Anomaly detection deals with the problem of finding data items that do not follow the patterns of the majority of data. The task is to distinguish good items from anomalous items. This can be defined as a binary classification problem and as such solved with supervised learning techniques. However, classes can be highly imbalanced.
Imagine an industrial manufacturing processes, where millions of parts are produced every day, but 1 percent of the production may be defective. A supervised learning approach would clearly suffer from this imbalance. Auto-encoders however are perfect for this situation, because they can be trained on normal parts and don't require annotated data. Once trained, we can give it a feature representation for a part and compare autoencoder output with input. The larger the difference, the more likely the input contains an anomaly.
Auto-encoders consist of two parts: an encoder that encodes the input data using a reduced representation and a decoder that attempts to reconstruct the original input data from the reduced representation. The network is subject to constraints that force the auto-encoder to learn a compressed representation of the training set. It does this in an unsupervised manner and is therefore most suitable for problems related to anomaly detection.
This notebook gives an example for an auto-encoder trained on UCSD Anomaly Detection Dataset
Let's start by downloading and extracting the dataset:
import glob
import numpy as np
from urllib import urlopen
import tarfile
import os
import mxnet as mx
from mxnet import gluon
from PIL import Image
from scipy import signal
from matplotlib import pyplot as plt
if not os.path.isfile("UCSD_Anomaly_Dataset.tar.gz"):
response = urlopen("http://www.svcl.ucsd.edu/projects/anomaly/UCSD_Anomaly_Dataset.tar.gz")
html = response.read()
tar = tarfile.open("UCSD_Anomaly_Dataset.tar.gz")
tar.extractall()
tar.close()Let's define the network structure. The encoder consists of two convolutional and two MaxPooling layers. Encoder and Decoder are connected by a fully connected layer. The larger this bottleneck, the more information can be reconstructed. The decoder consists of two Upsampling layers and two Deconvolutions.
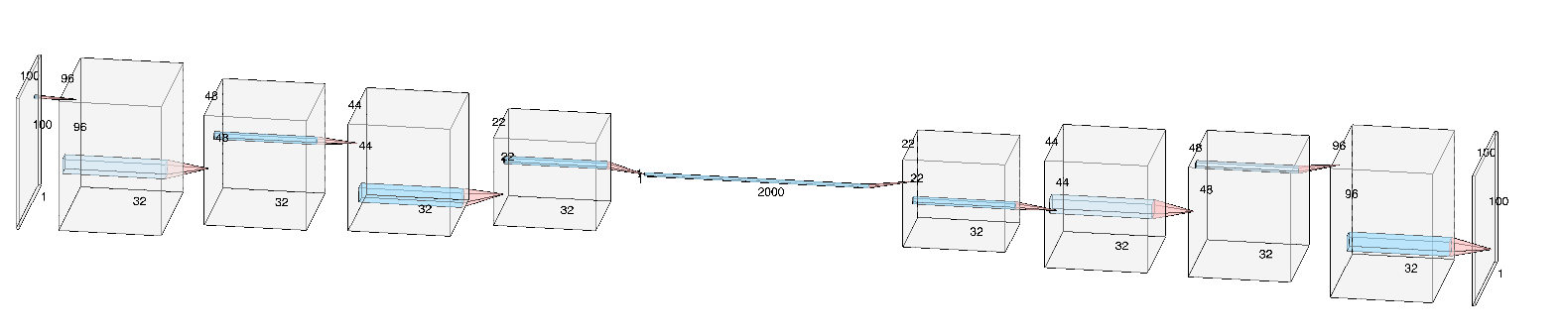
class ConvolutionalAutoencoder(gluon.nn.HybridBlock):
def __init__(self):
super(ConvolutionalAutoencoder, self).__init__()
with self.name_scope():
self.encoder = gluon.nn.HybridSequential()
with self.encoder.name_scope():
self.encoder.add(gluon.nn.Conv2D(32, 5, activation='relu'))
self.encoder.add(gluon.nn.MaxPool2D(2))
self.encoder.add(gluon.nn.Conv2D(32, 5, activation='relu'))
self.encoder.add(gluon.nn.MaxPool2D(2))
self.encoder.add(gluon.nn.Dense(2000))
self.decoder = gluon.nn.HybridSequential()
with self.decoder.name_scope():
self.decoder.add(gluon.nn.Dense(32*22*22, activation='relu'))
self.decoder.add(gluon.nn.HybridLambda(lambda F, x: F.UpSampling(x, scale=2, sample_type='nearest')))
self.decoder.add(gluon.nn.Conv2DTranspose(32, 5, activation='relu'))
self.decoder.add(gluon.nn.HybridLambda(lambda F, x: F.UpSampling(x, scale=2, sample_type='nearest')))
self.decoder.add(gluon.nn.Conv2DTranspose(1, kernel_size=5, activation='sigmoid'))
def hybrid_forward(self, F, x):
x = self.encoder(x)
x = self.decoder[0](x)
x = x.reshape((-1,32,22,22))
x = self.decoder[1:](x)
return xWe train the Autoencoder for 30 epochs and with a batch size of 32.
ctx = mx.cpu()
num_epochs = 30
batch_size = 32Images from the folder UCSDped1 have the format 158x238 pixels. They are rescaled to 100x100 and normalized.
files = sorted(glob.glob('UCSD_Anomaly_Dataset.v1p2/UCSDped1/Train/*/*'))
a = np.zeros((len(files),1,100,100))
for idx, filename in enumerate(files):
im = Image.open(filename)
im = im.resize((100,100))
a[idx,0,:,:] = np.array(im, dtype=np.float32)/255.0
dataset = gluon.data.ArrayDataset(mx.nd.array(a, dtype=np.float32))
dataloader = gluon.data.DataLoader(dataset, batch_size=batch_size, last_batch='rollover',shuffle=True)Intialize the network and define loss function.
model = ConvolutionalAutoencoder()
model.hybridize()
model.collect_params().initialize(mx.init.Xavier('gaussian'), ctx=ctx)
loss_function = gluon.loss.L2Loss()
optimizer = gluon.Trainer(model.collect_params(), 'adam', {'learning_rate': 1e-4, 'wd': 1e-5})The following code defines the training loop:
for epoch in range(num_epochs):
for image_batch in dataloader:
image = image_batch.as_in_context(ctx)
with mx.autograd.record():
output = model(image_batch)
loss = loss_function(output, image_batch)
loss.backward()
optimizer.step(image.shape[0])
print('epoch [{}/{}], loss:{:.4f}'.format(epoch + 1, num_epochs, mx.nd.mean(loss).asscalar()))
model.save_parameters("autoencoder_ucsd.params")Now that the Autoencoder is trained, we can use our test dataset, which contains some anomalies. We focus here on Test024, which is a video sequence with a golf cart that should be detected as anomaly.
files = sorted(glob.glob('UCSD_Anomaly_Dataset.v1p2/UCSDped1/Test/Test024/*'))
a = np.zeros((len(files),1,100,100))
for idx,filename in enumerate(files):
im = Image.open(filename)
im = im.resize((100,100))
a[idx,0,:,:] = np.array(im, dtype=np.float32)/255.0
dataset = gluon.data.ArrayDataset(mx.nd.array(a, dtype=np.float32))
dataloader = gluon.data.DataLoader(dataset, batch_size=1)A helper function that will plot input and output images and the differnce between them.
def plot(img, output, diff, H, threshold, counter):
fig, (ax0, ax1, ax2,ax3) = plt.subplots(ncols=4, figsize=(10, 5))
ax0.set_axis_off()
ax1.set_axis_off()
ax2.set_axis_off()
ax0.set_title('input image')
ax1.set_title('reconstructed image')
ax2.set_title('diff ')
ax3.set_title('anomalies')
ax0.imshow(img, cmap=plt.cm.gray, interpolation='nearest')
ax1.imshow(output, cmap=plt.cm.gray, interpolation='nearest')
ax2.imshow(diff, cmap=plt.cm.viridis, vmin=0, vmax=255, interpolation='nearest')
ax3.imshow(img, cmap=plt.cm.gray, interpolation='nearest')
x,y = np.where(H > threshold)
ax3.scatter(y,x,color='red',s=0.1)
plt.axis('off')
fig.savefig('images/' + str(counter) + '.png')Let's iterate over the test images. We compute the difference between input and output and create a pixel map H with a 4x4 convolution kernel. If a pixel value in H is larger than 4 times 255 it will be marked as anomaly. The maximum value for each pixel in H is 4x4x255. We perform this step, so that pixels will be marked only when their neighboring pixels are also anomalous.
threshold = 4*255
counter = 0
try:
os.mkdir("images")
except:
pass
for image in dataloader:
counter = counter + 1
img = image.as_in_context(mx.cpu())
output = model(img)
output = output.transpose((0,2,3,1))
image = image.transpose((0,2,3,1))
output = output.asnumpy()*255
img = image.asnumpy()*255
diff = np.abs(output-img)
tmp = diff[0,:,:,0]
H = signal.convolve2d(tmp, np.ones((4,4)), mode='same')
plot(img[0,:,:,0], output[0,:,:,0], diff[0,:,:,0], H, threshold, counter)
break
As we can see in the video, the golf cart is successfully identified as an anomaly. The autoencoder has learned to reconstruct human beings well, but it struggles with objects that it has not seen during training. The dimension of the bottleneck layer will influence how much information is transmitted between encoder and decoder. If we set it too large or even remove it, then images will be reconstructed quite well. In the video below we removed the layer, so information flows from the second MaxPooling layer directly to the first Upsampling layer.

One problem of the standard CAE is that it does not take into account the temporal aspect of sequence of images. As such identifying certain anomalies like a person moving faster than the average cannot be easily detected. For instance in the video above the person on skateboard nor the person on the bicycle are detected as an anomaly. The paper "Learning Temporal Regularity in Video Sequences" describes an autoencoder that can also learn spatio-temporal structures in datasets. Instead of considering only one image at a time we consider now n images at a time. CAE takes the input in the form of [batch_size, 1, width, height]) and the spatio-temporal autoencoder takes [batch_size, n, width, height].
class convSTAE(gluon.nn.HybridBlock):
def __init__(self):
super(convSTAE, self).__init__()
with self.name_scope():
self.encoder = gluon.nn.HybridSequential(prefix="encoder")
with self.encoder.name_scope():
self.encoder.add(gluon.nn.Conv2D(512, kernel_size=15, strides=4, activation='relu'))
self.encoder.add(gluon.nn.BatchNorm())
self.encoder.add(gluon.nn.MaxPool2D(2))
self.encoder.add(gluon.nn.BatchNorm())
self.encoder.add(gluon.nn.Conv2D(256, kernel_size=4, activation='relu'))
self.encoder.add(gluon.nn.BatchNorm())
self.encoder.add(gluon.nn.MaxPool2D(2))
self.encoder.add(gluon.nn.BatchNorm())
self.encoder.add(gluon.nn.Conv2D(128, kernel_size=3, activation='relu'))
self.encoder.add(gluon.nn.BatchNorm())
self.decoder = gluon.nn.HybridSequential(prefix="decoder")
with self.decoder.name_scope():
self.decoder.add(gluon.nn.Conv2DTranspose(channels=256, kernel_size=3, activation='relu'))
self.decoder.add(gluon.nn.BatchNorm())
self.decoder.add(gluon.nn.HybridLambda(lambda F, x: F.UpSampling(x, scale=2, sample_type='nearest')))
self.decoder.add(gluon.nn.BatchNorm())
self.decoder.add(gluon.nn.Conv2DTranspose(channels=512, kernel_size=4, activation='relu'))
self.decoder.add(gluon.nn.BatchNorm())
self.decoder.add(gluon.nn.HybridLambda(lambda F, x: F.UpSampling(x, scale=2, sample_type='nearest')))
self.decoder.add(gluon.nn.BatchNorm())
self.decoder.add(gluon.nn.Conv2DTranspose(channels=10, kernel_size=15, strides=4, activation='sigmoid'))
def hybrid_forward(self, F, x):
x = self.encoder(x)
x = self.decoder(x)
return xThe input dataset needs to be modified: instead of 1 channel, it contains now n channels.
files = sorted(glob.glob('UCSD_Anomaly_Dataset.v1p2/UCSDped1/Train/*/*'))
a = np.zeros((int(len(files)/n), n, 227, 227))
i = 0
idx = 0
for filename in range(0, len(files)):
im = Image.open(files[filename])
im = im.resize((n,n))
a[idx,i,:,:] = np.array(im, dtype=np.float32)/255.0
i = i + 1
if i >= n:
idx = idx + 1
i = 0Following shows, that this autoencoder can more accurately detect anomalies such as persons on bicycles or skateboards.

We can enhance the previous model by using convolutions LSTM cells. ConvLSTMs have proven to be effective in video processing, where they can be used to predict next video frames. The paper Abnormal Event Detection in Videos using Spatiotemporal Autoencoder describes an autoencoder model, where 10 input frames are stacked together in one cube. They are processed by 2 convolutionals layers (encoder), followed by the temporal enocder/decoder that consists of 3 convolutional LSTMs and last 2 deconvolutional layers that reconstruct the output frames.
class ConvLSTMAE(gluon.nn.HybridBlock):
def __init__(self, **kwargs):
super(ConvLSTMAE, self).__init__(**kwargs)
with self.name_scope():
self.encoder = gluon.nn.HybridSequential()
self.encoder.add(gluon.nn.Conv2D(128, kernel_size=11, strides=4, activation='relu'))
self.encoder.add(gluon.nn.Conv2D(64, kernel_size=5, strides=2, activation='relu'))
self.temporal_encoder = gluon.rnn.HybridSequentialRNNCell()
self.temporal_encoder.add(gluon.contrib.rnn.Conv2DLSTMCell((64,26,26), 64, 3, 3, i2h_pad=1))
self.temporal_encoder.add(gluon.contrib.rnn.Conv2DLSTMCell((64,26,26), 32, 3, 3, i2h_pad=1))
self.temporal_encoder.add(gluon.contrib.rnn.Conv2DLSTMCell((32,26,26), 64, 3, 3, i2h_pad=1))
self.decoder = gluon.nn.HybridSequential()
self.decoder.add(gluon.nn.Conv2DTranspose(channels=128, kernel_size=5, strides=2, activation='relu'))
self.decoder.add(gluon.nn.Conv2DTranspose(channels=10, kernel_size=11, strides=4, activation='sigmoid'))
def hybrid_forward(self, F, x, states=None, **kwargs):
x = self.encoder(x)
x, states = self.temporal_encoder(x, states)
x = self.decoder(x)
return x, statesWhen we initialize the model, we have to create the intital state vector for the LSTMs.
model = ConvLSTMAE()
model.hybridize()
model.collect_params().initialize(mx.init.Xavier(), ctx=mx.gpu())
states = model.temporal_encoder.begin_state(batch_size=batch_size, ctx=ctx)The following video shows the results of the spatio-termporal autoencoder based on convolutional LSTM cells. It achieves very similar results as the previous model.
