Releases: JohnSnowLabs/nlu
Hotfix for Databricks Endpoints in NLU 5.3.2
Visual Document NER and New Healthcare Models in NLU 5.3.1 !
We are excited to announce NLU 5.3.1 has been released! It comes with Visual Document NER, enabling you to extract entities from image files like JPGs.
Additionally 5 Healthcare Pipelines have been added for domains like Therapeutic Chemicals, HPO Resolvers, Voice of Patient, Oncology and Generic Clinical .
Additionally TextMatcherInternal based pipelines are now supported
Visual NER
- Tutorial Notebook
- Medium: Named Entity Recognition in Documents with Transformer Models using Visual-NLP: Part 1
- Medium: One-Liner Magic with Spark NLP: Deep Learning for NER in Documents — Part 2
VisualDocumentNER is a transformer-based model designed for Named Entity Recognition (NER) in documents. It serves as the primary interface for tasks such as detecting keys and values in datasets like FUNSD, representing the structure of a form. These keys and values are typically interconnected using a FormRelationExtractor model.
However, some VisualDocumentNER models are trained with a different approach, considering entities in isolation. These entities could be names, places, or medications, and the goal is not to connect these entities to others, but to utilize them individually.
Powered by Spark OCR's VisualDocumentNER
New Healthcare Models
| NLU ref | Model |
|---|---|
| en.resolve.atc_pipeline | atc_resolver_pipeline |
| en.map_entity.hpo_resolver_pipe | hpo_resolver_pipeline |
| en.explain_doc.pipeline_vop | explain_clinical_doc_vop |
| en.explain_doc.clinical_generic.pipeline | explain_clinical_doc_generic |
| en.explain_doc.clinical_oncology.pipeline | explain_clinical_doc_oncology |
New Medium Articles
Tutotirals on how to leverage Visual NLPs table extraction and Visual NER in 1 line and with custom pipelines:
- Deep Learning based Table Extraction using Visual NLP: Part 1
- One-Liner Magic with Spark NLP: Deep Learning for Table Extraction — Part 2
- Named Entity Recognition in Documents with Transformer Models using Visual-NLP: Part 1
- One-Liner Magic with Spark NLP: Deep Learning for NER in Documents — Part 2
📖Additional NLU resources
- 140+ NLU Tutorials
- Streamlit visualizations docs
- The complete list of all 20000+ models & pipelines in 300+ languages is available on Models Hub
- Spark NLP publications
- NLU documentation
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP and NLU!
Installation
#PyPI
pip install nlu pysparkOpen AI Completion and Word Embeddings, Visual Cocument Dlassifcation, Bart and XLM-RoBerta Zero-Shot-Classification and more in John Snow Labs NLU 5.3.0
We are very excited to announce NLU 5.3.0 has been released!
It features support for Open AI's Completion and Word Embeddings, alongside visual document classification, Bart and XLM RoBerta for Zero Shot Classification.
Open AI Completion
Tutorial Notebook
OpenAICompletion combines powers of OpenAI’s completion models with the robust NLP processing capabilities of Spark NLP. This integration not only ensures the utilization of OpenAI's capabilities but also capitalizes on Spark's inherent scalability advantages.
This annotator makes direct API calls to OpenAI’s Completion endpoint right from datasets. This enhancement promises to elevate the efficiency and versatility of data processing workflows within Spark NLP pipelines.
Powered by OpenAICompletion
Reference: OpenAI API Doc
Reference: OpenAICompletion Doc
| nlu.load() reference | Spark NLP Model reference |
|---|---|
| openai.completion | OpenAICompletion |
Open AI Embeddings
Tutorial Notebook
OpenAIEmbeddings combines powers of OpenAI’s embeddings model with the robust NLP processing capabilities of Spark NLP. This integration not only ensures the utilization of OpenAI's capabilities but also capitalizes on Spark's inherent scalability advantages.
This annotator makes direct API calls to OpenAI’s Embeddings endpoint right from datasets. This enhancement promises to elevate the efficiency and versatility of data processing workflows within Spark NLP pipelines.
Powered by OpenAIEmbeddings
| nlu.load() reference | Spark NLP Model reference |
|---|---|
| openai.embeddings | OpenAIEmbeddings |
Visual Document Classifier
The VisualDocumentClassifier is a DL model for document classification using text and layout data. The currently available pre-trained model on the Tobacco3482 dataset contains 3482 images belonging to 10 different classes (Resume, News, Note, Advertisement, Scientific, Report, Form, Letter, Email and Memo)
Powered By
VisualDocumentClassifier
| Language | nlu.load() reference | Spark NLP Model reference |
|---|---|---|
| xx | en.classify_image.tabacco | visual_document_classifier_tobacco3482 |
Bart for Zero Shot Classificaiton
BartForZeroShotClassification using a ModelForSequenceClassification trained on NLI (natural language inference) tasks.
The equivalent of BartForSequenceClassification models, but these models don’t require a hardcoded number of potential classes, they can be chosen at runtime. It usually means it’s slower but it is much more flexible.
We used TFBartForSequenceClassification to train this model and used BartForZeroShotClassification annotator in Spark NLP 🚀 for prediction at scale
Powered by BartForZeroShotClassification
| Language | nlu.load() reference | Spark NLP Model reference |
|---|---|---|
| English | en.bart.zero_shot_classifier | bart_large_zero_shot_classifier_mnli |
XLM RoBerta For Zero Shot Classification
Tutorial Notebook
XlmRoBertaForZeroShotClassification using a ModelForSequenceClassification trained on NLI (natural language inference) tasks.
Equivalent of XlmRoBertaForSequenceClassification models, but these models don’t require a hardcoded number of potential classes, they can be chosen at runtime. It usually means it’s slower but it is much more flexible.
We used TFXLMRobertaForSequenceClassification to train this model and used XlmRoBertaForZeroShotClassification annotator in Spark NLP 🚀 for prediction at scale!
Powered by XlmRoBertaForZeroShotClassification
| Language | nlu.load() reference | Spark NLP Model reference |
|---|---|---|
| xx | xx.xlm_roberta.zero_shot_classifier | xlm_roberta_large_zero_shot_classifier_xnli_anli |
Bugfixes
- Fix bug loading Albert for Question Answering Models
- Fix bug for predicting on imagefiles in Databricks
📖 Additional NLU resources
- 140+ NLU Tutorials
- Streamlit visualizations docs
- The complete list of all 20000+ models & pipelines in 300+ languages is available on Models Hub
- Spark NLP publications
- NLU documentation
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP and NLU!
Installation
#PyPI
pip install nlu pyspark Various bugfixes in John Snow Labs NLU 5.1.4
various minor bugfixes which fix various pre-trained pipelines
📖 Additional NLU resources
- 140+ NLU Tutorials
- Streamlit visualizations docs
- The complete list of all 20000+ models & pipelines in 300+ languages is available on Models Hub
- Spark NLP publications
- NLU documentation
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP and NLU!
Installation
#PyPI
pip install nlu pyspark Various bugfixes in John Snow Labs NLU 5.1.3
various minor bugfixes which fix various pre-trained pipelines
- proper handling for finisher
- light pipe bugfix
- missing metadata handling
Bugfixes
- Fixed a bug that caused some Chunk Mapper based pretrained pipelines to throw exceptions
- Fixed bug that caused pretrained some pipes with sentence embed converters to crash
📖 Additional NLU resources
- 140+ NLU Tutorials
- Streamlit visualizations docs
- The complete list of all 20000+ models & pipelines in 300+ languages is available on Models Hub
- Spark NLP publications
- NLU documentation
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP and NLU!
Installation
#PyPI
pip install nlu pyspark 10+ medical models for Summarization, NER, Classification, DEID and more in John Snow Labs NLU 5.1.2
We are announcing NLU 5.1.2 with new pipelines and bug fixes.
10+ new medical ner, summarization, classification, mapper, deidentification healthcare pipelines has been added!
New Healthcare Pipelines
| Language | nlu.load() reference | Spark NLP reference |
|---|---|---|
| Arabic | ar.deid.clinical | clinical_deidentification |
| English | en.summarize.biomedical_pubmed.pipeline | summarizer_biomedical_pubmed_pipeline |
| English | en.ner.oncology.pipeline | ner_oncology_pipeline |
| English | en.ner.oncology_response_to_treatment.pipeline | ner_oncology_response_to_treatment_pipeline |
| English | en.med_ner.vop.pipeline | ner_vop_pipeline |
| English | en.med_ner.vop_demographic.pipeline | ner_vop_demographic_pipeline |
| English | en.med_ner.vop_treatment.pipeline | ner_vop_treatment_pipeline |
| English | en.med_ner.vop_problem.pipeline | ner_vop_problem_pipeline |
| English | en.classify.bert_sequence.vop_hcp_consult.pipeline | bert_sequence_classifier_vop_hcp_consult_pipeline |
| English | en.classify.bert_sequence.vop_drug_side_effect.pipeline | bert_sequence_classifier_vop_drug_side_effect_pipeline |
| English | en.map_entity.rxnorm_resolver.pipe | rxnorm_resolver_pipeline) |
Bugfixes
- Fixed a bug that caused some Chunk Mapper based pretrained pipelines to throw exceptions
- Fixed bug that caused pretrained some pipes with sentence embed converters to crash
📖 Additional NLU resources
- 140+ NLU Tutorials
- Streamlit visualizations docs
- The complete list of all 20000+ models & pipelines in 300+ languages is available on Models Hub
- Spark NLP publications
- NLU documentation
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP and NLU!
Installation
#PyPI
pip install nlu pyspark Deep Learning Based Visual Table Recogition, Whisper for Multilingual Speech Recognition with 85+ models across various languages and 40+ new models in John Snow Labs NLU 5.1.1
We are incredibly excited to announce NLU 5.1.1 has been released with over 130+ models in 36+ languages including new models based on Whisper for multilingual automatic speech recognition and Deep Learning based Visual Table Recogition using cascade R-CNN
You can now transcribe speech to text with Whispe with 85+ models across 36 languages for Automatic Speech Recognition (ASR).
Additionally, Deep Learning based Visual Table Recogition based on an Cascade mask R-CNN HRNet that features detection of tables within images is now available in NLU 🌟.
Finally, 40+ new models for existing model classes has been added!
Deep Learning based Visual Table Recogition
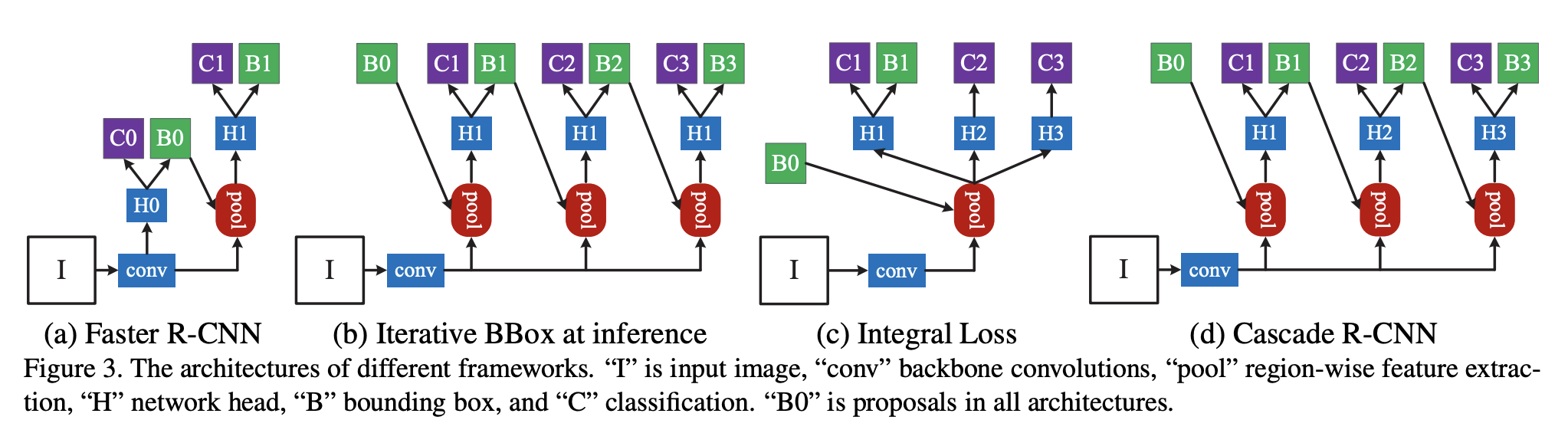
You can now extract tables from images as pandas dataframe in 1 line of code, leveraging Spark OCR's ImageTableDetector, ImageTableCellDetector and ImageCellsToTextTable classes.
The ImageTableDetector is a deep-learning model designed to identify tables within images. It utilizes the CascadeTabNet architecture, which incorporates the Cascade mask Region-based Convolutional Neural Network High-Resolution Network (Cascade mask R-CNN HRNet).
The ImageTableCellDetector, on the other hand, is engineered to pinpoint cells within a table image. Its foundation is an image processing algorithm that identifies both horizontal and vertical lines.
The ImageCellsToTextTable applies Optical Character Recognition (OCR) to regions of cells within an image and returns the recognized text to the outputCol as a TableContainer structure.
It’s important to note that these annotators do not need to be invoked individually in NLU. Instead, you can simply load the image_table_cell2text_table model using the command nlp.load('image_table_cell2text_table'), and then use nlp.predict to make predictions on any document.
Powered by Spark OCR's ImageTableDetector, ImageTableCellDetector, ImageCellsToTextTable
Reference: Cascade R-CNN: High Quality Object Detection and Instance Segmentation
| language | nlu.load() reference | Spark NLP Model Reference |
|---|---|---|
| en | en.image_table_detector | General Model for Table Detection |
Whisper for CTC

Whisper Model with a language modeling head on top for Connectionist Temporal Classification (CTC). Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. It transcribe in multiple languages, as well as translate from those languages into English. Whisper was trained and open-sourced that approaches human level robustness and accuracy on English speech recognition.
Powered by Spark-NLP's WhisperForCTC Annotator
Reference: OpenAI Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
Note that at the moment only Spark Versions 3.4 and up are supported.
| Language | NLU Reference | Spark NLP Reference | Annotator Class |
|---|---|---|---|
| bg | bg.speech2text.whisper.tiny_bulgarian_l | asr_whisper_tiny_bulgarian_l | WhisperForCTC |
| cs | cs.speech2text.whisper.small_czech_cv11 | asr_whisper_small_czech_cv11 | WhisperForCTC |
| da | da.speech2text.whisper.danish_small_augmented | asr_whisper_danish_small_augmented | WhisperForCTC |
| de | de.speech2text.whisper.small_allsnr | asr_whisper_small_allsnr | WhisperForCTC |
| el | el.speech2text.whisper.samoan_farsipal_e5 | asr_whisper_samoan_farsipal_e5 | WhisperForCTC |
| el | el.speech2text.whisper.small_greek | asr_whisper_small_greek | WhisperForCTC |
| el | el.speech2text.whisper.tswana_greek_modern_e1 | asr_whisper_tswana_greek_modern_e1 | WhisperForCTC |
| en | en.speech2text.whisper.small_english_model | asr_personal_whisper_small_english_model | WhisperForCTC |
| en | en.speech2text.whisper.base_bulgarian_l | asr_whisper_base_bulgarian_l | WhisperForCTC |
| en | en.speech2text.whisper.base_english | asr_whisper_base_english | WhisperForCTC |
| en | en.speech2text.whisper.base_european | asr_whisper_base_european | WhisperForCTC |
| en | en.speech2text.whisper.base_swedish | asr_whisper_base_swedish | WhisperForCTC |
| en | en.speech2text.whisper.persian_farsi | asr_whisper_persian_farsi | WhisperForCTC |
| en | en.speech2text.whisper.small_arabic_cv11 | asr_whisper_small_arabic_cv11 | WhisperForCTC |
| en | en.speech2text.whisper.small_bak | asr_whisper_small_bak | WhisperForCTC |
| en | en.speech2text.whisper.small_bengali_subhadeep | asr_whisper_small_bengali_subhadeep | WhisperForCTC |
| en | en.speech2text.whisper.small_chinese_hk | asr_whisper_small_chinese_hk | WhisperForCTC |
| en | en.speech2text.whisper.small_chinese_tw_voidful | asr_whisper_small_chinese_tw_voidful | WhisperForCTC |
| en | en.speech2text.whisper.small_english | asr_whisper_small_english | WhisperForCTC |
| en | en.speech2text.whisper.small_english_blueraccoon | asr_whisper_small_english_blueraccoon | WhisperForCTC |
| en | en.speech2text.whisper.small_german | asr_whisper_small_german | WhisperForCTC |
| en | en.speech2text.whisper.small_hungarian_cv11 | asr_whisper_small_hungarian_cv11 | WhisperForCTC |
| en | en.speech2text.whisper.small_lithuanian_serbian_v2 | asr_whisper_small_lithuanian_serbian_v2 | WhisperForCTC |
| en | en.speech2text.whisper.small_mongolian_2 | asr_whisper_small_mongolian_2 | WhisperForCTC |
| en | en.speech2text.whisper.small_mongolian_3 | asr_whisper_small_mongolian_3 | WhisperForCTC |
| en | en.speech2text.whisper.small_portuguese_yapeng | asr_whisper_small_portuguese_yapeng | WhisperForCTC |
| en | en.speech2text.whisper.small_se2 | asr_whisper_small_se2 | WhisperForCTC |
| en | en.speech2text.whisper.small_spanish_1e_6 | asr_whisper_small_spanish_1e_6 | WhisperForCTC |
| en | en.speech2text.whisper.small_swe2 | asr_whisper_small_swe2 | WhisperForCTC |
| en | en.speech2text.whisper.small_swe_davidt123 | asr_whisper_small_swe_davidt123 | WhisperForCTC |
| en | en.speech2text.whisper.small_swedish_se_afroanton | asr_whisper_small_swedish_se_afroanton | WhisperForCTC |
| en | en.speech2text.whisper.small_telugu_openslr | [asr_whisper_small_telugu_openslr](https://nlp.johnsnowlabs.com/2023/... |
350+ New Sentence Embedders based on Instructor, E5 and MPNET in John Snow Labs NLU 5.1.0
We are very excited to announce John Snow Labs NLU 5.1.0 has been released!
It features 350+ new models with 3 new Sentence Embeddings Architectures: Instructor, E5 and MPNET in English, French and Spanish.
Instructor Sentence Embeddings
Instructor👨🏫, an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation, etc.) and domains (e.g., science, finance, etc.) by simply providing the task instruction, without any finetuning. Instructor👨 achieves sota on 70 diverse embedding tasks.
Instructor was proposed in One Embedder, Any Task: Instruction-Finetuned Text Embeddings by Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, Tao Yu. Analysis of the writers suggests that INSTRUCTOR is robust to changes in instructions, and that instruction finetuning mitigates the challenge of training a single model on diverse datasets
Powered by InstructorEmbeddings
Reference: One Embedder, Any Task: Instruction-Finetuned Text Embeddings
Reference: InstructorEmbeddings Github Repo
| Language | NLU Reference | Spark NLP Reference |
|---|---|---|
| English | en.embed_sentence.instructor_base | instructor_base |
| English | en.embed_sentence.instructor_large | instructor_large |
E5 Sentence Embeddings
E5 is a weakly supervised text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation, etc).
E5 was proposed in Text Embeddings by Weakly-Supervised Contrastive Pre-training by Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, Furu Wei. The model is trained in a contrastive manner with weak supervision signals from our curated large-scale text pair dataset (called CCPairs). E5 can be readily used as a general-purpose embedding model for any tasks requiring a single-vector representation of texts such as retrieval, clustering, and classification, achieving strong performance in both zero-shot and fine-tuned settings.
Powered by E5Embeddings
Reference: Text Embeddings by Weakly-Supervised Contrastive Pre-training
Reference: E5Embeddings Github Repo
| Language | NLU Reference | Spark NLP Reference |
|---|---|---|
| English | en.embed_sentence.e5_small | e5_small |
| English | en.embed_sentence.e5_small_opt | e5_small_opt |
| English | en.embed_sentence.e5_small_quantized | e5_small_quantized |
| English | en.embed_sentence.e5_small_v2 | e5_small_v2 |
| English | en.embed_sentence.e5_small_v2_opt | e5_small_v2_opt |
| English | en.embed_sentence.e5_small_v2_quantized | e5_small_v2_quantized |
| English | en.embed_sentence.e5_base | e5_base |
| English | en.embed_sentence.e5_base_opt | e5_base_opt |
| English | en.embed_sentence.e5_base_quantized | e5_base_quantized |
| English | en.embed_sentence.e5_base_v2 | e5_base_v2 |
| English | en.embed_sentence.e5_base_v2_opt | e5_base_v2_opt |
| English | en.embed_sentence.e5_base_v2_quantized | e5_base_v2_quantized |
| English | en.embed_sentence.e5_large | e5_large |
| English | en.embed_sentence.e5_large_v2 | e5_large_v2 |
| English | en.embed_sentence.e5_large_v2_opt | e5_large_v2_opt |
| English | en.embed_sentence.e5_large_v2_quantized | e5_large_v2_quantized |
MPNET Sentence Embeddings
Tutorial Notebook
MPNet adopts a novel pre-training method, named masked and permuted language modeling, to inherit the advantages of masked language modeling and permuted language modeling for natural language understanding.
The MPNet model was proposed in MPNet: Masked and Permuted Pre-training for Language Understanding by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu. MPNet, a novel pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in XLNet).
Powered by MPNetEmbeddings
Reference: MPNet: Masked and Permuted Pre-training for Language Understanding
Reference: MPNetEmbeddings Github Repo
| Language | nlu.load() reference | Spark NLP Model reference |
|---|---|---|
| English | en.embed_sentence.mpnet.579_stmodel_product_rem_v3a | 579_stmodel_product_rem_v3a |
| English | en.embed_sentence.mpnet.abstract_sim_query | abstract_sim_query |
| English | en.embed_sentence.mpnet.abstract_sim_sentence | abstract_sim_sentence |
| English | en.embed_sentence.mpnet.action_policy_plans_classifier | action_policy_plans_classifier |
| English | en.embed_sentence.mpnet.all_datasets_v3_mpnet_base | all_datasets_v3_mpnet_base |
| English | en.embed_sentence.mpnet.all_datasets_v4_mpnet_base | all_datasets_v4_mpnet_base |
| English | en.embed_sentence.mpnet.all_mpnet_base_questions_clustering_english | all_mpnet_base_questions_clustering_english |
| English | en.embed_sentence.mpnet.all_mpnet_base_v1 | all_mpnet_base_v1 |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2 | all_mpnet_base_v2 |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_diptanuc | all_mpnet_base_v2_diptanuc |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_embedding_all | all_mpnet_base_v2_embedding_all |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_feature_extraction | all_mpnet_base_v2_feature_extraction |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_feature_extraction_pipeline | all_mpnet_base_v2_feature_extraction_pipeline |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_finetuned_v2 | all_mpnet_base_v2_finetuned_v2 |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_for_sb_clustering | all_mpnet_base_v2_for_sb_clustering |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_ftlegal_v3 | all_mpnet_base_v2_ftlegal_v3 |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_obrizum | all_mpnet_base_v2_obrizum |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_sentence_transformers | all_mpnet_base_v2_sentence_transformers |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_table | all_mpnet_base_v2_table |
| English | en.embed_sentence.mpnet.all_mpnet_base_v2_tasky_classification | all_mpnet_base_v2_tasky_classification |
| English | en.embed_sentence.mpnet.attack_bert | [attack_bert](https://sparknlp.or... |
John Snow Labs NLU 5.0.3 - Hotfix for removing logs
disable verbose logs by default
John Snow Labs NLU 5.0.2 - Hotfix for Pandas>=2 compatibility
This is a hotfix release, making NLU compatible with pandas>=2.
NLU is now compatible with any pandas>=1.3.5