Create ETL and Data warehouse on AWS.
Report Bug
·
Request Feature
Table of Contents
A music streaming startup, Sparkify, has grown their user base and song database and want to move their processes and data onto the cloud. Their data resides in S3, in a directory of JSON logs on user activity on the app, as well as a directory with JSON metadata on the songs in their app.
As their data engineer, you are tasked with building an ETL pipeline that extracts their data from S3, stages them in Redshift, and transforms data into a set of dimensional tables for their analytics team to continue finding insights in what songs their users are listening to. You'll be able to test your database and ETL pipeline by running queries given to you by the analytics team from Sparkify and compare your results with their expected results.
There are two datasets that reside in S3. Here are the S3 links for each:
Song data:
s3://udacity-dend/song_data
Log data:
s3://udacity-dend/log_data
Log data json path:
s3://udacity-dend/log_json_path.json
The first dataset is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song's track ID. For example, here are filepaths to two files in this dataset.
song_data/A/B/C/TRABCEI128F424C983.json
song_data/A/A/B/TRAABJL12903CDCF1A.json
And below is an example of what a single song file, TRAABJL12903CDCF1A.json, looks like.
{"num_songs": 1, "artist_id": "ARJIE2Y1187B994AB7", "artist_latitude": null, "artist_longitude": null, "artist_location": "", "artist_name": "Line Renaud", "song_id": "SOUPIRU12A6D4FA1E1", "title": "Der Kleine Dompfaff", "duration": 152.92036, "year": 0}
The second dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate activity logs from a music streaming app based on specified configurations.
The log files in the dataset you'll be working with are partitioned by year and month. For example, here are filepaths to two files in this dataset.
log_data/2018/11/2018-11-12-events.json
log_data/2018/11/2018-11-13-events.json
And below is an example of what the data in a log file, 2018-11-12-events.json, looks like.
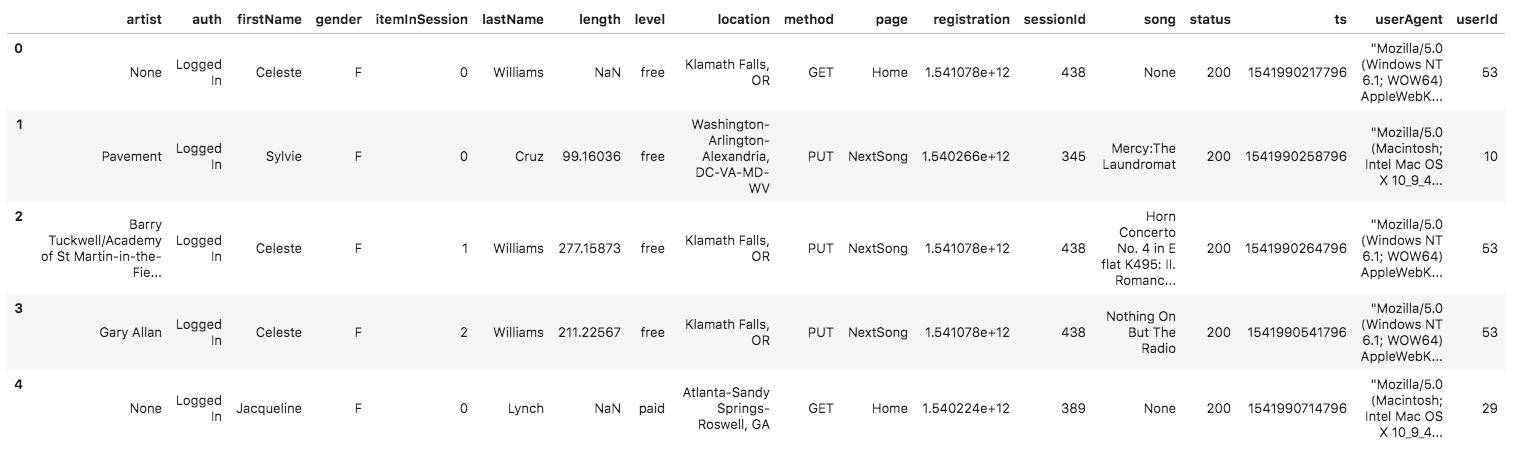
This is my database Star Schema.

install package with
pip install -r requirements.txt
create config files for access AWS
infra.cfg :
[AWS]
KEY = ? // AWS IAM User Key
SECRET = ? // AWS IAM User Secret[DWH]
DWH_CLUSTER_TYPE =multi-node
DWH_NUM_NODES =4
DWH_NODE_TYPE=dc2.largeDWH_IAM_ROLE_NAME = ? // Define IAM Role Name
DWH_CLUSTER_IDENTIFIER = ? // Define Cluster Name
DWH_DB = ? // Define DB Name
DWH_DB_USER = ? // Define DB Username
DWH_DB_PASSWORD = ? // Define DB Password
DWH_PORT = 5439
dwh.cfg :
[CLUSTER]
HOST =
DB_NAME =
DB_USER =
DB_PASSWORD =
DB_PORT =[IAM_ROLE]
ARN =[S3]
LOG_DATA = ? // Define event logs data path to S3
LOG_JSONPATH = ? // Define event logs json path data path to S3
SONG_DATA = ? // Define songs data path to S3
python create_infras.py
python create_tables.py
python etl.py
run script in test_queries.ipynb
- SELECT * FROM songplays LIMIT 5;

- SELECT * FROM users LIMIT 5;

- SELECT * FROM songs LIMIT 5;

- SELECT * FROM artists LIMIT 5;

- SELECT * FROM times LIMIT 5;

- SELECT u.firstName + ' ' + u.lastName as fullName,
a.name as artist_name,
s.title as song_title,
t.day::VARCHAR + '-' + t.month::VARCHAR + '-' + t.year::VARCHAR + ' ' + t.hour::VARCHAR + ':00' as date
FROM songplays sp
JOIN users u on sp.user_id = u.user_id
JOIN artists a on sp.artist_id = a.artist_id
JOIN songs s on sp.song_id = s.song_id
JOIN times t on sp.start_time = t.start_time







delete all infrastructures on AWS
python delete_infras.py
print all errors
python stl_load_errors.py
Facebook - @Natchapol Patamawisut
Project Link: https://github.com/BankNatchapol/AWS-Data-Warehouse-ETL