An openly shared baseline code for the NeurIPS 2021 Nethack challenge, using sample-factory in its core. Feel free to use in your submissions as you see fit! This code only works on Linux.
Core features:
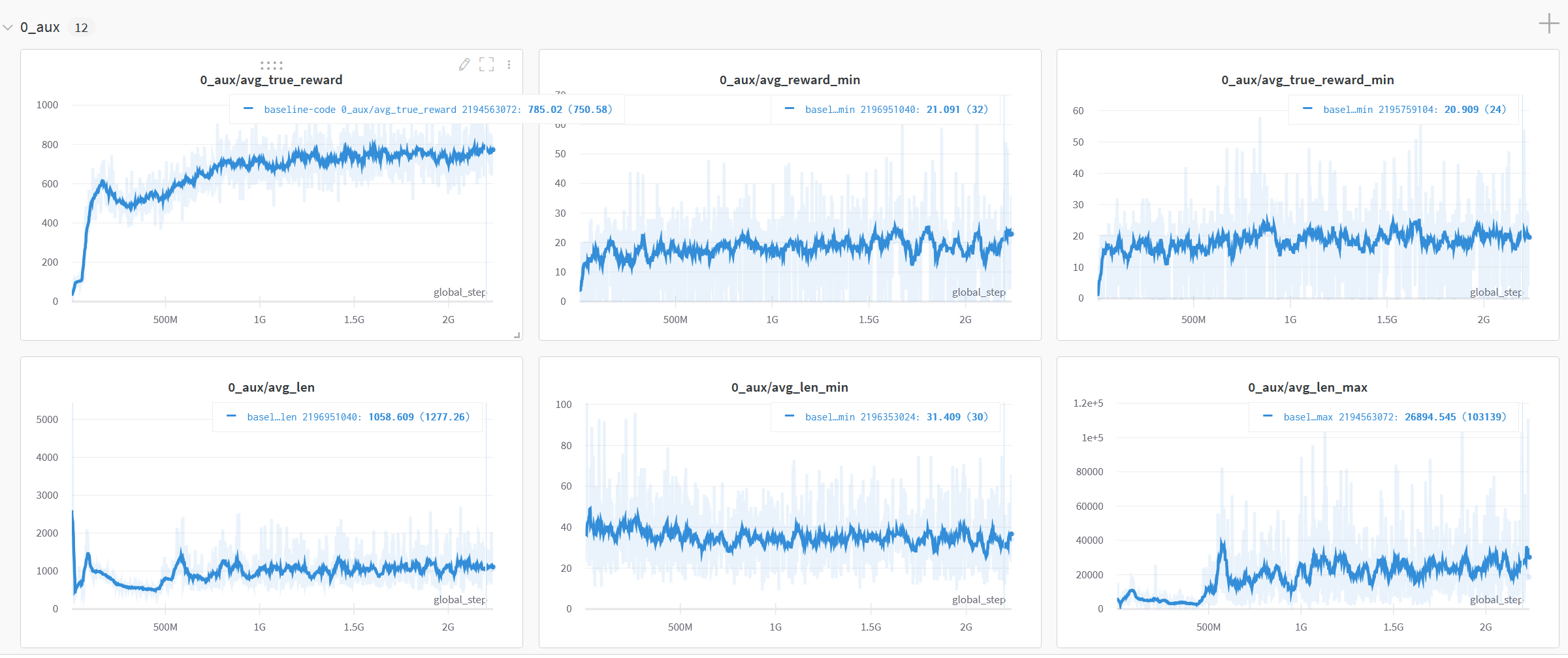
- Trains two billion (2e9) steps in 22h on a single RTX 2080Ti and 16 2.3Ghz cores. This reaches an average of 700-800 and a median of 400 reward.
- Learning algorithm is asynchronous PPO (see sample-factory for detailed explanation) with V-trace. Network consists of separate input heads and an RNN core (using GRUs).
- Main observation is an RGB image around the player character, rendered with
obs_wrappers.RenderCharImagesWithNumpyWrapper, processed with a standard CNN used with Atari experiments. - Agent also receives the
blstatsobservation, normalized with manually set normalization weights, and themessageobservation. Both are processed with a two-layer network before the RNN. This does not do proper text processing formessage, but at least allows it to detect common situations, e.g. "It is a wall". These encodings are concatenated with image encoding before the RNN core.
Install requirements with pip install -r requirements.txt.
Run code with ./train_baseline.sh. This should start printing out text about initializing the workers, and eventually learning statistics. Training lasts for two billion steps.
Note: by default this will continue the training with the files already contained in this repository. Change the experiment name in train_baseline.sh or alternatively remove train_dir directory to train a new model.
You can try to speed up training by changing the num_workers and num_envs_per_worker parameters inside train_baseline.sh.
This repository contains necessary files to make a submission, including a pretrained model. Simply follow the official instructions on doing a submission, and you should be good to go! Remember to update the aicrowd.json!
Checklist of things for changing your trained models for submission:
- Update
train_dirto only contain the experiment you want to submit (and preferably only one checkpoint file.cfg.jsonis a necessary file!) - Make sure the experiment name in
run.shmatches one intrain_baseline.sh.
main.py: entry point for training.evaluate.py: entry point for (AICrowd) evaluation.env.py: core environment wrappers and creation of environment in sample-factoryobs_wrappers.py: code for drawing RGB images of the NLE and processingblstatsinfo.models.py: torch model for encoding observations before the RNN core.train_baseline.sh: run training with the default settings.run.sh,apt.txt,aicrowd.json,Dockerfile,requirements.txt: files necessary for the AICrowd submission.
By default the sample-factory stores logs as tensorboard files, but to ease up tracking, this code comes with Weights & Biases integration.
Simply define WANDB_API_KEY variable in the environment and install wandb (pip install wandb), and you should start seeing logs on the wandb page once you launch the code.