- Day_01 : 資料介紹與評估指標
- 探索流程 : 找到問題 -> 初探 -> 改進 -> 分享 -> 練習 -> 實戰
- 思考關鍵點 :
- 為什麼這個問題重要?
- 資料從何而來?
- 資料型態是什麼?
- 回答問題的關鍵指標是什麼?
- Day_02 : 機器學習概論
- 機器學習範疇 : 深度學習 (Deep Learning) ⊂ 機器學習 (Machine Learning) ⊂ 人工智慧 (Artificial Intelligence)
- 機器學習是什麼 :
- 讓機器從資料找尋規律與趨勢,不需要給定特殊規則
- 給定目標函數與訓練資料,學習出能讓目標函數最佳的模型參數
- 機器學習總類 :
- 監督是學習 (Supervised Learning) : 圖像分類 (Classification)、詐騙偵測 (Fraud detection),需成對資料 (x,y)
- 非監督是學習 (Unsupervised Learning) : 降維 (Dimension Reduction)、分群 (Clustering)、壓縮,只需資料 (x)
- 強化學習 (Reinforcement Learning) : 下圍棋、打電玩,透過代理機器人 (Agent) 與環境 (Environment) 互動,學習如何獲取最高獎勵 (Reward),例如 Alpha GO
- Day_03 : 機器學習流程與步驟
- 資料蒐集、前處理
- 政府公開資料、Kaggle 資料
- 結構化資料 : Excel 檔、CSV 檔
- 非結構化資料 : 圖片、影音、文字
- 使用 Python 套件
- 開啟圖片 :
PIL、skimage、open-cv - 開啟文件 :
pandas
- 開啟圖片 :
- 資料前處理 :
- 缺失值填補
- 離群值處理
- 標準化
- 政府公開資料、Kaggle 資料
- 定義目標與評估準則
- 建立模型與調整參數
- Regression,回歸模型
- Tree-base model,樹模型
- Neural network,神經網路
- Hyperparameter,根據對模型了解和訓練情形進行調整
- 導入
- 建立資料蒐集、前處理(Preprocessing)等流程
- 送進模型進行預測
- 輸出預測結果
- 視專案需求調整前後端
- 資料蒐集、前處理
- Day_04 : 讀取資料與分析流程 (EDA,Exploratory Data Analysis)
- 透過視覺化和統計工具進行分析
- 了解資料 : 獲取資料包含的資訊、結構、特點
- 發現 outlier 或異常數值 : 檢查資料是否有誤
- 分析各變數間的關聯性 : 找出重要的變數
- 收集資料 -> 數據清理 -> 特徵萃取 -> 資料視覺化 -> 建立模型 -> 驗證模型 -> 決策應用
- 透過視覺化和統計工具進行分析
-
Day_05 : 如何建立一個 DataFrame?如何讀取其他資料?
- 用 pd.DataFrame 來建立,練習網站
- CSV
import pandas as pd df = pd.read_csv('example.csv') # sep=',' df = pd.read_table('example.csv') # sep='\t' - 文本 (txt)
with open('example.txt','r') as f: data = f.readlines() print(data) - Json
import json with open('example.json','r') as f: data = json.load(f) print(data) - 矩陣檔 (mat)
import scipy.io as sio data = sio.load('example.mat') - 圖像檔 (PNG/JPG...)
import cv2 image = cv2.imread('example.jpg') # Cv2 會以 GBR 讀入 image = cv2.cvtcolor(image,cv2.COLOR_BGR2RGB) - Python npy
import numpy as np arr = np.load('example.npy') - Picke (pkl)
import pickle with open('example.pkl','rb') as f: arr = pickle.load(f)
-
Day_06 : 欄位的資料類型介紹及處理
- 資料類型 :
- 離散變數 : 房間數量、性別、國家
- 連續變數 : 身高、花費時間、車速
- 常見的資料類型 :
- float64 : 浮點數,可表示離散或連續變數
- int64 : 整數,可表示離散或連續變數
- object : 包含字串,表示類別型變數
- Label encoding : 對象有序資料,例如年齡
from sklearn.preprocessing import LabelEncoder df[col] = LabelEncoder().fit_transform(df[col]) - One Hot encoding : 對象無序資料,例如國家
df = pd.get_dummies(df)
- Label encoding : 對象有序資料,例如年齡
- 其他 : 日期、boolean
- 資料類型 :
-
Day_07 : 特徵類型
- 數值型特徵 : 有不同轉換方式,函數/條件式都可以
- 類別型特徵 : 通常一種類別對應一種分數
- 二元型特徵 : True/False,可當類別或數值處理
- 排序型特徵 : 有大小關係時當數值型特徵處理
- 時間型特徵 : 可當數值或類別處理,但會失去週期性,需特別處理
-
Day_08 : EDA 之資料分佈
- 以單變量進行分析
- 計算集中趨勢
- 平均數,
mean() - 中位數,
median() - 眾數,
mode()
- 平均數,
- 計算資料分散程度
- 最小值,
min() - 最大值,
max() - 範圍
- 四分位差,
quantile() - 變異數,
var() - 標準差,
std()
- 最小值,
- 計算集中趨勢
- 視覺化方式
-
matplotlib
import matplotlib.pyplot as plt %matplotlib inline # 內嵌方式,不需要 plt.show() %matplotlib notebook # 互動方式 plt.style.use('ggplot') # 改變繪圖風格 plt.style.available # 查詢有哪些風格 -
seaborn
import seaborn as sns sns.set() # 使用預設風格 sns.set_style('whitegrid') # 變更其他風格 sns.axes_style(...) # 更詳細的設定
-
matplotlib
- 延伸閱讀 :
- 以單變量進行分析
-
Day_09 : 離群值 (Outlier) 及其處理
- 異常值出現可能原因
- 未知值隨意填補或約定成俗代入
- 錯誤紀錄/手誤/系統性錯誤
- 檢查異常值的方法
- 統計值 : 如平均數、標準差、中位數、分位數
df.describe() df[col].value_counts() - 畫圖 : 如值方圖、合圖、次數累積分佈等
df.plot.hist() # 直方圖 df.boxplot() # 盒圖 df = df[col].value_counts().sort_index().cumsum() plt.plot(list(df.index), df/df.max()) # 次數累積圖
- 統計值 : 如平均數、標準差、中位數、分位數
- 異常值的處理方法
- 取代補植 : 中位數、平均數等
- 另建欄位 : 標示異常(Y/N)
- 整欄不用
- 延伸閱讀 :
- 異常值出現可能原因
-
Day_10 : 數值特徵 - 去除離群值
- 方法一 : 去除離群值,可能刪除掉重要資訊,但不刪除會造成特徵縮放 (標準化/最大最小化) 有很大問題
mask = df[col] > threshold_lower & df[col] < threshold_upper df = df[mask] - 方法二 : 調整離群值
df[col] = df[col].clip(lower, upper) # 將數值限制在範圍內
- 方法一 : 去除離群值,可能刪除掉重要資訊,但不刪除會造成特徵縮放 (標準化/最大最小化) 有很大問題
-
Day_11 : 數值填補與連續數值標準化
- 常用於填補的統計值
- 中位數 (median) :
np.median(df[col]) - 分位數 (quantiles) :
np.quantile(df[col],q=...) - 眾數 (mode) :
from scipy.stats import mode mode(df[col]) - 平均數 (mean) :
np.mean(df[col])
- 中位數 (median) :
- 連續型數值標準化
- 為何要標準化 : 每個變數 x 對 y 的影響力不同
- 是否要做標準化 : 對於權重敏感或損失函數平滑有幫助者
- 非樹狀模型 : 線性回歸、羅吉斯回歸、類神經,對預測會有影響
- 樹狀模型 : 決策樹、隨機森林樹、梯度提升樹,對預測不會有影響
- 優點 : 加速模型收斂,提升模型精準度
- 缺點 : 量的單位有影響力時不適用
- 標準化方法 :
- Z-transform : $ \frac{(x - mean(x))}{std(x)} $
- Range (0 ~ 1) : $ \frac{x - min(x)}{max(x) - min(x)} $
- Range (-1 ~ 1) : $ (\frac{x - min(x)}{max(x) - min(x)} - 0.5) * 2 $
- 常用於填補的統計值
-
Day_12 : 數值型特徵 - 補缺失值與標準化
-
缺失值處理 : 最重要的是欄位領域知識與欄位中的非缺數值,須注意不要破壞資料分佈
- 填補統計值 :
- 填補平均數 (mean) : 數值型欄位,偏態不明顯
- 填補中位數 (meadian) : 數值型欄位,偏態明顯
- 填補重數 (mode) : 類別型欄位
- 填補指定值 : 須對欄位領域知識已有了解
- 補 0 : 空缺原本就有零的含意
- 補不可能出現的數值 : 類別型欄位,但不適合用眾數時
df.fillna(0) df.fillna(-1) df.fillna(df.mean()) - 填補預測值 : 速度慢但精確,從其他欄位學得填補知識
- 若填補範圍廣,且是重要的特徵欄位時可用本方式
- 須提防 overfitting : 可能退化成其他特徵組合
- 標準化 : 以合理的方式平衡特徵間的影響力
- 標準化 (Standard Scaler) : 假設數值為常態分 佈,適用本方式平衡特徵,不易受極端值影響
- 最大最小化 (MinMax Scaler) : 假設數值為均勻分布,適用本方式平衡特徵,易受極端值影響
from sklearn.preprocessing import MinMaxScaler, StandardScaler df_temp = MinMaxScaler().fit_transform(df) df_temp = StandardScaler().fit_transform(df)
- 填補統計值 :
-
缺失值處理 : 最重要的是欄位領域知識與欄位中的非缺數值,須注意不要破壞資料分佈
-
Day_13 : 常用的 DataFrame 操作
- Panda 官方 Cheat Sheet
- Panda Cheet Sheet
- 轉換與合併
- 將"column"轉換成"row"
df.melt(id_vars=['A'], value_vars=['B', 'C']) - 將"row"轉換成"column"
df.pivot(index='A', columns='B', values='C') - 沿"row"進行合併
pd.concat([df1,df2]) - 沿"column"進行合併
pd.concat([df1,df2],axis=1) - 以"id"欄位做全合併(遺失以na補)
pd.merge(df1,df2,on='id',how='outer') - 以'id'欄位做部分合併
pd.merge(df1,df2,on='id',how='inner')
- 將"column"轉換成"row"
- subset 操作
- 邏輯操作(>,<,=,&,|,~,^)
sub_df = df[df.age>20] - 移除重複的"row"
df = df.drop_duplicates() - 前 5 筆、後 n 筆
sub_df = df.head() # default = 5 sub_df = df.tail(10) - 隨機抽樣
sub_df = df.sample(frac=0.5) # 抽50% sub_df = df.sample(n=10) # 抽10筆 - 第 n 到 m 筆
sub_df = df.iloc[n:m] - 欄位中包含 value
df.column.isin(value) - 判斷 Nan
pd.isnull(obj) # df.isnull() pd.notnull(obj) # df.notnull() - 欄位篩選
new_df = df['col1'] # df.col1 new_df = df[['col1','col2','col3']] df = pd.DataFrame(np.array(([1, 2, 3], [4, 5, 6])), index=['mouse', 'rabbit'], columns=['one', 'two', 'three']) new_df = df.filter(items=['one', 'three']) new_df = df.filter(regex='e$', axis=1) new_df = df.filter(like='bbi', axis=0)
- 邏輯操作(>,<,=,&,|,~,^)
- Groupby 操作 :
sub_df_obj = df.groupby(['col1'])- 計算各組的數量
sub_df_obj.size() - 得到各組的統計值
sub_df_obj.describe() - 根據 col1 分組後計算 col2 的統計值
sub_df_obj['col2'].mean() - 根據 col1 分組後的 col2 引用操作
sub_df_obj['col2'].apply(...) - 根據 col1 分組後的 col2 繪圖
sub_df_obj['col2'].hist()
- 計算各組的數量
-
Day_14 : 相關係數簡介
- 想要了解兩個變數之間的線性關係時,相關係數是一個還不錯的簡單方法,能給出一個 -1~1 之間的值來衡量化兩個變數之間的關係。
- Correlation Coefficient :
$$r=\frac{1}{n-1} \sum_{i=1}^n\frac{(x_i-\bar{x})}{s_x}\frac{(y_i-\bar{y})}{s_y}$$ - 相關係數小遊戲
-
Day_15 : 相關係數實作
df = pd.DataFrame(np.concatenate([np.random.randn(20).reshape(-1,1),np.random.randint(0,2,20).reshape(-1,1)],axis=1), columns=["X","y"]) df.corr() np.corrcoef(df)- 通常搭配繪圖進一步了解目標與變數的關係
df.plot(x='X',y='y',kind='scatter') df.boxplot(column=['X'], by=['y'])
- 通常搭配繪圖進一步了解目標與變數的關係
-
Day_16 : 繪圖與樣式 & Kernel Density Estimation (KDE)
- 繪圖風格 : 用已經被設計過的風格,讓觀看者更清楚明瞭,包含色彩選擇、線條、樣式等。
plt.style.use('default') # 不需設定就會使用預設 plt.style.use('ggplot') plt.style.use('seaborn') # 採⽤ seaborn 套件繪圖 - KDE
- 採用無母數方法劃出觀察變數的機率密度函數
- Density Plot 特性 :
- 歸一 : 線下面積和為1
- 常用的 kernal function :
- Gaussian(Normal dist)
- Cosine
- 優點 : 無母數方法,對分布沒有假設
- 缺點 : 計算量大
- 透過 KDE Plot 可以清楚看出不同組間的分布情形
import matplotlib.pyplot as plt import seaborn as sns # 將欄位分成多分進行統計繪圖 plt.hist(df[col], edgecolor = 'k', bins = 25) # KDE, 比較不同的 kernel function sns.kdeplot(df[col], label = 'Gaussian esti.', kernel='gau') sns.kdeplot(adf[col], label = 'Cosine esti.', kernel='cos') sns.kdeplot(df[col], label = 'Triangular esti.', kernel='tri') # 完整分布圖 (distplot) : 將 bar 與 Kde 同時呈現 sns.distplot(df[col]) # 繪製 barplot 並顯示目標的 variables sns.barplot(x="BIRTH_RANGE", y="TARGET", data=df) plt.xticks(rotation=45) # 旋轉刻度標籤 - 延伸閱讀 :
- 繪圖風格 : 用已經被設計過的風格,讓觀看者更清楚明瞭,包含色彩選擇、線條、樣式等。
-
Day_17 : 把連續型變數離散化
-
離散化目的 :
- 讓事情變簡單,增加運算速度
- 減少 outlier 對模型的影響
- 引入非線性,提升模型表達能力
- 提升魯棒性,減少過似合
- 主要方法 :
- 等寬劃分
pd.cut(),可使用np.linspace()進行等距切分 - 等頻劃分
pd.qcut() - 聚類劃分
- 等寬劃分
-
離散化目的 :
-
Day_18 : 把連續型變數離散化實作
- 把連續型的特徵離散化後,可以配合
groupby劃出與預測目標的圖,來判斷兩者之間是否有某些關係和趨勢。# 將年齡相關資料, 另外存成一個 DataFrame 來處理 age_data = app_train[['TARGET', 'DAYS_BIRTH']] age_data['YEARS_BIRTH'] = age_data['DAYS_BIRTH'] / 365 # 將年齡資料離散化 / 分組 age_data['YEARS_BINNED'] = pd.cut(age_data['YEARS_BIRTH'], bins = np.linspace(20, 70, num = 11)) age_groups = age_data.groupby('YEARS_BINNED').mean() plt.figure(figsize = (8, 8)) # 繪製目標值平均與分組組別的長條圖 plt.bar(range(len(age_groups.index)), age_groups['TARGET']) # 加上 X, y 座標說明, 以及圖表的標題 plt.xticks(range(len(age_groups.index)), age_groups.index, rotation = 75) plt.xlabel('Age Group (years)') plt.ylabel('Average Failure to Repay') plt.title('Failure to Repay by Age Group')
- 把連續型的特徵離散化後,可以配合
-
Day_19 : Subplot
- 使用時機 :
- 有很多相似的資料要呈現時 (如不同組別)
- 同一組資料,想要同時用不同的圖呈現
- 適時的使用有助於資訊傳達,但過度使用會讓重點混淆
- subplot 坐標系 (列-欄-位置)
- (321) 代表在⼀個 3列2欄 的最左上⾓ 列1欄1
- (232) 代表在一個 2列3欄 的 列1欄2 位置
# 方法一 : 數量少的時候或繪圖方法不同時 plt.figure(figsize=(8,8)) plt.subplot(321) plt.plot([0,1],[0,1], label = 'I am subplot1') plt.legend() plt.subplot(322) plt.plot([0,1],[1,0], label = 'I am subplot2') plt.legend() # 方法二 : 數量多的時候或繪圖方法雷同時 nrows = 5 ncols = 2 plt.figure(figsize=(10,30)) for i in range(nrows*ncols): plt.subplot(nrows, ncols, i+1) - 延伸閱讀 :
- 使用時機 :
-
Day_20 : Heatmap & Grid-plot
-
heatmap- 常用於呈現變數間的相關性
- 也可以用於呈現不同條件下的數量關係
- 常用於呈現混淆矩陣 (Confusion matrix)
plt.figure(figsize = (8, 6)) # 繪製相關係數 (correlations) 的 Heatmap sns.heatmap(df.corr(), cmap = plt.cm.RdYlBu_r, vmin = -1.0, annot = True, vmax = 1.0) plt.title('Correlation Heatmap') -
pairplot- 對角線 : 該變數的分布(distribution)
- 非對角線 : 倆倆變數間的散佈圖
import seaborn as sns; sns.set(style="ticks", color_codes=True) iris = sns.load_dataset("iris") g = sns.pairplot(iris) -
PairGrid- 可以自訂對角線和非對角線的繪圖類型
g = sns.PairGrid(iris, hue="species") g = g.map_diag(plt.hist) # 對角線繪圖類型 g = g.map_offdiag(plt.scatter) # 非對角線繪圖類型 g = g.add_legend() g = sns.PairGrid(iris) g = g.map_upper(sns.scatterplot) # 上三角繪圖類型 g = g.map_lower(sns.kdeplot, colors="C0") # 下三角繪圖類型 g = g.map_diag(sns.kdeplot, lw=2) - 延伸閱讀 :
-
-
Day_21 : 模型初體驗 - Logistic Regression
-
Logistic Regression
from sklearn.linear_model import LogisticRegression # 設定模型與模型參數 log_reg = LogisticRegression(C = 0.0001) # 使用 Train 資料訓練模型 log_reg.fit(train, train_labels) # 用模型預測結果 # 請注意羅吉斯迴歸是分類預測 (會輸出 0 的機率, 與 1 的機率), 而我們只需要留下 1 的機率這排 log_reg_pred = log_reg.predict_proba(test)[:, 1] # 將 DataFrame/Series 轉成 CSV 檔案方法 df['Target'] = log_reg_pred df.to_csv(file_name, encoding='utf-8', index=False)
-
Logistic Regression
-
Day_22 : 特徵工程簡介
- 資料工程是將事實對應到分數的轉換
- 由於資料包含類別特徵 (文字) 和數值特徵,所以最小的特徵工程至少包含一種類別編碼 (例如:標籤編碼)和特徵縮放方法 (例如:最小最大化)
from sklearn.preprocessing import LabelEncoder, MinMaxScaler LEncoder = LabelEncoder() MMEncoder = MinMaxScaler() for c in df.columns: df[c] = df[c].fillna(-1) if df[c].dtype == 'object': df[c] = LEncoder.fit_transform(list(df[c].values)) df[c] = MMEncoder.fit_transform(df[c].values.reshape(-1, 1)) - 延伸閱讀 :
-
Day_23 : 數值型特徵 - 去除偏態
- 當離群值資料比例太高,或者平均值沒有代表性時,可以考慮去除偏態
- 去除偏態包含 : 對數去偏 (log1p)、方根去偏 (sqrt)、分布去偏 (boxcox)
- 使用 box-cox 分布去偏時,除了注意
$\lambda$ 參數要界於 0 到 0.5 之間,並且要注意轉換前的數值不可小於等於 0# 對數去偏 df_fixed['Fare'] = np.log1p(df_fixed['Fare']) # 方根去偏 df['score'] = np.sqrt(df['score']) * 10 from scipy import stats # 修正方式 : 加入下面這一行, 使最小值大於 0, 類似log1p的概念 df_fixed['Fare'] = df_fixed['Fare'] + 1 df_fixed['Fare'] = stats.boxcox(df_fixed['Fare'])[0] - 延伸閱讀 :
-
Day_24 : 類別型特徵 - 基礎處理
- 類別型特徵有標籤編碼 (Label Encoding) 與獨熱編碼 (One Hot Encoding) 兩種基礎編碼方式
- 標籤編碼將特徵依序轉為代碼,若特徵沒有大小順序之別,則大小順序沒有意義,常用於非深度學習模型,深度學習模型主要依賴倒傳導,標籤編碼不易收斂
- 當特徵重要性高且可能值少時,可考慮獨熱編碼
from sklearn.preprocessing import LabelEncoder object_features = [] for dtype, feature in zip(df.dtypes, df.columns): if dtype == 'object': object_features.append(feature) df = df[object_features] df = df.fillna('None') # 標籤編碼 for c in df.columns: df_temp[c] = LabelEncoder().fit_transform(df[c]) # 獨熱編碼 df_temp = pd.get_dummies(df) - 延伸閱讀 :
-
Day_25 : 類別型特徵 - 均值編碼
- 均值編碼 (Mean Encoding) : 使用目標值的平均值取代原本類別型特徵
- 當類別特徵與目標明顯相關時,該考慮採用均值編碼
- 樣本數少時可能是極端值,平均結果可能誤差很大,需使用平滑公式來調整
- 當平均值可靠度低則傾向相信總平均
- 當平均值可靠性高則傾向相信類別的平均
- 依照紀錄的比數,在兩者間取折衷 : $$新類別均值 = \frac{原類別平均類別樣本數 + 全部的總平均調整因子}{類別樣本數 + 調整因子}$$
- 相當容易 overfitting 請小心使用
data = pd.concat([df[:train_num], train_Y], axis=1) for c in df.columns: mean_df = data.groupby([c])['target'].mean().reset_index() mean_df.columns = [c, f'{c}_mean'] data = pd.merge(data, mean_df, on=c, how='left') data = data.drop([c] , axis=1) data = data.drop(['target'] , axis=1)
-
Day_26 : 類別型特徵 - 其他進階處理
-
計數編碼 (Counting) : 計算類別在資料中出現次數,當目前平均值與類別筆數呈現正/負相關時,可以考慮使用
count_df = df.groupby(['Ticket'])['Name'].agg({'Ticket_Count':'size'}).reset_index() df = pd.merge(df, count_df, on=['Ticket'], how='left') -
雜湊編碼 : 將類別由雜湊函數對應到一組數字
- 調整雜湊函數對應值的數量,在計算空間/時間與鑑別度間取折衷
- 提高訊息密度並減少無用的標籤
df_temp['Ticket_Hash'] = df['Ticket'].map(lambda x:hash(x) % 10) - 雜湊編碼也不佳時可使用嵌入式編碼 (Embedding),但需要基於深度學習前提下
- 延伸閱讀 :
-
計數編碼 (Counting) : 計算類別在資料中出現次數,當目前平均值與類別筆數呈現正/負相關時,可以考慮使用
-
Day_27 : 時間型特徵
- 時間型特徵分解 :
- 依照原意義分欄處理,年、月、日、時、分、秒或加上第幾周和星期幾
- 週期循環特徵
- 年週期 : 與季節溫度相關
- 月週期 : 與薪水、繳費相關
- 周週期 : 與周休、消費習慣相關
- 日週期 : 與生理時鐘相關
- 週期數值除了由欄位組成還需頭尾相接,因此一般以正(餘)弦函數加以組合
- 年週期 : ( 正 : 冷 / 負 : 熱 )
$cos((月/6 + 日/180)\pi)$ - 周週期 : ( 正 : 精神飽滿 / 負 : 疲倦 )
$sin((星期幾/3.5 + 小時/84)\pi)$ - 日週期 : ( 正 : 精神飽滿 / 負 : 疲倦 )
$sin((小時/12 + 分/720 + 秒/43200)\pi)$ - 須注意最高點與最低點的設置
- 年週期 : ( 正 : 冷 / 負 : 熱 )
import datetime # 時間特徵分解方式:使用datetime df['pickup_datetime'] = df['pickup_datetime'].apply(lambda x: datetime.datetime.strptime(x, '%Y-%m-%d %H:%M:%S UTC')) df['pickup_year'] = df['pickup_datetime'].apply(lambda x: datetime.datetime.strftime(x, '%Y')).astype('int64') df['pickup_month'] = df['pickup_datetime'].apply(lambda x: datetime.datetime.strftime(x, '%m')).astype('int64') df['pickup_day'] = df['pickup_datetime'].apply(lambda x: datetime.datetime.strftime(x, '%d')).astype('int64') df['pickup_hour'] = df['pickup_datetime'].apply(lambda x: datetime.datetime.strftime(x, '%H')).astype('int64') df['pickup_minute'] = df['pickup_datetime'].apply(lambda x: datetime.datetime.strftime(x, '%M')).astype('int64') df['pickup_second'] = df['pickup_datetime'].apply(lambda x: datetime.datetime.strftime(x, '%S')).astype('int64') # 加入星期幾(day of week)和第幾周(week of year) df['pickup_dow'] = df['pickup_datetime'].apply(lambda x: datetime.datetime.strftime(x, '%w')).astype('int64') df['pickup_woy'] = df['pickup_datetime'].apply(lambda x: datetime.datetime.strftime(x, '%W')).astype('int64') # 加上"日週期"特徵 (參考講義"週期循環特徵") import math df['day_cycle'] = df['pickup_hour']/12 + df['pickup_minute']/720 + df['pickup_second']/43200 df['day_cycle'] = df['day_cycle'].map(lambda x:math.sin(x*math.pi)) # 加上"年週期"與"周週期"特徵 df['year_cycle'] = df['pickup_month']/6 + df['pickup_day']/180 df['year_cycle'] = df['year_cycle'].map(lambda x:math.cos(x*math.pi)) df['week_cycle'] = df['pickup_dow']/3.5 + df['pickup_hour']/84 df['week_cycle'] = df['week_cycle'].map(lambda x:math.sin(x*math.pi)) - 延伸閱讀 :
- 時間型特徵分解 :
-
Day_28 : 特徵組合 - 數值與數值組合
- 除了基本的加減乘除,最關鍵的是領域知識,例如將經緯度資料組合成高斯距離
# 增加緯度差, 經度差, 座標距離等三個特徵 df['longitude_diff'] = df['dropoff_longitude'] - df['pickup_longitude'] df['latitude_diff'] = df['dropoff_latitude'] - df['pickup_latitude'] df['distance_2D'] = (df['longitude_diff']**2 + df['latitude_diff']**2)**0.5 import math latitude_average = df['pickup_latitude'].mean() latitude_factor = math.cos(latitude_average/180*math.pi) df['distance_real'] = ((df['longitude_diff']*latitude_factor)**2 + df['latitude_diff']**2)**0.5 - 機器學習的關鍵是特徵工程,能有效地提升模型預測能力
- 延伸閱讀 :
- 除了基本的加減乘除,最關鍵的是領域知識,例如將經緯度資料組合成高斯距離
-
Day_29 : 特徵組合 - 類別與數值組合
-
群聚編碼 (Group by Encoding) : 類別特徵與數值特徵可以使用群聚編碼組合出新的特徵
- 常見的組合方式有
mean,mdian,mode,max,min,count - 與均值編碼 (Mean Encoding) 的比較
名稱 均值編碼 Encoding 群聚編碼 Group by Encoding 平均對象 目標值 其他數值型特徵 過擬合 (Overfitting) 容易 不容易 對均值平滑化 (Smoothing) 需要 不需要 - 機器學習的特徵是 寧爛勿缺 的,以前非樹狀模型為了避免共線性,會希望類似特徵不要太多,但現在強力模型大多是樹狀模型,所以通通做成
雞精特徵
- 常見的組合方式有
- 延伸閱讀 :
# 取船票票號(Ticket), 對乘客年齡(Age)做群聚編碼 df['Ticket'] = df['Ticket'].fillna('None') df['Age'] = df['Age'].fillna(df['Age'].mean()) mean_df = df.groupby(['Ticket'])['Age'].mean().reset_index() mode_df = df.groupby(['Ticket'])['Age'].apply(lambda x: x.mode()[0]).reset_index() median_df = df.groupby(['Ticket'])['Age'].median().reset_index() max_df = df.groupby(['Ticket'])['Age'].max().reset_index() min_df = df.groupby(['Ticket'])['Age'].min().reset_index() temp = pd.merge(mean_df, mode_df, how='left', on=['Ticket']) temp = pd.merge(temp, median_df, how='left', on=['Ticket']) temp = pd.merge(temp, max_df, how='left', on=['Ticket']) temp = pd.merge(temp, min_df, how='left', on=['Ticket']) temp.columns = ['Ticket', 'Age_Mean', 'Age_Mode', 'Age_Median', 'Age_Max', 'Age_Min'] temp.head()Index Ticket Age_Mean Age_Mode Age_Median Age_Max Age_Min 0 110152 26.333333 16.000000 30.000000 33.0 16.000000 1 110413 36.333333 18.000000 39.000000 52.0 18.000000 2 110465 38.349559 29.699118 38.349559 47.0 29.699118 3 110564 28.000000 28.000000 28.000000 28.0 28.000000 4 110813 60.000000 60.000000 60.000000 60.0 60.000000
-
群聚編碼 (Group by Encoding) : 類別特徵與數值特徵可以使用群聚編碼組合出新的特徵
-
Day_30 : 特徵選擇
- 特徵需要適當的增加與減少,以提升精確度並減少計算時間
- 增加特徵 : 特徵組合 (Day_28),群聚編碼 (Day_29)
- 減少特徵 : 特徵選擇 (Day_30)
- 特徵選擇有三大類方法
- 過濾法 (Filter) : 選定統計值與設定門檻,刪除低於門檻的特徵
- 包裝法 (Wrapper) : 根據目標函數,逐步加入特徵或刪除特徵
- 嵌入法 (Embedded) : 使用機器學習模型,根據擬合後的係數,刪除係數低餘門檻的特徵
-
相關係數過濾法
# 計算df整體相關係數, 並繪製成熱圖 import seaborn as sns import matplotlib.pyplot as plt corr = df.corr() sns.heatmap(corr) plt.show() # 篩選相關係數大於 0.1 或小於 -0.1 的特徵 high_list = list(corr[(corr['SalePrice']>0.1) | (corr['SalePrice']<-0.1)].index) # 刪除目標欄位 high_list.pop(-1) -
Lasso (L1) 嵌入法
- 使用 Lasso Regression 時,調整不同的正規化程度,就會自然使得一部分特徵係數為 0,因此刪除係數是 0 的特徵,不須額外指定門檻,但需調整正規化程度
from sklearn.linear_model import Lasso L1_Reg = Lasso(alpha=0.001) train_X = MMEncoder.fit_transform(df) L1_Reg.fit(train_X, train_Y) L1_Reg.coef_ L1_mask = list((L1_Reg.coef_>0) | (L1_Reg.coef_<0)) df.columns[L1_mask] # index type from itertools import compress L1_mask = list((L1_Reg.coef_>0) | (L1_Reg.coef_<0)) L1_list = list(compress(list(df), list(L1_mask))) # list type -
GDBT (梯度提升樹) 嵌入法
-
使用梯度提升樹擬合後,以特徵在節點出現的頻率當作特徵重要性,以此刪除重要性低於門檻的特徵
計算時間 共線性 特徵穩定性 相關係數過濾法 快速 無法排除 穩定 Lasso 嵌入法 快速 能排除 不穩定 GDBT 嵌入法 較慢 能排除 穩定
-
- 延伸閱讀 :
- 特徵需要適當的增加與減少,以提升精確度並減少計算時間
-
Day_31 : 特徵評估
- 特徵的重要性 : 分支次數、特徵覆蓋度、損失函數降低量
- sklearn 當中的樹狀模型,都有特徵重要性這項方法
.feature_importance_,而實際上都是分支次數from sklearn.ensemble import RandomForestRegressor # 隨機森林擬合後, 將結果依照重要性由高到低排序 estimator = RandomForestRegressor() estimator.fit(df.values, train_Y) # estimator.feature_importances_ 就是模型的特徵重要性, 這邊先與欄位名稱結合起來, 才能看到重要性與欄位名稱的對照表 feats = pd.Series(data=estimator.feature_importances_, index=df.columns) feats = feats.sort_values(ascending=False) - 進階版的 GDBT 模型(
Xgboost、lightbm、catboost)中,才有上述三種不同的重要性Xgboost 對應參數 計算時間 估計精確性 sklearn 有此功能 分支次數 weight 最快 最低 O 分支覆蓋度 cover 快 中 X 損失降低量 (資訊增益度) gain 較慢 最高 X - 機器學習的優化循環
- 原始特徵
- 進階版 GDBT 模型擬合
- 用特徵重要性增刪特徵
- 特徵選擇(刪除) : 挑選門檻,刪除一部分重要性較低的特徵
- 特徵組合(增加) : 依領域知識,對前幾名的特徵做特徵組合或群聚編碼,形成更強力特徵
- 交叉驗證 (cross validation),確認特徵效果是否改善
- 排序重要性 (Permutation Importance)
-
雖然特徵重要性相當實用,然而計算原理必須基於樹狀模型,於是有了可延伸至非樹狀模型的排序重要性
-
排序重要性是打散單一特徵的資料排序,再用原本模型重新預測,觀察打散前後誤差變化有多少
特徵重要性 Feature Importance 排序重要性 Permutation Importance 適用模型 限定樹狀模型 機器學習模型均可 計算原理 樹狀模型的分歧特徵 打散原始資料中單一特徵的排序 額外計算時間 較短 較長
-
- 延伸閱讀 :
-
Day_32 : 分類型特徵優化 - 葉編碼
- 葉編碼(leaf encoding) : 採用決策樹的葉點作為編碼依據重新編碼
- 葉編碼的目的是重新標計資料,以擬合後的樹狀模型分歧條件,將資料離散化,這樣比人為寫作的判斷條件更精準,更符合資料的分布情形
- 葉編碼完後,因特徵數量較多,通常搭配羅吉斯回歸或者分解機做預測,其他模型較不適合
from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier # 因為擬合(fit)與編碼(transform)需要分開, 因此不使用.get_dummy, 而採用 sklearn 的 OneHotEncoder from sklearn.preprocessing import OneHotEncoder from sklearn.metrics import roc_curve # 隨機森林擬合後, 再將葉編碼 (*.apply) 結果做獨熱 / 邏輯斯迴歸 rf = RandomForestClassifier(n_estimators=20, min_samples_split=10, min_samples_leaf=5, max_features=4, max_depth=3, bootstrap=True) onehot = OneHotEncoder() lr = LogisticRegression(solver='lbfgs', max_iter=1000) rf.fit(train_X, train_Y) onehot.fit(rf.apply(train_X)) lr.fit(onehot.transform(rf.apply(val_X)), val_Y) # 將隨機森林+葉編碼+邏輯斯迴歸結果輸出 pred_rf_lr = lr.predict_proba(onehot.transform(rf.apply(test_X)))[:, 1] fpr_rf_lr, tpr_rf_lr, _ = roc_curve(test_Y, pred_rf_lr) # 將隨機森林結果輸出 pred_rf = rf.predict_proba(test_X)[:, 1] fpr_rf, tpr_rf, _ = roc_curve(test_Y, pred_rf) - 延伸閱讀 :
- 葉編碼(leaf encoding) : 採用決策樹的葉點作為編碼依據重新編碼
-
Day_33 : 機器如何學習
- 定義模型 : 線性回歸、決策樹、神經網路等等
- 例如線性回歸 : $ y = b + w * x $
-
$w$ : weight 和$b$ : bias 就是模型參數 - 不同參數模型會產生不同的
$\hat{y}$ - 希望產生出來的
$\hat{y}$ 與真實答案$y$ 越接近越好 - 找出一組參數讓模型產生的
$\hat{y}$ 與真正的$y$ 很接近,這個過程有點像是學習的概念。
-
- 例如線性回歸 : $ y = b + w * x $
- 評估模型好壞 : 定義一個目標函數 (objective function) 也可稱為損失函數 (Loss function),來衡量模型好壞
- 例如線性回歸可以使用均方差(mean square error)來衡量 $$ MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i-\hat{y_i})^2$$
- Loss 越大代表模型預測愈不准,代表不該選擇這個參數
- 找出最佳參數 : 可以使用爆力法、梯度下降 (Gradient Descent)、增量訓練 (Addtive Training) 等方式
- 過擬合 (over-fitting) : 訓練過程學習到了噪音導致在實際應用失準
-
欠擬合 (under-fitting) : 模型無法好好的擬合訓練數據
- 如何知道 : 觀察訓練資料與測試資料的誤差趨勢
- 如何改善 :
- 過擬合 :
- 增加資料量
- 降低模型複雜度
- 使用正規化 (Regularization)
- 欠擬合 :
- 增加模型複雜度
- 減輕或不使用正規化
- 過擬合 :
- 延伸閱讀 :
- 定義模型 : 線性回歸、決策樹、神經網路等等
-
Day_34 : 訓練與測試集切分
- 為何需要切分 :
- 機器學習模型需要資料訓練
- 若所有資料都送進訓練模型,就沒有額外資料來評估模型
- 機器模型可能過擬合,需要驗證/測試集來評估模型是否過擬合
- 使用 train_test_split 進行切分
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42, shuffle=False) -
K-fold Cross Validation : 若僅做一次切分,有些資料會沒有被拿來訓練,因此有 cross validation 方法,讓結果更穩定
from sklearn.model_selection import KFold X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) y = np.array([1, 2, 3, 4]) kf = KFold(n_splits=2, shuffle=False) kf.get_n_splits(X) for train_index, test_index in kf.split(X): print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] - 驗證集與測試集差異 : 驗證集常用來評估不同超參數或不同模型的結果,測試集則是預先保留的資料,在專案開發過程中都不使用,最終在拿來做測試
- 延伸閱讀 :
- 為何需要切分 :
-
Day_35 : Regression & Classification
- 機器學習主要分為回歸問題與分類問題
- 回歸問題 : 預測目標值為實數(
$-\infty$ 至$\infty$)(continuous) - 分類問題 : 預測目標值為類別(0或1)(discrete)
- 回歸問題可以轉化為分類問題 :
- 原本預測身高(cm)問題可以轉化為預測高、中等、矮(類別)
- 回歸問題 : 預測目標值為實數(
- 二元分類(binary-class) vs. 多元分類(multi-class)
- 二元分類 : 目標類別只有兩個,例如詐騙分析(正常用戶、異常用戶)、瑕疵偵測(瑕疵、正常)
- 多元分類 : 目標類別有兩種以上,例如手寫數字辨識(0~9),影像競賽(ImageNet)有高達1000個類別
- 多元分類 vs. 多標籤(multi-label)
- 多元分類 : 每個樣本只能歸在一個類別
- 多標籤 : 一個樣本可以屬於多個類別
- 延伸閱讀 :
- 機器學習主要分為回歸問題與分類問題
-
Day_36 : 評估指標選定
-
設定各項指標來評估模型的準確性,最常見的為準確率 (Accuracy) = 正確分類樣本數/總樣本數
-
不同的評估指標有不同的評估準則與面向,衡量的重點有所不同
-
評估指標
- 回歸 : 觀察預測值 (prediction) 與實際值 (ground truth) 的差距
- MAE (mean absolute error),範圍[0,inf]
- MSE (mean square error),範圍[0,inf]
- R-square,範圍[0,1]
- 分類 : 觀察預測值與實際值的正確程度
- AUC (area under curve),範圍[0,1]
- F1-score (precision, recall),範圍[0,1]
- 混淆矩陣 (Confusion Matrix)
- 回歸 : 觀察預測值 (prediction) 與實際值 (ground truth) 的差距
-
回歸問題可透過 R-square 快速了解準確度,二元分類問題通常使用 AUC 評估,希望哪個類別不要分錯則可使用 F1-score 並觀察 precision 與 recall 數值,多分類問題則可使用 top-k accuracy,例如 ImageNet 競賽通常採用 top-5 accuracy
-
Q&A :
- AUC 計算怪怪的,AUC 的 y_pred 的值填入每個樣本預測機率 (probility) 而非分類結果
- F1-score 計算則填入每個樣本分類結果,如機率 >= 0.5 則視為 1,而非填入機率值
from sklearn import metrics, datasets from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split # MAE, MSE, R-square X, y = datasets.make_regression(n_features=1, random_state=42, noise=4) # 生成資料 model = LinearRegression() # 建立回歸模型 model.fit(X, y) # 將資料放進模型訓練 prediction = model.predict(X) # 進行預測 mae = metrics.mean_absolute_error(prediction, y) # 使用 MAE 評估 mse = metrics.mean_squared_error(prediction, y) # 使用 MSE 評估 r2 = metrics.r2_score(prediction, y) # 使用 r-square 評估 # AUC cancer = datasets.load_breast_cancer() # 我們使用 sklearn 內含的乳癌資料集 X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=50, random_state=0) y_pred = np.random.random((50,)) # 我們先隨機生成 50 筆預測值,範圍都在 0~1 之間,代表機率值 auc = metrics.roc_auc_score(y_test, y_pred) # 使用 roc_auc_score 來評估。 **這邊特別注意 y_pred 必須要放機率值進去!** # F1-score, precision, recall threshold = 0.5 y_pred_binarized = np.where(y_pred>threshold, 1, 0) # 使用 np.where 函數, 將 y_pred > 0.5 的值變為 1,小於 0.5 的為 0 f1 = metrics.f1_score(y_test, y_pred_binarized) # 使用 F1-Score 評估 precision = metrics.precision_score(y_test, y_pred_binarized) # 使用 Precision 評估 recall = metrics.recall_score(y_test, y_pred_binarized) # 使用 recall 評估 -
延伸閱讀 :
-
-
Day_37 : Regression 模型
- Linear Regression (線性回歸) : 簡單線性模型,可用於回歸問題,須注意資料共線性與資料標準化問題,通常可做為 baseline 使用
- Logistic Regression (羅吉斯回歸) : 分類模型,將線性模型結果加上 sigmoid 函數,將預測值限制在 0~1 之間,即為預測機率值
- 延伸閱讀 :
-
Day_38 : Regression 模型 </>
- 使用 scikit-learn 套件
from sklearn.linear_model import LinearRegression, LogisticRegression from sklearn.metrics import mean_squared_error, accuracy_score # 線性回歸 reg = LinearRegression().fit(x_train, y_train) y_pred = reg.predict(x_test) print("Mean squared error: %.2f" % mean_squared_error(y_test, y_pred)) # 羅吉斯回歸 logreg = LogisticRegression().fit(x_train, y_train) y_pred = logreg.predict(x_test) print("Accuracy: ", accuracy_score(y_test, y_pred)) - Logistic Regression 參數
- 延伸閱讀 :
- 使用 scikit-learn 套件
-
Day_39 : LASSO, Ridge regression
- 機器學習模型的目標函數有兩個非常重要的元素
- 損失函數 (Loss function) : 衡量實際值與預測值差異,讓模型往正確方向學習
- 正則化 (Regularization) : 避免模型過於複雜,造成過擬合
- 為了避免過擬合我們把正則化加入目標函數,目標函數 = 損失函數 + 正則化
- 正則化可以懲罰模型的複雜度,當模型越大其值越大
- 正則化函數 : 用來衡量模型的複雜度
- L1 :
$\alpha\sum|weight|$ - L2 :
$\alpha\sum(weight)^2$ - 這兩種都是希望模型的參數數值不要太大,原因是參數的數值變小,噪音對最終輸出的結果影響越小,提升模型的泛化能力,但也讓模型的擬合能力下降
- L1 :
- LASSO 為 Linear Regression 加上 L1
- Ridge 為 Linear Regression 加上 L2
- 其中有個超參數
$\alpha$ 可以調整正則化強度 - 延伸閱讀 :
- 機器學習模型的目標函數有兩個非常重要的元素
-
Day_40 : LASSO, Ridge regression </>
from sklearn import datasets from sklearn.linear_model import Lasso, Ridge # 讀取糖尿病資料集 diabetes = datasets.load_diabetes() # 切分訓練集/測試集 x_train, x_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, test_size=0.2, random_state=4) # 建立一個線性回歸模型 lasso = Lasso(alpha=1.0) # 將訓練資料丟進去模型訓練 lasso.fit(x_train, y_train) # 將測試資料丟進模型得到預測結果 y_pred = lasso.predict(x_test) # 印出訓練後的模型參參數 print(lasso.coef_) # 建立一個線性回歸模型 ridge = Ridge(alpha=1.0) # 將訓練資料丟進去模型訓練 ridge.fit(x_train, y_train) # 將測試資料丟進模型得到預測結果 y_pred = regr.predict(x_test) # 印出訓練後的模型參參數 print(ridge.coef_) -
Day_41 : 決策樹 Decision Tree
-
決策樹 (Decision Tree) : 透過一系列的是非問題,幫助我們將資料切分,可視覺化每個切分過程,是個具有非常高解釋性的模型
- 從訓練資料中找出規則,讓每一次決策使訊息增益 (information Gain) 最大化
- 訊息增益越大代表切分後的兩群,群內相似度越高,例如使用健檢資料來預測性別,若使用頭髮長度 50 公分進行切分,則切分後的兩群資料很有可能多數為男生或女生(相似程度高),這樣頭髮長度就是個好 feature
- 如何衡量相似程度
-
吉尼係數 (gini-index) (不純度)
$$Gini = 1 - \sum_jp_j^2$$ -
熵 (entropy)
$$Entropy = -\sum_jp_jlog_2p_j$$
-
吉尼係數 (gini-index) (不純度)
- 決策樹的特徵重要性
- 我們可以從構建樹的過程中,透過 feature 被用來切分的次數,來得知哪些 features 是相對有用的
- 所有 feature importance 的總和為 1
- 實務上可以使用 feature importance 來了解模型如何進行分類
- 延伸閱讀 :
-
決策樹 (Decision Tree) : 透過一系列的是非問題,幫助我們將資料切分,可視覺化每個切分過程,是個具有非常高解釋性的模型
-
Day_42 : 決策樹 </>
- 機器學習的建模步驟 :
- 讀取和檢查資料
- 使用 pandas 讀取 .csv 檔 :
pd.read_csv - 使用 numpy 讀取 txt 檔 :
np.loadtxt - 使用 sklearn 內建資料集 :
sklearn.datasets.load_xxx - 檢查資料數量 :
data.shape
- 使用 pandas 讀取 .csv 檔 :
- 將資料切分為訓練 (train) 與測試集 (test)
train_test_split(data)
- 建立模型開始訓練 (fit)
clf = DecisionTreeClassifier() clf.fit(x_train, y_train) - 將測試資料放進訓練好的模型進行預測 (predict),並和測試資料的 label (y_test) 做評估
clf.predict(x_test) accuracy_score(y_test, y_pred) f1_score(y_test, y_pred)
- 讀取和檢查資料
- 根據回歸/分類問題建立不同的 Classifier
from sklearn.tree_model import DecisionTreeRegressor from sklearn.tree_model import DecisionTreeClassifier # 讀取鳶尾花資料集 iris = datasets.load_iris() # 切分訓練集/測試集 x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.25, random_state=4) # 建立模型 clf = DecisionTreeClassifier() # 訓練模型 clf.fit(x_train, y_train) # 預測測試集 y_pred = clf.predict(x_test) print("Acuuracy: ", metrics.accuracy_score(y_test, y_pred)) # 列出特徵和重要性 print(iris.feature_names) print("Feature importance: ", clf.feature_importances_) - 決策樹的超參數
- Criterion: 衡量資料相似程度的 metric
- Max_depth: 樹能生長的最深限制
- Min_samples_split: 至少要多少樣本以上才進行切分
-
Min_samples_lear: 最終的葉子(節點)上至少要有多少樣本
clf = DecisionTreeClassifier( criterion = 'gini', max_depth = None, min_samples_split = 2, min_samples_left = 1, )
- 延伸閱讀 :
- 機器學習的建模步驟 :
-
Day_43 : 隨機森林樹 Random Forest
- 決策樹缺點 :
- 若不對決策樹進行限制 (樹深度、葉子上至少要有多少樣本等),決策樹非常容易 over-fitting
- 集成模型 - 隨機森林 (Random Forest)
- 集成 (Ensemble) : 將多個模型的結果組合在一起,透過投票或是加權的方式獲得最終結果
- 每棵樹使用部分訓練資料與特徵進行訓練而成
- 延伸閱讀 :
- 決策樹缺點 :
-
Day_44 : 隨機森林樹 </>
from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import RandomForestRegressor clf = RandomForestClassifier( n_estimators=10, #決策樹的數量量 criterion="gini", max_features="auto", #如何選取 features max_depth=10, min_samples_split=2, min_samples_leaf=1) # 將訓練資料丟進去模型訓練 clf.fit(x_train, y_train) # 將測試資料丟進模型得到預測結果 y_pred = clf.predict(x_test) print("Accuracy: ", accuracy_score(y_test, y_pred)) # 建立一個線性回歸模型 regr = RandomForestRegressor() # 將訓練資料丟進去模型訓練 regr.fit(x_train, y_train) # 將測試資料丟進模型得到預測結果 y_pred = regr.predict(x_test) print("Mean squared error: %.2f" % mean_squared_error(y_test, y_pred)) -
Day_45 : 梯度提升機 Gradient Boosting Machine
- 隨機森林使用的方法為 Bagging (Bootstrap Aggregating),用抽樣資料與特徵生成每一棵樹,最後在取平均
- Boosting 是另一種集成方法,希望由後面生成的樹來修正前面學不好的地方
-
Bagging :
- 透過抽樣 (sampling) 方式生成每一棵樹,樹與樹之間是獨立的
- 降低 over-fitting
- 減少 variance
- Independent classifiers
-
Boosting :
- 透過序列 (additive) 方式生成每一棵樹,每棵樹與前面的樹關聯
- 可能會 over-fitting
- 減少 bias 和 variance
- Sequential classifiers
- 延伸閱讀 :
-
Day_46 : 梯度提升機 </>
from sklearn.ensemble import GradientBoostingClassifier from sklearn.ensemble import GradientBoostingRegressor clf = GradientBoostingClassifier( loss="deviance", #Loss 的選擇,若若改為 exponential 則會變成Adaboosting 演算法,概念念相同但實作稍微不同 learning_rate=0.1, #每棵樹對最終結果的影響,應與 n_estimators 成反比 n_estimators=100 #決策樹的數量量 ) # 訓練模型 clf.fit(x_train, y_train) # 預測測試集 y_pred = clf.predict(x_test) print("Acuuracy: ", metrics.accuracy_score(y_test, y_pred))
-
Day_47 : 超參數調整
- 機器學習中的超參數
- LASSO, Ridge :
$\alpha$ 的大小 - 決策樹 : 樹的深度、節點最小樣本數
- 隨機森林 : 樹的數量
- LASSO, Ridge :
- 超參數會影響模型訓練的結果,建議先使用預設再慢慢進行調整
- 超參數會影響結果但提升效果有限,資料清理和特徵工程才能最有效的提升準確率
- 超參數的調整方法
- 窮舉法 (Grid Search) : 直接指定超參數的範圍組合,每一組參數都訓練完成,再根據驗證集的結果選擇最佳參數
- 隨機搜尋 (Random Search) : 指定超參數範圍,用均勻分布進行參數抽樣,用抽到的參數進行訓練,再根據驗證集的結果選擇最佳參數,隨機搜尋通常能獲得較好的結果
- 正確的超參數調整步驟 : 若使用同一份驗證集 (validation) 來調參,可能讓模型過於擬合驗證集,正確步驟是使用 Cross-validation 確保模型的泛化性
- 將資料切分為訓練/測試集,測試集先保留不用
- 將剛切好的訓練集,再使用 Cross-validation 切成 K 份訓練/驗證集
- 用 gird/random search 的超參數進行訓練與評估
- 選出最佳參數,用該參數與全部訓練集建模
- 最後使用測試集評估結果
from sklearn import datasets, metrics from sklearn.model_selection import train_test_split, KFold, GridSearchCV from sklearn.ensemble import GradientBoostingRegressor # 讀取手寫辨識資料集 boston = datasets.load_boston() # 切分訓練集/測試集 x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.25, random_state=42) # 建立模型 clf = GradientBoostingRegressor(random_state=7) # 設定要訓練的超參數組合 n_estimators = [100, 200, 300] max_depth = [1, 3, 5] param_grid = dict(n_estimators=n_estimators, max_depth=max_depth) # 建立搜尋物件,放入模型及參數組合字典 (n_jobs=-1 會使用全部 cpu 平行運算) grid_search = GridSearchCV(clf, param_grid, scoring="neg_mean_squared_error", n_jobs=-1, verbose=1) # 開始搜尋最佳參數 grid_result = grid_search.fit(x_train, y_train) # 預設會跑 3-fold cross-validadtion,總共 9 種參數組合,總共要 train 27 次模型 # 印出最佳結果與最佳參數 print("Best Accuracy: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) # 使用最佳參數重新建立模型 clf_bestparam = GradientBoostingRegressor( max_depth=grid_result.best_params_['max_depth'], n_estimators=grid_result.best_params_['n_estimators']) # 訓練模型 clf_bestparam.fit(x_train, y_train) # 預測測試集 y_pred = clf_bestparam.predict(x_test) print(metrics.mean_squared_error(y_test, y_pred)) - 延伸閱讀 :
- 機器學習中的超參數
-
Day_48 : Kaggle
- Kaggle 為全球資料科學競賽的網站,許多資料科學的競賽均會在此舉辦,吸引全球優秀的資料科學家參加
- 主辦單位通常會把測試資料分為 public set 與 private set,參賽者上傳預測結果可以看到 public set 的成績,但比賽最終會使用 private set 的成績作為排名
- Kernels 可以看見許多高手們分享的程式碼與結果,多半會以 jupyter notebook 呈現
- Discussion 可以看到高手們互相討論可能的做法,或是資料中是否存在某些問題
- scikit-learn-practice
-
Day_49 : 混和泛化 (Blending)
-
集成是使用不同方式,結合多個或多種分類器,作為綜合預測的做法總稱
- 將模型截長補短,可以說是機器學習的和議制/多數決
- 其中分為資料層面的集成 : 如裝袋法(Bagging)、提升法(Boosting)
- 以及模型的特徵集成 : 如混和泛化(Blending)、堆疊泛化(Stacking)
- 裝袋法 (Bagging) : 將資料放入袋中抽取,每回合結束後重新放回袋中重抽,在搭配弱分類器取平均或多數決結果,例如隨機森林
- 提升法 (Boosting) : 由之前模型的預測結果,去改便資料被抽到的權重或目標值
- 將錯判的資料機率放大,正確的縮小,就是自適應提升(AdaBoost, Adaptive Boosting)
- 如果是依照估計誤差的殘差項調整新目標值,則就是梯度提升機 (Gradient Boosting Machine) 的作法,只是梯度提升機還加上用梯度來選擇決策樹分支
- Bagging/Boosting : 使用不同資料、相同模型,多次估計的結果合成最終預測
- Voting/Blending/Stacking : 使用同一資料不同模型,合成出不同預測結果
- 混合泛化 (Blending)
- 將不同模型的預測值加權合成,權重和為1如果取預測的平均 or 一人一票多數決(每個模型權重相同),則又稱為投票泛化(Voting)
- 容易使用且有效
- 使用前提 : 個別單模效果好(有調教)並且模型差異大,單模要好尤其重要
- 延伸閱讀 :
new_train = pd.DataFrame([lr_y_prob, gdbt_y_prob, rf_y_prob]) new_train = new_train.T clf = LogisticRegression(tol=0.001, penalty='l2', fit_intercept=False, C=1.0) clf.fit(new_train, train_Y) coef = clf.coef_[0] / sum(clf.coef_[0]) blending_pred = lr_pred*coef[0] + gdbt_pred*coef[1] + rf_pred*coef[2]
-
集成是使用不同方式,結合多個或多種分類器,作為綜合預測的做法總稱
-
Day_50 : 堆疊泛化 (Stacking)
- 不只將預測結果混和,而是使用預測結果當新特徵
- Stacking 主要是把模型當作下一階的特徵編碼器來使用,但是待編碼資料與訓練編碼器的資料不可重複(訓練測試的不可重複性)
- 若是將訓練資料切成兩份,待編碼資料太少,下一層的資料筆數就會太少,訓練編碼器的資料太少,則編碼器的強度就會不夠,因此使用 K-fold 拆分資料訓練,這樣資料沒有變少,編碼器也夠強韌,但 K 值越大訓練時間越長
- 自我遞迴的 Stacking :
- Q1:能不能新舊特徵一起用,再用模型預測呢?
- A1:可以,這裡其實有個有趣的思考,也就是 : 這樣不就可以一直一直無限增加特徵下去? 這樣後面的特徵還有意義嗎? 不會 Overfitting 嗎?...其實加太多次是會 Overfitting 的,必需謹慎切分 Fold 以及新增次數
- Q2:新的特徵,能不能再搭配模型創特徵,第三層第四層...一直下去呢?
- A2:可以,但是每多一層,模型會越複雜 : 因此泛化 (又稱為魯棒性) 會做得更好,精準度也會下降,所以除非第一層的單模調得很好,否則兩三層就不需要繼續往下了
- Q3:既然同層新特徵會 Overfitting,層數加深會增加泛化,兩者同時用是不是就能把缺點互相抵銷呢?
- A3:可以!!而且這正是 Stacking 最有趣的地方,但真正實踐時,程式複雜,運算時間又要再往上一個量級,之前曾有大神寫過 StackNet 實現這個想法,用JVM 加速運算,但實際上使用時調參困難,後繼使用的人就少了
- Q4 : 實際上寫 Stacking 有這麼困難嗎?
- A4 : 其實不難,就像 sklearn 幫我們寫好了許多機器學習模型,mlxtend 也已經幫我們寫好了 Stacking 的模型,所以用就可以了 (參考今日範例或 mlxtrend 官網)
- Q5 : Stacking 結果分數真的比較高嗎?
- A5 : 不一定,有時候單模更高,有時候 Blending 效果就不錯,視資料狀況而定
- Q6 : Stacking 可以做參數調整嗎?
- A6 : 可以,請參考 mlxtrend 的調參範例,主要差異是參數名稱寫法稍有不同
- Q7 : 還有其他做 Stacking 時需要注意的事項嗎?
- A7 :「分類問題」的 Stacking 要注意兩件事:記得加上 use_probas=True (輸出特徵才會是機率值),以及輸出的總特徵數會是:模型數量*分類數量 (回歸問題特徵數=模型數量量)
from mlxtend.classifier import StackingClassifier meta_estimator = GradientBoostingClassifier(tol=100, subsample=0.70, n_estimators=50, max_features='sqrt', max_depth=4, learning_rate=0.3) stacking = StackingClassifier(classifiers =[lr, gdbt, rf], use_probas=True, meta_classifier=meta_estimator) stacking.fit(train_X, train_Y) stacking_pred = stacking.predict(test_X)
- Q1:能不能新舊特徵一起用,再用模型預測呢?
- Day_51~53 : Kaggle期中考
- Enron Fraud Dataset 安隆公司詐欺案資料集
- 如何處理存在各種缺陷的真實資料
- 使用 val / test data 來了解機器學習模型的訓練情形
- 使用適當的評估函數了解預測結果
- 應用適當的特徵工程提升模型的準確率
- 調整機器學習模型的超參數來提升準確率
- 清楚的說明文件讓別人了解你的成果
- Enron Fraud Dataset 安隆公司詐欺案資料集
-
Day_54 : 非監督式機器學習簡介
- 非監督學習允許我們在對結果無法預知時接近問題。非監督學習演算法只基於輸入資料找出模式。當我們無法確定尋找內容,或無標記 (y) 資料時,通常會用這個演算法,幫助我們了解資料模式
- 非監督學習算法概要
- 聚類分析 : 尋找資料的隱藏模式
- 降低維度 : 特徵數太大且特徵間相關性高,以此方式縮減特徵維度
- 其他 : 關聯法則 (購物籃分析)、異常值偵測、探索性資料分析等
- 應用案例 :
- 客戶分群 : 在資料沒有任何標記,或是問題還沒定義清楚前,可用分群的方式幫助理清資料特性。
- 特徵抽象化 : 徵數太多難於理解及呈現的情況下,藉由抽象化的技術幫助降低資料維度,同時不失去原有的資訊,組合成新的特徵。
- 購物籃分析 : 資料探勘的經典案例,適用於線下或線上零售的商品組合推薦。
- 非結構化資料分析 : 非結構化資料如文字、影像等,可以藉由一些非監督式學習的技術,幫助呈現及描述資料,例如主題模型 (topic model)
- 延伸閱讀 :
-
Day_55 : K-means 聚類算法
- Supervised learning : 目標在找出決策邊界 (decision boundary)
- Unsupervised learning : 目標在找出資料結構
- Why clustering ?
- 在資料還沒有標記、問題還沒定義清楚時,聚類算法可以幫助我們理理解資料特性,評估機器學習問題方向等,也是一種呈現資料的方式
-
K-means 聚類算法
- 把所有資料點分成 k 個 cluster,使得相同 cluster 中的所有資料點彼此儘量相似,而不同 cluster 的資料點儘量不同。
- 距離測量(e.g. 歐氏距離)用於計算資料點的相似度和相異度。每個 cluster 有一個中心點。中心點可理解為最能代表 cluster 的點。
- 算法流程 :
- 隨機取 K 個點 (cluster centroid)
- 對每一個 training example 根據它距離哪一個 cluster centroid 較近,標記爲其中之一 (cluster assignment)
- 然後把 centroid 移到同一群 training examples 的中心點 (update centroid)
- 反覆進行 cluster assignment 及 update centroid, 直到 cluster assignment 不再導致 training example 被 assign 爲不同的標記 (算法收斂)
- K-means 目標是使總體群內平方誤差最小
$$\sum_{i=0}^n\min_{\mu_j\in{C}} (||x_i-\mu_j||^2) $$ - 注意事項 :
- Random initialization : initial 設定的不同,會導致得到不同 clustering 的結果,可能導致 local optima,而非 global optima。
- 因爲沒有預先的標記,對於 cluster 數量多少才是最佳解,沒有標準答案,得靠手動測試觀察。
- 延伸閱讀 :
- Andrew Ng - K-means
-
Unsupervised machine learning
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=3, n_init=1, init='random') kmeans.fit(X) print(kmeans.cluster_centers_) print(kmeans.labels_)
-
Day_56 : K-means 觀察 : 使用輪廓分析
- 分群模型的評估
- 困難點 : 非監督模型因為沒有目標值,因此無法使用目標值與預測值的差距來衡量優劣
- 評估方式類型
- 有目標值的分群 : 如果資料有目標值,只是先忽略目標值做非監督學習,則只要微調後,就可以使用原本監督的測量函數評估準確性
- 無目標值的分群 : 通常沒有目標值/目標值非常少才會用非監督模型,這種情況下,只能使用資料本身的分布資訊,來做模型的評估
- 輪廓分析 (Silhouette analysis)
- 歷史 : 最早由 Peter J. Rousseeuw 於 1986 提出。它同時考慮了群內以及相鄰群的距離,除了可以評估資料點分群是否得當,也可以用來來評估不同分群方式對於資料的分群效果
- 設計精神 : 同一群的資料點應該很近,不同群的資料點應該很遠,所以設計一種當同群資料點越近 / 不同群資料點越遠時越大的分數,當資料點在兩群交界附近,希望分數接近 0
- 單點輪廓值 :
- 對任意單一資料點 i,「與 i 同一群」的資料點,距離 i 的平均稱為 ai
- 「與 i 不同群」的資料點中,不同群距離 i 平均中,最近的稱為 bi ( 其實就是要取第二靠近 i 的那一群平均,滿足交界上分數為 0 的設計)
- i 點的輪廓分數 si : (bi-ai) / max{bi, ai} 其實只要不是刻意分錯,bi 通常會大於等於 ai,所以上述公式在此條件下可以化簡為 1 - ai / bi
- 整體輪廓分析 :
- 分組觀察,依照不同的類別,將同類別的輪廓分數排序後顯示,發現兩組的輪廓值大多在平均以下,且比例\例上接近 0 的點也比較多,這些情況都表示這兩組似乎沒分得那麼開
- 平均值觀察,計算分群的輪廓分數總平均,分的群數越多應該分數越小,如果總平均值沒有隨著分群數增加而變小,就說明了那些分群數較不洽當
from sklearn.cluster import KMeans from sklearn.metrics import silhouette_samples, silhouette_score # 宣告 KMean 分群器, 對 X 訓練並預測 clusterer = KMeans(n_clusters=n_clusters, random_state=10) cluster_labels = clusterer.fit_predict(X) # 計算所有點的 silhouette_score 平均 silhouette_avg = silhouette_score(X, cluster_labels) print("For n_clusters =", n_clusters, "The average silhouette_score is :", silhouette_avg) # 計算所有樣本的 The silhouette_score sample_silhouette_values = silhouette_samples(X, cluster_labels)
- 分群模型的評估
-
Day_57 : 階層分群法
- 階層式分析 : 一種構建 cluster 的層次結構的算法。該算法從分配給自己 cluster 的所有資料點開始。然後,兩個距離最近的 cluster 合併為同一個 cluster。最後,當只剩下一個 cluster 時,該算法結束。
- K-means vs. 階層分群 :
- K-means : 需要定義群數 (n of clusters)
- 階層分群 : 可根據定義距離來分群 (bottom-up),也可以決定群數做分群 (top-down)
- 階層分群演算法流程 : 不指定分群數量
- 每筆資料為一個 cluster
- 計算每兩群之間的距離
- 將最近的兩群合併成一群
- 重覆步驟 2、3,直到所有資料合併成同一 cluster
- 階層分群距離計算方式 :
- single-link : 群聚與群聚間的距離可以定義為不同群聚中最接近兩點間的距離。
- complete-link : 群聚間的距離定義為不同群聚中最遠兩點間的距離,這樣可以保證這兩個集合併後,任何一對的距離不會大於 d。
- average-link : 群聚間的距離定義為不同群聚間各點與各點間距離總和的平均。
- 階層分群的優劣分析 :
- 優點 : 概念簡單,易於呈現,不需指定群數
- 缺點 : 只適用於少量資料,大量資料會很難處理
- 延伸閱讀 :
from sklearn.cluster import AgglomerativeClustering from sklearn import datasets iris = datasets.load_iris() X = iris.data y = iris.target estimators = [('hc_iris_ward', AgglomerativeClustering(n_clusters=3, linkage="ward")), ('hc_iris_complete', AgglomerativeClustering(n_clusters=3, linkage="complete")), ('hc_iris_average', AgglomerativeClustering(n_clusters=3, linkage="average"))] for name, est in estimators: est.fit(X) labels = est.labels_
-
Day_58 : 階層分群法 觀察 : 2D 樣版資料集
- 資料集用途 : 通常這樣的資料集,是用來讓人眼評估非監督模型的好壞,因為非監督模型的任務包含分群 (對應於監督的分類) 與流形還原 (對應監督的迴歸),所以 2D 樣板資料集在設計上也包含這兩種類型的資料集
- sklearn 的 2D 樣版資料集 :
- sklearn 的資料集主要分為兩種 : 載入式 (Loaders) 與生成式 (Samples generator),載入式的是固定資料,生成式的則是先有既定模式,在模式下有限度的隨機生成每次使用的資料集
- 2D 樣版資料集屬於生成式資料集,使用不同分布,用以顯示各種非監督模型的優缺點,提供使用者參考
- 2D 樣板資料集很多套件都有,也不限於只有 Python 上使用的套件 : 如 sklearn / mathworks / mlbench 都有對應的資料集
from sklearn import cluster, datasets # 設定 2D 樣板資料 n_samples = 1500 random_state = 100 # 生成 同心圓 資料點 noisy_circles = datasets.make_circles(n_samples=n_samples, factor=.5, noise=.05) # 生成 斜向三群 資料點 (使用轉換矩陣) X, y = datasets.make_blobs(n_samples=n_samples, random_state=random_state) transformation = [[0.6, -0.6], [-0.4, 0.8]] X_aniso = np.dot(X, transformation) aniso = (X_aniso, y) # 生成 稀疏三群 資料點 varied = datasets.make_blobs(n_samples=n_samples, cluster_std=[1.0, 2.5, 0.5], random_state=random_state) # 生成 雙半月 資料點 noisy_moons = datasets.make_moons(n_samples=n_samples, noise=.05) # 生成 緊密三群 資料點 blobs = datasets.make_blobs(n_samples=n_samples, random_state=8) # 生成 2維均勻分布 資料點 no_structure = np.random.rand(n_samples, 2), None
-
Day_59 : 降維方法 - 主成分分析
- 為甚麼需要降低維度 (Dimension reduction)
- 減少 RAM or disk space 使用,有助於加速 learning algorithm
- 影像壓縮 : 原始影像維度爲 512,在降低維度到 16 的情況下,圖片雖然有些許模糊,但依然保有明顯的輪廓和特徵
- 壓縮資料可進而組合出新的、抽象化的特徵,減少冗餘的資訊
- 特徵太多時,很難 visualize data,不容易觀察資料。把資料維度 (特徵) 降到 2 到 3 個,則能夠用一般的 2D 或 3D 圖表呈現資料
-
主成分分析 (PCA) : 透過計算 eigen value,eigen vector,可以將原本的 features 降維至特定的維度
- 原本資料有 100 個 features,透過 PCA,可以將這 100 個 features 降成 2 個 features
- 新 features 為舊 features 的線性組合,且彼此不相關
- 在維度太大發生 overfitting 的情況下,可以嘗試用PCA 組成的特徵來做監督式學習
- 不建議在早期時做,否則可能會丟失重要的 features 而 underfitting
- 可以在 optimization 階段時,考慮 PCA ,並觀察運用了 PCA 後對準確度的影響
- 延伸閱讀 :
- Unsupervised Learning
- Further Principal Components
- Principal Components Regression
- Andrew Ng - Dimensionality Reduction
from sklearn import decomposition pca = decomposition.PCA(n_components=3) pca.fit(X) X = pca.transform(X)
- 為甚麼需要降低維度 (Dimension reduction)
-
Day_60 : PCA 觀察 : 使用手寫辨識資料集
- 手寫辨識資料集的來源 : 手寫辨識資料集 (MNIST, Modified National Institute of Standards and Technology databas) 原始來源的 NIST,應該是來自於美國人口普查局的員工以及學生手寫所得,其中的 Modified 指的是資料集為了適合機器學習做了一些調整 : 將原始圖案一律轉成黑底白字,做了對應的抗鋸齒的調整,最後存成 28x28 的灰階圖案,成為了目前最常聽到的基礎影像資料集
- sklearn 中的手寫辨識資料集 : 與完整的 MNIST 不同,sklearn 為了方便非深度學習的計算,再一次將圖片的大小壓縮到 8x8 的大小,雖然仍是灰階,但就形狀上已經有點難以用肉眼辨識,但壓縮到如此大小時,每張手寫圖就可以當作 64 (8x8=64) 個特徵的一筆資料,搭配一般的機器學習模型做出學習與預測
- 為什麼挑 MNIST 檢驗 PCA 的降維效果 :
- 高維度、高複雜性、人可理解的資料集
- 由於 PCA 的強大,如果資料有意義的維度太低,則前幾個主成分就可以將資料解釋完畢
- 使用一般圖形資料,維度又會太高,因此我們使用 sklearn 版本的 MNIST 檢驗 PCA,以兼顧內容的複雜性與可理解性
# 載入套件 import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn import datasets from sklearn.decomposition import PCA from sklearn.linear_model import SGDClassifier from sklearn.pipeline import Pipeline from sklearn.model_selection import GridSearchCV import warnings warnings.filterwarnings("ignore") # 定義 PCA 與隨後的邏輯斯迴歸函數 logistic = SGDClassifier(loss='log', penalty='l2', max_iter=10000, tol=1e-5, random_state=0) pca = PCA() pipe = Pipeline(steps=[('pca', pca), ('logistic', logistic)]) # 載入手寫數字辨識集 digits = datasets.load_digits() X_digits = digits.data y_digits = digits.target # 先執行 GridSearchCV 跑出最佳參數 param_grid = { 'pca__n_components': [4, 10, 20, 30, 40, 50, 64], 'logistic__alpha': np.logspace(-4, 4, 5), } search = GridSearchCV(pipe, param_grid, iid=False, cv=5, return_train_score=False) search.fit(X_digits, y_digits) print("Best parameter (CV score=%0.3f):" % search.best_score_) print(search.best_params_) # 繪製不同 components 的 PCA 解釋度 pca.fit(X_digits) fig, (ax0, ax1) = plt.subplots(nrows=2, sharex=True, figsize=(6, 6)) ax0.plot(pca.explained_variance_ratio_, linewidth=2) ax0.set_ylabel('PCA explained variance') ax0.axvline(search.best_estimator_.named_steps['pca'].n_components, linestyle=':', label='n_components chosen') ax0.legend(prop=dict(size=12)) # 繪製不同採樣點的分類正確率 results = pd.DataFrame(search.cv_results_) components_col = 'param_pca__n_components' best_clfs = results.groupby(components_col).apply(lambda g: g.nlargest(1, 'mean_test_score')) best_clfs.plot(x=components_col, y='mean_test_score', yerr='std_test_score', legend=False, ax=ax1) ax1.set_ylabel('Classification accuracy (val)') ax1.set_xlabel('n_components') plt.tight_layout() plt.show()
-
Day_61 : 降維方法 - t-SNE
- PCA 的問題
- 求共變異數矩陣進行奇異值分解,因此會被資料的差異性影響,無法很好的表現相似性及分佈。
- PCA 是一種線性降維方式,特徵間爲非線性關係時 (e.g. 文字、影像資料),PCA 很容易 underfitting
- t-SNE
- t-SNE 也是一種降維方式,但它用了更複雜的公式來表達高維和低維之間的關係。
- 主要是將高維的資料用 gaussian distribution 的機率密度函數近似,而低維資料的部分用 t 分佈來來近似,在用 KL divergence 計算相似度,再以梯度下降 (gradient descent) 求最佳解。
- t-SNE 優劣
- 優點 :
- 當特數量過多時,使用 PCA 可能會造成降維後的 underfitting,這時可以考慮使用 t-SNE 來降維,
- t-SNE 對於特徵非線性資料有更好的降維呈現能力
- 缺點 :
- t-SNE 的需要比較多的時間執行
- 優點 :
- 延伸閱讀 :
from sklearn import manifold tsne = manifold.TSNE(n_components=2, random_state=0, init='pca', learning_rate=200., early_exaggeration=12.) X_tsne = tsne.fit_transform(X)
- PCA 的問題
-
Day_62 : t-sne 觀察 : 分群與流形還原
- 流形還原的意義
- 流形還原就是將高維度上相近的點,對應到低維度上相近的點,沒有資料點的地方不列入考量範圍
- 簡單的說,如果資料結構像瑞士捲一樣,那麼流形還原就是把它攤開鋪平 (流形還原資料集的其中一種,就是叫做瑞士捲 - Swiss Roll)
- 其實流形還原的模型相當多種,只是應用上較少,常見的除了了 t-sne 之外,還有 Isomap / LLE / MDS 等等,因為實用度不高,之後的課程中我們也不會教,因此只在此展示幾種流形還原的結果圖
from sklearn import manifold from time import time n_components = 2 perplexities = [4, 6, 9, 14, 21, 30, 45, 66, 100] for i, perplexity in enumerate(perplexities): t0 = time() tsne = manifold.TSNE(n_components=n_components, init='random', random_state=0, perplexity=perplexity) Y = tsne.fit_transform(X) t1 = time() # perplexity 越高,時間越長,效果越好 print("S-curve, perplexity=%d in %.2g sec" % (perplexity, t1 - t0))
- 流形還原的意義
- Day_63 : 深度學習簡介
-
類神經網路 (Neural Network)
- 在1956年的達特茅斯會議中誕生,以數學模擬神經傳導輸出預測,在初期人工智慧領域中就是重要分支
- 因層數一多計算量就大幅增加等問題,過去無法解決,雖不斷有學者試圖改善,在歷史中仍不免大起大落
- 直到近幾年在算法、硬體能力與巨量資料的改善下,多層的類神經網路才重新成為當前人工智慧的應用主流
-
類神經網路與深度學習的比較
- 就基礎要素而言,深度學習是比較多層的類神經網路
- 但就實務應用的層次上,因著設計思路與連結架構的不同,兩者有了很大的差異性
類神經網路
(Neural Network)深度學習
(Deep Learning)隱藏層數量 1~2層 十數層到百層以上不等 活躍年代 1956~1974 2011⾄至今 代表結構 感知器 (Perceptron)
啟動函數 (Activation Function)卷積神經網路(CNN)
遞歸神經網路(RNN)解決問題 基礎迴歸問題 影像、自然語言處理等多樣問題 -
深度學習應用爆發的三大關鍵
- 類神經的應用曾沉寂二三十年,直到 2012 年 AlexNet 在 ImageNet 圖像分類競賽獲得驚艷表現後,才重回主流舞台
- 深度學習相比於過去,到底有哪些關鍵優勢呢
- 算法改良
- 網路結構:CNN 與 RNN 等結構在神經連結上做有意義的精省,使得計算力得以用在刀口上
- 細節改良:DropOut (隨機移除) 同時有節省連結與集成的效果,BatchNormalization (批次正規化) 讓神經層間有更好的傳導力
- 計算機硬體能力提升
- 圖形處理器 (GPU) 的誕生,持續了晶片摩爾定律,讓計算成為可行
- 巨量資料
- 個人行動裝置的普及網路速度的持續提升,帶來巨量的資料量,使得深度學習有了可以學習的素材
- 算法改良
-
卷積神經網路 (CNN, Convolutional Neural Network)
- 設計目標:影像處理
- 結構改進:CNN 參考像素遠近省略神經元,並且用影像特徵的平移不變性來共用權重,大幅減少了影像計算的負擔
- 衍伸應用:只要符合上述兩種特性的應用,都可以使用 CNN 來來計算,例如 AlphaGo 的 v18 版的兩個主網路都是 CNN 圖片
-
遞歸神經網路 (RNN, Recurrent Neural Network)
- 設計目標:時序資料處理
- 結構改進:RNN 雖然看似在 NN 外增加了時序間的橫向傳遞,但實際上還是依照時間遠近省略了部分連結
- 衍伸應用:只要資料是有順序性的應用,都可以使用 RNN 來計算,近年在自然語言處理 (NLP) 上的應用反而成為大宗
-
深度學習 - 巨觀結構
- 輸入層 (input layer):輸入資料進入的位置
- 輸出層 (hidden layer):輸出預測值的最後一層
- 隱藏層 (output layer):除了上述兩層外,其他層都稱為隱藏
-
深度學習 - 微觀結構
- 啟動函數 (Activation Function):位於神經元內部,將上一層神經元的輸入總和,轉換成這一個神經元輸出值的函數
- 損失函數 (Loss Function):定義預測值與實際值的誤差大小
- 倒傳遞 (Back-Propagation):將損失值,轉換成類神經權重更新的方法
-
延伸閱讀 :
-
- Day_64 : 深度學習體驗 - 模型調整與學習曲線
- 深度學習體驗平台:TensorFlowPlayGround
- TensorFlow PlayGround 是 Google 精心開發的體驗網⾴頁,提供學習者在接觸語言之前,就可以對深度學習能概略了
- 平台上目前有 4 個分類問題與 2 個迴歸問題
- 練習 1:按下啟動,觀察指標變化
- 全部使用預設值,按下啟動按鈕,看發生了什麼變化?
- 遞迴次數(Epoch,左上):逐漸增加
- 神經元(中央):⽅方框圖案逐漸明顯,權重逐漸加粗,滑鼠移至上方會顯示權重
- 訓練/測試誤差:開始時明顯下降,幅度漸漸趨緩
- 學習曲線:訓練/測試誤差
- 結果圖像化:圖像逐漸穩定後續討論觀察,如果沒有特別註明,均以訓練/測試誤差是否趨近 0 為主,這種情況我們常稱為收斂
- 練習 2:增減隱藏層數
- 練習操作
- 資料集切換:分類資料集(左下) - 2 群,調整層數後啟動學習
- 資料集切換:分類資料集(左上) - 同心圓,調整層數後啟動學習
- 資料集切換:迴歸資料集(左) - 對⾓角線,調整層數後啟動學習
- 實驗結果
- 2 群與對角線:因資料集結構簡單,即使沒有隱藏層也會收斂
- 同心圓:資料集稍微複雜 (無法線性分割),因此最少要⼀一層隱藏層才會收斂
- 練習操作
- 練習 3:增減神經元數
- 練習操作
- 資料集切換:分類資料集(左上)-同心圓,隱藏層設為 1 後啟動學習
- 切換不同隱藏層神經元數量後,看看學習效果有何不同?
- 實驗結果
- 當神經元少於等於兩個以下時,將無法收斂
- 練習操作
- 練習 4:切換不同特徵
- 練習操作
- 資料集切換:分類資料集(左上) - 同心圓,隱藏層 1 層,隱藏神經元 2 個
- 切換任選不同的 2 個特徵後啟動,看看學習效果有何不同?
- 實驗結果
- 當特徵選到兩個特徵的平方時,即使中間只有 2 個神經元也會收斂
- 練習操作
- 知識要點
- 雖然圖像化更直覺,但是並非量化指標且可視化不容易,故深度學習的觀察指標仍以損失函數/誤差為主
- 對於不同資料類型,適合加深與加寬的問題都有,但加深適合的問題類型較多
- 輸入特徵的選擇影響結果甚鉅,因此深度學習也需要考慮特徵工程
- 深度學習體驗平台:TensorFlowPlayGround
- Day_65 : 深度學習體驗 - 啟動函數與正規化
- 練習 5:切換批次大小
- 練習操作
- 資料集切換 : 分類資料集(右下) - 螺旋雙臂,特徵全選,隱藏層1層 / 8神經元
- 調整不同的批次大小後執行 500 次遞迴,看看學習效果有何不同?
- 實驗結果
- 批次大小很小時,雖然收斂過程非常不穩定,但平均而言會收斂到較好的結果
- 實務上,批次大小如果極小,效果確實比較好,但計算時間會相當久,因此通常會依照時間需要而折衷
- 練習操作
- 練習 6:切換學習速率
- 練習操作
- 資料集切換:分類資料集(右下) - 螺旋雙臂,特徵全選,隱藏層1層 / 8神經元,批次大小固定 10
- 調整不同的學習速率後執行 500 次遞迴,看看學習效果有何不同?
- 實驗結果
- 小於 0.3 時學習速率較大時,收斂過程會越不穩定,但會收斂到較好的結果
- 大於 1 時因為過度不穩定而導致無法收斂
- 練習操作
- 練習 7:切換啟動函數
- 練習操作
- 資料集切換 : 分類資料集(右下) - 螺旋雙臂,特徵全選,隱藏層1層 / 8神經元,批次大小固定 10,學習速率固定 1
- 調整不同的啟動函數後執行 500 次遞迴,看看學習效果有何不同?
- 實驗結果
- 在這種極端的情形下,Tanh 會無法收斂,Relu 很快就穩定在很糟糕的分類狀狀態,惟有 Sigmoid 還可以收斂到不錯的結果
- 但實務上,Sigmoid 需要大量計算時間,而Relu 則相對快得很多,這也是需要取捨的,在本例中因為只有一層,所以狀況不太明顯
- 練習操作
- 練習 8:切換正規化選項與參數
- 練習操作
- 資料集切換 : 分類資料集(右下) - 螺旋雙臂,特徵全選,隱藏層1層 / 8神經元,批次大小固定 10,學習速率固定 0.3,啟動函數設為 Tanh
- 調整不同的正規化選項與參數後執行 500 次遞迴,看看學習效果有何不同?
- 實驗結果
- 我們已經知道上述設定本來就會收斂,只是在較小的 L1 / L2 正規劃參數下收斂比較穩定一點
- 但正規化參數只要略大,反而會讓本來能收斂的設定變得無法收斂,這點 L1 比 L2情況略略嚴重,因此本例例中最適合的正規化參數是 L2 + 參數 0.001
- 實務上:L1 / L2 較常使用在非深度學習上,深度學習上效果有限
- 練習操作
- 延伸閱讀 :
- 練習 5:切換批次大小
-
Day_66 : Keras 安裝與介紹
- Keras 是什麼?
-
易學易懂的深度學習套件
- Keras 設計出發點在於容易上手,因此隱藏了很多實作細節,雖然自由度稍嫌不夠,但很適合教學
- Keras 實作並優化了各式經典組件,因此即使是同時熟悉 TensorFlow 與 Keras 的老手,開發時也會兩者並用互補
-
Keras 包含的組件有哪些?
- Keras 的組件很貼近直覺,因此我們可以用 TensorFlow PlayGround 體驗所學到的概念,分為兩大類來理解 ( 非一一對應 )
- 模型形狀狀類
- 直覺概念:神經元數 / 隱藏層數 / 啟動函數
- Keras 組件 : Sequential Model / Functional Model / Layers
- 配置參數類
- 直覺概念:學習速率 / 批次大小 / 正規化
- Keras 組件 : Optimier / Reguliarizes / Callbacks
-
深度學習寫法封裝
- TensorFlow 將深度學習中的 GPU/CPU 指令封裝來來,減少語法差異,Keras 則是將前者更近一步封裝成單一套件,用少量的程式便能實現經典模型
-
Keras 的後端
- Keras 的實現,實際上完全依賴 TensorFlow 的語法完成,這種情形我們稱 TensorFlow 是 Keras 的一種後端 (Backend)
-
Keras/TensorFlow 的比較
Keras Tensorflow 學習難度 低 高 模型彈性 中 高 主要差異 處理神經層 處理資料流 代表組件 Layers/Model Tensor /
Session /
Placeholder
-
- Keras 安裝流程
-
安裝分歧點
- 是否有 GPU :
- 因為有 GPU 則需要先裝 GPU 的指令集,所以有 GPU 則需要 4 個步驟,沒有就只需要 2 步驟
- 作業系統 :
- 因為不同作業系統間,GPU 的安裝步驟會因介面或指令有所不同,所以我們會分 Windows / Linux (以Ubuntu為例) / Mac 分別介紹流程
- 是否有 GPU :
-
Keras 安裝注意事項
- 是否使用了 Anaconda 虛擬環境 :
- 如果您的 Python 環境是採用 Anaconda 安裝,那麼進行後續安裝時,請先切換到你常用的虛擬環境下安裝 (點選 Anaconda / Anaconda Prompt 後再安裝),以確保安裝與常用環境是同一目錄
- 軟硬體間版本搭配 :
- 由於 GPU 的 CUDA / cuDNN 版本經常升級,因此 TensorFlow / Keras 的版本也需要頻繁更換版本,因此建議以安裝當時的官網資訊為準
- 是否使用了 Anaconda 虛擬環境 :
-
安裝 Keras 大致上分為四個步驟 : 依序安裝 CUDA / cuDNN / TensorFlow / Keras,只要注意四個程式間的版本問題以及虛擬環境問題,基本上應該能順利安裝完成
-
- 安裝流程 - 沒有 GPU 版
- Step 1 - 安裝 TensorFlow
pip install tensorflow- Ubuntu 前面加上
sudo
- Ubuntu 前面加上
- Step 2 - 安裝 Keras
pip install keras- Python 找不到
pip指令,可以採用pip3代替執行安裝
- Python 找不到
- Step 1 - 安裝 TensorFlow
- 安裝流程 - 有 GPU 版
- Step 1 - 安裝 CUDA
- Step 2 - 安裝 cuDNN
- Step 3 - 安裝 TensorFlow GPU 版
pip install tensorflow-gpu - Step 4 - 安裝 Keras
pip install keras - Step 4-2 - 新增環境變數於 PATH
- (只有 Windows 需要, 其他作業系統請跳過) 如果是 Win10,可從開始 / 控制台 / 系統開啟視窗後,點選"進階"分頁最下面的按鈕"環境變數",會跳出下列列視窗,請在下半視窗中尋找"Path"變數,把下列列兩個路徑加入
項目間要用分號
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\bin C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\libnvvp;隔開 / CUDA 版號請依 Step1 實際安裝版本為準
- (只有 Windows 需要, 其他作業系統請跳過) 如果是 Win10,可從開始 / 控制台 / 系統開啟視窗後,點選"進階"分頁最下面的按鈕"環境變數",會跳出下列列視窗,請在下半視窗中尋找"Path"變數,把下列列兩個路徑加入
- 驗證安裝
- 安裝完後,可以開啟一個 .ipynb 檔輸入下列指令並執行,如果都有順利利執行,就是安裝成功了!!
import tensorflow import keras
- 安裝完後,可以開啟一個 .ipynb 檔輸入下列指令並執行,如果都有順利利執行,就是安裝成功了!!
- 延伸閱讀 : Keras 中文文檔
import keras from keras import backend as K # 檢查 backend keras.backend.backend() # 檢查 fuzz factor keras.backend.epsilon() # 檢查Keras float K.floatx() # 設定 Keras 浮點運算為float16 K.set_floatx('float16')
- Keras 是什麼?
-
Day_67 : Keras embedded dataset 的介紹與應用
- Keras 自帶的數據集 :
- CIFAR10 小圖像分類
- CIFAR100 小圖像分類
- IMDB 電影評論情緒分類
- 路透社 newswire 話題分類
- 手寫數字的 MNIST 數據庫
- 時尚文章的時尚 MNIST 數據庫
- 波士頓房屋價格回歸數據集
- 下載後預設存儲目錄
C:Users\Administrator\.keras\datasets下的同名檔,注意有個點.keras - 執行下載時,要 import 相應的模組,利用資料集模組提供的函數下載資料
- CIFAR10
- 小圖像分類
- 數據集 50,000 張 32x32 彩色訓練圖像,標註超過 10 個類別,10,000 張測試圖像。
'''Label description 0 : airplane 1 : automobile 2 : bird 3 : cat 4 : deer 5 : dog 6 : frog 7 : horse 8 : ship 9 : truck ''' from keras.datasets import cifar10 (x_train, y_train), (x_test, y_test) = cifar10.load_data()
- CIFAR100
- 小圖像分類
- 數據集 50,000 張 32x32 彩色訓練圖像,標註超過100個類別,10,000 張測試圖像。
from keras.datasets import cifar100 (x_train, y_train), (x_test, y_test) = cifar100.load_data(label_mode=‘fine’)
- MNIST 數據庫
- 手寫數字的 MNIST 數據庫
- 數據集包含 10 個數字的 60,000 個 28x28 灰度圖像,以及 10,000 個圖像的測試集。
from keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnsit.load_data()
- 時尚文章的時尚 MNIST 數據庫
- Zalando's article images
- 數據集包含 10 個時尚類別的 60,000 個 28x28 灰度圖像,以及 10,000 個圖像的測試集。這個數據集可以用作 MNIST 的直接替換。
'''Label description 0 : T-shirt / top 1 : Trouser 2 : Pullover 3 : Dress 4 : Coat 5 : Sandal 6 : Shirt 7 : Sneaker 8 : Bag 9 : Ankle boot ''' from keras.datasets import fashion_mnsit (x_train, y_train), (x_test, y_test) = fashion_mnsit.load_data()
- 波士頓房屋價格回歸
- 取自卡內基梅隆大學維護的 StatLib 庫
- 20 世紀 70 年代後期,樣本在波士頓郊區的不同位置包含 13 個房屋屬性。目標是一個地點房屋的中位值 (單位:k $)
from keras.datasets import boston_housing (x_train, y_train), (x_test, y_test) = boston_housing.load_data()
- IMDB 電影評論情緒分類
- 來自 IMDB 的 25,000 部電影評論的數據集,標有情緒 (正面 / 負面)。評論已經過預處理,每個評論都被編碼為一系列單詞索引 (整數)
- 單詞由數據集中的整體頻率索引
- 整數"3"編碼數據中第 3 個最頻繁的單詞。
- "0"不代表特定單詞,而是用於編碼任何未知單詞
''' path:如果您沒有本地數據(at'~/.keras/datasets/' + path),它將被下載到此位置。 num_words:整數或無。最常見的詞彙需要考慮。任何不太頻繁的單詞將 oov_char 在序列數據中顯示為值。 skip_top:整數。最常被忽略的詞(它們將 oov_char 在序列數據中顯示為值)。 maxlen:int。最大序列長度。任何更長的序列都將被截斷。 seed:int。用於可重複數據改組的種子。 start_char:int。序列的開頭將標有此字符。設置為 1,因為 0 通常是填充字符。 oov_char:int。這是因為切出字 num_words 或 skip_top 限制將這個字符替換。 index_from:int。使用此索引和更高的索引實際單詞。 ''' from keras.datasets import imdb (x_train, y_train), (x_test, y_test) = imdb.load_data(path=“imdb.npz”,num_words= None,skip_top=0,maxlen=None, seed=113,start_char=1,oov_char=2,index_from=3)
- 路透社新聞專題主題分類
- 來自路透社的 11,228 條新聞專線的數據集,標註了 46 個主題。與 IMDB 數據集一樣,每條線都被編碼為一系列字索引
from keras.datasets import reuters (x_train, y_train), (x_test, y_test) = reuters.load_data(path=“reuters npz”,num_words= None,skip_top=0,maxlen=None, test_split=0.2,seed=113,start_char=1,oov_char=2,index_from=3)
- 來自路透社的 11,228 條新聞專線的數據集,標註了 46 個主題。與 IMDB 數據集一樣,每條線都被編碼為一系列字索引
- 如何使用 Keras 自帶數據集做目標學習
- 適用於文本分析與情緒分類
- IMDB 電影評論情緒分類
- 路透社新聞專題主題分類
- 適用於影像分類與識別學習
- CIFAR10 / CIFAR100
- MNIST / Fashion-MNIST
- 適用於 Data / Numerical 學習
- Boston housing price regression dataset
- 針對小數據集的深度學習
- 數據預處理與數據提升
- 適用於文本分析與情緒分類
- 延伸閱讀 :
- Keras 自帶的數據集 :
-
Day_68 : 序列模型搭建網路 Sequential API
-
序列模型是多個網路層的線性堆疊
- Sequential 是一系列模型的簡單線性疊加,可以在構造函數中傳入一些列的網路層
from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential([Dense(32, _input_shap=(784,)), Activation(“relu”)]) - 也可以透過
.addmodel = Sequential() model.add(Dense(32, _input_dim=784)) model.add(Activation(“relu”))
- Sequential 是一系列模型的簡單線性疊加,可以在構造函數中傳入一些列的網路層
-
指定模型輸入維度
- Sequential 的第一層 (只有第一層,後面的層會自動匹配) 需要知道輸入的 shape
- 在第一層加入一個 input_shape 參數,input_shape 應該是一個 shape 的 tuple 資料類型
- input_shape 是一系列整數的 tuple,某些位置可以為 None
- input_shape 中不用指明 batch_size 的數目
- 2D 的網路層,如 Dense,允許在層的構造函數的 input_dim 中指定輸入的維度。
- 對於某些 3D 時間層,可以在構造函數中指定 input_dim 和 input_length 來實現。
- 對於某些 RNN,可以指定 batch_size。這樣後面的輸入必須是 (batch_size, input_shape) 的輸入
- Sequential 的第一層 (只有第一層,後面的層會自動匹配) 需要知道輸入的 shape
-
常用參數說明
名稱 作用 原型參數 Dense 實現全連接層 Dense(units,activation,use_bias=True,kernel_initializer='golorot_uniform',bias_initializer='zeros') Activation 對上層輸出應用激活函數 Activation(activation) Dropout 對上層輸出應用 dropout 以防止過擬合 Dropout(ratio) Flatten 對上層輸出一維化 Flatten() Reshape 對上層輸出 reshape Reshape(target_shape) -
Sequential 模型的基本元件一般需要 :
- Model 宣告
- model.add 添加層
- model.compile 配置學習過程參數
- model.fit 模型訓練參數設置+訓練
- 模型評估
- 模型預測
-
延伸閱讀 :
# 載入必須使用的 Library import keras from keras.datasets import cifar10 from keras.models import Sequential, load_model from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D batch_size = 32 num_classes = 10 epochs = 10 # The data, shuffled and split between train and test sets: (x_train, y_train), (x_test, y_test) = cifar10.load_data() print('x_train shape:', x_train.shape) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') # Convert class vectors to binary class matrices. y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) # build our CNN model, 多加幾層 model = Sequential() model.add(Conv2D(32, (5, 5), padding='same', input_shape=x_train.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(64, (5, 5))) model.add(Activation('relu')) model.add(Conv2D(128, (5, 5))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(1024)) model.add(Activation('relu')) model.add(Dropout(0.25)) model.add(Dense(num_classes)) model.add(Activation('softmax')) print(model.summary())
-
-
Day_69 : Keras Module API 的介紹與應用
-
函數式 API
- 用戶定義多輸出模型、非循環有向模型或具有共享層的模型等複雜模型的途徑
- 定義復雜模型(如多輸出模型、有向無環圖,或具有共享層的模型)的方法。
- 所有的模型都可調用,就像網絡層一樣
- 利用函數式 API,可以輕易地重用訓練好的模型:可以將任何模型看作是一個層,然後通過傳遞一個張量來調用它。注意,在調用模型時,您不僅重用模型的結構,還重用了它的權重。
-
函數式 API 與順序模型
- 模型需要多於一個的輸出,那麼你總應該選擇函數式模型。
- 函數式模型是最廣泛的一類模型,序貫模型(Sequential)只是它的一種特殊情況。
- 延伸說明
- 層對象接受張量為參數,返回一個張量。
- 輸入是張量,輸出也是張量的一個框架就是一個模型,通過 Model 定義。
- 這樣的模型可以被像 Keras 的 Sequential 一樣被訓練。
- 模型需要多於一個的輸出,那麼你總應該選擇函數式模型。
-
如何配置
- 使用函數式模型的一個典型場景是搭建多輸入、多輸出的模型
-
延伸閱讀 :
from keras.layers import Input, Embedding, LSTM, Dense from keras.models import Model #主要輸入接收新聞標題本身,即一個整數序列(每個整數編碼一個詞)。 #這些整數在1 到10,000 之間(10,000 個詞的詞彙表),且序列長度為100 個詞 #宣告一個 NAME 去定義Input main_input = Input(shape=(100,), dtype='int32', name='main_input') # Embedding 層將輸入序列編碼為一個稠密向量的序列, # 每個向量維度為 512。 x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input) # LSTM 層把向量序列轉換成單個向量, # 它包含整個序列的上下文信息 lstm_out = LSTM(32)(x) #插入輔助損失,使得即使在模型主損失很高的情況下,LSTM 層和Embedding 層都能被平穩地訓練 news_output = Dense(1, activation='sigmoid', name='news_out')(lstm_out) #輔助輸入數據與LSTM 層的輸出連接起來,輸入到模型 import keras news_input = Input(shape=(5,), name='news_in') x = keras.layers.concatenate([lstm_out, news_input]) # 堆疊多個全連接網路層 x = Dense(64, activation='relu')(x) x = Dense(64, activation='relu')(x) #作業解答: 新增兩層 x = Dense(64, activation='relu')(x) x = Dense(64, activation='relu')(x) # 最後添加主要的邏輯回歸層 main_output = Dense(1, activation='sigmoid', name='main_output')(x) # 宣告 MODEL API, 分別採用自行定義的 Input/Output Layer model = Model(inputs=[main_input, news_input], outputs=[main_output, news_output]) #輔助輸入數據與LSTM 層的輸出連接起來,輸入到模型 import keras news_input = Input(shape=(5,), name='news_in') x = keras.layers.concatenate([lstm_out, news_input]) # 堆疊多個全連接網路層 x = Dense(64, activation='relu')(x) x = Dense(64, activation='relu')(x) # 最後添加主要的邏輯回歸層 main_output = Dense(1, activation='sigmoid', name='main_output')(x) model.compile(optimizer='rmsprop', loss={'main_output': 'binary_crossentropy', 'news_out': 'binary_crossentropy'}, loss_weights={'main_output': 1., 'news_out': 0.2}) model.summary()
-
-
Day_70 : Multi-layer Perception 簡介
- Multi-layer Perceptron (MLP) 多層感知器 :
- 為一種監督式學習的演算法
- 此算法將可以使用非線性近似將資料分類或進行迴歸運算
- 多層感知機是一種前向傳遞類神經網路,至少包含三層結構 (輸入層、隱藏層和輸出層),並且利用到「倒傳遞」的技術達到學習 (model learning) 的監督式學習,以上是傳統的定義。
- 現在深度學習的發展,其實 MLP 是深度神經網路(deep neural network, DNN) 的一種 special case,概念基本上一樣,DNN 只是在學習過程中多了一些手法和層數會更多更深。
- 若每個神經元的激活函數都是線性函數,那麼任意層數的 MLP 都可被約簡成一個等價的單層感知器
- MLP 優點:
- 有能力建立非線性的模型
- 可以使用 partial_fit 建立 real-time 模型
- MLP 缺點 :
- 擁有大於一個區域最小值,使用不同的初始權重,會讓驗證時的準確率浮動
- MLP 模型需要調整每層神經元數、層數、疊代次數
- 對於特徵的預先處理很敏感
from keras.utils import np_utils import numpy as np #載入手寫辨識的資料集 from keras.datasets import mnist (x_train_image,y_train_label),\ (x_test_image,y_test_label)= mnist.load_data() #指定測試集與訓練資料集 x_Train =x_train_image.reshape(60000, 784).astype('float32') x_Test = x_test_image.reshape(10000, 784).astype('float32') # normalize inputs from 0-255 to 0-1 x_Train_normalize = x_Train / 255 x_Test_normalize = x_Test / 255 #把LABEL轉成NUMERICAL Categorical y_Train_OneHot = np_utils.to_categorical(y_train_label) y_Test_OneHot = np_utils.to_categorical(y_test_label) #建立模型 from keras.models import Sequential from keras.layers import Dense #宣告採用序列模型 model = Sequential() #建構輸入層 model.add(Dense(units=256, input_dim=784, kernel_initializer='normal', activation='relu')) #建構輸出層 model.add(Dense(units=10, kernel_initializer='normal', activation='softmax')) print(model.summary()) #模型訓練 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) train_history = model.fit(x=x_Train_normalize, y=y_Train_OneHot,validation_split=0.2, epochs=10, batch_size=32,verbose=1) #以圖形顯示訓練過程 import matplotlib.pyplot as plt def show_train_history(train_history,train,validation): plt.plot(train_history.history[train]) plt.plot(train_history.history[validation]) plt.title('Train History') plt.ylabel(train) plt.xlabel('Epoch') plt.legend(['train', 'validation'], loc='upper left') plt.show() show_train_history(train_history,'accuracy','val_accuracy') show_train_history(train_history,'loss','val_loss') #評估模型準確率 scores = model.evaluate(x_Test_normalize, y_Test_OneHot) print('accuracy=',scores[1])
- Multi-layer Perceptron (MLP) 多層感知器 :
-
Day_71 : 損失函數的介紹與應用
- 損失函數
- 機器學習中所有的算法都需要最大化或最小化一個函數,這個函數被稱為「目標函數」。其中,我們一般把最小化的一類函數,稱為「損失函數」。它能根據預測結果,衡量出模型預測能力的好壞
- 損失函數大致可分為:分類問題的損失函數和回歸問題的損失函數
- 損失函數為什麼是最小化
- 期望:希望模型預測出來的東西可以跟實際的值一樣
- 損失函數中的損失就是「實際值和預測值的落差」
- 預測出來的東西基本上跟實際值都會有落差
- 在回歸問題稱為「殘差 (residual)」
- 在分類問題稱為「錯誤率 (error rate)」
-
$y$ 表示實際值,$\hat{y}$ 表示預測值 $$ loss/residual = y - \hat{y}$$ $$ error_rate = \frac{\sum_{i=1}^n sign(y_i\neq \hat{y_i})}{n}$$
- 損失函數的分類介紹
-
均方誤差 (mean_squared_error):
- 就是最小平方法 (Least Square) 的目標函數 -- 預測值與實際值的差距之平均值。還有其他變形的函數, 如 mean_absolute_error、mean_absolute_percentage_error、mean_squared_logarithmic_error $$ MSE = \frac{\sum{(\hat{y}-y)^2}}{N} $$
- 使用時機:
- n 個樣本的預測值($y$)與($\hat{y}$)的差距
- Numerical 相關
from keras import losses model.compile(loss= 'mean_squared_error', optimizer='sgd') #其中,包含 y_true, y_pred 的傳遞,函數是表達如下: keras.losses.mean_squared_error(y_true, y_pred) -
Cross Entropy
- 當預測值與實際值愈相近,損失函數就愈小,反之差距很大,就會更影響損失函數的值
- 要用 Cross Entropy 取代 MSE,因為在梯度下時,Cross Entropy 計算速度較快
- 使用時機:
- 整數目標:Sparse categorical_crossentropy
- 分類目標:categorical_crossentropy
- 二分類目標:binary_crossentropy
from keras import losses model.compile(loss= ‘categorical_crossentropy ‘, optimizer='sgd’) #其中, 包含y_true, y_pred的傳遞, 函數是表達如下: keras.losses.categorical_crossentropy(y_true, y_pred) -
Hinge Error (hinge)
- 是一種單邊誤差,不考慮負值同樣也有多種變形,squared_hinge、categorical_hinge $$ l(y) = max(0,1-t.y)$$
- 使用時機:
- 適用於『支援向量機』(SVM) 的最大間隔分類法 (maximum-margin classification)
from keras import losses model.compile(loss= ‘hinge‘, optimizer='sgd’) #其中,包含 y_true,y_pred 的傳遞, 函數是表達如下 keras.losses.hinge(y_true, y_pred) -
自定義損失函數
- 根據問題的實際情況,定制合理的損失函數
- 舉例:預測果汁日銷量問題,如果預測銷量大於實際銷量量則會損失成本;如果預測銷量小於實際銷量則會損失利潤。
- 考慮重點:製造一盒果汁的成本和銷售一盒果汁的利潤不是等價的
- 需要使用符合該問題的自定義損失函數自定義損失函數為
- 若預測結果
$y$ 小於標準答案$\hat{y}$ ,損失函數為利潤乘以預測結果$y$ 與標準答案之差 - 若預測結果
$y$ 大於標準答案$\hat{y}$ ,損失函數為成本乘以預測結果 y 與標準答案之差用
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), COST*(y-y_), PROFIT*(y_-y))) - 若預測結果
-
均方誤差 (mean_squared_error):
- 延伸閱讀 :
- 損失函數
-
Day_72 : 啟動函數的介紹與應用
- 何謂啟動函數
- 啟動函數定義了每個節點(神經元)的輸出和輸入的關係的函數,為神經元提供規模化非線性能力,讓神經網路具備了強大的擬合能力
- 輸出值的範圍 :
- 當輸出值範圍是有限的時候,基於梯度的優化方法會更加穩定,因為特徵的表現受有限的權值的影響更為顯著
- 當輸出值範圍是無限的時候,模型的訓練會更加高效
- 啟動函數的作用
- 深度學習的基本原理是基於人工神經網路,信號從一個神經元進入,經過非線性的 activation function,如此循環往復直到輸出層,正是由於這些非線性函數的反覆疊加,層使得神經往復有足夠的能力來抓取複雜的 pattern
- 啟動函數的最大作用就是非線性化
- 如果不用啟動函數,無論神經網路有多少層,輸出都是輸入的線性組合
- 啟動函數的另一個特徵是
- 他應該可以區分前行網路和反向式傳播網路的網路參數更新,然後相應的使用梯度下降或其他優化技術優化權重以減少誤差
- 常用的啟動函數介紹
-
Sigmoid
$$ f(z) = \frac{1}{1+exp(-z)} $$
- 特點是會把輸出限在 0~1 之間,當 x < 0,輸出就是 0,當 x > 0,輸出就是 1,這樣使得輸出在傳遞過程中不容易發散
- 兩個主要缺點
- 容易過飽和,丟失梯度。這樣在反向傳播時,很容易出現梯度消失的情況,導致訓練無法完整
- 輸出均值不是 0
-
Softmax
$$ \sigma(z)j = \frac{e^{z_j}}{\sum{k=1}^Ke^{z_k}} $$
- 把一個 k 維的 real value 向量 (a1, a2, a3, ...) 映射成一個 (b1, b2, b3, ...) 其中 bi 是一個 0~1 的常數,輸出神經元之和為 1.0,所以可以拿來做多分類預測
- 為什麼要取指數
- 模擬 max 行為,要讓大者更大
- 需要一個可導函數
-
Tanh
$$ tanh(x) = 2\sigma(2x) - 1$$
$$tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$$ - Tanh 讀做 Hyperbolic tangent
- 稱為雙正切函數,取值範圍 [-1, 1]
- 在特徵相差明顯時的效果很好,在循環過程中不斷擴大特徵效果
-
ReLU
$$ f(x) = max(0, x)$$
- 修正線性單元 (Rectified linear unit)
- 在 x > 0,導數恆為 1
- 在 x < 0,梯度恆為 0,這時候他也會出現飽和現象,甚至使神經元直接無效,從而齊權重無法得到更新 (這種情況下通常稱為 dying ReLU)
- Leak ReLU 和 PReLU 的提出正是為了解決這一問題
-
ELU
$$ f(x))= \begin{cases} x & \text {, if
$x > 0$ } \ a(e^x-1) & \text{, if$x \leq 0$ } \end{cases} $$- ELU 是針對 ReLU 的一個改進型,相比於 ReLU 函數,在輸入為負的情況下,是有一定的輸出的
- 這樣可以消除 ReLU 死掉的問題
- 還是有梯度飽和和指數運算的問題
-
PReLU
$$ f(x) = max(ax, x)$$
- 參數化修正線性單元 (Parameteric Rectified linear unit)
- Leaky ReLU,當
$a = 0.1$ 時,我們叫 PReLU 為 Leaky ReLU - PReLU 和 Leaky ReLU 有一些共點,即為負值輸入添加了一個線性項
-
Maxout
$$ f(x) = max(w^T_1x + b_1, w^T_2x + b_2)$$
- Maxout 是深度學習網路中的一層網路,就像池化層、卷積層依樣,可以看成是網路的啟動層
- Maxout 神經元的啟動函數是取得所有「函數層」中的最大值
- 擬合力非常強,優點是簡單設計,不會過飽和,同時又沒有 ReLU 的缺點
- 缺點是過程參數相當於多了一倍
-
Sigmoid
$$ f(z) = \frac{1}{1+exp(-z)} $$
- Sigmoid vs. Tanh
- Tanh 將輸出值壓縮到了 [-1, 1] 範圍,因此他是 0 均值的,解決了 Sigmoid 函數非 zero-centered 問題,但是他也存在梯度消失和冪運算的問題
- 其實 Tanh(x) = 2 * Sigmoid(2x) - 1
- Sigmoid vs. Softmax
- Sigmoid 將一個 real value 映射到 (0, 1) 的區間,用來做二分類
- 把一個 k 維的 real value 向量 (a1, a2, a3, ...) 映射成一個 (b1, b2, b3, ...) 其中 bi 是一個 0~1 的常數,輸出神經元之和為 1.0,所以可以拿來做多分類預測
- 二分類問題時 Sigmoid 和 Softmax 是一樣的,求的都是 cross entropy loss
- 梯度消失 (Vanishing gradient problem)
- 原因 : 前面的層比後面的層梯度變化更小,故變化更慢
- 結果 : Output 變化慢 -> Gradient 變化小 -> 學得慢
- Sigmoid 和 Tanh 都有這樣特性,不適合用在 layers 多的 DNN 架構
- 如何選擇正確的啟動函數
- 根據各函數的的優缺點來配置
- 如果使用 ReLU,要小心 learning rate,注意不要讓網路出現很多「dead」神經元,如果不好解決,可以試試 Leaky ReLU、PReLU、Maxout
- 根據問題的性質
- 用於分類器,Sigmoid 函數及其組合通常效果更好
- 由於梯地消失問題,有時要避免使用 Sigmoid 和 Tanh 函數。ReLU 函數是一個通用的啟動函數,目前的大多情況下使用
- 如果神經網路中出現死的神經元,那麼 PReLU 函數就是最好的選擇
- ReLU 函數只建議用在隱藏層
- 考慮 DNN 損失函數和啟動函數
- 如果使用 Sigmoid 啟動函數,則交叉熵損失函數肯定比均方差損失函數的好
- 如果是 DNN 用於分類,擇一般在輸出層使用 Softmax 啟動函數
- ReLU 啟動函數對梯度消失問題有一定層度的解決,尤其是在 CNN 模型中
- 根據各函數的的優缺點來配置
- 延伸閱讀 :
import numpy as np #sigmoid 數學函數表示方式 def sigmoid(x): return (1 / (1 + np.exp(-x))) #Sigmoid 微分 def dsigmoid(x): return (x * (1 - x)) #Softmax 數學函數表示方式 def softmax(x): return np.exp(x) / float(sum(np.exp(x))) #tanh 數學函數表示方式 def tanh(x): return(np.exp(x) - np.exp(-x))/(np.exp(x) + np.exp(-x)) #tanh 微分 def dtanh(x): return 1 - np.square(x) #ReLU 數學函數表示方式 def ReLU(x): return abs(x) * (x > 0) #ReLU 微分 def dReLU(x): return (1 * (x > 0))
- 何謂啟動函數
-
Day_73 : 梯度下降 Gradient Descent 簡介
- 機器學習算法當中,優化算法的功能,是通過改善訓練方式,來最小化 (或最大化) 損失函數
- 最常用的優化算法是梯度下降
- 通過尋找最小值,控制方差,更新模型參數,最終使模型收斂
$w_{i+1} = w_i - d_i·η_i , i=0,1,...$ - 參數
$η$ 是學習率。這個參數既可以設置為固定值,也可以用一維優化方法沿著訓練的方向逐步更新計算 - 參數的更新分為兩步:第一步計算梯度下降的方向,第二步計算合適的學習
- 學習率對梯度下降的影響
- 學習率定義了每次疊代中應該更改的參數量。換句話說,它控制我們應該收斂到最低的速度。小學習率可以使迭代收斂,大學習率可能超過最小值 $$ compute : \frac{\partial{L}}{\partial{w}} $$ $$ w \leftarrow w - \eta\frac{\partial{L}}{\partial{w}} $$
- 梯度下降法的過程
- 首先需要設定一個初始參數值,通常情況下將初值設為零 (w=0),接下來需要計算成本函數 cost
- 然後計算函數的導數 (某個點處的斜率值),並設定學習效率參數 (lr) 的值。
- 重複執行上述過程,直到參數值收斂,這樣我們就能獲得函數的最優解
- 怎麼確定到極值點了呢?
-
$η$ 又稱學習率,是一個挪動步長的基數,$\frac{df(x)}{dx}$ 是導函數,當離得遠的時候導數大,移動的就快,當接近極值時,導數非常小,移動的就非常小,防止跨過極值點 - Gradient descent never guarantee global minima
- Different initial point will be caused reach different minima, so different results
- avoid local minima
-
在訓練神經網絡的時候,通常在訓練剛開始的時候使用較大的 learning rate,隨著訓練的進行,我們會慢慢的減小 learning rate,具體就是每次迭代的時候減少學習率的大小,更新公式: decayed_learning_rate=learning_rate* decay_rate^(global_step/decay_steps)
參數 意義 decayed_learning_rate 衰減後的學習率 learning_rate 初始學習率 decay_rate 衰減率 global_step 當前的 step decay_steps 衰減週期
-
- 使用 momentum,是梯度下降法中一種常用的加速技術。
- Gradient Descent 的實現:SGD, 對於一般的SGD,其表達式為
$x ← x\ −\ \alpha\ ∗\ dx$ (x沿負梯度⽅方向下降) 而帶 momentum 項的 SGD 則寫成如下形式:$v\ = \beta\ ∗\ v\ −\ \alpha\ ∗\ dx$ $x\ ←\ x\ +\ v$ - 其中
$\beta$ 即 momentum 係數,通俗的理解上面式⼦子就是,如果上一次的 momentum(即$\beta$ )與這一次的負梯度方向是相同的,那這次下降的幅度就會加大,所以這樣做能夠達到加速收斂的過程
- Gradient Descent 的實現:SGD, 對於一般的SGD,其表達式為
-
- 梯度下降法的缺點包括:
- 靠近極小值時速度減慢。
- 直線搜索可能會產生一些問題。
- 可能會「之字型」地下降
- 延伸閱讀 :
- learning rate decay
- 機器/深度學習 - 基礎數學 : 梯度下降
- 各種衰減方法
- exponential_decay : 指數衰減
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps) - natural_exp_decay : 自然指數衰減
decayed_learning_rate = learning_rate * exp(-decay_rate * global_step) - inverse_time_decay : 逆時間衰減
decayed_learning_rate = learning_rate / (1 + decay_rate * global_step / decay_step) - polynomial_decay : 多項式衰減
global_step = min(global_step, decay_steps)decayed_learning_rate = (learning_rate - end_learning_rate) *(1 - global_step / decay_steps) ^ (power) + end_learning_rate
- exponential_decay : 指數衰減
import numpy as np import matplotlib.pyplot as plt %matplotlib inline # 目標函數:y=(x+3)^2 def func(x): return np.square(x+3) # 目標函數一階導數:dy/dx=2*(x+3) def dfunc(x): return 2 * (x+3) def GD(w_init, df, epochs, lr): """ 梯度下降法。給定起始點與目標函數的一階導函數,求在epochs次反覆運算中x的更新值 :param w_init: w的init value :param df: 目標函數的一階導函數 :param epochs: 反覆運算週期 :param lr: 學習率 :return: x在每次反覆運算後的位置 """ xs = np.zeros(epochs+1) # 把 "epochs+1" 轉成dtype=np.float32 x = w_init xs[0] = x for i in range(epochs): dx = df(x) # v表示x要跨出的幅度 v = - dx * lr x += v xs[i+1] = x return xs # 起始權重 w_init = 3 # 執行週期數 epochs = 20 # 學習率 #lr = 0.3 lr = 0.01 # 梯度下降法 x = GD(w_init, dfunc, epochs, lr=lr) print (x) #劃出曲線圖 color = 'r' from numpy import arange t = arange(-6.0, 6.0, 0.01) plt.plot(t, func(t), c='b') plt.plot(x, func(x), c=color, label='lr={}'.format(lr)) plt.scatter(x, func(x), c=color, ) plt.legend() plt.show()
-
Day_74 : Gradient Descent 數學原理
- Gradient 梯度
- 在微積分裡面,對多元函數的參數求 ∂ 偏導數,把求得的各個參數的偏導數以向量的形式寫出來,就是梯度。
- 比如函數 f(x), 對 x 求偏導數,求得的梯度向量就是 (∂f/∂x),簡稱 grad f(x)或者▽f (x)
- 最常用的優化算法 - 梯度下降
- 目的:沿著目標函數梯度下降的方向搜索極小值 (也可以沿著梯度上升的方向搜索極大值)
- 要計算 Gradient Descent,考慮
- Loss = (實際) ydata – (預測) ydata = w * (實際) xdata – w * (預測) xdata (bias 為 init value,被消除)
- Gradient = ▽f (θ) (Gradient = ∂L/∂w)
- 調整後的權重 = 原權重 – η(Learning rate) * Gradient $$ w \leftarrow w - \eta\frac{\partial{L}}{\partial{w}}$$
- 梯度下降的算法調優
- Learning rate 選擇,實際上取值取決於數據樣本,如果損失函數在變小,說明取值有效,否則要增大 Learning rate
- 自動更新 Learning rate - 衰減因子 decay
- 算法參數的初始值選擇。初始值不同,獲得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;當然如果損失函數是凸函數則一定是最優解。
- 學習率衰減公式
- lr_i = lr_start * 1.0 / (1.0 + decay * i)
- 其中 lr_i 為第一迭代 i 時的學習率,lr_start 為初始值,decay 為一個介於[0.0, 1.0]的小數。從公式上可看出:
- decay 越小,學習率衰減地越慢,當 decay = 0 時,學習率保持不變
- decay 越大,學習率衰減地越快,當 decay = 1 時,學習率衰減最快
- 使用 momentum 是梯度下降法中一種常用的加速技術。
$x ← x\ −\ \alpha\ ∗\ dx$ (x沿負梯度方向下降)$v\ = \beta\ ∗\ v\ −\ \alpha\ ∗\ dx$ $x\ ←\ x\ +\ v$ - 其中
$\beta$ 即 momentum 係數,通俗的理解上面式子就是,如果上一次的 momentum(即$\beta$ )與這一次的負梯度方向是相同的,那這次下降的幅度就會加大,所以這樣做能夠達到加速收斂的過程
- 延伸閱讀 :
import matplotlib import matplotlib.pyplot as plt %matplotlib inline #適用於 Jupyter Notebook, 宣告直接在cell 內印出執行結果 import random as random import numpy as np import csv # 給定初始的data x_data = [ 338., 333., 328., 207., 226., 25., 179., 60., 208., 606.] y_data = [ 640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.] #給定神經網路參數:bias 跟weight x = np.arange(-200,-100,1) #給定bias y = np.arange(-5,5,0.1) #給定weight Z = np.zeros((len(x), len(y))) #meshgrid返回的兩個矩陣X、Y必定是 column 數、row 數相等的,且X、Y的 column 數都等 #meshgrid函數用兩個坐標軸上的點在平面上畫格。 X, Y = np.meshgrid(x, y) for i in range(len(x)): for j in range(len(y)): b = x[i] w = y[j] Z[j][i] = 0 for n in range(len(x_data)): Z[j][i] = Z[j][i] + (y_data[n] - b - w*x_data[n])**2 Z[j][i] = Z[j][i]/len(x_data) # ydata = b + w * xdata b = -120 # initial b w = -4 # initial w lr = 0.000001 # learning rate iteration = 100000 # Store initial values for plotting. b_history = [b] w_history = [w] #給定初始值 lr_b = 0.0 lr_w = 0.0 ''' Loss = (實際ydata – 預測ydata) Gradient = -2*input * Loss 調整後的權重 = 原權重 – Learning * Gradient ''' # Iterations for i in range(iteration): b_grad = 0.0 w_grad = 0.0 for n in range(len(x_data)): b_grad = b_grad - 2.0*(y_data[n] - b - w*x_data[n])*1.0 w_grad = w_grad - 2.0*(y_data[n] - b - w*x_data[n])*x_data[n] lr_b = lr_b + b_grad ** 2 lr_w = lr_w + w_grad ** 2 # Update parameters. b = b - lr * b_grad w = w - lr * w_grad # Store parameters for plotting b_history.append(b) w_history.append(w) # plot the figure plt.contourf(x,y,Z, 50, alpha=0.5, cmap=plt.get_cmap('jet')) plt.plot([-188.4], [2.67], 'x', ms=12, markeredgewidth=3, color='orange') plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black') plt.xlim(-200,-100) plt.ylim(-5,5) plt.xlabel(r'$b$', fontsize=16) plt.ylabel(r'$w$', fontsize=16) plt.show()
- Gradient 梯度
-
Day_75 : 反向式傳播簡介
- 何謂反向傳播
- 反向傳播(BP:Backpropagation)是「誤差反向傳播」的簡稱,是一種與最優化方法(如梯度下降法)結合使用的該方法對網路中所有權重計算損失函數的梯度。這個梯度會反饋給最優化方法,用來更新權值以最小化損失函數。
- 反向傳播要求有對每個輸入值想得到的已知輸出,來計算損失函數梯度。因此,它通常被認為是一種監督式學習方法,可以對每層疊代計算梯度。反向傳播要求人工神經元(或「節點」)的啟動函數可微。
- 推導流程 :
-
$\to$ 建立神經網路 (Input、Hidden、Output)
$\to$ 拆解神經網路為局部設計算單元$\to$ 給定計算單元$\to$ 神經網路初始化 (init value)$\to$ Forward Propagation$\to$ 取得 OUTPUT$\to$ 解函數微分$\to$ Back Propagation
-
- BP 神經網路是一種按照逆向傳播算法訓練的多層前饋神經網路
- 優點:具有任意複雜的模式分類能力和優良的多維函數映射能力,解決了簡單感知器不能解決的一些其他的問題。
- 從結構上講,BP 神經網路具有輸入層、隱含層和輸出層。
- 從本質上講,BP 算法就是以網路誤差平方目標函數、採用梯度下降法來計算目標函數的最小值。
- 缺點:
- ①學習速度慢,即使是一個簡單的過程,也需要幾百次甚至上千次的學習才能收斂。
- ②容易陷入局部極小值。
- ③網路層數、神經元個數的選擇沒有相應的理論指導。
- ④網路推廣能力有限。
- 應用:
- ①函數逼近。
- ②模式識別。
- ③分類。
- ④數據壓縮。
- 優點:具有任意複雜的模式分類能力和優良的多維函數映射能力,解決了簡單感知器不能解決的一些其他的問題。
- 重要知識點複習:
- 第1階段:解函數微分
- 每次疊代中的傳播環節包含兩步:
- (前向傳播階段)將訓練輸入送入網路以獲得啟動響應;
- (反向傳播階段)將啟動響應同訓練輸入對應的目標輸出求差,從而獲得輸出層和隱藏層的響應誤差。
- 每次疊代中的傳播環節包含兩步:
- 第2階段:權重更新
- Follow Gradient Descent
- 第 1 和第 2 階段可以反覆循環疊代,直到網路對輸入的響應達到滿意的預定的目標範圍為止。
- 第1階段:解函數微分
- 延伸閱讀 :
#定義並建立一神經網路 class mul_layer(): def _ini_(self): self.x = None self.y = None def forward(self, x, y): self.x = x self.y = y out = x*y return out def backward(self, dout): dx = dout * self.y dy = dout * self.x return dx, dy # 初始值設定 n_X = 2 price_Y = 100 b_TAX = 1.1 # 指定Build _Network組合 mul_fruit_layer = mul_layer() mul_tax_layer = mul_layer() #forward fruit_price = mul_fruit_layer.forward(price_Y, n_X) total_price = mul_tax_layer.forward(fruit_price, b_TAX) #backward dtotal_price = 1 #this is linear function, which y=x, dy/dx=1 d_fruit_price, d_b_TAX = mul_tax_layer.backward(dtotal_price) d_price_Y, d_n_X = mul_tax_layer.backward(d_fruit_price)
- 何謂反向傳播
-
Day_76 : 優化器 Optimizers 簡介
- 什麼是優化算法 - Optimizer
- 機器學習算法當中,大部分算法的本質就是建立優化模型,通過最優化方法對目標函數進行優化從而訓練出最好的模型
- 優化算法的功能,是通過改善訓練方式,來最小化 (或最大化) 損失函數 E(x)
- 優化策略和算法,是用來更新和計算影響模型訓練和模型輸出的網絡參數,使其逼近或達到最優值
- 最常用的優化算法
- Gradient Descent
- 最常用的優化算法是梯度下降
- 這種算法使用各參數的梯度值來最小化或最大化損失函數 E(x)。
- 通過尋找最小值,控制方差,更新模型參數,最終使模型收斂
- 動量 Momentum
- 「一顆球從山上滾下來,在下坡的時候速度越來越快,遇到上坡,方向改變,速度下降」 $$ V_t \leftarrow \beta V_{t-1} - \eta\frac{\partial{L}}{\partial{w}}$$ $$ w \leftarrow w + V_t $$
-
$v_t$ : 「方向速度」,會跟上一次的更新有關 - 如果上一次的梯度跟這次同方向的話,$|V_t|$ (速度)會越來來越大(代表梯度增強),$w$ 參數的更新梯度便會越來越快,如果方向不同,$|V_t|$ 便會比上次更小(梯度減弱),$w$ 參數的更新梯度便會變小
- 加入的這一項,可以使得梯度方向不變的維度上速度變快,梯度方向有所改變的維度上的更新速度變慢,這樣就可以加快收斂並減小震盪
- SGD - 隨機梯度下降法 (stochastic gradient decent)
- 找出參數的梯度 (利用微分的方法),往梯度的方向去更新參數 (weight) $$ w \leftarrow w -\eta \frac{\partial{L}}{\partial{w}}$$
-
$w$ 為權重 (weight) 參數,$L$ 為損失函數 (loss function),$\eta$ 是學習率 (learning rate),$\frac{\partial{L}}{\partial{w}}$ 是損失函數對參數的梯度 (微分) - 優點:SGD 每次更新時對每個樣本進行梯度更新,對於很大的數據集來說,可能會有相似的樣本,而 SGD 一次只進行一次更新,就沒有冗餘,而且比較快
- 缺點:但是 SGD 因為更新比較頻繁,會造成 cost function 有嚴重的震盪
- SGD 調用
-
keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False)- lr: 學習率。
- Momentum 動量: 參數,用於加速 SGD 在相關方向上前進,並抑制震盪。
- Decay (衰變): 每次參數更新後學習率衰減值。
- nesterov:布爾值。是否使用 Nesterov 動量。
from keras import optimizers model = Sequential() model.add(Dense(64, kernel_initializer='uniform', input_shape=(10,)))model.add(Activation('softmax’)) #實例化一個優化器對象,然後將它傳入model.compile(),可以修改參數 sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss='mean_squared_error', optimizer=sgd) # 通過名稱來調用優化器,將使用優化器的默認參數。 model.compile(loss='mean_squared_error', optimizer='sgd') -
- mini-batch gradient descent
- batch-gradient,其實就是普通的梯度下降算法但是採⽤用批量處理。
- 當數據集很大(比如有 100000 個左右時),每次 iteration 都要將 1000000 個數據跑一遍,機器帶不動。於是有了 mini-batch-gradient —— 將 1000000 個樣本分成 1000 份,每份 1000 個,都看成一組獨立的數據集,進行 forward_propagation 和 backward_propagation。
- 在整個算法的流程中,cost function 是局部的,但是 W 和 b 是全局的。
- 批量梯度下降對訓練集上每一個數據都計算誤差,但只在所有訓練數據計算完成後才更新模型。
- 對訓練集上的一次訓練過程稱為一代(epoch)。因此,批量梯度下降是在每一個訓練 epoch 之後更新模型。
- batchsize:批量大小,即每次訓練在訓練集中取batchsize 個樣本訓練;
- batchsize = 1;
- batchsize = mini-batch;
- batchsize = whole training set
- iteration:1 個 iteration 等於使用 batchsize 個樣本訓練一次;
- epoch:1 個 epoch 等於使用訓練集中的全部樣本訓練一次;
- Example:
features is (50000, 400) labels is (50000, 10) batch_size is 128 Iteration = 50000/128+1 = 391 - 怎麼配置 mini-batch 梯度下降
- Mini-batch sizes,簡稱為「batch sizes」,是算法設計中需要調節的參數。
- 較小的值讓學習過程收斂更快,但是產生更多噪聲。
- 較大的值讓學習過程收斂較慢,但是準確的估計誤差梯度。
- batch size 的默認值最好是 32 盡量選擇 2 的冪次⽅方,有利於 GPU 的加速。
- 調節 batch size 時,最好觀察模型在不同 batch size 下的訓練時間和驗證誤差的學習曲線。
- 調整其他所有超參數之後再調整 batch size 和學習率。
- batch-gradient,其實就是普通的梯度下降算法但是採⽤用批量處理。
- Adagrad
- 對於常見的數據給予比較小的學習率去調整參數,對於不常見的數據給予比較大的學習率調整參數
- 每個參數都有不同的 learning rate
- 根據之前所有 gradient 的 root mean square 修改
- 第 t 次更新
$$ g^t = \frac{\partial{L}}{\partial{\theta}}|_{\theta={\theta^t}}$$
- Gradient descent $$ \theta^{t+1} = \theta^t - \eta g^t$$
- Adagrad $$ \theta^{t+1} = \theta^t - \frac{\eta}{\sigma^t} g^t$$ $$ \sigma^t = \sqrt{\frac{(g^0)^2+...+(g^t)^2}{t+1}} $$
- 對於常見的數據給予比較小的學習率去調整參數,對於不常見的數據給予比較大的學習率調整參數
- Adagrad 調用
- 超參數設定值 :
keras.optimizers.Adagrad(lr=0.01, epsilon=None, decay=0.0)- lr:float >= 0. 學習率。一般
$\eta$ 就取 0.01 - epsilon: float >= 0。若為 None,默認為 K.epsilon()
- decay:float >= 0。每次參數更新後學習率衰減值
from keras import optimizers model = Sequential() model.add(Dense(64, kernel_initializer='uniform', input_shape=(10,))) model.add(Activation('softmax’)) #實例化一個優化器對象,然後將它傳入model.compile() , 可以修改參數 opt = optimizers.Adagrad(lr=0.01, epsilon=None, decay=0.0) model.compile(loss='mean_squared_error', optimizer=opt) - lr:float >= 0. 學習率。一般
- 超參數設定值 :
- RMSprop
- RMSProp 算法也旨在抑制梯度的鋸齒下降,但與動量相比, RMSProp 不需要手動配置學習率超參數,由算法自動完成。更重要的是,RMSProp 可以為每個參數選擇不同的學習率。
- RMSprop 是為了解決 Adagrad 學習率急劇下降問題的,所以比對梯度更新規則:
- Adagrad $$ \theta^{t+1} = \theta^t - \frac{\eta}{\sigma^t} g^t$$ $$ \sigma^t = \sqrt{\frac{(g^0)^2+...+(g^t)^2}{t+1}} $$ Root mean square (RMS) of all Gradient
- RMSprop $$ \theta^{t+1} = \theta^t - \frac{\eta}{\sqrt{r^t}} g^t$$ $$ r^t = (1 - p)(g^t)^2 + pr^{t-1}$$ 分母換成了過去的梯度平方的衰減平均值
- RMSprop 調用
keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0)- This optimizer is usually a good choice for recurrent neural networks.Arguments
- lr:float >= 0。Learning rate.
- rho:float >= 0。
- epsilon:float >= 0。Fuzz factor. If None, defaults to K.epsilon()。
- decay:float >= 0。 Learning rate decay over each update。
from keras import optimizers model = Sequential() model.add(Dense(64, kernel_initializer='uniform', input_shape=(10,))) model.add(Activation('softmax’)) #實例化一個優化器對象,然後將它傳入model.compile() , 可以修改參數 opt = optimizers.RMSprop(lr=0.001, epsilon=None, decay=0.0) model.compile(loss='mean_squared_error', optimizer=opt)
- This optimizer is usually a good choice for recurrent neural networks.Arguments
- Adam 說明
- 除了像 RMSprop 一樣存儲了過去梯度的平⽅方
$v_t$ 的指數衰減平均值,也像 momentum 一樣保持了過去梯度$m_t$ 的指數衰減平均值, 「 t 」:- the first moment (the mean) $$ m_t = \beta_1m_t + (1 - \beta_1)g_t$$
- the second moment (the uncentered variance) $$ v_t = \beta_2m_t + (1 - \beta_2){g_t}^2$$
- 計算梯度的指數移動平均數,$m_0$ 初始化為 0。綜合考慮之前時間步的梯度動量。
- β1 係數為指數衰減率,控制權重分配(動量與當前梯度),通常取接近於 1 的值。默認為 0.9
- 其次,計算梯度平方的指數移動平均數,$v_0$ 初始化為 0。
- β2 係數為指數衰減率,控制之前的梯度平⽅方的影響情況。類似於 RMSProp 算法,對梯度平方進行加權均值。默認為 0.999
- 由於
$m_0$ 初始化為 0,會導致$m_t$ 偏向於 0,尤其在訓練初期階段。所以,此處需要對梯度均值$m_t$ 進行偏差糾正,降低偏差對訓練初期的影響。與$m_0$ 類似,因為$v_0$ 初始化為 0 導致訓練初始階段$v_t$ 偏向 0,對其進行糾正。 $$ \hat{m_t} = \frac{m_t}{1 - {{\beta^t}_1}}$$ $$ \hat{v_t} = \frac{v_t}{1 - {{\beta^t}_2}}$$ - 更新參數,初始的學習率 lr 乘以梯度均值與梯度方差的平方根之比。其中默認學習率 lr =0.001, eplison (ε=10^-8),避免除數變為 0。
- 對更新的步長計算,能夠從梯度均值及梯度平方兩個角度進行自適應地調節,而不是直接由當前梯度決定
- 除了像 RMSprop 一樣存儲了過去梯度的平⽅方
- Adam 調用
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)- lr:float >= 0. 學習率。
- beta_1:float, 0 < beta < 1. 通常接近於 1。
- beta_2:float, 0 < beta < 1. 通常接近於 1。
- epsilon:float >= 0. 模糊因數. 若為None, 默認為 K.epsilon()。
- amsgrad:boolean. 是否應用此演算法的 AMSGrad 變種,來自論文「On the Convergence of Adam and Beyond」
- decay:float >= 0. 每次參數更新後學習率衰減值。
from keras import optimizers model = Sequential() model.add(Dense(64, kernel_initializer='uniform', input_shape=(10,))) model.add(Activation('softmax’)) #實例化一個優化器對象,然後將它傳入 model.compile() , 可以修改參數 opt = optimizers.Adam(lr=0.001, epsilon=None, decay=0.0) model.compile(loss='mean_squared_error', optimizer=opt)
- Gradient Descent
- 如何選擇優化器
- 隨機梯度下降(SGD):SGD 指的是 mini batch gradient descent 優點:針對大數據集,訓練速度很快。從訓練集樣本中隨機選取一個 batch 計算一次梯度,更新一次模型參數。
- 缺點:對所有參數使用相同的學習率。對於稀疏數據或特徵,希望盡快更新一些不經常出現的特徵,慢一些更新常出現的特徵。所以選擇合適的學習率比較困難。
- 容易收斂到局部最優 Adam:利用梯度的一階矩估計和二階矩估計動態調節每個參數的學習率。
- 優點:
- 經過偏置校正後,每一次迭代都有確定的範圍,使得參數比較平穩。善於處理稀疏梯度和非平穩目標。
- 對內存需求小
- 對不同內存計算不同的學習
- 優點:
- RMSProp:自適應調節學習率。對學習率進行了約束,適合處理非平穩目標和 RNN。
- 如果輸入數據集比較稀疏,SGD、NAG 和動量項等方法可能效果不好。因此對於稀疏數據集,應該使用某種自適應學習率的方法,且另一好處為不需要人為調整學習率,使用默認參數就可能獲得最優值。
- Adagrad, RMSprop, Adam。
- 如果想使訓練深層網絡模型快速收斂或所構建的神經網絡較為複雜,則應該使用 Adam 或其他自適應學習速率的方法,因為這些方法的實際效果更優。
- Adam 就是在 RMSprop 的基礎上加了 bias-correction 和 momentum,
- 隨著梯度變的稀疏,Adam 比 RMSprop 效果會好。
- 隨機梯度下降(SGD):SGD 指的是 mini batch gradient descent 優點:針對大數據集,訓練速度很快。從訓練集樣本中隨機選取一個 batch 計算一次梯度,更新一次模型參數。
- 延伸閱讀 :
- 什麼是優化算法 - Optimizer
-
Day_77 : 訓練神經網路的細節與技巧
- 什麼是 Overfitting
- 過度擬合 (overfitting) 代表
- 訓練集的損失下降的遠比驗證集的損失還來的快
- 驗證集的損失隨訓練時間增長,反而上升
- 如何檢視我的模型有沒有 overfitting
- 在 Keras 中,加入驗證集
# 訓練模型並檢視驗證集的結果 model.fit(x_train, y_train, epochs=100, batch_size=256, validation_data=(x_test, y_test), shuffle=True) # 將訓練集切分一部分當作驗證集 model.fit(x_train, y_train, epochs=100, batch_size=256, validation_split=0.2, shuffle=True)- 注意:使用 validation_split 與 shuffle 時,Keras 是先自 x_train/y_train 取最後 (1-x)% 做為驗證集使用,再行 shuffle。
- 在訓練完成後,將 training loss 與 validation loss 取出並繪圖
# 以視覺畫方式檢視訓練過程 import matplotlib.pyplot as plt train_loss = model.history.history["loss"] valid_loss = model.history.history["val_loss"] train_acc = model.history.history["accuracy"] valid_acc = model.history.history["val_accuracy"] plt.plot(range(len(train_loss)), train_loss, label="train loss") plt.plot(range(len(valid_loss)), valid_loss, label="valid loss") plt.legend() plt.title("Loss") plt.show() plt.plot(range(len(train_acc)), train_acc, label="train accuracy") plt.plot(range(len(valid_acc)), valid_acc, label="valid accuracy") plt.legend() plt.title("Accuracy") plt.show()
- 過度擬合 (overfitting) 代表
- 延伸閱讀 :
- 什麼是 Overfitting
-
Day_78 : 訓練神經網路前的注意事項
- 訓練模型前的檢查
- 為何要做事前檢查
- 訓練模型的時間跟成本都很大 (如 GPU quota & 你/妳的人生)
- 要做哪些檢查:
- 使用的裝置:是使用 CPU or GPU / 想要使用的 GPU 是否已經被別人佔用?
- nvidia-smi 可以看到目前可以取得的GPU 裝置使用狀態
- Input preprocessing:資料 (Xs) 是否有進行過適當的標準化?
- Output preprocessing:目標 (Ys) 是否經過適當的處理? (如 onehot-encoded)
- 透過 Function 進行處理,而非在 Cell 中單獨進行避免遺漏、錯置
- Model Graph:模型的架構是否如預期所想?
- model.summary() 可以看到模型堆疊的架構
- 超參數設定(Hyper-parameters):訓練模型的相關參數是否設定得當?
- 將模型/程式所使用到的相關參數集中管理,避免散落在各處
- 使用的裝置:是使用 CPU or GPU / 想要使用的 GPU 是否已經被別人佔用?
- 為何要做事前檢查
- 延伸閱讀 :
-
Troubleshooting Deep Neural Networks
- 檢查程式碼
- 養成好的程式撰寫習慣(PEP8)
- 確認參數設定欲實作的模型是否合適當前的資料
- 確認資料結構資料是否足夠
- 是否乾淨
- 是否有適當的前處理
- 以簡單的⽅方式實現想法建立評估機制開始循環測試 (evaluate - tuning - debugging)
-
Troubleshooting Deep Neural Networks
- 訓練模型前的檢查
-
Day_79 : 訓練神經網路的細節與技巧 - Learning Rate Effect
- 如果 Learning rate (LR, alpha) 太大,將會導致每步更新時,無法在陡峭的損失山谷中,順利的往下滑動;但若太小,則要滑到谷底的時間過於冗長,且若遇到平原區則無法找到正確的方向。
- Options in SGD optimizer
- Momentum:動量 – 在更新方向以外,加上一個固定向量,使得真實移動方向會介於算出來的 gradient step 與 momentum 間。
- Actual step = momentum step + gradient step
- Nesterov Momentum:拔草測風向
- 將 momentum 納入 gradient 的計算
- Gradient step computation is based on x + momentum
- Momentum:動量 – 在更新方向以外,加上一個固定向量,使得真實移動方向會介於算出來的 gradient step 與 momentum 間。
- 重要知識點複習
- 學習率對訓練造成的影響
- 學習率過大:每次模型參數改變過大,無法有效收斂到更低的損失平面
- 學習率過小:每次參數的改變量小,導致
- 損失改變的幅度小
- 平原區域無法找到正確的方向在
- SGD 中的動量方法•
- 在損失方向上,加上一定比率的動量協助擺脫平原或是小山谷
- 學習率對訓練造成的影響
- 延伸閱讀 :
-
Day_80 : 優化器與學習率的組合與比較
- </>
import os import keras import itertools # 從 Keras 的內建功能中,取得 train 與 test 資料集 train, test = keras.datasets.cifar10.load_data() ## 資料前處理 def preproc_x(x, flatten=True): x = x / 255. if flatten: x = x.reshape((len(x), -1)) return x def preproc_y(y, num_classes=10): if y.shape[-1] == 1: y = keras.utils.to_categorical(y, num_classes) return y x_train, y_train = train x_test, y_test = test # 資料前處理 - X 標準化 x_train = preproc_x(x_train) x_test = preproc_x(x_test) # 資料前處理 -Y 轉成 onehot y_train = preproc_y(y_train) y_test = preproc_y(y_test) """ 建立神經網路 """ def build_mlp(input_shape, output_units=10, num_neurons=[512, 256, 128]): input_layer = keras.layers.Input(input_shape) for i, n_units in enumerate(num_neurons): if i == 0: x = keras.layers.Dense(units=n_units, activation="relu", name="hidden_layer"+str(i+1))(input_layer) else: x = keras.layers.Dense(units=n_units, activation="relu", name="hidden_layer"+str(i+1))(x) out = keras.layers.Dense(units=output_units, activation="softmax", name="output")(x) model = keras.models.Model(inputs=[input_layer], outputs=[out]) return model ## 超參數設定 LEARNING_RATE = [1e-1, 1e-2, 1e-3, 1e-4, 1e-5] EPOCHS = 50 BATCH_SIZE = 256 OPTIMIZER = [keras.optimizers.SGD, keras.optimizers.RMSprop, keras.optimizers.Adagrad, keras.optimizers.Adam] results = {} for lr, opti in itertools.product(LEARNING_RATE, OPTIMIZER): keras.backend.clear_session() # 把舊的 Graph 清掉 print("Experiment with LR = %.6f, Optimizer = %s" % (lr, str(opti))) model = build_mlp(input_shape=x_train.shape[1:]) model.summary() optimizer = opti(lr=lr) model.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer=optimizer) model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), shuffle=True) # Collect results train_loss = model.history.history["loss"] valid_loss = model.history.history["val_loss"] train_acc = model.history.history["accuracy"] valid_acc = model.history.history["val_accuracy"] exp_name_tag = "exp-lr-%s-optimizer-%s" % (str(lr), str(opti)) results[exp_name_tag] = {'train-loss': train_loss, 'valid-loss': valid_loss, 'train-acc': train_acc, 'valid-acc': valid_acc} """ Plot results """ import matplotlib.pyplot as plt %matplotlib inline NUM_COLORS = len(results.keys()) cm = plt.get_cmap('gist_rainbow') color_bar = [cm(1.*i/NUM_COLORS) for i in range(NUM_COLORS)] plt.figure(figsize=(8,6)) for i, cond in enumerate(results.keys()): plt.plot(range(len(results[cond]['train-loss'])),results[cond]['train-loss'], '-', label=cond, color=color_bar[i]) plt.plot(range(len(results[cond]['valid-loss'])),results[cond]['valid-loss'], '--', label=cond, color=color_bar[i]) plt.title("Loss") plt.legend(loc='center left', bbox_to_anchor=(1, 0.5)) plt.show() plt.figure(figsize=(8,6)) for i, cond in enumerate(results.keys()): plt.plot(range(len(results[cond]['train-acc'])),results[cond]['train-acc'], '-', label=cond, color=color_bar[i]) plt.plot(range(len(results[cond]['valid-acc'])),results[cond]['valid-acc'], '--', label=cond, color=color_bar[i]) plt.title("Accuracy") plt.legend(loc='center left', bbox_to_anchor=(1, 0.5)) plt.show() - 延伸閱讀 :
-
优化方法总结
- SGD (mini-batch)
- 在單步更新與全局更新的折衷辦法,通常搭配 momentum 穩定收斂方向與結果。
- 收斂速度較慢。
- RMSprop
- 學習率的調整是根據過去梯度的狀況調整,收斂速度快又不易會出現 learning rate 快速下降的狀況。
- Adam
- 同樣是可以根據過去的梯度自行調整 learning rate,但校正方式考量一、二階矩陣,使其更加平穩。
- 在實作過程中,建議先使用 Adam 驗證,若要做最終的優化,則再改用 SGD 找到最佳參數。
- SGD (mini-batch)
- An overview of gradient descent optimization algorithms
-
优化方法总结
- </>
-
Day_81 : 訓練神經網路的細節與技巧 - Regularization
-
正規化 (Regularization)
- Cost function = Loss + Regularization
- 透過 regularization,可以使的模型的 weights 變得比較小
- wi 較小
$\to$ Δxi 對$\hat{y}$ 造成的影響(Δ$\hat{y}$)較小$\to$ 對 input 變化比較不敏感 ➔ better generalization
- Regularizer 的效果:讓模型參數的數值較小
- 使得 Inputs 的改變不會讓 Outputs 有大幅的改變。
- 延伸閱讀 :
from keras.regularizers import l1_l2 """ 建立神經網路 """ def build_mlp(input_shape, output_units=10, num_neurons=[512, 256, 128], l1_ratio=0.0, l2_ratio=0.0): input_layer = keras.layers.Input(input_shape) for i, n_units in enumerate(num_neurons): if i == 0: x = keras.layers.Dense(units=n_units, activation="relu", name="hidden_layer"+str(i+1), kernel_regularizer=l1_l2(l1=l1_ratio, l2=l2_ratio))(input_layer) else: x = keras.layers.Dense(units=n_units, activation="relu", name="hidden_layer"+str(i+1), kernel_regularizer=l1_l2(l1=l1_ratio, l2=l2_ratio))(x) out = keras.layers.Dense(units=output_units, activation="softmax", name="output")(x) model = keras.models.Model(inputs=[input_layer], outputs=[out]) return model ## 超參數設定 LEARNING_RATE = 1e-3 EPOCHS = 10 BATCH_SIZE = 256 MOMENTUM = 0.95 L1_EXP = [1e-2, 1e-4, 1e-8, 1e-12, 0.0] L2_EXP = [1e-2, 1e-4, 1e-8, 1e-12, 0.0] results = {} for l1r, l2r in itertools.product(L1_EXP, L2_EXP): keras.backend.clear_session() # 把舊的 Graph 清掉 print("Experiment with L1 = %.6f, L2 = %.6f" % (l1r, l2r)) model = build_mlp(input_shape=x_train.shape[1:], l1_ratio=l1r, l2_ratio=l2r) model.summary() optimizer = keras.optimizers.SGD(lr=LEARNING_RATE, nesterov=True, momentum=MOMENTUM) model.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer=optimizer) model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), shuffle=True) # Collect results train_loss = model.history.history["loss"] valid_loss = model.history.history["val_loss"] train_acc = model.history.history["accuracy"] valid_acc = model.history.history["val_accuracy"] exp_name_tag = "exp-l1-%s-l2-%s" % (str(l1r), str(l2r)) results[exp_name_tag] = {'train-loss': train_loss, 'valid-loss': valid_loss, 'train-acc': train_acc, 'valid-acc': valid_acc}
-
正規化 (Regularization)
-
Day_82 : 訓練神經網路的細節與技巧 - Dropout
-
隨機移除 (Dropout)
- 在訓練過程中,在原本全連結的前後兩層 layers ,隨機拿掉一些連結 (weights 設為 0)
- 解釋1:增加訓練的難度 – 當你知道你的同伴中有豬隊友時,你會變得要更努力學習
- 解釋2:被視為一種 model 自身的 ensemble 方法,因為 model 可以有 2^n 種 weights combination
- 優點 : 強迫模型的每個參數有更強的泛化能力,也讓網路能在更多參數組合的狀態下習得表徵。
- 延伸閱讀 :
from keras.layers import Dropout def build_mlp(input_shape, output_units=10, num_neurons=[512, 256, 128], drp_ratio=0.2): input_layer = keras.layers.Input(input_shape) for i, n_units in enumerate(num_neurons): if i == 0: x = keras.layers.Dense(units=n_units, activation="relu", name="hidden_layer"+str(i+1))(input_layer) x = Dropout(drp_ratio)(x) else: x = keras.layers.Dense(units=n_units, activation="relu", name="hidden_layer"+str(i+1))(x) x = Dropout(drp_ratio)(x) out = keras.layers.Dense(units=output_units, activation="softmax", name="output")(x) model = keras.models.Model(inputs=[input_layer], outputs=[out]) return model
-
隨機移除 (Dropout)
-
Day_83 : 訓練神經網路的細節與技巧 - Batch normalization
-
批次標準化 (Batch normalization)
- 對於 Input 的數值,前面提到建議要 re-scale
- Weights 修正的路徑比較會在同心圓山谷中往下滑
- 只加在輸入層 re-scale 不夠,你可以每一層都 re-scale !!
- 每個 input feature 獨立做 normalization
- 利用 batch statistics 做 normalization 而非整份資料
- 同一筆資料在不同的 batch 中會有些微不同
- BN:將輸入經過 t 轉換後輸出
- 訓練時:使用 Batch 的平均值
- 推論時:使用 Moving Average
- 可以解決 Gradient vanishing 的問題
- 可以用比較大的 learning rate 加速訓練
- 取代 dropout & regularizes
- 目前大多數的 Deep neural network 都會加
Input : Values of x over a mini-batch :
$B = {x_{1...m}}$ ; Parameters to be learn :$\gamma, \beta$ Output :${y_i = BN_{\gamma,\beta}(x_i) }$ $$ \mu_B \leftarrow \frac{1}{m} \sum_{i=1}^{m}x_i$$ // mini-batch mean $$ \sigma^2_B \leftarrow \frac{1}{m}\sum_{i=1}^{m}(x_i - \mu_B)^2$$ // mini-batch variance$$\hat{x_i} \leftarrow \frac{x_i - \mu_B}{\sqrt{\sigma^2_B + \epsilon}} $$ // normalize$$y_i \leftarrow \gamma\hat{x_i} + \beta \equiv BN_{\gamma, \beta}(x_i)$$ // scale and shift - 對於 Input 的數值,前面提到建議要 re-scale
-
延伸閱讀 :
from keras.layers import BatchNormalization, Activation def build_mlp(input_shape, output_units=10, num_neurons=[512, 256, 128], pre_activate=False): input_layer = keras.layers.Input(input_shape) for i, n_units in enumerate(num_neurons): if i == 0: x = keras.layers.Dense(units=n_units, name="hidden_layer"+str(i+1))(input_layer) if pre_activate: x = BatchNormalization()(x) x = Activation("relu")(x) else: x = Activation("relu")(x) x = BatchNormalization()(x) else: x = keras.layers.Dense(units=n_units, name="hidden_layer"+str(i+1))(x) if pre_activate: x = BatchNormalization()(x) x = Activation("relu")(x) else: x = Activation("relu")(x) x = BatchNormalization()(x) out = keras.layers.Dense(units=output_units, activation="softmax", name="output")(x) model = keras.models.Model(inputs=[input_layer], outputs=[out]) return model
-
-
Day_84 : 正規化/機移除/批次標準化的 組合與比較
- </>
import os import keras import itertools train, test = keras.datasets.cifar10.load_data() ## 資料前處理 def preproc_x(x, flatten=True): x = x / 255. if flatten: x = x.reshape((len(x), -1)) return x def preproc_y(y, num_classes=10): if y.shape[-1] == 1: y = keras.utils.to_categorical(y, num_classes) return y x_train, y_train = train x_test, y_test = test # Preproc the inputs x_train = preproc_x(x_train) x_test = preproc_x(x_test) # Preprc the outputs y_train = preproc_y(y_train) y_test = preproc_y(y_test) from keras.layers import BatchNormalization, Activation, Dropout, regularizers def build_mlp(input_shape, output_units=10, num_neurons=[512, 256, 128], use_bn=True, drp_ratio=0., l2_ratio=0.): input_layer = keras.layers.Input(input_shape) for i, n_units in enumerate(num_neurons): if i == 0: x = keras.layers.Dense(units=n_units, kernel_regularizer=regularizers.l2(l2_ratio), name="hidden_layer"+str(i+1))(input_layer) if use_bn: x = BatchNormalization()(x) x = Activation("relu")(x) x = Dropout(drp_ratio)(x) else: x = keras.layers.Dense(units=n_units, kernel_regularizer=regularizers.l2(l2_ratio), name="hidden_layer"+str(i+1))(x) if use_bn: x = BatchNormalization()(x) x = Activation("relu")(x) x = Dropout(drp_ratio)(x) out = keras.layers.Dense(units=output_units, activation="softmax", name="output")(x) model = keras.models.Model(inputs=[input_layer], outputs=[out]) return model ## 超參數設定 """ Set your hyper-parameters """ LEARNING_RATE = 1e-3 EPOCHS = 3 BATCH_SIZE = 128 """ 建立實驗組合 """ USE_BN = [True, False] DRP_RATIO = [0., 0.4, 0.8] L2_RATIO = [0., 1e-6, 1e-8] import keras.backend as K """ 以迴圈方式遍歷組合來訓練模型 """ results = {} for i, (use_bn, drp_ratio, l2_ratio) in enumerate(itertools.product(USE_BN, DRP_RATIO, L2_RATIO)): K.clear_session() print("Numbers of exp: %i, with bn: %s, drp_ratio: %.2f, l2_ratio: %.2f" % (i, use_bn, drp_ratio, l2_ratio)) model = build_mlp(input_shape=x_train.shape[1:], use_bn=use_bn, drp_ratio=drp_ratio, l2_ratio=l2_ratio) model.summary() optimizer = keras.optimizers.Adam(lr=LEARNING_RATE) model.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer=optimizer) model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), verbose=1, shuffle=True) # Collect results exp_name_tag = ("exp-%s" % (i)) results[exp_name_tag] = {'train-loss': model.history.history["loss"], 'valid-loss': model.history.history["val_loss"], 'train-acc': model.history.history["accuracy"], 'valid-acc': model.history.history["val_accuracy"]}
- </>
-
Day_85 : 訓練神經網路的細節與技巧 - 使用 callbacks 函數做 earlystop
-
提前終止 (EarlyStopping)
- 假如能夠早點停下來就好
- 在 Overfitting 前停下,避免 model weights 被搞爛
- 注意:Earlystop 不會使模型得到更好的結果,僅是避免更糟
- Callbacks function:在訓練過程中,我們可以透過一些函式來監控/介入訓練
- 延伸閱讀 :
""" # 載入 Callbacks, 並將 monitor 設定為監控 validation loss """ from keras.callbacks import EarlyStopping earlystop = EarlyStopping(monitor="val_loss", patience=5, verbose=1 ) model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), shuffle=True, callbacks=[earlystop] )
-
提前終止 (EarlyStopping)
-
Day_86 : 訓練神經網路的細節與技巧 - 使用 callbacks 函數儲存 model
-
Model CheckPoint
- 為何要使用 Model Check Point?
- ModelCheckPoint:自動將目前最佳的模型權重存下
- 假如電腦突然斷線、當機該怎麼辦? 難道我只能重新開始?
- 假如不幸斷線 : 可以重新自最佳的權重開始
- 假如要做 Inference : 可以保證使用的是對 monitor metric 最佳的權重
- 為何要使用 Model Check Point?
- 延伸閱讀 :
""" # 載入 Callbacks, 並將監控目標設為 validation loss, 且只存最佳參數時的模型 """ from keras.callbacks import ModelCheckpoint model_ckpt = ModelCheckpoint(filepath="./tmp.h5", monitor="val_loss", save_best_only=True) model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), shuffle=True, callbacks=[model_ckpt] ) model.save("final_model.h5") model.save_weights("model_weights.h5") pred_final = model.predict(x_test) # Load back model = keras.models.load_model("./tmp.h5") pred_loadback = model.predict(x_test) from sklearn.metrics import accuracy_score new_model = build_mlp(input_shape=x_train.shape[1:]) new_model_pred = new_model.predict(x_test) new_model_acc = accuracy_score(y_true=y_test.argmax(axis=-1), y_pred=new_model_pred.argmax(axis=-1)) print("Accuracy of best weights: %.3f" % new_model_acc) new_model.load_weights("./model_weights.h5") new_model_pred = new_model.predict(x_test) new_model_loadback_acc = accuracy_score(y_true=y_test.argmax(axis=-1), y_pred=new_model_pred.argmax(axis=-1)) print("Accuracy of best weights: %.3f" % new_model_loadback_acc)
-
Model CheckPoint
-
Day_87 : 訓練神經網路的細節與技巧 - 使用 callbacks 函數做 reduce learning rate
- Reduce Learning Rate: 隨訓練更新次數,將 Learning rate 逐步減小
- 因為通常損失函數越接近谷底的位置,開口越小 – 需要較⼩的 Learning rate 才可以再次下降
- 可行的調降方式
- 每更新 n 次後,將 Learning rate 做一次調降 – schedule decay
- 當經過幾個 epoch 後,發現 performance 沒有進步 – Reduce on plateau
- Reduce learning rate on plateau:模型沒辦法進步的可能是因為學習率太大導致每次改變量太大而無法落入較低的損失平面,透過適度的降低,就有機會得到更好的結果
- 因為我們可以透過這樣的監控機制,初始的 Learning rate 可以調得比較高,讓訓練過程與 callback 來做適當的 learning rate 調降。
- 延伸閱讀 :
- Callbacks API
- A. LearningRateScheduler
- 在每個 epoch 開始前,得到目前 lr
- 根據 schedule function 重新計算 lr,比如 epoch = n 時, new_lr = lr * 0.1
- 將 optimizer 的 lr 設定為 new_lr
- 根據 shhedule 函式,假設要自訂的話,它應該吃兩個參數:epoch & lr
- B. ReduceLR
- 在每個 epoch 結束時,得到目前監控目標的數值
- 如果目標比目前儲存的還要差的話,wait+1;若否則 wait 設為 0,目前監控數值更新的數值
- 如果 wait >= patient,new_lr = lr * factor,將 optimizer 的 lr 設定為 new_lr,並且 wait 設回 0
""" # 載入 Callbacks, 並設定監控目標為 validation loss """ from keras.callbacks import ReduceLROnPlateau reduce_lr = ReduceLROnPlateau(factor=0.5, min_lr=1e-12, monitor='val_loss', patience=5, verbose=1) model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), shuffle=True, callbacks=[reduce_lr] )
- Reduce Learning Rate: 隨訓練更新次數,將 Learning rate 逐步減小
-
Day_88 : 訓練神經網路的細節與技巧 - 撰寫自己的 callbacks 函數
- Callbacks
- Callback 在訓練時的呼叫時機
- on_train_begin:在訓練最開始時
- on_train_end:在訓練結束時
- on_batch_begin:在每個 batch 開始時
- on_batch_end:在每個 batch 結束時
- on_epoch_begin:在每個 epoch 開始時
- on_epoch_end:在每個 epoch 結束時
- 在 Keras 中,僅需要實作你想要啟動的部分即可
- 舉例來說,假如你想要每個 batch 都記錄 loss 的話
from keras.callbacks import Callback class My_callback(Callback): def on_train_begin(self, logs={}): return def on_train_end(self, logs={}): return def on_epoch_begin(self, logs={}): return def on_epoch_end(self, logs={}): return def on_batch_begin(self, batch, logs={}): return def on_batch_end(self, batch, logs={}): self.losses.append(logs.get("loss")) return - Callback 在訓練時的呼叫時機
- 延伸閱讀 :
""" # 載入 Callbacks,撰寫一個 f1 score 的 callback function """ from keras.callbacks import Callback from sklearn.metrics import f1_score class f1sc(Callback): def on_train_begin(self, epoch, logs = {}): logs = logs or {} record_items = ["val_f1sc"] for i in record_items: if i not in self.params['metrics']: self.params['metrics'].append(i) def on_epoch_end(self, epoch, logs = {}, thres=0.5): logs = logs or {} y_true = self.validation_data[1].argmax(axis = 1) y_pred = self.model.predict(self.validation_data[0]) y_pred = (y_pred[:, 1] >= thres) * 1 logs["val_f1sc"] = f1_score(y_true = y_true, y_pred = y_pred, average="weighted") log_f1sc = f1sc() model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), shuffle=True, callbacks=[log_f1sc] ) # 在訓練後,將 f1sc 紀錄調出 valid_f1sc = model.history.history['val_f1sc'] import matplotlib.pyplot as plt %matplotlib inline plt.plot(range(len(valid_f1sc)), valid_f1sc, label="valid f1-score") plt.legend() plt.title("F1-score") plt.show()# 載入 Callbacks from keras.callbacks import Callback # Record_fp_tp class Record_tp_tn(Callback): def on_train_begin(self, epoch, logs = {}): logs = logs or {} record_items = ["val_tp", "val_tn"] for i in record_items: if i not in self.params['metrics']: self.params['metrics'].append(i) def on_epoch_end(self, epoch, logs = {}, thres=0.5): logs = logs or {} y_true = self.validation_data[1].argmax(axis = 1) y_pred = self.model.predict(self.validation_data[0]) y_pred = (y_pred[:, 1] >= thres) * 1 val_tp = sum(y_true*y_pred) val_tn = sum((y_true==0) & (y_pred==0)) logs["val_tp"] = val_tp logs["val_tn"] = val_tn rec_tptn = Record_tp_tn() model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), shuffle=True, callbacks=[rec_tptn] ) valid_tp = model.history.history['val_tp'] valid_tn = model.history.history['val_tn']
- Callbacks
-
Day_89 : 訓練神經網路的細節與技巧 - 撰寫自己的 Loss function
- 在 Keras 中,除了使用官方提供的 Loss function 外,亦可以自行定義/修改 loss function 所定義的函數
- 最內層函式的參數輸入須根據 output tensor 而定,舉例來說,在分類模型中需要有 y_true, y_pred
- 需要使用 tensor operations – 即在 tensor 上運算而非在 numpy array 上進行運算
- 回傳的結果是一個 tensor
import keras.backend as K def dice_coef(y_true, y_pred, smooth): # 皆須使用 tensor operations y_pred = y_pred >= 0.5 y_true_f = K.flatten(y_true) y_pred_f = K.flatten(y_pred) intersection = K.sum(y_true_f * y_pred_f) return (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth) def dice_loss(smooth, thresh): # 最內層的函式 – 在分類問題中,只能有 y_true 與 y_pred,其他調控參數應至於外層函式 def dice(y_true, y_pred): return dice_coef(y_true, y_pred): # 輸出為 Tensor return dice - 在 Keras 中,我們可以自行定義函式來進行損失的運算。一個損失函數必須:
- 有 y_true 與 y_pred 兩個輸入
- 必須可以微分
- 必須使用 tensor operation,也就是在 tensor 的狀狀態下,進行運算。如 K.sum ...
- 延伸閱讀 :
import tensorflow as tf import keras.backend as K """ # 撰寫自定義的 loss function: focal loss (https://blog.csdn.net/u014380165/article/details/77019084) """ def focal_loss(gamma=2., alpha=4.): gamma = float(gamma) alpha = float(alpha) def focal_loss_fixed(y_true, y_pred): """Focal loss for multi-classification FL(p_t)=-alpha(1-p_t)^{gamma}ln(p_t) """ epsilon = 1e-8 y_true = tf.convert_to_tensor(y_true, tf.float32) y_pred = tf.convert_to_tensor(y_pred, tf.float32) model_out = tf.add(y_pred, epsilon) ce = tf.multiply(y_true, -tf.log(model_out)) weight = tf.multiply(y_true, tf.pow(tf.subtract(1., model_out), gamma)) fl = tf.multiply(alpha, tf.multiply(weight, ce)) reduced_fl = tf.reduce_max(fl, axis=1) return tf.reduce_mean(reduced_fl) return focal_loss_fixed model = build_mlp(input_shape=x_train.shape[1:]) model.summary() optimizer = keras.optimizers.SGD(lr=LEARNING_RATE, nesterov=True, momentum=MOMENTUM) """ # 在 compile 時,使用自定義的 loss function """ model.compile(loss=focal_loss(), metrics=["accuracy"], optimizer=optimizer) model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), shuffle=True )# 自行定義一個 loss function, 為 0.3 * focal loss + 0.7 cross-entropy import tensorflow as tf import keras.backend as K def combined_loss(gamma=2., alpha=4., ce_weights=0.7, fcl_weights=0.3): gamma = float(gamma) alpha = float(alpha) def CE_focal_loss(y_true, y_pred): """Focal loss for multi-classification FL(p_t)=-alpha(1-p_t)^{gamma}ln(p_t) """ epsilon = 1e-8 y_true = tf.convert_to_tensor(y_true, tf.float32) y_pred = tf.convert_to_tensor(y_pred, tf.float32) model_out = tf.add(y_pred, epsilon) ce = tf.multiply(y_true, -tf.log(model_out)) weight = tf.multiply(y_true, tf.pow(tf.subtract(1., model_out), gamma)) fl = tf.multiply(alpha, tf.multiply(weight, ce)) reduced_fl = tf.reduce_max(fl, axis=1) ce_loss = keras.losses.categorical_crossentropy(y_true, y_pred) return (ce_weights*ce_loss) + (fcl_weights*tf.reduce_mean(reduced_fl) ) return CE_focal_loss ce_weights_list = [0., 0.3, 0.5, 0.7, 1] import itertools results = {} for i, ce_w in enumerate(ce_weights_list): print("Numbers of exp: %i, ce_weight: %.2f" % (i, ce_w)) model = build_mlp(input_shape=x_train.shape[1:]) model.summary() optimizer = keras.optimizers.SGD(lr=LEARNING_RATE, nesterov=True, momentum=MOMENTUM) model.compile(loss=combined_loss(ce_weights=ce_w, fcl_weights=1.-ce_w), metrics=["accuracy"], optimizer=optimizer) model.fit(x_train, y_train, epochs=EPOCHS, batch_size=BATCH_SIZE, validation_data=(x_test, y_test), shuffle=True )
- 在 Keras 中,除了使用官方提供的 Loss function 外,亦可以自行定義/修改 loss function 所定義的函數
-
Day_90 : 傳統電腦視覺與影像辨識
- 影像辨識的傳統方法是特徵描述及檢測,需要辦法把影像素量化為特徵(特徵工程),然後把特徵丟給我們之前學過的機器學習算法來做分類或回歸。
- 為了有更直觀的理解,這裡介紹一種最簡單提取特徵的方法
- 如何描述顏色?
- 顏色直方圖 : 顏色直方圖是將顏色信息轉化為特徵一種⽅方法,將顏色值 RGB 轉為直方圖值,來描述色彩和強度的分佈情況。舉例來說,一張彩色圖有 3 個channel, RGB,顏色值都介於 0-255 之間,最小可以去統計每個像素值出現在圖片的數量,也可以是一個區間如 (0 - 15)、(16 - 31)、...、(240 - 255)。
- 在要辨認顏色的場景就會非常有用,但可能就不適合用來做邊緣檢測的任務,因為從顏色的分佈沒有考量到空間上的信息。
- 不同的任務,我們就要想辦法針對性地設計特徵來進行後續影像辨識的任務。
import os import keras import cv2 # 載入 cv2 套件 import matplotlib.pyplot as plt train, test = keras.datasets.cifar10.load_data() image = train[0][0] # 讀取圖片 # 把彩色的圖片轉為灰度圖 gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) ''' 調用 cv2.calcHist 函數,回傳值就是 histogram images (list of array):要分析的圖片 channels:產生的直方圖類型。例:[0]→灰度圖,[0, 1, 2]→RGB三色。 mask:optional,若有提供則僅計算 mask 部份的直方圖。 histSize:要切分的像素強度值範圍,預設為256。每個channel皆可指定一個範圍。例如,[32,32,32] 表示RGB三個channels皆切分為32區段。 ranges:像素的範圍,預設為[0,256],表示<256。 ''' hist = cv2.calcHist([gray], [0], None, [256], [0, 256]) plt.figure() plt.title("Grayscale Histogram") plt.xlabel("Bins") plt.ylabel("# of Pixels") plt.plot(hist) plt.xlim([0, 256]) plt.show() chans = cv2.split(image) # 把圖像的 3 個 channel 切分出來 colors = ("r", "g", "b") plt.figure() plt.title("'Flattened' Color Histogram") plt.xlabel("Bins") plt.ylabel("# of Pixels") # 對於所有 channel for (chan, color) in zip(chans, colors): # 計算該 channel 的直方圖 hist = cv2.calcHist([chan], [0], None, [256], [0, 256]) # 畫出該 channel 的直方圖 plt.plot(hist, color = color) plt.xlim([0, 256]) plt.show()
- 如何描述顏色?
- 延伸閱讀 :
-
Day_91 : 傳統電腦視覺與影像辨識 </>
- 靠人工設計的特徵在簡單的任務上也許是堪用,但複雜的情況,比如說分類的類別多起來,就能明顯感覺到這些特徵的不足之處,體會這一點能更幫助理解接下來的卷積神經網路的意義。
- 延伸閱讀 :
import os import keras import tensorflow as tf import numpy as np import cv2 # 載入 cv2 套件 import matplotlib.pyplot as plt train, test = keras.datasets.cifar10.load_data() x_train, y_train = train x_test, y_test = test y_train = y_train.astype(int) y_test = y_test.astype(int) # 產生直方圖特徵的訓練資料 x_train_histogram = [] x_test_histogram = [] # 對於所有訓練資料 for i in range(len(x_train)): chans = cv2.split(x_train[i]) # 把圖像的 3 個 channel 切分出來 # 對於所有 channel hist_feature = [] for chan in chans: # 計算該 channel 的直方圖 hist = cv2.calcHist([chan], [0], None, [16], [0, 256]) # 切成 16 個 bin hist_feature.extend(hist.flatten()) # 把計算的直方圖特徵收集起來 x_train_histogram.append(hist_feature) # 對於所有測試資料也做一樣的處理 for i in range(len(x_test)): chans = cv2.split(x_test[i]) # 把圖像的 3 個 channel 切分出來 # 對於所有 channel hist_feature = [] for chan in chans: # 計算該 channel 的直方圖 hist = cv2.calcHist([chan], [0], None, [16], [0, 256]) # 切成 16 個 bin hist_feature.extend(hist.flatten()) x_test_histogram.append(hist_feature) x_train_histogram = np.array(x_train_histogram) x_test_histogram = np.array(x_test_histogram) # 產生 HOG 特徵的訓練資料 bin_n = 16 # Number of bins def hog(img): img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) gx = cv2.Sobel(img, cv2.CV_32F, 1, 0) gy = cv2.Sobel(img, cv2.CV_32F, 0, 1) mag, ang = cv2.cartToPolar(gx, gy) bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16) bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:] mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:] hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)] hist = np.hstack(hists) # hist is a 64 bit vector return hist.astype(np.float32) x_train_hog = np.array([hog(x) for x in x_train]) x_test_hog = np.array([hog(x) for x in x_test]) # 用 histogram 特徵訓練 SVM 模型 SVM_hist = cv2.ml.SVM_create() SVM_hist.setKernel(cv2.ml.SVM_LINEAR) SVM_hist.setGamma(5.383) SVM_hist.setType(cv2.ml.SVM_C_SVC) SVM_hist.setC(2.67) #training SVM_hist.train(x_train_histogram, cv2.ml.ROW_SAMPLE, y_train) # prediction _, y_hist_train = SVM_hist.predict(x_train_histogram) _, y_hist_test = SVM_hist.predict(x_test_histogram) # 用 HOG 特徵訓練 SVM 模型 SVM_hog = cv2.ml.SVM_create() SVM_hog.setKernel(cv2.ml.SVM_LINEAR) SVM_hog.setGamma(5.383) SVM_hog.setType(cv2.ml.SVM_C_SVC) SVM_hog.setC(2.67) #training SVM_hog.train(x_train_hog, cv2.ml.ROW_SAMPLE, y_train) # prediction _, y_hog_train = SVM_hog.predict(x_train_hog) _, y_hog_test = SVM_hog.predict(x_test_hog) # accuracy acc_hist_train = (sum(y_hist_train == y_train) / len(y_hist_train))[0] * 100 acc_hog_train = (sum(y_hog_train == y_train) / len(y_hog_train))[0] * 100 acc_hist_test = (sum(y_hist_test == y_test) / len(y_hist_test))[0] * 100 acc_hog_test = (sum(y_hog_test == y_test) / len(y_hog_test))[0] * 100 import numpy as np labels = ['training', 'testing'] hist_acc = [acc_hist_train, acc_hist_test] hog_acc = [acc_hog_train, acc_hog_test] x = np.arange(len(labels)) # the label locations width = 0.35 # the width of the bars fig, ax = plt.subplots() rects1 = ax.bar(x - width/2, hist_acc, width, label='histogram') rects2 = ax.bar(x + width/2, hog_acc, width, label='HOG') # Add some text for labels, title and custom x-axis tick labels, etc. ax.set_ylabel('accuracy %') ax.set_title('cifar10 by SVM with different features') ax.set_ylim(0,30) ax.set_xticks(x) ax.set_xticklabels(labels) ax.legend() def autolabel(rects): """Attach a text label above each bar in *rects*, displaying its height.""" for rect in rects: height = rect.get_height() ax.annotate('{0:.3f}'.format(height), xy=(rect.get_x() + rect.get_width() / 2, height), xytext=(0, 3), # 3 points vertical offset textcoords="offset points", ha='center', va='bottom') autolabel(rects1) autolabel(rects2) fig.tight_layout() plt.show()
- Day_92 : 卷積神經網路(Convolution Neural Network, CNN) 簡介
- ImageNet Challenge 是電腦視覺的競賽,需要對影像進行 1000 個類別的預測,在 CNN 出現後首次有超越人類準確率的模型
- 卷積是甚麼?
- 卷積其實只是簡單的數學乘法與加法
- 利用濾波器 (filter) 對圖像做卷積來找尋規則
- 卷積是將影像與 filter 的值相乘後再進行加總,即可得到特徵圖 (Feature Map)
- 卷積的目的
- 透過卷積,我們可以找出圖像上與濾波器具有相同特徵的區域
- 濾波器 (filter)
- 濾波器是用來找圖像上是否有同樣特徵
- 那濾波器 (filter) 中的數字是怎麼得來的呢?
- 其實是透過資料學習而來的! 這也就是 CNN 模型中的參數 (或叫權重 weights)
- CNN 會自動從訓練資料中學習出適合的濾波器來完成你的任務 (分類、偵測等)
- 濾波器 (Filter) 視覺化
- 透過一層又一層的神經網路疊加,可以看到底層的濾波器在找線條與顏色的特徵,中層則是輪輪廓與形狀 (輪胎),高層的則是相對完整的特徵 (如車窗、後照鏡等)
- Day_93 : 卷積神經網路架構細節
- 卷積神經網路跟深度網路
- 傳統的 DNN(即 Deep neural network)最大問題在於它會忽略資料的形狀。
- 例如,輸入影像的資料時,該 data 通常包含了水平、垂直、color channel 等三維資訊,但傳統 DNN 的輸入處理必須是平面的、也就是須一維的資料。
- 一些重要的空間資料,只有在三維形狀中才能保留下來。
- RGB 不同的 channel 之間也可能具有某些關連性、而遠近不同的像素彼此也應具有不同的關聯性
- 深度學習(Deep learning)中的 CNN 較傳統的 DNN 多了 Convolutional(卷積)及池化(Pooling)兩層 layer,用以維持形狀資訊並且避免參數大幅增加。
- Convolution 原理是透過一個指定尺寸的window,由上而下依序滑動取得圖像中各局部特徵作為下一層的輸入,這個 sliding window 在 CNN 中稱為 Convolution kernel 利用此方式來取得圖像中各局部的區域加總計算後,透過 ReLU activation function 輸出為特徵值再提供給下一層使用
- 傳統的 DNN(即 Deep neural network)最大問題在於它會忽略資料的形狀。
- 池化層 (Pooling Layer)
- Pooling layer 稱為池化層,它的功能很單純,就是將輸入的圖片尺寸縮小(大部份為縮小一半)以減少每張 feature map 維度並保留重要的特徵,其好處有:
- 特徵降維,減少後續 layer 需要參數。
- 具有抗干擾的作用:圖像中某些像素在鄰近區域有微小偏移或差異時,對 Pooling layer 的輸出影響不大,結果仍是不變的。
- 減少過度擬合 over-fitting 的情況。與卷積層相同,池化層會使用 kernel 來取出各區域的值並運算,但最後的輸出並不透過 Activate function(卷積層使用的 function是 ReLU)
- Pooling layer 稱為池化層,它的功能很單純,就是將輸入的圖片尺寸縮小(大部份為縮小一半)以減少每張 feature map 維度並保留重要的特徵,其好處有:
- 卷積網路的組成
- Convolution Layer 卷積層
- Pooling Layer 池化層
- Flatten Layer 平坦層
- Fully connection Layer 全連接層
- Flatten – 平坦層
- Flatten:將特徵資訊丟到 Full connected layer 來進行分類,其神經元只與上一層 kernel 的像素連結,而且各連結的權重在同層中是相同且共享的
- Fully connected layers - 全連接層
- 卷積和池化層,其最主要的目的分別是提取特徵及減少圖像參數,然後將特徵資訊丟到 Full connected layer 來進行分類,其神經元只與上一層 kernel 的像素連結,而且各連結的權重在同層中是相同且共享的
#導入相關模組 import keras from keras import layers from keras import models from keras.models import Sequential from keras.layers import Conv2D, Activation, MaxPooling2D, Flatten, Dense #建立一個序列模型 model = models.Sequential() #建立一個卷績層, 32 個內核, 內核大小 3x3, #輸入影像大小 28x28x1 model.add(layers.Conv2D(32, (3, 3), input_shape=(28, 28, 1))) #建立第二個卷績層, #請注意, 不需要再輸入 input_shape model.add(layers.Conv2D(25, (3, 3))) #新增平坦層 model.add(Flatten()) #建立一個全連接層 model.add(Dense(units=100)) model.add(Activation('relu')) #建立一個輸出層, 並採用softmax model.add(Dense(units=10)) model.add(Activation('softmax')) #輸出模型的堆疊 model.summary()
- 卷積神經網路跟深度網路
- Day_94 : 卷積神經網路 - 卷積(Convolution)層與參數調整
- 卷積 (Convolution) 的超參數 (Hyper parameter)
- 卷積內核 (kernel)
- Depth (kernels的總數)
- Padding (是否加一圈 0 值的 pixel)
- Stride (選框每次移動的步數)
- 填充或移動步數 (Padding/Stride) 的用途
- RUN 過 CNN,兩個問題
- 是不是卷積計算後,卷積後的圖是不是就一定只能變小?
- 可以選擇維持一樣大
- 卷積計算是不是一次只能移動一格?
- 是不是卷積計算後,卷積後的圖是不是就一定只能變小?
- 控制卷積計算的圖大小 - Valid and Same convolutions
- padding = ‘VALID’ 等於最一開始敘述的卷積計算,圖根據 filter 大小和 stride 大小而變小
- new_height = new_width = (W-F + 1) / S
- padding = ‘ Same’的意思是就是要讓輸入和輸出的大小是一樣的
- pad=1,表示圖外圈額外加 1 圈 0,假設 pad=2,圖外圈額外加 2 圈 0,以此類推
- RUN 過 CNN,兩個問題
- 舉例
Model.add(Convolution2D(32, 3, 3), input_shape=(1, 28, 28), strides=2, padding='valid’)- 這代表卷積層 filter 數設定為 32,filter 的 kernel size 是 3,步伐 stride 是 2,pad 是1。
- pad = 1,表示圖外圈額外加 1 圈 0,假設 pad = 2,圖外圈額外加 2 圈 0,以此類推
- kernel size 是 3 的時候,卷積後圖的寬高不要變,pad 就要設定為 1
- kernel size 是 5 的時候,卷積後圖的寬高不要變,pad 就要設定為 2
- pad = 1,表示圖外圈額外加 1 圈 0,假設 pad = 2,圖外圈額外加 2 圈 0,以此類推
- 這代表卷積層 filter 數設定為 32,filter 的 kernel size 是 3,步伐 stride 是 2,pad 是1。
- 延伸閱讀 :
- 卷積 (Convolution) 的超參數 (Hyper parameter)
- Day_95 : 卷積神經網路 - 池化(Pooling)層與參數調整
- 池化層 (Pooling Layer) 如何調用
keras.layers.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)- pool_size:整數,沿(垂直,水平)方向縮小比例的因數。
- (2,2)會把輸入張量的兩個維度都縮小一半
- strides:整數,2 個整數表示的元組,或者是”None”。表示步長值。
- 如果是 None,那麼默認值是 pool_size。
- padding:"valid"或者"same"(區分大小寫)。
- data_format:channels_last(默認)或 channels_first 之一。表⽰\示輸入各維度的順序
- channels_last 代表尺寸是 (batch, height, width, channels) 的輸入張量。
- channels_first 代表尺寸是 (batch, channels, height, width) 的輸入張量。
- pool_size:整數,沿(垂直,水平)方向縮小比例的因數。
- 池化層 (Pooling Layer) 超參數
- 前端輸入 feature map 維度:W1×H1×D1 有兩個 hyperparameters:
- Pooling filter 的維度 - F,
- 移動的步數S,
- 所以預計生成的輸出是 W2×H2×D2:
- W2=(W1−F)/S+1
- H2=(H1−F)/S+1
- D2=D1
- 前端輸入 feature map 維度:W1×H1×D1 有兩個 hyperparameters:
- 池化層 (Pooling Layer ) 常用的類型
- Max pooling (最大池化)
- Average pooling (平均池化)
- 卷積神經網路 (CNN) 特性
- 適合用在影像上
- 因為 fully-connected networking (全連接層) 如果用在影像辨識上,會導致參數過多(因為像素很多),導致 over-fitting (過度擬合)
- CNN 針對影像辨識的特性,特別設計過,來減少參數
- Convolution(卷積) : 學出 filter 比對原始圖片,產生出 feature map (特徵圖, 也當成image)
- Max Pooling (最大池化):將 feature map 縮小
- Flatten (平坦層):將每個像素的 channels (有多少個 filters) 展開成 fully connected feedforward network (全連接的前行網路)
- AlphaGo 也用了 CNN,但是沒有用 Max Pooling (所以不問題需要不同 model)
- 適合用在影像上
- Pooling Layer (池化層) 適用的場景
- 特徵提取的誤差主要來自兩個方面:
- 鄰域大小受限造成的估計值方差增大;
- 卷積層超參數與內核造成估計均值的偏移
- 一般來來說,
- average-pooling 能減小第一種誤差,更多的保留圖像的背景信息
- max-pooling 能減小第二種誤差,更多的保留紋理信息
- 特徵提取的誤差主要來自兩個方面:
- 延伸閱讀 :
# GRADED FUNCTION: zero_pad def zero_pad(X, pad): """ 對image X 做 zero-padding. 參數定義如下: X -- python numpy array, 呈現維度 (m, n_H, n_W, n_C), 代表一批 m 個圖像 n_H: 圖高, n_W: 圖寬, n_C: color channels 數 pad -- 整數, 加幾圈的 zero padding. Returns: X_pad -- image of shape (m, n_H + 2*pad, n_W + 2*pad, n_C) 做完zero-padding 的結果 """ ### Code 起始位置 X_pad = np.pad(X, ((0, 0), (pad, pad), (pad, pad), (0, 0)), 'constant', constant_values=(0, 0)) return X_pad # GRADED FUNCTION: pool_forward def pool_forward(A_prev, hparameters, mode = "max"): """ 設計一個前行網路的池化層 參數定義如下: A_prev -- 輸入的numpy 陣列, 維度 (m, n_H_prev, n_W_prev, n_C_prev) hparameter 超參數 -- "f" and "stride" 所形成的python 字典 mode -- 池化的模式: "max" or "average" 返回: A -- 輸出的池化層, 維度為 (m, n_H, n_W, n_C) 的 numpy 陣列 cache -- 可以應用在 backward pass pooling layer 資料, 包含 input and hparameter """ # 檢索尺寸 from the input shape (m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape # 檢索超參數 from "hparameters" f = hparameters["f"] stride = hparameters["stride"] # 定義輸出的dimensions n_H = int(1 + (n_H_prev - f) / stride) n_W = int(1 + (n_W_prev - f) / stride) n_C = n_C_prev # 初始化輸出的 matrix A A = np.zeros((m, n_H, n_W, n_C)) ### 程式起始位置 ### for i in range(m): # 訓練樣本的for 迴圈 for h in range(n_H): # 輸出樣本的for 迴圈, 針對vertical axis for w in range(n_W): # 輸出樣本的for 迴圈, 針對 horizontal axis for c in range (n_C): # 輸出樣本的for 迴圈, 針對channels # 找出特徵圖的寬度跟高度四個點 vert_start = h * stride vert_end = h * stride+ f horiz_start = w * stride horiz_end = w * stride + f # 定義第i個訓練示例中 a_prev_slice = A_prev[i, vert_start:vert_end, horiz_start:horiz_end,c] # 計算輸入data 的池化結果. 使用 if statment 去做分類 if mode == "max": A[i, h, w, c] = np.max(a_prev_slice) elif mode == "average": A[i, h, w, c] = np.mean(a_prev_slice) ### 程式結束 ### # 儲存輸入的特徵圖跟所設定的超參數, 可以用在 pool_backward() cache = (A_prev, hparameters) # 確認輸出的資料維度 assert(A.shape == (m, n_H, n_W, n_C)) return A, cache
- 池化層 (Pooling Layer) 如何調用
- Day_96 : Keras 中的 CNN layers
- 卷積層 Convolution layer
- 卷積神經網路就是透過疊起一層又一層的卷積層、池化層產生的。
- 影像經過卷積後稱作特徵圖 (feature map),經過多次卷積層後,特徵圖的尺寸 (width, height) 會越來越小,但是通道數 (Channel) 則會越來越大
- Keras 中的 CNN layers - Conv2D
from keras.layers import Conv2D feature_maps = Conv2D(filters=128, kernel_size=(3,3), input_shape=input_image.shape)(input_image)
- 上方的程式碼先 import Keras 中的 Conv2D,接下來對 input_image 進行2D 卷積,即可得到我們的特徵圖 feature maps
- Conv2D 中的參數意義
- Keras 中的 CNN layers - SeparableConv2D
- 全名稱做 Depthwise Separable Convolution,與常用的 Conv2D 效果類似,但是參數量可以大幅減少,減輕對硬體的需求
- 對影像做兩次卷積
- 第一次稱為 DetphWise Conv,對影像的三個通道獨立做卷積,得到三張特徵圖;
- 第二次稱為 PointWise Conv,使用 1x1 的 filter 尺寸做卷積。
- 兩次卷積結合起來可以跟常用的卷積達到接近的效果,但參數量卻遠少於常見的卷積更多資訊可參考連結
- SeparableConv2D 中的參數意義
- filters, kernel_size, strides, padding 都與 Conv2D 相同
- depth_multiplier : 在做 DepthWise Conv 時,輸出的特徵圖 Channel 數量會是 filters * depth_multiplier,預設為 1
from keras.layers import Conv2D, SeparableConv2D, Input from keras.models import Model, Sequential input_image = Input((224, 224, 3)) feature_maps = Conv2D(filters=32, kernel_size=(3,3))(input_image) feature_maps2 = Conv2D(filters=64, kernel_size=(3,3))(feature_maps) model = Model(inputs=input_image, outputs=feature_maps2) model.summary() ''' _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_5 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 222, 222, 32) 896 _________________________________________________________________ conv2d_6 (Conv2D) (None, 220, 220, 64) 18496 ================================================================= Total params: 19,392 Trainable params: 19,392 Non-trainable params: 0 _________________________________________________________________ ''' input_image = Input((224, 224, 3)) feature_maps = SeparableConv2D(filters=32, kernel_size=(3,3))(input_image) feature_maps2 = SeparableConv2D(filters=64, kernel_size=(3,3))(feature_maps) model = Model(inputs=input_image, outputs=feature_maps2) model.summary() ''' _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_6 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ separable_conv2d_1 (Separabl (None, 222, 222, 32) 155 _________________________________________________________________ separable_conv2d_2 (Separabl (None, 220, 220, 64) 2400 ================================================================= Total params: 2,555 Trainable params: 2,555 Non-trainable params: 0 _________________________________________________________________ # 可以看到使用 Seperable Conv2D,即使模型設置都一模一樣,但是參數量明顯減少非常多! '''
- 卷積層 Convolution layer
- Day_97 : 使用 CNN 完成 CIFAR-10 資料集 </>
- Cifar-10
- 如同先前課程中的 Scikit-learn.datasets,深度學習的影像資料集以 MNIST (手寫數字辨識) 與 Cifar-10 (自然影像分類) 作為常見
- Cifar-10 是 10 個類別,影像大小為 32x32 的一個輕量資料集,非常適合拿來做深度學習的練習
- CNN 相比 DNN,更適合用來來處理影像的資料集
import keras from keras.datasets import cifar10 from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D from keras.optimizers import RMSprop, Adam batch_size = 128 # batch 的大小,如果出現 OOM error,請降低這個值 num_classes = 10 # 類別的數量,Cifar 10 共有 10 個類別 epochs = 10 # 訓練的 epochs 數量 # 讀取資料並檢視 (x_train, y_train), (x_test, y_test) = cifar10.load_data() print('x_train shape:', x_train.shape) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') # 對 label 進行 one-hot encoding (y_trian 原本是純數字) y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) # 首先我們使用一般的 DNN (MLP) 來訓練 # 由於 DNN 只能輸入一維的資料,我們要先將影像進行攤平,若 (50000, 32, 32, 3) 的影像,攤平後會變成 (50000, 32x32x3) = (50000, 3072) # 將資料攤平成一維資料 x_train = x_train.reshape(50000, 3072) x_test = x_test.reshape(10000, 3072) # 將資料變為 float32 並標準化 x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') model = Sequential() model.add(Dense(512, activation='relu', input_shape=(3072,))) model.add(Dropout(0.2)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.2)) model.add(Dense(num_classes, activation='softmax')) model.summary() model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) # 接下來我們使用 CNN 來訓練神經網路 (x_train, y_train), (x_test, y_test) = cifar10.load_data() print('x_train shape:', x_train.shape) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 # Convert class vectors to binary class matrices. y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) model = Sequential() model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes)) model.add(Activation('softmax')) model.summary() model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1])
- Cifar-10
- Day_98 : 訓練卷積神經網路的細節與技巧 - 處理大量數據
- 大數據?
- Cifar-10 資料集相對於常用到的影像來說是非常小,所以可以先把資料集全部讀進記憶體裡面,要使用時直接從記憶體中存取,速度會相當快
- 但是如果我們要處理的資料集超過電腦記憶體的容量呢?桌上電腦的記憶體多為 32, 64, 128 GB,當處理超大圖片、3D 影像或影片時,就可能遇到 Out of Memory error
- 批次 (batch) 讀取
- 如同訓練神經網路時,Batch (批次) 的概念一樣。我們可以將資料一批一批的讀進記憶體,當從 GPU/CPU 訓練完後,將這批資料從記憶體釋出,在讀取下一批資料
- 如何用 Python 撰寫批次讀取資料的程式碼
- 使用 Python 的 generator 來幫你完成這個任務!
- Generator 可以使用 next(your_generator) 來執行下一次循環
- 假設有一個 list,其中有 5 個數字,我們可以撰寫一個 generator,用 next(generator) 會自動吐出 list 的第一個數字,再用第二次 next 則會吐出第二個數字,以此類推
- 將原本 Python function 中的 return 改為 yield,這樣 Python 就知道這是一個 Generator 囉
from keras.datasets import cifar10 (x_train, x_test), (y_train, y_test) = cifar10.load_data() def cifar_generator(image_array, batch_size=32): while True: for indexs in range(0, len(image_array), batch_size): images = image_array[indexs: indexs+batch_size] yield images, labels cifar_gen = cifar_generator(x_train) images, labels = next(cifar_gen)
import keras from keras.datasets import cifar10 from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D from keras.optimizers import RMSprop, Adam batch_size = 128 # batch 的大小,如果出現 OOM error,請降低這個值 num_classes = 10 # 類別的數量,Cifar 10 共有 10 個類別 epochs = 10 # 訓練的 epochs 數量 (x_train, y_train), (x_test, y_test) = cifar10.load_data() print('x_train shape:', x_train.shape) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 # Convert class vectors to binary class matrices. y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) model = Sequential() model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes)) model.add(Activation('softmax')) model.summary() model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) from sklearn.utils import shuffle def my_generator(x, y, batch_size): while True: for idx in range(0, len(x), batch_size): # 讓 idx 從 0 開始,一次增加 batch size。假設 batch_size=32, idx = 0, 32, 64, 96, .... batch_x, batch_y = x[idx:idx+batch_size], y[idx:idx+batch_size] yield batch_x, batch_y x, y = shuffle(x, y) # loop 結束後,將資料順序打亂再重新循環 train_generator = my_generator(x_train, y_train, batch_size) # 建立好我們寫好的 generator history = model.fit_generator(train_generator, steps_per_epoch=int(len(x_train)/batch_size), # 一個 epochs 要執行幾次 update,通常是資料量除以 batch size epochs=epochs, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1])
- 大數據?
- Day_99 : 訓練卷積神經網路的細節與技巧 - 處理小量數據
- ⼩數據?
- 實務上進⾏各種機器學習專案時,我們經常會遇到資料量不⾜的情形,常⾒原因:
- 資料搜集困難或是成本極⾼
- 資料標註不易
- 資料品質不佳
- 除了繼續搜集資料以外,資料增強 (Data augmentation) 是很常⾒的⽅法之⼀
- 實務上進⾏各種機器學習專案時,我們經常會遇到資料量不⾜的情形,常⾒原因:
- 資料增強 (Data augmentation)
- 其實就是對影像進⾏⼀些隨機的處理如翻轉、平移、旋轉、改變亮度等各樣的影像操作,藉此將⼀張影像增加到多張
- 資料增強並非萬靈丹!
- 適度的資料增強通常都可以提升準確率。選⽤的增強⽅法則須視資料集⽽定
- 例如⼈臉辨識就不太適合⽤上下翻轉,因為實際使⽤時不會有上下顛倒的臉部
- 另外需特別注意要先對資料做 train/test split 後再做資料增強!否則其實都是同樣的影像,誤以為模型訓練得非常好
- 適度的資料增強通常都可以提升準確率。選⽤的增強⽅法則須視資料集⽽定
- 延伸閱讀 :
- 常見問題 :
- Q: 跑資料增強時程式碼好像都會出錯?
- A: 要特別注意,資料增強應該要在圖像標準化之 前完成 (e.g. 除以 255、減去平均值)!因為多數資 料增強的函數多是以圖像為 int32 的 RGB 影像來 設計的,若已經先經過標準化,有可能造成程式 碼錯誤
import keras from keras.datasets import cifar10 from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D from keras.optimizers import RMSprop, Adam batch_size = 128 # batch 的大小,如果出現 OOM error,請降低這個值 num_classes = 10 # 類別的數量,Cifar 10 共有 10 個類別 epochs = 10 # 訓練的 epochs 數量 (x_train, y_train), (x_test, y_test) = cifar10.load_data() print('x_train shape:', x_train.shape) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 # Convert class vectors to binary class matrices. y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) model = Sequential() model.add(Conv2D(32, (3, 3), padding='same', input_shape=x_train.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes)) model.add(Activation('softmax')) model.summary() model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy']) augment_generator = ImageDataGenerator(rotation_range=10, width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True) history = model.fit_generator(augment_generator.flow(x_train, y_train, batch_size=batch_size), steps_per_epoch=int(len(x_train)/batch_size), # 一個 epochs 要執行幾次 update,通常是資料量除以 batch size epochs=epochs, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1])
- ⼩數據?
- Day_100 : 訓練卷積神經網路的細節與技巧 - 轉移學習 (Transfer learning)
- 遷移學習,Transfer Learning
- 資料量不足時,遷移學習也是很常見的方法
- 神經網路訓練前的初始參數是隨機產生的,不具備任何意義
- 透過其他龐大資料集上訓練好的模型參數,我們使用這個參數當成起始點,改用在自己的資料集上訓練!
- 為何可以用遷移學習?
- 前面 CNN 的課程有提到,CNN 淺層的過濾器 (filter) 是用來偵測線條與顏色等簡單的元素。因此不管圖像是什麼類型,基本的組成應該要是一樣的
- 大型資料集 (如 ImageNet) 訓練好的參數具有完整的顏色、線條 filters,從此參數開始訓練我們既自己的資料集,逐步把 filters 修正為適合自己資料集的結果。
- 參考大神們的網路架構
- 許多學者們研究了許多架構與多次調整超參數,並在大型資料集如 ImageNet 上進行測試得到準確性高並容易泛化的網路架構,我們可以從這樣的架構開始!
- Transfer learning in Keras: ResNet-50
from keras.applications.resnet50 import ResNet50 resnet_model = ResNet50(input_shape=(224,224,3), weights='imagenet', pooling='avg'), include_top=False) last_featuremaps = resnet_model.output flatten_featuremap = Flatten()(last_featuremaps) output = Dense(num_classes)(flatten_featuremap) New_resnet_model = Model(inputs=resnet_model.input, outputs=output)
- 我們使用了 ResNet50 網路結構,其中可以看到 weight='imagenet',代表我們使用從 imagenet 訓練好的參數來初始化,並指定輸入的影像大小為 (224,224,3)
- pooling='avg' 代表最後一層使用 Global Average pooling,把 feature maps 變成一維的向量
- include_top=False 代表將原本 Dense layer 拔掉,因為原本這個網路是用來做 1000 個分類模型,我們必須替換成自己的 Dense layer 來符合我們自己資料集的類別數量
- 我們將模型設定成沒有 Dense layers,且最後一層做 GAP,使用 resnet_model.output 我們就可以取出最後一層的 featuremaps
- 將其使用 Flatten 攤平後,在接上我們的 Dense layer,神經元數量與資料集的類別數量一致,重建立模型,就可以得到一個新的 ResNet-50 模型,且參數是根據 ImageNet 大型資料集育訓練好的
- 整體流程參考,我們保留 Trained convolutional base,並建立 New classifier (Dense 部分),最後 convolutional base 是否要 frozen (不訓練),則是要看資料集與育訓練的 ImageNet 是否相似,如果差異很大則建議訓練時不要 frozen,讓 CNN 的參數可以繼續更新
- 重要知識複習
- 遷移學習是透過預先再大型資料集訓練好的權重,再根據自己的資料及進行微調 (finetune) 的一種學習方法
- Keras 中的模型,只要指定權重 weights='imagenet' 即可使用遷移學習
- 延伸閱讀 :
""" #Trains a ResNet on the CIFAR10 dataset. ResNet 共有兩個版本,此處解答我們使用 v1 來做訓練。 ResNet v1: [Deep Residual Learning for Image Recognition ](https://arxiv.org/pdf/1512.03385.pdf) ResNet v2: [Identity Mappings in Deep Residual Networks ](https://arxiv.org/pdf/1603.05027.pdf) """ import keras from keras.layers import Dense, Conv2D, BatchNormalization, Activation from keras.layers import AveragePooling2D, Input, Flatten from keras.optimizers import Adam from keras.callbacks import ModelCheckpoint, LearningRateScheduler from keras.callbacks import ReduceLROnPlateau from keras.preprocessing.image import ImageDataGenerator from keras.regularizers import l2 from keras import backend as K from keras.models import Model from keras.datasets import cifar10 import numpy as np import os # 訓練用的超參數 batch_size = 128 epochs = 200 data_augmentation = True num_classes = 10 # 資料標準化的方式,此處使用減去所有影像的平均值 subtract_pixel_mean = True # Model parameter # ---------------------------------------------------------------------------- # | | 200-epoch | Orig Paper| 200-epoch | Orig Paper| sec/epoch # Model | n | ResNet v1 | ResNet v1 | ResNet v2 | ResNet v2 | GTX1080Ti # |v1(v2)| %Accuracy | %Accuracy | %Accuracy | %Accuracy | v1 (v2) # ---------------------------------------------------------------------------- # ResNet20 | 3 (2)| 92.16 | 91.25 | ----- | ----- | 35 (---) # ResNet32 | 5(NA)| 92.46 | 92.49 | NA | NA | 50 ( NA) # ResNet44 | 7(NA)| 92.50 | 92.83 | NA | NA | 70 ( NA) # ResNet56 | 9 (6)| 92.71 | 93.03 | 93.01 | NA | 90 (100) # ResNet110 |18(12)| 92.65 | 93.39+-.16| 93.15 | 93.63 | 165(180) # ResNet164 |27(18)| ----- | 94.07 | ----- | 94.54 | ---(---) # ResNet1001| (111)| ----- | 92.39 | ----- | 95.08+-.14| ---(---) # --------------------------------------------------------------------------- n = 9 # 使用 ResNet-56 的網路架構 # 使用的 ResNet 模型版本 # Orig paper: version = 1 (ResNet v1), Improved ResNet: version = 2 (ResNet v2) version = 1 # 計算不同 ResNet 版本對應的網路深度,此處都是根據 paper 的定義來計算 depth = n * 6 + 2 # 模型的名稱 model_type = 'ResNet%dv%d' % (depth, version) # 讀取 Cifar-10 資料集 (x_train, y_train), (x_test, y_test) = cifar10.load_data() # 影像輸入的維度 input_shape = x_train.shape[1:] # 先把影像縮放到 0-1 之間 x_train = x_train.astype('float32') / 255 x_test = x_test.astype('float32') / 255 # 再減去所有影像的平均值 if subtract_pixel_mean: x_train_mean = np.mean(x_train, axis=0) x_train -= x_train_mean x_test -= x_train_mean # 此處要注意!測試資料也是減去訓練資料的平均值來做標準化,不可以減測試資料的平均值 (因為理論上你是不能知道測試資料的平均值的!) print('x_train shape:', x_train.shape) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') print('y_train shape:', y_train.shape) # 對 label 做 one-hot encoding y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) # 學習率動態調整。當跑到第幾個 epcoh 時,根據設定修改學習率。這邊的數值都是參考原 paper def lr_schedule(epoch): """Learning Rate Schedule Learning rate is scheduled to be reduced after 80, 120, 160, 180 epochs. Called automatically every epoch as part of callbacks during training. # Arguments epoch (int): The number of epochs # Returns lr (float32): learning rate """ lr = 1e-3 if epoch > 180: lr *= 0.5e-3 elif epoch > 160: lr *= 1e-3 elif epoch > 120: lr *= 1e-2 elif epoch > 80: lr *= 1e-1 print('Learning rate: ', lr) return lr # 使用 resnet_layer 來建立我們的 ResNet 模型 def resnet_layer(inputs, num_filters=16, kernel_size=3, strides=1, activation='relu', batch_normalization=True, conv_first=True): """2D Convolution-Batch Normalization-Activation stack builder # Arguments inputs (tensor): input tensor from input image or previous layer num_filters (int): Conv2D number of filters kernel_size (int): Conv2D square kernel dimensions strides (int): Conv2D square stride dimensions activation (string): activation name batch_normalization (bool): whether to include batch normalization conv_first (bool): conv-bn-activation (True) or bn-activation-conv (False) # Returns x (tensor): tensor as input to the next layer """ # 建立卷積層 conv = Conv2D(num_filters, kernel_size=kernel_size, strides=strides, padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4)) # 對輸入進行卷機,根據 conv_first 來決定 conv. bn, activation 的順序 x = inputs if conv_first: x = conv(x) if batch_normalization: x = BatchNormalization()(x) if activation is not None: x = Activation(activation)(x) else: if batch_normalization: x = BatchNormalization()(x) if activation is not None: x = Activation(activation)(x) x = conv(x) return x # Resnet v1 共有三個 stage,每經過一次 stage,影像就會變小一半,但 channels 數量增加一倍。ResNet-20 代表共有 20 層 layers,疊越深參數越多 def resnet_v1(input_shape, depth, num_classes=10): """ResNet Version 1 Model builder [a] Stacks of 2 x (3 x 3) Conv2D-BN-ReLU Last ReLU is after the shortcut connection. At the beginning of each stage, the feature map size is halved (downsampled) by a convolutional layer with strides=2, while the number of filters is doubled. Within each stage, the layers have the same number filters and the same number of filters. Features maps sizes: stage 0: 32x32, 16 stage 1: 16x16, 32 stage 2: 8x8, 64 The Number of parameters is approx the same as Table 6 of [a]: ResNet20 0.27M ResNet32 0.46M ResNet44 0.66M ResNet56 0.85M ResNet110 1.7M # Arguments input_shape (tensor): shape of input image tensor depth (int): number of core convolutional layers num_classes (int): number of classes (CIFAR10 has 10) # Returns model (Model): Keras model instance """ if (depth - 2) % 6 != 0: raise ValueError('depth should be 6n+2 (eg 20, 32, 44 in [a])') # 模型的初始設置,要用多少 filters,共有幾個 residual block (組成 ResNet 的單元) num_filters = 16 num_res_blocks = int((depth - 2) / 6) # 建立 Input layer inputs = Input(shape=input_shape) # 先對影像做第一次卷機 x = resnet_layer(inputs=inputs) # 總共建立 3 個 stage for stack in range(3): # 每個 stage 建立數個 residual blocks (數量視你的層數而訂,越多層越多 block) for res_block in range(num_res_blocks): strides = 1 if stack > 0 and res_block == 0: # first layer but not first stack strides = 2 # downsample y = resnet_layer(inputs=x, num_filters=num_filters, strides=strides) y = resnet_layer(inputs=y, num_filters=num_filters, activation=None) if stack > 0 and res_block == 0: # first layer but not first stack # linear projection residual shortcut connection to match # changed dims x = resnet_layer(inputs=x, num_filters=num_filters, kernel_size=1, strides=strides, activation=None, batch_normalization=False) x = keras.layers.add([x, y]) # 此處把 featuremaps 與 上一層的輸入加起來 (欲更了解結構需閱讀原論文) x = Activation('relu')(x) num_filters *= 2 # 建立分類 # 使用 average pooling,且 size 跟 featuremaps 的 size 一樣 (相等於做 GlobalAveragePooling) x = AveragePooling2D(pool_size=8)(x) y = Flatten()(x) # 接上 Dense layer 來做分類 outputs = Dense(num_classes, activation='softmax', kernel_initializer='he_normal')(y) # 建立模型 model = Model(inputs=inputs, outputs=outputs) return model # 建立 ResNet v1 模型 model = resnet_v1(input_shape=input_shape, depth=depth) # 編譯模型,使用 Adam 優化器並使用學習率動態調整的函數,0代表在第一個 epochs model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=lr_schedule(0)), metrics=['accuracy']) model.summary() print(model_type) # 使用動態調整學習率 lr_scheduler = LearningRateScheduler(lr_schedule) # 使用自動降低學習率 (當 validation loss 連續 5 次沒有下降時,自動降低學習率) lr_reducer = ReduceLROnPlateau(factor=np.sqrt(0.1), cooldown=0, patience=5, min_lr=0.5e-6) # 設定 callbacks callbacks = [lr_reducer, lr_scheduler] print('Using real-time data augmentation.') datagen = ImageDataGenerator( # set input mean to 0 over the dataset featurewise_center=False, # set each sample mean to 0 samplewise_center=False, # divide inputs by std of dataset featurewise_std_normalization=False, # divide each input by its std samplewise_std_normalization=False, # apply ZCA whitening zca_whitening=False, # epsilon for ZCA whitening zca_epsilon=1e-06, # randomly rotate images in the range (deg 0 to 180) rotation_range=0, # randomly shift images horizontally width_shift_range=0.1, # randomly shift images vertically height_shift_range=0.1, # set range for random shear shear_range=0., # set range for random zoom zoom_range=0., # set range for random channel shifts channel_shift_range=0., # set mode for filling points outside the input boundaries fill_mode='nearest', # value used for fill_mode = "constant" cval=0., # randomly flip images horizontal_flip=True, # randomly flip images vertical_flip=False, # set rescaling factor (applied before any other transformation) rescale=None, # set function that will be applied on each input preprocessing_function=None, # image data format, either "channels_first" or "channels_last" data_format=None, # fraction of images reserved for validation (strictly between 0 and 1) validation_split=0.0) # 將資料送進 ImageDataGenrator 中做增強 datagen.fit(x_train) # 訓練模型囉! model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size), steps_per_epoch=int(len(x_train)//batch_size), validation_data=(x_test, y_test), epochs=epochs, verbose=1, workers=4, callbacks=callbacks) # 評估我們的模型 scores = model.evaluate(x_test, y_test, verbose=1) print('Test loss:', scores[0]) print('Test accuracy:', scores[1])
- 遷移學習,Transfer Learning
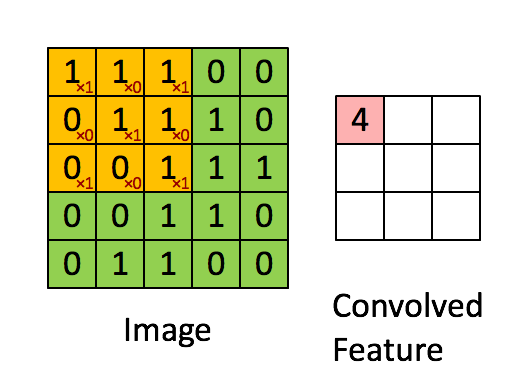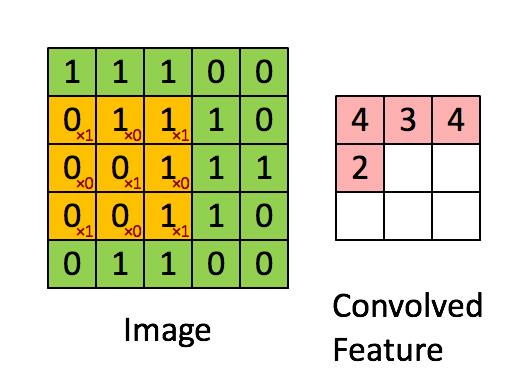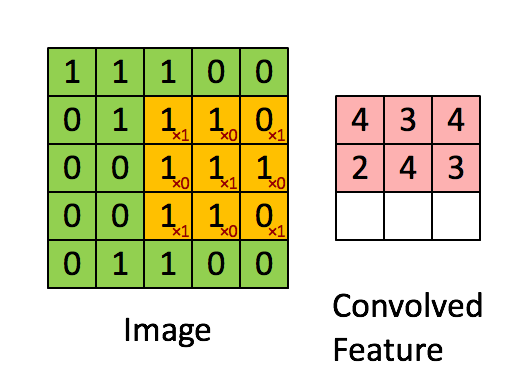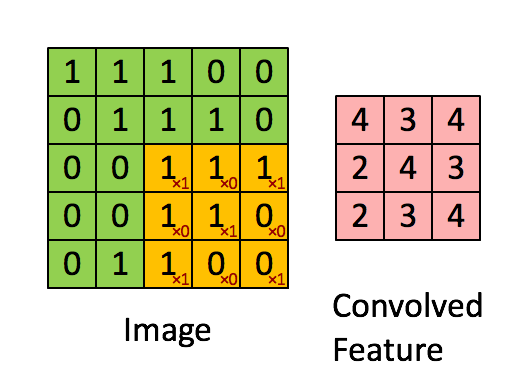{kind=link}
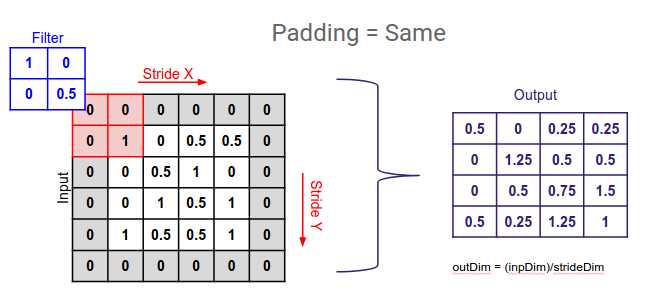{kind=link}
- Day_101~103 : 影像辨識
- Day_104 : 互動式網頁神經網路視覺化
- 何謂 ConvNetJS?
- ConvNetJS 是一個 Javascript 庫,用於完全在您的瀏覽器中訓練深度學習模型(神經網路)
- 線上網址
- 何謂 ConvNetJS?
- Day_105 : CNN 卷積網路演進和應用
- 卷積網路 CNN 的進展簡圖
st1=>start: Perception st2=>start: Neocognition st3=>start: LeNet st4=>condition: AlexNet a1=>start: MIN a2=>start: Inception V1 a3=>start: Inception V2 a4=>start: Inception V3 b1=>start: VGG b2=>start: MSRANet b3=>start: ResNet b4=>start: ResNet V2 e=>start: Inception ResNet V2 st1->st2->st3->st4 st4(yes)->a1->a2->a3->a4->e st4(no)->b1->b2->b3->b4->e - 卷積網路架構回顧
- 卷積網路的優點:
- 局部感知與權重共享,藉由卷積核抽取影像的局部特徵,並且讓影像各區域共享這個卷積核
- 兩大部分:
- 影像特徵提取:CNN_Layer1+Pooling_1+CNN_Layer2+Pooling_2 的處理
- Fully Connected Layer:包含 Flatten Layer, Hidden Layer, Output Layer
- 卷積網路的優點:
- CNN 圖像處理上有不同的模型
- 主要的元素:ROI, CNN feature map, anchor boxes, mask
- 有趣延伸應用 :
- 無人商店 : 貨架掃描機器人
- 主要功能 :
- 利用電腦視覺導航,避免撞上顧客或推車
- 缺貨補上
- 價格標錯校正
- 價格缺標校正
- 主要功能 :
- 說圖人 (Image Caption)
- Activity Recognition : CNNs + LSTM
- Image Description : CNN + LSTM
- Vedio Description : CRF + LSTM
- R-CNN (Regional CNN)
- R-CNN,它把物體檢測技術拓展到提供像素級別的分割。
- R-CNN 的目標是:導入一張圖片,通過方框正確識別主要物體在圖像的哪個地方。
- 輸入:圖像
- 輸出:方框 + 每個物體的標籤
- 但怎麼知道這些方框應該在哪裡呢?
- R-CNN 的處理方式 — 在圖像中搞出一大堆方框,看看是否有任何一個與某個物體重疊
- 生成這些邊框、或者說是推薦局域,R-CNN 採用的是一項名為 Selective Search 的流程
- Selective Search 通過不同尺寸的窗口來查看圖像
- 對於每一個尺寸,它通過紋理、色彩或密度把相鄰像素劃為一組,來進行物體識別。
- 當邊框方案生成之後,R-CNN 把選取區域變形為標準的方形
- 在 CNN 的最後一層,R-CNN 加入了一個支持向量機,它要做的事很簡單:對這是否是一個物體進行分類,如果是,是什麼物體。
- 是否能縮小邊框,讓它更符合物體的三維尺寸?
- 答案是肯定的,這是 R-CNN 的最後一步。
- R-CNN 在推薦區域上運行一個簡單的線性回歸,生成更緊的邊框坐標以得到最終結果。
- 回歸模型的輸入和輸出:
- 輸入:對應物體的圖像子區域
- 輸出:針對該物體的新邊框系統
- 回歸模型的輸入和輸出:
- 概括下來,R-CNN 只是以下這幾個步驟:
- 生成對邊框的推薦
- 在預訓練的 AlexNet 上運行方框裡的物體。用支持向量機來看邊框裡的物體是什麼。
- 在線性回歸模型上跑該邊框,在物體分類之後輸出更緊的邊框的座標
- 無人商店 : 貨架掃描機器人
- 卷積網路 CNN 的進展簡圖
- Day_106 : 電腦視覺常用公開資料集
- 搜集與標注資料是耗時勞力的工作
- 若專案的目標相近,網路上是有非常多公開且標注好的資料集可以使用!
- Kaggle
- ImageNet dataset
- COCO dataset
- Kaggle
- 各式各樣的影像辨識題目,例如數海獅數量
- ImageNet
- 由史丹佛李飛飛教授團隊收集,共 1400 萬張影像,1000 個類別要分類,其中類別非常細緻,需要區分各種鳥類、瓶子與車輛等
- 目前分類模型的 benchmark 幾乎都是跑在 ImageNet
- COCO dataset
- 常見的 80 個類別,是目前最完整標註的資料集,包含分割、偵測、文字描述。
- 偵測模型、分割模型的 benchmark 都會使用在 COCO dataset 上
- Day_107 : 電腦視覺應用介紹 - 影像分類, 影像分割, 物件偵測
- 電腦視覺中,有許多不同的應用,比如:
- 影像分類
- 影像分割
- 物件偵測
- 人臉偵測
- 關鍵點偵測
- 實例分割
- 這些應用多半有大型且標注好的資料集作為評估 (benchmark)
- 影像分類 Image Classification
- 最常見的有
- 手寫數字辨識 (MNIST)、
- Cifar-10、
- Cifar-100、
- ImageNet (1,000 個類別分類)、
- ImageNet-10k (10,000 個類別分類)
- 最常見的有
- 影像分割 Image Segmentation
- 將影像中的類別輪廓分割出來,可以得到每個類別的輪廓,常見的有
- Pascal VOC dataset
- cityscapes dataset
- 將影像中的類別輪廓分割出來,可以得到每個類別的輪廓,常見的有
- 物件偵測 Object Detection
- 將影像中的類別座標偵測出來,可以得到每個類別涵蓋的範圍,可以進行數量計算,常見的有
- COCO dataset
- Home objects dataset
- 將影像中的類別座標偵測出來,可以得到每個類別涵蓋的範圍,可以進行數量計算,常見的有
- 人臉偵測 Face Detection
- 將影像中的人臉位置找出,並進行分類。常見的臉部資料集有
- CelebFaces,
- Labeled Face in the wilds
- 將影像中的人臉位置找出,並進行分類。常見的臉部資料集有
- 關鍵點偵測 Keypoint Detection
- 將影像中人物的關鍵點偵測出來,後續可做姿勢預測或是步態辨別等應用。
- COCO dataset
- 將影像中人物的關鍵點偵測出來,後續可做姿勢預測或是步態辨別等應用。
- 實例分割 Instance Segmentation
- 與物件偵測非常類似,但除了物件的框框以外,需要將輪廓也一併偵測出來。
- COCO dataset
- 與物件偵測非常類似,但除了物件的框框以外,需要將輪廓也一併偵測出來。
- 電腦視覺中,有許多不同的應用,比如: