
You can also find all 70 answers here 👉 Devinterview.io - Linear Algebra
In machine learning, vectors are essential for representing diverse types of data, including numerical, categorical, and text data.
They form the framework for fundamental operations like adding and multiplying with a scalar.
A vector is a tuple of one or more values, known as its components. Each component can be a number, category, or more abstract entities. In machine learning, vectors are commonly represented as one-dimensional arrays.
- Row Vector: Will have only one row.
- Column Vector: Comprising of only one column.
Play and experiment with the code to know about vectors. Here is the Python code:
# Define a row vector with 3 components
row_vector = [1, 2, 3]
# Define a column vector with 3 components
column_vector = [[1],
[2],
[3]]
# Print the vectors
print("Row Vector:", row_vector)
print("Column Vector:", column_vector)Each corresponding element is added.
Sum of the products of corresponding elements.
Each element is multiplied by the scalar.
Euclidean distance is calculated by finding the square root of the sum of squares of individual elements.
Scalars are single, real numbers that are often used as the coefficients in linear algebra equations.
Vectors, on the other hand, are multi-dimensional objects that not only have a magnitude but also a specific direction in a coordinate space. In machine learning, vectors are commonly used to represent observations or features of the data, such as datasets, measurements, or even the coefficients of a linear model.
-
Scalar: Represents a single point in space and has no direction.
-
Vector: Defines a direction and magnitude in a multi-dimensional space.
-
Scalar: Is standalone and does not have components. Scalars can be considered as 0-D vectors.
-
Vector: Consists of elements called components, which correspond to the magnitudes of the vector in each coordinate direction.
-
Scalar: Denoted by a lower-case italicized letter
-
Vector: Typically represented using a lowercase bold letter (e.g.,
) or with an arrow over the variable (
). Its components can be expressed in a column matrix
or as a transposed row vector.
-
Scalar: Represents a single point with no spatial extent and thus is dimensionless.
-
Vector: Extends from the origin to a specific point in 3D space, effectively defining a directed line segment.
At the heart of Linear Algebra lies the concept of matrices, which serve as a compact, efficient way to represent and manipulate linear transformations.
-
Addition and Subtraction: Dually to arithmetic, matrix addition and subtraction are performed component-wise.
-
Scalar Multiplication: Each element in the matrix is multiplied by the scalar.
-
Matrix Multiplication: Denoted as
$C = AB$ , where$A$ is$m \times n$ and$B$ is$n \times p$ , the dot product of rows of$A$ and columns of$B$ provides the elements of the$m \times p$ matrix$C$ . -
Transpose: This operation flips the matrix over its main diagonal, essentially turning its rows into columns.
-
Inverse: For a square matrix
$A$ , if there exists a matrix$B$ such that$AB = BA = I$ , then$B$ is the inverse of$A$ .
-
Machine Perspective: Matrices are seen as a sequence of transformations, with emphasis on matrix multiplication. This viewpoint is prevalent in Computer Graphics and other fields.
-
Data Perspective: Vectors comprise the individual components of a system. Here, matrices are considered a mechanism to parameterize how the vectors change.
-
The Cartesian Coordinate System can visually represent transformations through matrices. For example:
-
For Reflection: The 2D matrix
flips the y-component.
- For Rotation: The 2D matrix
rotates points by
radians.
- For Scaling: The 2D matrix
scales points by a factor of
in both dimensions.
-
Graphic Systems: Matrices are employed to convert vertices from model to world space and to perform perspective projection.
-
Data Science: Principal Component Analysis (PCA) inherently entails eigendecompositions of covariance matrices.
-
Quantum Mechanics: Operators (like Hamiltonians) associated with physical observables are represented as matrices.
-
Classical Mechanics: Systems of linear equations describe atmospheric pressure, fluid dynamics, and more.
-
Control Systems: Transmitting electrical signals or managing mechanical loads can be modeled using state-space or transfer function representations, which rely on matrices.
-
Optimization: The notorious Least Squares method resolves linear systems, often depicted as matrix equations.
- Markov Chains: Navigating outcomes subject to variables like customer choice or stock performance benefits from matrix manipulations.
- Rotoscoping: In earlier hand-drawn animations or even in modern CGI, matrices facilitate transformations and movements of characters or objects.
In Machine Learning, a tensor is a generalization of scalars, vectors, and matrices to higher dimensions. It is the primary data structure you'll work with across frameworks like TensorFlow, PyTorch, and Keras.
-
Scalar: A single number, often a real or complex value.
-
Vector: Ordered array of numbers, representing a direction in space. Vectors in
$\mathbb{R}^n$ aren-dimensional. -
Matrix: A 2D grid of numbers representing linear transformations and relationships between vectors.
-
Higher-Dimensional Tensors: Generalize beyond 1D (vectors) and 2D (matrices) and are crucial in deep learning for handling multi-dimensional structured data.
- Data Representation: Tensors conveniently represent multi-dimensional data, such as time series, text sequences, and images.
- Flexibility in Operations: Can undergo various algebraic operations such as addition, multiplication, and more, thanks to their defined shape and type.
- Memory Management: Modern frameworks manage underlying memory, facilitating computational efficiency.
- Speed and Parallel Processing: Tensors enable computations to be accelerated through hardware optimizations like GPU and TPU.
Here is the Python code:
import tensorflow as tf
# Creating Scalars, Vectors, and Matrices
scalar = tf.constant(3)
vector = tf.constant([1, 2, 3])
matrix = tf.constant([[1, 2], [3, 4]])
# Accessing shapes of the created objects
print(scalar.shape) # Outputs: ()
print(vector.shape) # Outputs: (3,)
print(matrix.shape) # Outputs: (2, 2)
# Element-wise operations
double_vector = vector * 2 # tf.constant([2, 4, 6])
# Reshaping
reshaped_matrix = tf.reshape(matrix, shape=(1, 4))- Time-Series Data: Capture events at distinct time points.
- Text Sequences: Model relationships in sentences or documents.
- Images: Store and process pixel values in 2D arrays.
- Videos and Beyond: Handle multi-dimensional data such as video frames.
Beyond deep learning, tensors find applications in physics, engineering, and other computational fields due to their ability to represent complex, multi-dimensional phenomena.
Matrix addition is an operations between two matrices which both are of the same order
Given two matrices:
and
The sum of
For the projection of these operations in code, you could use Python:
import numpy as np
A = np.array([[1, 2, 3], [4, 5, 6]])
B = np.array([[7, 8, 9], [10, 11, 12]])
result = A + BMatrix multiplication is characterized by several fundamental properties, each playing a role in the practical application of both linear algebra and machine learning.
The product
Matrix multiplication is associative, meaning that the order of multiplication remains consistent despite bracketing changes:
In general, matrix multiplication is not commutative:
This implies that, for matrices to be commutative, they must be square and diagonal.
Matrix multiplication distributes across addition and subtraction:
When a matrix is multiplied by an identity matrix
Multiplying any matrix by a zero matrix results in a zero matrix:
Assuming that an inverse exists,
For a product of matrices
The transpose of a matrix is generated by swapping its rows and columns. For any matrix
-
Self-Inverse:
$(\mathbf{A}^T)^T = \mathbf{A}$ -
Operation Consistency:
- For a constant
$c$ :$(c \mathbf{A})^T = c \mathbf{A}^T$ - For two conformable matrices
$\mathbf{A}$ and$\mathbf{B}$ :$(\mathbf{A} + \mathbf{B})^T = \mathbf{A}^T + \mathbf{B}^T$
- For a constant
Here is the Python code:
import numpy as np
# Create a sample matrix
A = np.array([[1, 2, 3], [4, 5, 6]])
print("Original Matrix A:\n", A)
# Transpose the matrix using NumPy
A_transpose = np.transpose(A) # or A.T
print("Transpose of A:\n", A_transpose)In machine learning, the dot product has numerous applications from basic data transformations to sophisticated algorithms like PCA and neural networks.
The dot product
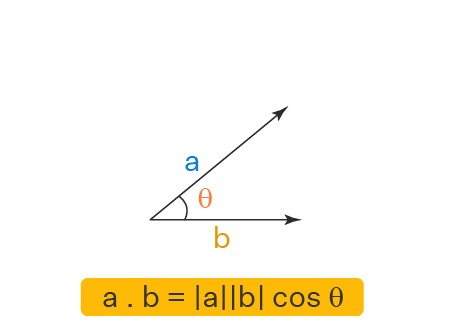
The norm or magnitude of a vector can be obtained from the dot product using:
This forms the basis for Euclidean distance and algorithms such as k-nearest neighbors.
The angle
The dot product is crucial for determining the projection of one vector onto another. It's used in tasks like feature extraction in PCA and in calculating gradient descent steps in optimization algorithms.
Here is the Python code:
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
dot_product = np.dot(a, b)
print("Dot Product:", dot_product)
# Alternatively, you can use the @ operator in recent versions of Python (3.5+)
dot_product_alt = a @ b
print("Dot Product (Alt):", dot_product_alt)The cross product is a well-known operation between two vectors in three-dimensional space. It results in a third vector that's orthogonal to both input vectors. The cross product is extensively used within various domains, including physics and computer graphics.
For two three-dimensional vectors and
, their cross product
is calculated as:
-
Direction: The cross product yields a vector that's mutually perpendicular to both input vectors. The direction, as given by the right-hand rule, indicates whether the resulting vector points "up" or "down" relative to the plane formed by the input vectors.
-
Magnitude: The magnitude of the cross product, denoted by
$\lvert \mathbf{a} \times \mathbf{b} \rvert$ , is the area of the parallelogram formed by the two input vectors.
The cross product is fundamental in many areas, including:
- Physics: It's used to determine torque, magnetic moments, and angular momentum.
- Engineering: It's essential in mechanics, fluid dynamics, and electric circuits.
- Computer Graphics: For tasks like calculating surface normals and implementing numerous 3D manipulations.
- Geography: It's utilized, alongside the dot product, for various mapping and navigational applications.
The vector norm quantifies the length or size of a vector. It's a fundamental concept in linear algebra, and has many applications in machine learning, optimization, and more.
The most common norm is the Euclidean norm or L2 norm, denoted as
Here is the Python code:
import numpy as np
vector = np.array([3, 4])
euclidean_norm = np.linalg.norm(vector)
print("Euclidean Norm:", euclidean_norm)- L1 Norm (Manhattan Norm): The sum of the absolute values of each component.
- L-Infinity Norm (Maximum Norm): The maximum absolute component value.
- L0 Pseudonorm: Represents the count of nonzero elements in the vector.
Here is the Python code:
L1_norm = np.linalg.norm(vector, 1)
L_infinity_norm = np.linalg.norm(vector, np.inf)
print("L1 Norm:", L1_norm)
print("L-Infinity Norm:", L_infinity_norm)It is worth to note that L2 is suitable for many mathematical operations like inner products and projections, that is why it is widely used in ML.
In linear algebra, vectors in a space can be defined by their direction and magnitude. Orthogonal vectors play a significant role in this framework, as they are perpendicular to one another.
In a real vector space, two vectors
This defines a geometric relationship between vectors as their dot product measures the projection of one vector onto the other.
For any two vectors
This relationship embodies the Pythagorean theorem: the sum of squares of the side lengths of a right-angled triangle is equal to the square of the length of the hypotenuse.
In terms of the dot product, this can be expressed as:
or
-
Geometry: Orthogonality defines perpendicularity in geometry.
-
Machine Learning: Orthogonal matrices are used in techniques like Principal Component Analysis (PCA) for dimensionality reduction and in whitening operations, which ensure zero covariances between variables.
-
Signal Processing: In digital filters and Fast Fourier Transforms (FFTs), orthogonal functions are used because their dot products are zero, making their projections independent.
Here is the Python code:
import numpy as np
# Initialize two vectors
v = np.array([3, 4])
w = np.array([-4, 3])
# Check orthogonality
if np.dot(v, w) == 0:
print("Vectors are orthogonal!")
else:
print("Vectors are not orthogonal.")The determinant of a matrix, denoted by
The determinant of a matrix possesses several key properties:
- Linearity: It's linear in each row and column when the rest are fixed.
- Factor Out: It's factored out if two rows (or columns) are added or subtracted, or a scalar is multiplied to a row (or column).
The Laplace expansion method and using the Eigendecomposition of matrices are two common approaches for computing the determinant.
The determinant of a matrix
Where
If matrix
Where
-
Orientation of Linear Transformations: The determinant of the matrix representation of a linear transformation indicates whether the transformation is orientation-preserving (positive determinant) or orientation-reversing (negative determinant), or if it is just a translation or a projection (determinant of zero).
-
Volume Scaling: The absolute value of the determinant represents the factor by which volumes are scaled when a linear transformation is applied. A determinant of 1 signifies no change in volume, while a determinant of 0 indicates a transformation that collapses the volume to zero.
-
Linear Independence and Invertibility: The existence of linearly independent rows or columns is captured by a non-zero determinant. If the determinant is zero, the matrix is singular and not invertible.
-
Conditioning in Optimization Problems: The determinant of the Hessian matrix, which is the matrix of second-order partial derivatives in optimization problems, provides insights into the local behavior of the objective function, helping to diagnose convergence issues and the geometry of the cost landscape.
Here is the Python code:
import numpy as np
# Create a random matrix
A = np.random.rand(3, 3)
# Compute the determinant
det_A = np.linalg.det(A)Eigenvectors and Eigenvalues have paramount significance in linear algebra and are fundamental to numerous algorithms, especially in fields like data science, physics, and engineering.
-
Eigenvalue: A scalar (represented by the Greek letter
$\lambda$ ) that indicates how the corresponding eigenvector is scaled by a linear transformation. -
Eigenvector: A non-zero vector (denoted as
$v$ ) that remains in the same span or direction during a linear transformation, except for a potential scaling factor indicated by its associated eigenvalue.
Let
More formally, for some scalar
In this context,
For a geometric perspective, consider a matrix
- The eigenvectors of
$A$ are unchanged in direction, except for potential scaling. - The eigenvalues determine the scaling factor.
In 3D or higher-dimensional spaces, the eigenvector description remains analogous.
Here is the Python code:
import numpy as np
# Define the matrix
A = np.array([[2, 1], [1, 3]])
# Calculate eigenvalues and eigenvectors
eigenvalues, eigenvectors = np.linalg.eig(A)
print("Eigenvalues:", eigenvalues)
print("Eigenvectors:", eigenvectors)- Principal Component Analysis (PCA): Eigenvalues and eigenvectors are pivotal for computing principal components, a technique used for feature reduction.
- Data Normalization: Eigenvectors provide directions along which data varies the most, influencing the choice of axes for normalization.
- Singular Value Decomposition (SVD): The guiding principle in SVD is akin to that in eigen-decomposition.
The trace of a square matrix, often denoted as
-
Linearity: For matrices
$\mathbf{A}, \mathbf{B},$ and scalar$k$ ,$\text{tr}(k \mathbf{A}) = k \text{tr}(\mathbf{A})$ and$\text{tr}(\mathbf{A} + \mathbf{B}) = \text{tr}(\mathbf{A}) + \text{tr}(\mathbf{B})$ . -
Cyclic Invariance: The trace of
$\mathbf{A} \mathbf{B} \mathbf{C}$ is equal to the trace of$\mathbf{B} \mathbf{C} \mathbf{A}$ . -
Transposition Invariance: The trace of a matrix is invariant under its transpose:
$\text{tr}(\mathbf{A}) = \text{tr}(\mathbf{A}^T)$ . -
Trace and Determinant: The trace of a matrix is related to its determinant via characteristic polynomials.
-
Trace and Eigenvalues: The trace is the sum of the eigenvalues. This can be shown by putting the matrix in Jordan form where the diagonal elements are the eigenvalues.
-
Orthogonal Matrices: For an orthogonal matrix,
$\text{tr}(\mathbf{S})$ equals the dimension of the matrix and$\det(\mathbf{S})$ takes the values$\pm 1$ .
A diagonal matrix is a structured linear operator seen in both applied and theoretical linear algebra. In this matrix, non-diagonal elements, which reside off the principal diagonal, are all zero.
A diagonal matrix
where
When a matrix is diagonal, matrix multiplication simplifies:
can be rewritten as:
This reduces to:
which is equivalent to the system of linear equations:
This is especially advantageous when matrix-vector multiplication can be efficiently computed using element-wise operations.
- Coordinate Transformation: Diagonal matrices facilitate transforming coordinates in a multi-dimensional space.
- Component-wise Operations: They allow for operations like scaling specific dimensions without affecting others.
You can use Python to demonstrate matrix-vector multiplication with a diagonal matrix:
import numpy as np
# Define a random diagonal matrix
D = np.array([
[2, 0, 0],
[0, 3, 0],
[0, 0, 5]
])
# Define a random vector
x = np.array([1, 2, 3])
# Compute the matrix-vector product
y = D.dot(x)
# Display the results
print("D:", D)
print("x:", x)
print("Dx:", y)Explore all 70 answers here 👉 Devinterview.io - Linear Algebra