Coding and testing the commercial applications of academic papers and cutting edge analytical techniques.
Paper 1: Annual Report Readability, Current Earnings, and Earnings Persistence
Abstract: This paper examines the relationship between annual report readability and firm performance and earnings persistence. I find that the annual reports of firms with lower earnings are harder to read (i.e., they have higher Fog and are longer). Moreover, the positive earnings of firms with annual reports that are easier to read are more persistent. This suggests that managers may be opportunistically choosing the readability of annual reports to hide adverse information from investors.
Paper 2: Lexical Tightness and Text Complexity
Abstract: We present a computational notion of Lexical Tightness that measures global cohesion of content words in a text. Lexical tightness represents the degree to which a text tends to use words that are highly inter-associated in the language. We demonstrate the utility of this measure for estimating text complexity.
Bonus Paper: Improving Pointwise Mutual Information (PMI) by Incorporating Significant Co-occurrence
Abstract: We design a new co-occurrence based word association measure by incorporating the concept of significant cooccurrence in the popular word association measure Pointwise Mutual Information (PMI). By extensive experiments with a large number of publicly available datasets we show that the newly introduced measure performs better than other co-occurrence based measures.
Annual Report Readability, Current Earnings, and Earnings Persistence
Lexical Tightness and Text Complexity
Improving Pointwise Mutual Information (PMI) by Incorporating Significant Co-occurrence
Overall goal is to develop a solution that can analyse the relationship between financial statement complexity and performance. The following are the projects hypotheses:
- Lexical tightness, calculated by mean normalised point-wise mutual information (PMI), is a good indicator of text complexity
- There is a correlation between text complexity and financial performance: percentage change in profit before tax.
- Financial statements that exhibit higher complexity are associated with poorer performance.
Begin by importing and extracting all text from each PDF to create a corpus. Proceed to lemmatize each word and remove 'stop-words' For this round of experimentation we have only compared financial statments from the same company accross time. Noting that domain specific words will vary across companies, potentially skewing results.
The process is also memory intensive with the amount of pairs needing to be held represented by the following equation.
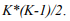
Once the corpus has been created we can calculate the unigram and pair-wise probability. Using these two dictionaries, the caluclation for each pairs normalised PMI is calculated using the following formula.
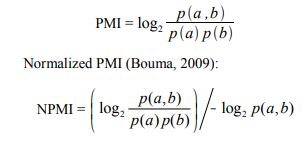
A financial statments lexical tightness is the mean value of all the pairs normalised PMI for that statment.
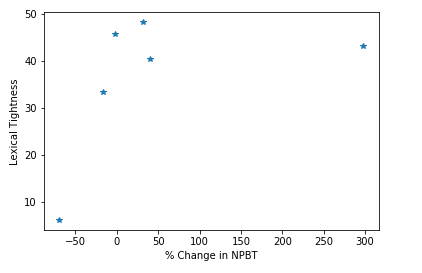
We finally plot lexical tighness against the percentage in profit before tax to access our results.
Lexical tightness (LT) represents the degree to which a text tends to use words that are highly inter-associated in the language. The papers posit that lexically tight texts (higher values of LT) are easier to read and thus should correspond to higher return values.
We note initially positive (not amazing) results from our testing with visual confirmation that the years where the percentage change in profit before tax was higher, corresponded to higher values of LT.
- Investigate putting a distance restriction for pairs within a statement so that pairs from opposite ends of the statements are not included
- Explore ways to store results, so recalculation becomes easier on memory
PyPDF2
itertools
math
matplotlib
nltk
collections