

This repository is the web miner of the Keep-Current project.
The goal is to deploy a web crawler, that given a specific set of sources (URLs), should locate new documents (web-pages) and save them in the DB for future processing. When possible and legal, an API can be used. For example, for arxiv.org.
We lean heavily on existing tools as well as developing our own new methods.
- scrapy which later we hope to host on scrapy-cloud
- scrapy-splash which can render JS-based pages before storing them.
- Textract can be used to extract the content (the text) to be saved.
for running this project locally, you need first to install the dependency packages. To install them, you can use
Install pipenv
sudo easy_install pip # if you haven't installed pip
pip install pipenv # install pipenv
brew install pipenv # with homebrew (on macOS)Install the packages and run the server
pipenv install # install all packages
pipenv run flask run # run the serverIf you are on Windows OS, some packages may not be installed. Specifically - feedparser. In case the web server doesn't run, please install these packages manually using
pip install feedparserIf you have anaconda installed, it's recommended to create an environment for the project, and install the dependencies in it.
conda create -q -n web-miner python=3.6 # create the environment
source activate web-miner # activate the environment
pip install pipenv
pipenv installand test your installation by running the web server:
flask run # start serversudo easy_install pip # installl pip if you haven't
pip3 install --upgrade virtualenv # install virtualenv
virtualenv --python3 <targetDirectory> # create the environment
source <targetDirectory>/./bin/activate # activate the virtualenv
pip install pipenv
pipenv install
flask run # start serverWe follow the clean architecture style and structure the codebase accordingly.
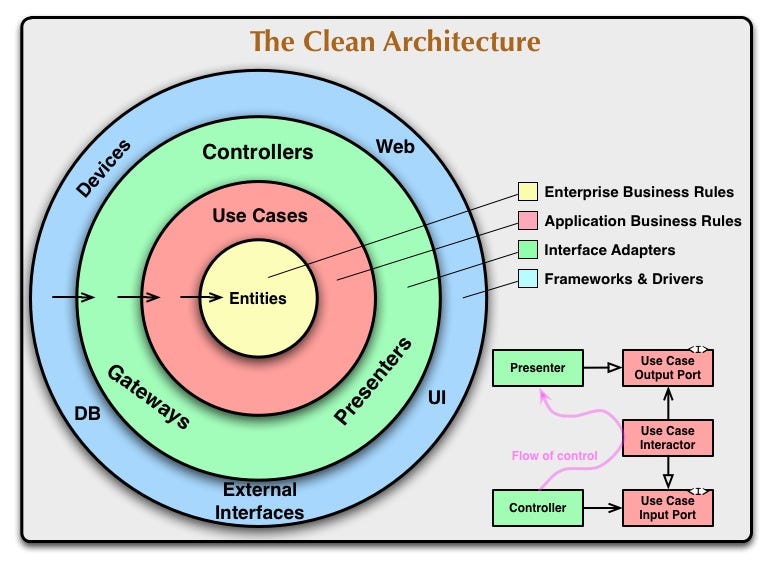
Image credit to Uncle Bob
Most important rule:
Source code dependencies can only point inwards. Nothing in an inner circle can know anything at all about something in an outer circle. In particular, the name of something declared in an outer circle must not be mentioned by the code in the an inner circle. That includes, functions, classes. variables, or any other named software entity.
This project intends to be a shared work of meetup members, with the purpose, beside the obvious result, to also be used as a learning platform, while advancing the Natural Language Processing / Machine Learning field by exploring, comparing and hacking different models.
Please visit
- the project board on Github
- the repository board on Github
- our chat room on Slack. If you're new, you can join using this link
- our facebook group where we discuss and share current topics also outside of the project
for more.
You can find our Project board here on GitHub and we use Slack as our communication channel. If you're new, you can join using this link
We welcome anyone who would like to join and contribute.
Please see our contribute guide.
We meet regularly every month in Vienna through
to show our progress and discuss the next steps.
After studying a topic, keeping current with the news, published papers, advanced technologies and such proved to be a hard work. One must attend conventions, subscribe to different websites and newsletters, go over different emails, alerts and such while filtering the relevant data out of these sources.
In this project, we aspire to create a platform for students, researchers, professionals and enthusiasts to discover news on relevant topics. The users are encouraged to constantly give a feedback on the suggestions, in order to adapt and personalize future results.
The goal is to create an automated system that scans the web, through a list of trusted sources, classify and categorize the documents it finds, and match them to the different users, according to their interest. It then presents it as a timely summarized digest to the user, whether by email or within a site.
This repository is the web miner. It encourage you to learn about software architecture, mining the web, setting up web-spiders, scheduling CRON Jobs, creating pipelines, etc.
If you wish to assist in different aspects (Data Engineering / Web development / DevOps), we have divided the project to several additional repositories focusing on these topics:
- The machine-learning engine can be found in our Main repository
- Web Development & UI/UX experiments can be found in our App repository
- Data Engineering tasks are more than welcomed in our Data Engineering repository
- Devops tasks are all across the project. This project is developed mostly in a serverless architecture. Using Docker and Kubernetes enables freedom in deploying it on different hosting providers and plans.
Feel free to join the discussion and provide your input!