- About The Project
- Business Objective
- Business Metrics
- Getting Started
- Data Workflow
- Conclusion
- Prediction using API and Streamlit

The aim of this project is to explore the application of machine learning models for predicting customer acquisition costs (CAC) and to investigate the effectiveness of feature selection techniques in improving the accuracy of these models.
Customer acquisition cost is a crucial metric for businesses, as it directly affects their profitability and marketing strategies. By accurately estimating CAC, companies can optimize their marketing budgets and make informed decisions to maximize return on investment (ROI).
Feature selection plays a vital role in building accurate regression models. It involves identifying the most informative features that have a significant impact on the target variable (CAC). By discarding irrelevant or redundant features, feature selection techniques can enhance the model's performance, reduce overfitting, and improve interpretability.
The research focuses on various feature selection methods, including but not limited to:
-
Univariate feature selection: This approach evaluates each feature independently based on statistical measures such as chi-square test, ANNOVA test, mutual information, or correlation with the target variable.
-
Embedded methods: These techniques incorporate feature selection within the model building process itself. For instance, Lasso regression performs feature selection and regularization simultaneously.
Customer Acquisition Cost (CAC): This metric represents the average cost a business incurs to acquire a new customer. It includes expenses related to marketing campaigns, advertising, sales efforts, and other customer acquisition activities.

The research goal is to investigate the application of machine learning regression models for predicting customer acquisition costs and evaluate the effectiveness of feature selection techniques in improving the accuracy of these models.
To evaluate the performance of a machine learning regression model for predicting customer acquisition costs (CAC), we can utilize the following metrics:
- Mean Squared Error (MSE): MSE measures the average squared difference between the predicted and actual CAC values. A lower MSE indicates better model performance, as it indicates that the model's predictions are closer to the actual values.
- Coefficient of Determination (R-squared or R2): R-squared measures the proportion of the variance in the CAC that can be explained by the regression model. It ranges from 0 to 1, with 1 indicating that the model perfectly predicts the CAC and 0 indicating that the model fails to explain any variance. A higher R-squared value signifies a better fit of the regression model to the CAC data.
SSR represents the sum of the squared differences between the predicted values (ŷ) and the actual values (y) of the dependent variable in a regression model.
SST represents the total sum of squares and quantifies the total variation in the dependent variable. It measures the squared differences between the actual values (y) and the mean of the dependent variable (ȳ)
- Clone the repository
git clone https://github.com/DandiMahendris/regression-model-cac`-
Install requirement library and package on
requirements.txt. -
If you want to create the folder instead
git init
echo "# MESSAGE" >> README.md
git add README.md
git commit -m "first commit" -
Remote the repository
git remote add origin git@github.com:DandiMahendris/regression-model-cac.git
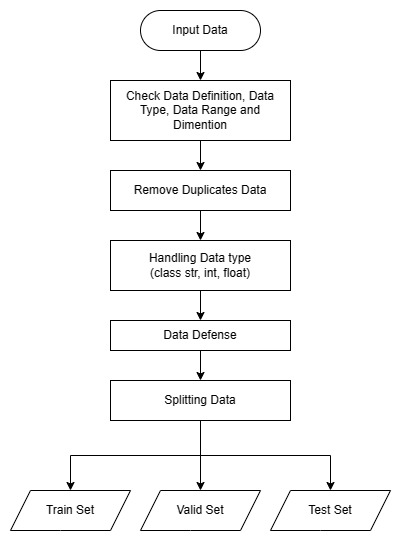
Dataset is collected and loaded from the directory. After obtaining the dataset, thoroughly examine the data definitions and data types of each feature, which could be categorized as strings, integers, floats, or objects.
To ensure data integrity and prevent any issues with data types or values that fall outside the acceptable range for the trained model, implement data defense mechanisms. This will involve incorporating code to raise a ValueError whenever an unmatched data type or a data value beyond the permissible range is encountered. By doing so, we can maintain the quality and reliability of the data used for training the model.

We will utilize the sklearn.model_selection.train_test_split function to divide the dataset into three distinct sets: training data, validation data, and testing data.
This function will allow us to split the dataset randomly while maintaining the proportions of the data, ensuring that each set is representative of the overall dataset.

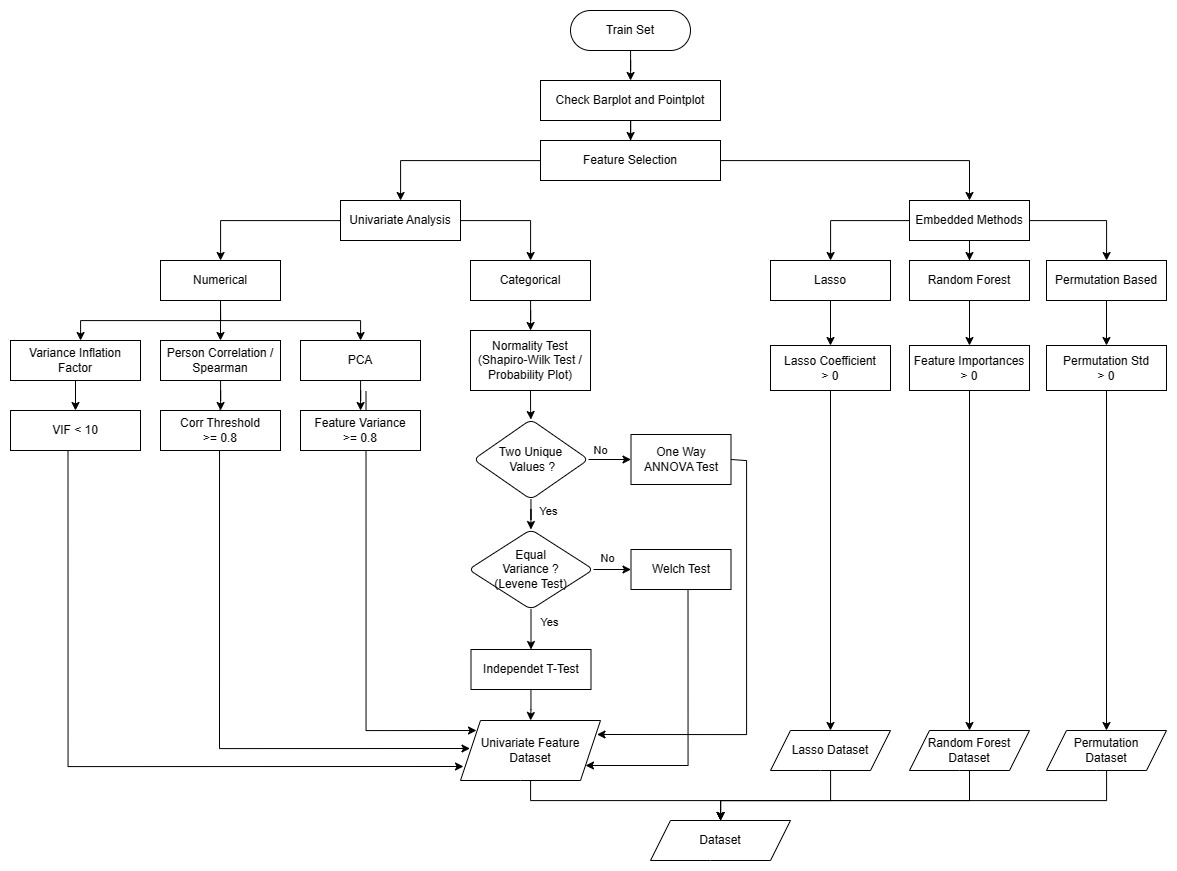
The given point plot illustrates the relationship between categorical features and the cost (label) data. Although some features appear to have similar means between categories, making it difficult to determine their impact on the label data at a population level, we can conduct statistical inference to gain a more detailed understanding.
To perform statistical inference, we can use techniques like Analysis of Variance (ANOVA) or t-tests for categorical variables. These methods will help us assess whether the means of the label data are significantly different across the categories of each categorical feature. Here's how we can proceed:

Formulate hypotheses:
- Null hypothesis (H0): There is no significant difference in the means of the label data between the categories of the categorical feature.
- Alternative hypothesis (H1): There is a significant difference in the means of the label data between at least two categories of the categorical feature.
Choose the appropriate statistical test:
- If you have only two categories within each feature, you can perform an independent two-sample t-test.
- If you have more than two categories within each feature, you can perform ANOVA followed by post hoc tests (e.g., Tukey's HSD test) to identify which specific categories differ significantly. Perform the statistical test and analyze the results:
Calculate the test statistic and p-value.
- If the p-value is below a predefined significance level (e.g., 0.05), we reject the null hypothesis and conclude that there is a significant difference in means between at least two categories.
- If the p-value is not below the significance level, we fail to reject the null hypothesis, indicating that there is no significant difference in means.
Interpret the findings:
- If the null hypothesis is rejected, it suggests that the categorical feature is indeed associated with the label data and may have an impact on the cost.
- If the null hypothesis is not rejected, it implies that the categorical feature may not be significantly related to the label data and may not play a significant role in determining the cost.

Shapiro-Wilk Test and Probability Plot
- The Shapiro-Wilk
H0 (null hypothesis) : the data was drawn from a normal distribution.
The Shapiro-Wilk test is a statistical test that evaluates whether the data is normally distributed. If the p-value resulting from the test is greater than the chosen significance level (commonly set at 0.05), we fail to reject the null hypothesis, indicating that the data is normally distributed. Conversely, if the p-value is less than the significance level, we reject the null hypothesis, suggesting that the data deviates from a normal distribution.
stats.shapiro(model.resid)Shapiro-Wilk Test Result:
ShapiroResult(statistic=0.9924623370170593, pvalue=1.1853023190337898e-40)
However the N > 5000, using probability plot
- Probability Plot
Probability plots, like Q-Q plots (Quantile-Quantile plots), compare the observed data against the expected values from a theoretical normal distribution.
normality_plot, stat = stats.probplot(model.resid, plot= plt, rvalue= True)

PPCC shown as R2, if R2 is nearly 1 it shown distribution is uniform
PPCC stands for Probability Plot Correlation Coefficient. PPCC is a measure used to assess the goodness-of-fit of a given probability distribution to a dataset. It quantifies the degree of linear association between the observed data and the theoretical values expected from the specified distribution.
A high PPCC value (close to 1) suggests that the data follows the specified distribution well, while a low PPCC value (close to -1) indicates significant deviations. Other techniques, such as visual inspection or statistical tests like the Kolmogorov-Smirnov test or Anderson-Darling test
To evaluate homogeneity of variance, we can use statistical tests like Levene's test. Levene's test assesses whether the variance of the data significantly differs among the groups defined by the categorical features.
If the test's p-value is above the significance level, we can assume homogeneity of variance. However, if the p-value is below the significance level, it suggests that the variance is not uniform across the groups.
If assumption violated we can used another non-parametric statistical test such as
Welch's ANOVA, Kruskal-Wallis H
Level of significance = α
A one-way ANOVA has the below given null and alternative hypotheses:
- H0 (null hypothesis):
μ1 = μ2 = μ3 = … = μk (It implies that the means of all the population are equal) - H1 (alternative hypothesis):
It states that there will be at least one population mean that differs from the rest
# lst_cate_bool = all more than two-group features
for i,col in enumerate(lst_cate_column):
model = ols(f'cost ~ C({col})', data=train_set[lst_cate_column]).fit()
aov_table = sm.stats.anova_lm(model, typ=2)
model_anova[col] = aov_table['PR(>F)']
model_anova_ = (pd.DataFrame(
data=model_anova.copy(),
columns=lst_cate_column,
)
.melt(var_name='columns', value_name='PR(>F)')
.sort_values(by=['columns'])
.drop_duplicates()
.dropna()
)
model_anova_[model_anova_['PR(>F)'] > 0.05]['columns'].values.tolist()If PR(>F) > 0.05 : Failed to Reject H0, that states no significant different mean between independent groups
# lst_cate_bool = all two-groups features
for col in lst_cate_bool:
levene = stats.levene(train_set['cost'][train_set[col]==1],
train_set['cost'][train_set[col]==0])
print(f'Levene of {col} : \n {levene}')The Levene test examines the H0 (null hypothesis) that all input samples originate from populations with equal variances.
The test results in a non-significant p-value (huge p-value), indicating a lack of evidence to reject the null hypothesis.
Therefore, we conclude that there is homogeneity of variances among the samples, allowing us to proceed with further analysis.
e.g.
Levene of marital_status:
LeveneResult(statistic=0.34138308811262486, pvalue=0.5590350792841461)
Levene of gender:
LeveneResult(statistic=0.740265911515631, pvalue=0.38958058725529066)
Levene of houseowner:
LeveneResult(statistic=3.2592825784464243, pvalue=0.07102729946524858)
Equal Variance would perform Independence T-Test.
Non-Equal Variance would perform Welch's Test.
H0 : There's no difference mean between var1 and var2,
H1 : There's difference mean between var1 and var2,
H₀ : μ₁ = μ₂
H₁ : μ₁ ≠ μ₂
`Independence T-test` used Two-sided alternative with equal_var = True,
while `Welch's Test` used Two-sided alternative with equal_var = False
degree = list_0.count() + list_1.count()
t_stat, p_value = ttest_ind(list_0, list_1, equal_var=True, alternative="two-sided")
t_crit = scipy.stats.t.ppf(alpha * 0.5, degree)

All variable on Equal Variance is Failed to Reject H0, then these variable is not statistically significant since mean between group is same
degree = list_0.count() + list_1.count()
t_stat, p_value = ttest_ind(list_0, list_1, equal_var=False)
t_crit = scipy.stats.t.ppf(alpha*0.5, degree)

Non-Equal variance group show Reject H0, then these vairables is statistically significant

Quantitative variable selection aim to drop multicollinearity of variable.
Multicollinearity occurs when two or more independent variables(also known as predictor) are highly correlated with one another in a regression model
This means that an independent variable can be predicted from another independent variable in a regression model.
Since in a regression model our research objective is to find out how each predictor is impacting the target variable individually,
Y = a0 + a1 X1 + a2 X2
Here X1 and X2 are the independent variables. But for a situation where multicollinearity exists our independent variables are highly correlated, so if we change X1 then X2 also changes and we would not be able to see their Individual effect on Y which is our research objective for a regression model.
“ This makes the effects of X1 on Y difficult to differentiate from the effects of X2 on Y. ”
Multicollinearity may not affect the accuracy of the model as much but we might lose reliability in determining the effects of individual independent features on the dependent feature in your model and that can be a problem when we want to interpret your model.

To handle redundancy of between variable, we can drop variable with high correlation score of pearson correlation.
Collinearity is the state where two variables are highly correlated and contain similar information about the variance within a given dataset.
To detect collinearity among variables, simply create a correlation matrix and find variables with large absolute values.
Kutner, Nachtsheim, Neter, and Li (2004) suggest to use a VIF ≥ 10 as indication of multicollinearity
def cal_vif(X):
thresh = 10
output = pd.DataFrame()
k = X.shape[1]
vif = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
for i in range(1,k):
print("iteration no ", i)
print(vif)
a = np.argmax(vif)
print('Max vif is for variable no: ', a)
if(vif[a]<=thresh):
break
if(i==1):
output = X.drop(X.columns[a], axis=1)
vif = [variance_inflation_factor(output.values, j) for j in range(output.shape[1])]
elif(i>1):
output = output.drop(output.columns[a], axis=1)
vif = [variance_inflation_factor(output.values, j) for j in range(output.shape[1])]
return(output)
vif_features = cal_vif(X_vif)
vif_features.head()Regularization methods are the most commonly used embedded methods which penalize a feature given a coefficient threshold. Here we will do feature selection using Lasso regularization.
If the feature is irrelevant, lasso penalizes its coefficient and make it 0. Hence the features with coefficient = 0 are removed and the rest are taken.
lasso_cv = LassoCV()
# Fit into train_set after StandardScaler
lasso_cv.fit(train_scaled.drop(columns=config_data['label'],axis=1),
train_scaled[config_data['label']])
coef = pd.Series(lasso_cv.coef_, index = train_set[train_scaled.drop(columns=config_data['label'],axis=1).columns.to_list()].columns)
imp_coef = coef.sort_values(ascending=False)
import matplotlib
matplotlib.rcParams['figure.figsize'] = (8.0, 10.0)
imp_coef.plot(kind='barh')

- Gini Importance (or mean decrease impurity)
The features for internal nodes on each Decision Tree are selected with some criterion, which for classification tasks can be gini impurity or infomation gain, and for regression is variance reduction.
We can measure how each feature decrease the impurity of the split (the feature with highest decrease is selected for internal node).
For each feature we can collect how on average it decreases the impurity. The average over all trees in the forest is the measure of the feature importance.
- Mean Decrease Accuracy
is a method of computing the feature importance on permuted out-of-bag (OOB) samples based on mean decrease in the accuracy.
rf = RandomForestRegressor()
rf.fit(train_scaled.drop(columns=config_data['label'],axis=1), train_scaled[config_data['label']])
rf.feature_importances_

The main idea behind this method is to assess the impact of each feature on the model's performance by randomly permuting the values of that feature while keeping other features unchanged. By comparing the model's performance on the original data with the performance on permuted data, we can determine how much each feature contributes to the model's predictive power.
perm_importance = permutation_importance(rf, train_scaled[predictor], train_scaled[config_data['label']])
sorted_index = perm_importance.importances_std.argsort()

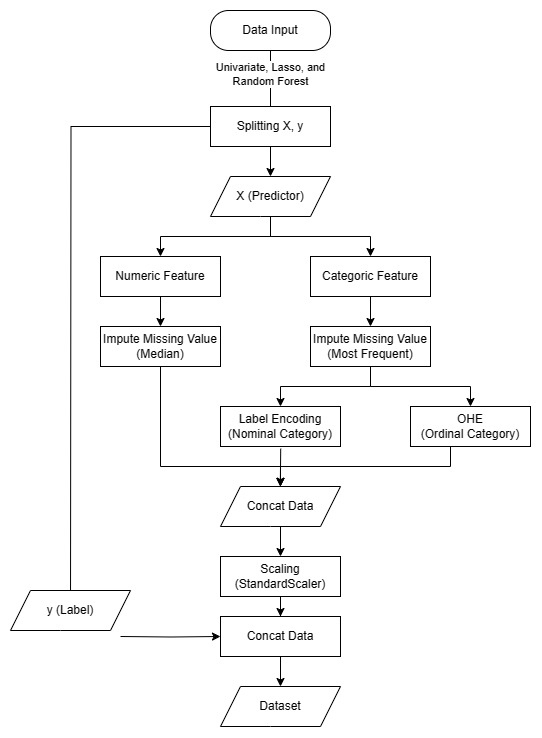
In the data preprocessing step, I employed several essential tools from the scikit-learn library to handle missing values, encode categorical variables, and scale numerical features for optimal model performance.
Firstly, I utilized sklearn.impute.SimpleImputer to address missing data in the dataset. This module allowed me to replace missing values with appropriate measures such as the mean, median, or most frequent value from the respective feature.
By doing so, I ensured that the model training process was not hindered by incomplete data, resulting in more reliable and accurate predictions.
imputer = SimpleImputer(missing_values=np.nan,
strategy='median')
imputer.fit(data)
data_imputed_num = pd.DataFrame(imputer.transform(data),
index = data.index,
columns = data.columns)To handle categorical variables, I applied two techniques sequentially: sklearn.preprocessing.LabelEncoder and sklearn.preprocessing.OneHotEncoder. Using LabelEncoder, I converted categorical variables into numerical labels, effectively transforming them into a format that machine learning algorithms can process.
Subsequently, I employed OneHotEncoder to create binary dummy variables for each category. This process is vital for avoiding any ordinal relationship assumptions between categories and enabling the model to interpret the categorical data correctly.
# One Hot Encoding
encoder = OneHotEncoder(handle_unknown= 'ignore',
drop = 'if_binary')
encoder.fit(data)
encoder_col = encoder.get_feature_names_out(data.columns)
data_encoded = encoder.transform(data).toarray()
data_encoded = pd.DataFrame(data_encoded,
index=data.index,
columns=encoder_col)
# Label Encoding
for col in data.columns.to_list():
data[col] = le_encoder.fit_transform(data[col])Finally, I utilized sklearn.preprocessing.StandardScaler to standardize the numerical features. Standardization involves transforming numerical data to have a mean of 0 and a standard deviation of 1. This scaling technique ensures that all numerical features contribute equally to the model, preventing features with larger scales from dominating the learning process.
scaler = StandardScaler()
scaler.fit(data)
data_scaled = pd.DataFrame(scaler.transform(data),
index=data.index,
columns=data.columns)
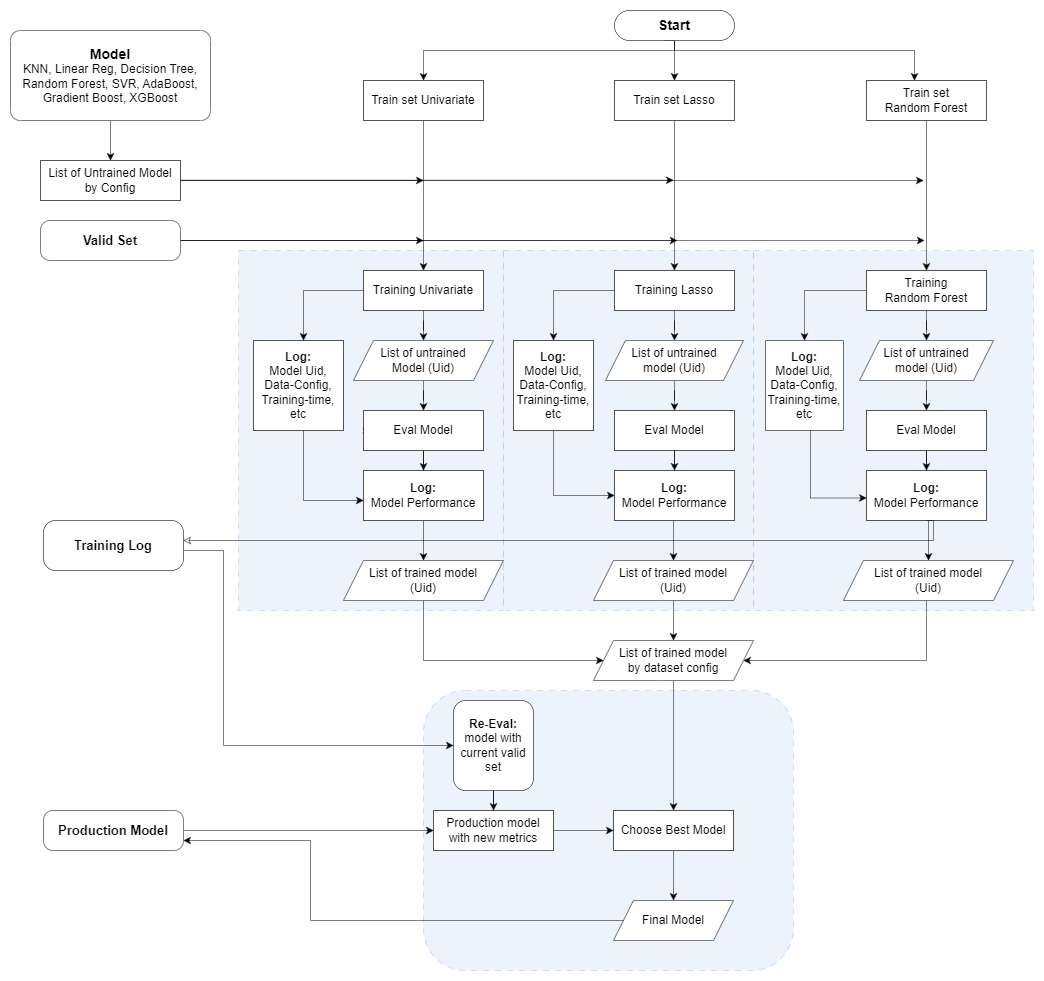
In our comparison of three feature selection methods (Training set Univariate, Training set of Lasso, and Training set of Random Forest), we aim to assess their impact on the model's performance in predicting the Customer Acquisition Cost (CAC). To achieve this, we will employ two key metrics, Mean Squared Error (MSE) and Coefficient of Determination (R^2), to evaluate the models' effectiveness.
Firstly, we will create a training log template to store the details of untrained models from various Sklearn methods. The list of methods includes K-Nearest Neighbors (KNN), Linear Regression, Decision Tree, Random Forest, Support Vector Regression (SVR), AdaBoost, Gradient Boost, and XGBoost. Each untrained model will be assigned a unique identifier (Uid) in the training log.
The model's performance will be evaluated based on three criteria: the lowest Mean Squared Error (indicating better accuracy), the highest R^2 (indicating better explanatory power), and the fastest training time (for efficiency). We will train each model configuration using the three feature selection methods, and the corresponding evaluation scores will be recorded in the Training log along with their Uids.
By examining the validation set data, we will determine the best-performing model and store its results in our directory as the final model. This best model will represent the most effective combination of feature selection method and Sklearn algorithm for predicting the CAC with optimal accuracy, interpretability, and efficiency.

Based on the baseline model evaluation, the Filter method applied on Random Forest Regression appears to be the best model.
However, it is worth noting that this model takes more time for predictions. If training time is a significant consideration, alternative methods such as Lasso Method on Decision Tree Regression or XGBoost Regressor could be viable options.
It is important to mention that Decision Tree Regression may result in a high variance model, potentially leading to overfitting. To assess the model's performance on the test set, further evaluation should be conducted. Nevertheless, Decision Tree models are relatively easier to interpret due to their inherent structure.
On the other hand, if the objective is to minimize error within a shorter amount of time, XGBoost Regression is the recommended choice. However, it is worth noting that XGBoost models are generally more complex and can be more challenging to interpret.
Ultimately, the choice of the model depends on the specific requirements and trade-offs between factors such as accuracy, interpretability, training time, and ease of use.
CVS is performed to understand the distribution of data that we can be sure out model generalises well accross the whole dataset and not just a single portion.
How do we now that single dataset is representative?
Cross Val Score train and test our model on multiple folds and give a better understanding of model performance over the whole dataset instead of just a single train/test split.
If we see that the metrics for all folds cvs are significant differences between them then this may indicate over-fitting to certain folds.

neg_mean_squared_error always return negative (-), it because cross_val_score function will return maximize value as sign higher is better, the cross_val_score will turn it into negative (-). Hence, cross_val_score will return the smaller value.
e.g.
MSE Score 5 is better than 9.
Cross val score will return the higher which is 9.
As of that, cross_val_score function will turn it into -5 and -9, and
cross_val_score will return -5 as the higher value.
Since our baseline model has been fitted and shows good performance in terms of Mean Squared Error and R^2 Score, it becomes a viable option to perform hyperparameter tuning, especially for the top three machine learning methods.
For the Decision Tree method, we can fine-tune the min_samples_split, min_samples_leaf, and max_depth hyperparameters. Adjusting these parameters can help us achieve even lower Mean Squared Error while maintaining reasonable training time. A lower value for min_samples_split and min_samples_leaf can lead to more complex trees, while controlling the max_depth can prevent overfitting and improve generalization.
In the case of the Random Forest method, we can focus on maximizing the n_estimators, as increasing the number of estimators can reduce the variance and lead to a more stable model. Additionally, tuning the max_depth and min_samples_split hyperparameters for each tree can further optimize the model's performance by controlling the depth of individual trees and promoting better splits.
As for the XGBoost method, we have several important hyperparameters to adjust. Setting a lower value for eta (learning rate) can slow down the learning process, but it may result in more accurate and robust predictions. Adjusting the lambda hyperparameter, which represents L2 regularization, helps prevent feature coefficients from approaching zero, promoting a more robust and stable model. Finally, tuning the max_depth parameter can control the depth of the decision trees within the ensemble, balancing the model's complexity and preventing overfitting.
After selecting the best model based on its performance on the validation dataset, the final model is tested on a completely independent test dataset. The test dataset acts as a final evaluation to verify the model's ability to generalize to new, real-world data and provides a final performance estimation.

Best model performance based on validation data is Random Forest Regressor on Filter Data Configuration,
Show up with MSE Score = 1.023 and R2_Score = 0.998
However, it defent on training time: 47.97s
If you prefer more fast training time with nearly score, you can choose:
Random Forest Regressor on Lasso Data Configuration
The observed phenomenon where the best model performance is achieved with univariate analysis and the Lasso method, while Random Forest performs poorly, can be attributed to the following factors:
-
Relevance of Features: Univariate analysis and the Lasso method focus on selecting the most relevant features for the prediction task. These methods help in identifying the features that have a strong impact on the target variable (CAC) and are directly associated with the outcome. In contrast, Random Forest tends to consider a larger number of features, including some less relevant or noisy ones. If the dataset contains many irrelevant features, Random Forest might struggle to distinguish them, leading to poorer performance compared to more focused feature selection methods like univariate analysis and Lasso.
-
Overfitting: Random Forest is an ensemble method that builds multiple decision trees and combines their predictions. While it generally has good performance, there is a possibility of overfitting when the model is too complex or when the number of trees
(n_estimators)is too high.
XGBoost is known for its ability to handle complex, high-dimensional datasets and perform well on a wide range of problems. For instance, if the data exhibits non-linear relationships or high multicollinearity, XGBoost's ability to capture complex interactions between features could give it an advantage over simpler models like Random Forest and Decision Tree. The success of XGBoost might also be attributed to the effectiveness of feature engineering.
Regarding the Random Forest dataset generated from Random Forest feature importance yielding poor performance in its own method, it is possible that the importance scores from one Random Forest model might not be transferable to another Random Forest trained on the same data. The importance scores are specific to each Random Forest instance, and factors such as the number of trees, hyperparameters, and random seed can affect the importance rankings. As a result, using feature importance scores from one model to select features for another Random Forest might not yield the best results.
In summary, the performance differences observed between different feature selection methods and machine learning models can be attributed to the complexity of the data, relevance of features, potential overfitting, hyperparameter tuning, and the unique characteristics of each model and method. It is essential to carefully consider these factors and experiment with various approaches to identify the best combination of feature selection and machine learning methods that yield the optimal performance for predicting CAC.
- Open a
Command PromptorPowerShellterminal and navigate to the folder's directory. Try to test API by following the code:
$ python .\src\api.py

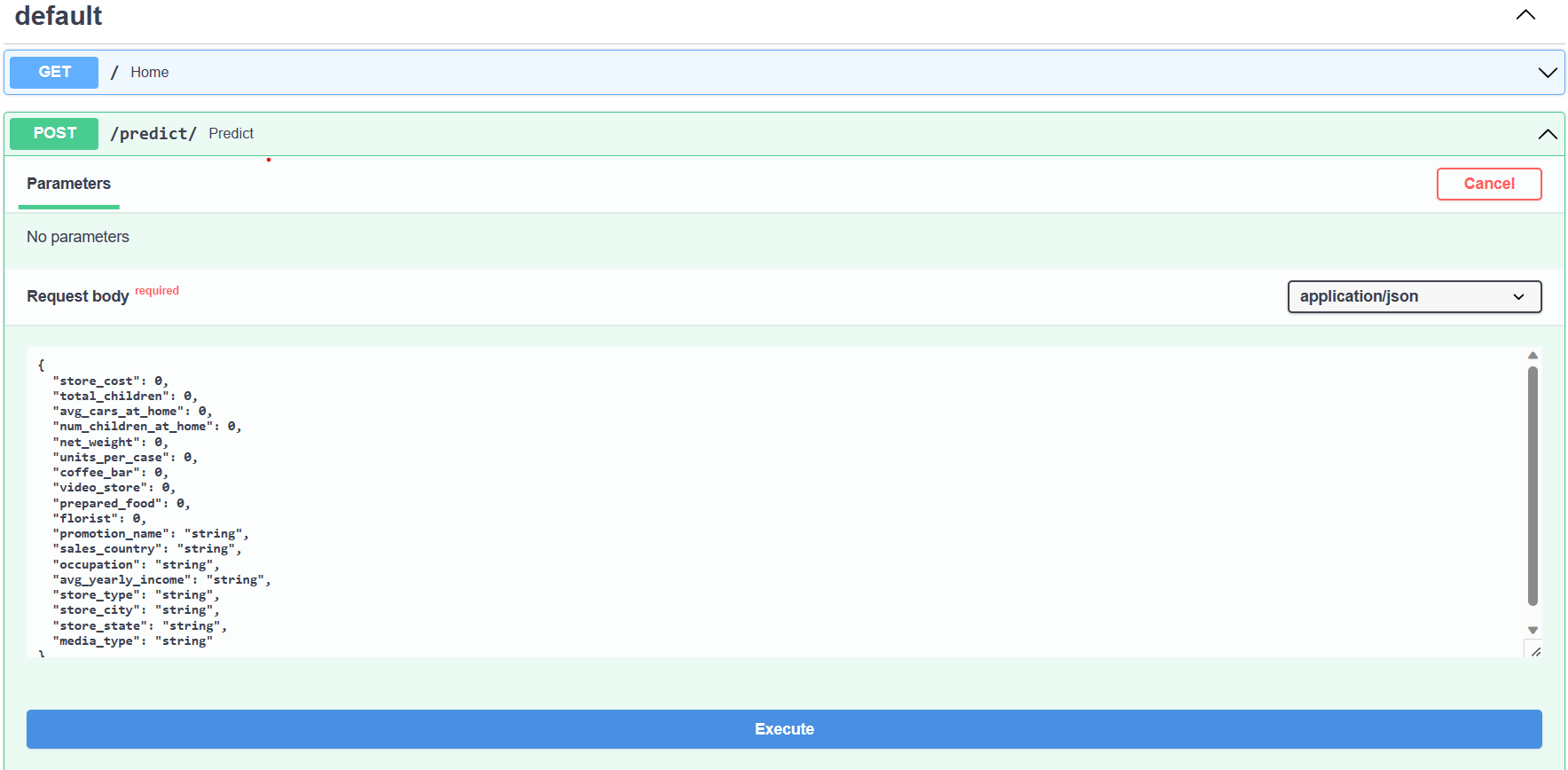
- To try streamlit. Open CMD terminal and type the code:
$ streamlit run .\src\streamlit.py

Numerical Data:
| Store_cost | total_children | avg_cars_at_home | num_children_at_home | net_weight | units_per_case | coffee_bar | video_store | prepared_food | florist | |
|---|---|---|---|---|---|---|---|---|---|---|
| Type | float | float | float | float | float | float | float | float | float | float |
| Data Range | 1700k - 97000k | 0-5 | 0-4 | 0-5 | 3-21 | 1-36 | 0-1 | 0-1 | 0-1 | 0-1 |
Categorical Data:
| promotion_name | sales_country | occupation | avg_yearly_income | store_type | store_city | store_city | media_type | |
|---|---|---|---|---|---|---|---|---|
| Type | Object | Object | Object | Object | Object | Object | Object | Object |