Emotions provide a plethora of information in communication, enabling us to comprehend and respond appropriately. SER systems enable applications to account for the emotional state of the user in their performance. Many existing implementations rely on low-level descriptors conveying linguistic, para-linguistic, and acoustic features. Challenges faced include -
- Feature selection is heavily based on domain, database, language, speaker types, architecture etc.
- Need of domain specific knowledge to manually engineer the features.
To develop a general, speaker independent, speech emotion classifier that will classify an audio of adult human speech into 8 categorical labels of emotion using a convolutional neural network, multitask learning, attention, and data augmentation. Additionally, predictions can be obtained for gender and intensity of emotion (valence, arousal, and dominance). IEMOCAP & RAVDESS are the 2 datasets used.
| Input | Outputs | Improvements |
|---|---|---|
| Log Mel Spectrograms | Anger | Data Augmentation |
| Excited | Attention | |
| Fear | Multitask Learning | |
| Frustration | ||
| Happiness | ||
| Neutral | ||
| Sadness | ||
| Surprise |
- The model is trained on English audio samples only and is thus not suitable to be used for other languages.
- The IEMOCAP dataset is a semi-simulated dataset and is not fully reflective of everyday real-world human speech. Limited number of samples compared to other ML domains for deep learning and class imbalance in turn make the model unfit for direct applications.
The purpose of each package is as follows -
- Preprocessing - preprocessing steps on the data.
- Network - architecture, batches, model creation, training, and testing.
- Visualization - explonatory and explanatory visualizations.
- Helper - helper functions for the other modules.
Following are the notebooks -
- Preprocessing - IEMOCAP
- Preprocessing - RAVDESS
- Model Development - Part I
- Model Development - Part II
- Model Development - Part III
- Model Training
- Model Testing - IEMOCAP
- Model Testing - RAVDESS

IEMOCAP Top-1

IEMOCAP VAD
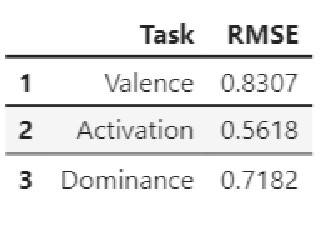
IEMOCAP Top-1 with Test-Time Augmentation

IEMOCAP Top-3

RAVDESS Top-1
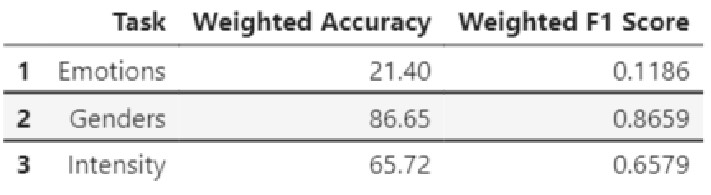
RAVDESS Top-1 with Test-Time Augmentation

RAVDESS Top-3

Log Mel Spectrogram provides a good amount of information to be used for emotional state recognition and that CNNs can be used to perform this image classification task.
- Multitask learning aids the main task through auxiliary task predictions. Infact, we use our own method of calculating the multitask losses.
- Attention mechanism focuses on the important features in the feature maps.
- Data augmentation techniques are employed to increase the training sample size and to help the model in generalization.
Taking the top-3 predictions into consideration greatly improves the accuracy metric for both IEMOCAP and RAVDESS. Thus, despite low top-1 accuracy, the model is learning to distinguish among the features, but has trouble in having high confidence for emotions with low number of samples. Test-Time Augmentation yielded similar performance results to just using original samples. This indicates the model was able to correctly predict the augmentations, and thus is robust to variations in the input audio/spectrogram.