{kind=link}
This is a simple program written to recognize the 26 English Letters. Using the Neural Network model, the program can be run to train itself to identify different English letters.
This following link leads to a video on this project:
For those who are not familiar with machine learning technology, the neural network model is the most popular learning model in the A.I. industry. Basically, a neural network is a web of interconnected neurons, each holding a bias value, and numerous weights depending on how many other neurons are connected to it. The neurons form layers, which then interconnect to form a fully functional neural network. There are basically three parts in a neural network, an input layer, hidden layers and an output layer. The data is fed into the input layer, which is then forwarded to the hidden layers (Layers that contain weights and biases) for calculations, and lastly given to the output layer for human-friendly feedback.
During training, an activation function is utilized to normalize the results and a loss function is written to assess the results of training. A process known as backpropagation is used to calibrate the weights and biases in the hidden layers.
In application, these 2 functions are not necessarily needed, and in this project, the application module does not implement these 2 functions.
Below is the result of a successful attempt to recognize the letter 'A'. The image is drawn in MS Paint.
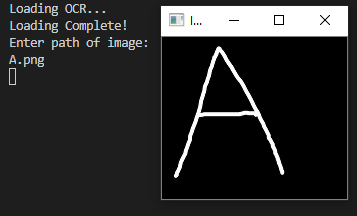
Training Data is downloaded from http://arxiv.org/abs/1702.05373 and http://archive.ics.uci.edu/ml.
OCR_Train.py is the training module. The trained results will be saved into 2 files, OCR_en_US_biases.csv & OCR_en_US_weights.csv. 2 trained sets of weights and biases are already put up, each folder's name indicating their recognition accuracy.
OCR_Main.py is the module that does the recognition. The image path will be prompted, an the predicted letter will be printed out.
preprocess.py is the module used to convert training data into numpy arrays.
The folder testImages contains images used for testing. Note: These images differ from the testing data during training.
The preprocessing function in OCR_Main.py is looking forward to be improved to be able to deal with RGB images. Your constructive comments and suggestions are welcome!