越好,但base越大外推效果先变差后变好,base=10000不再是外推最差的base。
- 无论base=500,还是base=1000000,都可以胜任100K长度的外推。
缩小base(base=500)和 放大base(base=1000000),在更长序列(1M)上外推效果的测试效果:
| 128K | 256K | 512K | 1M | |
|---|---|---|---|---|
| base=500 | 9.15 | 12.41 | 22.78 | 51.28 |
| base=500 log-scaled | 9.13 | 10.01 | 12.07 | 19.07 |
| base=1000000 | 7.07 | 76.82 | 1520.41 | 8349.9 |