- Python replication of all the plots from Reinforcement Learning: An Introduction
- Solution for all of the exercises
- Anki flashcards summary of the book
To reproduce a figure, say figure 2.2, do:
cd chapter2
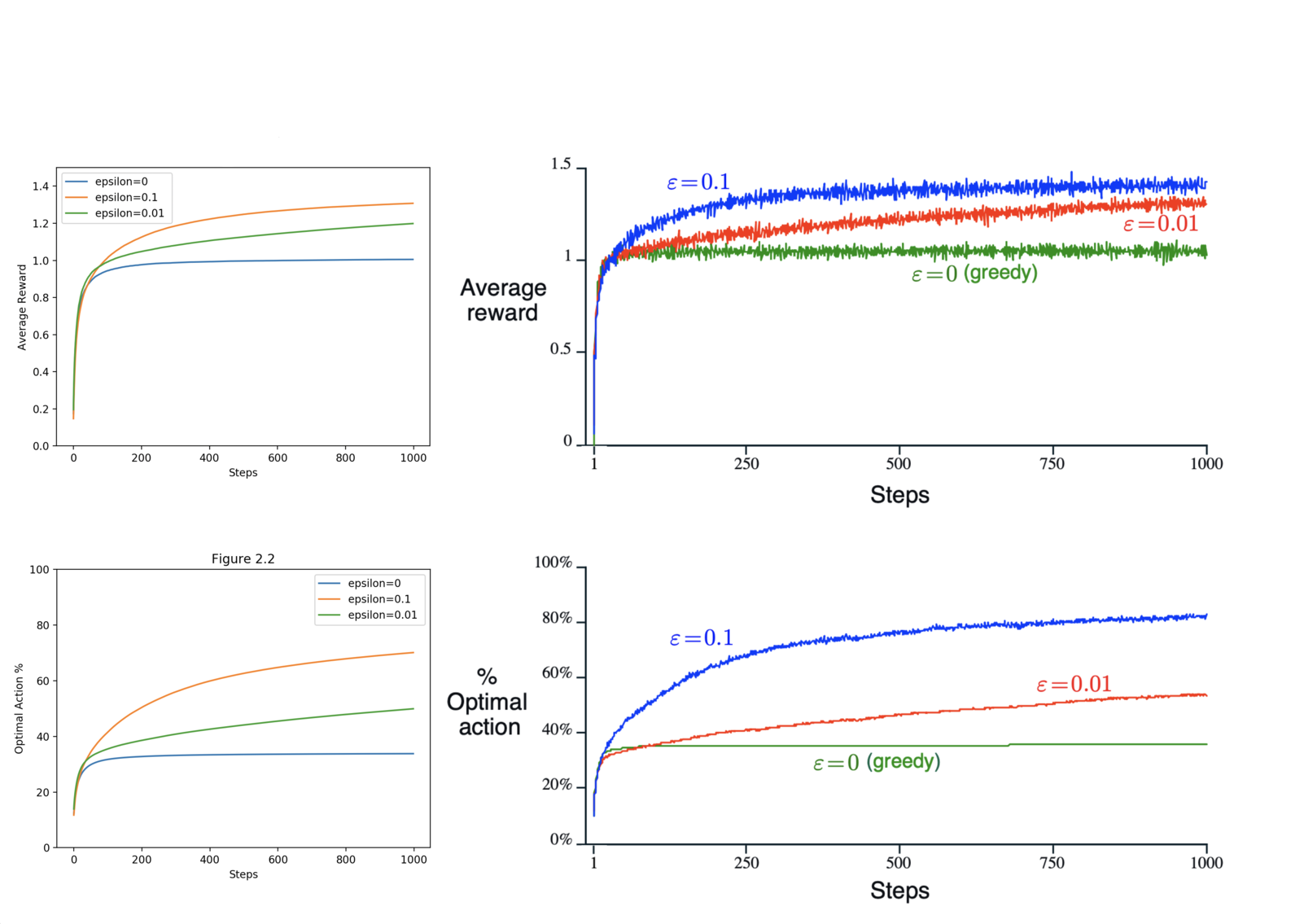
python figures.py 2.2- Figure 2.2: Average performance of epsilon-greedy action-value methods on the 10-armed testbed
- Figure 2.3: Optimistic initial action-value estimates
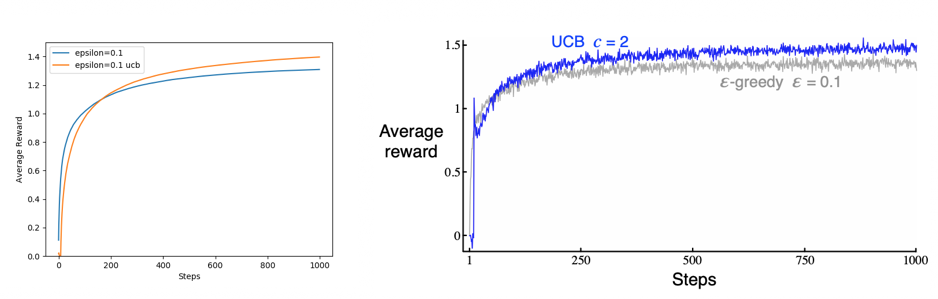
- Figure 2.4: Average performance of UCB action selection on the 10-armed testbed
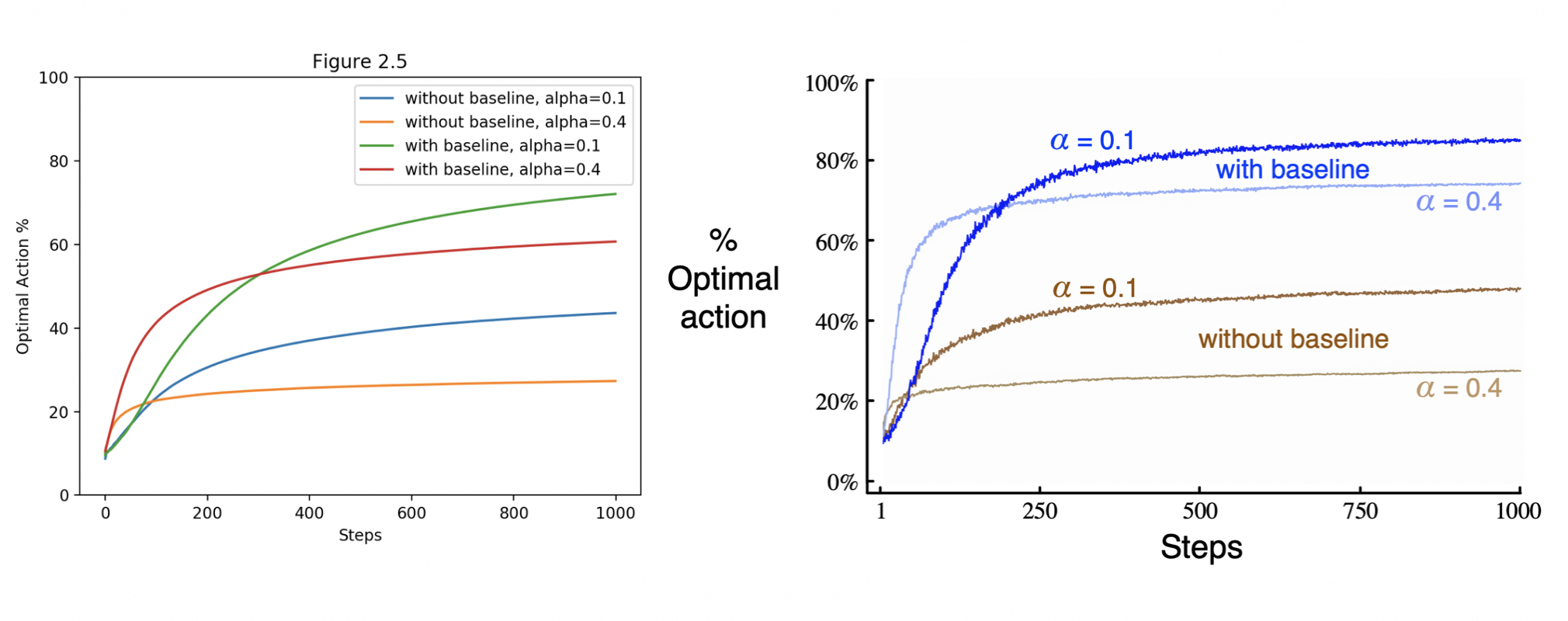
- Figure 2.5: Average performance of the gradient bandit algorithm
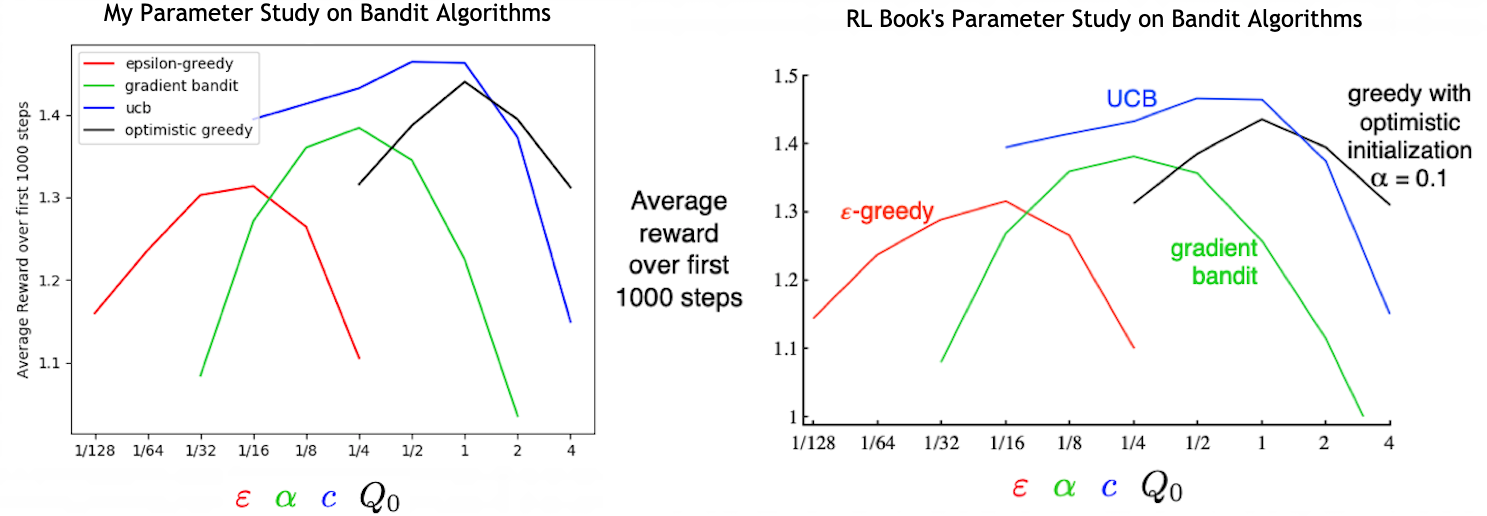
- Figure 2.6: A parameter study of the various bandit algorithms
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
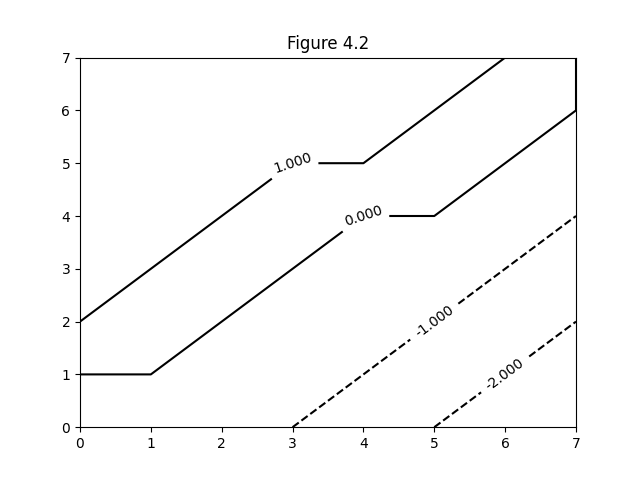
- Figure 4.2: Jack’s car rental problem (value function, policy)
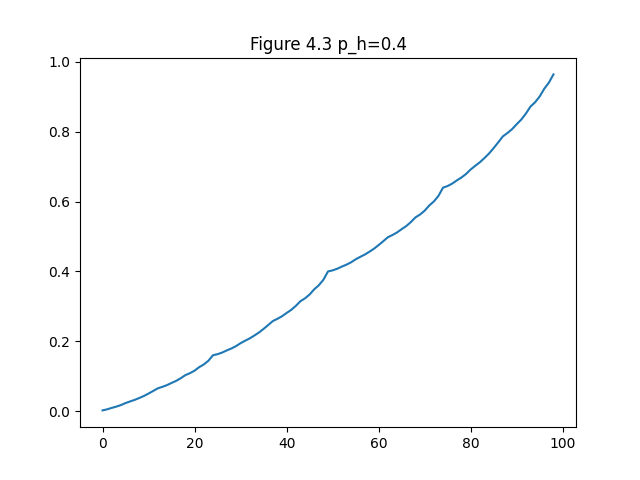
- Figure 4.3: The solution to the gambler’s problem (value function, policy)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
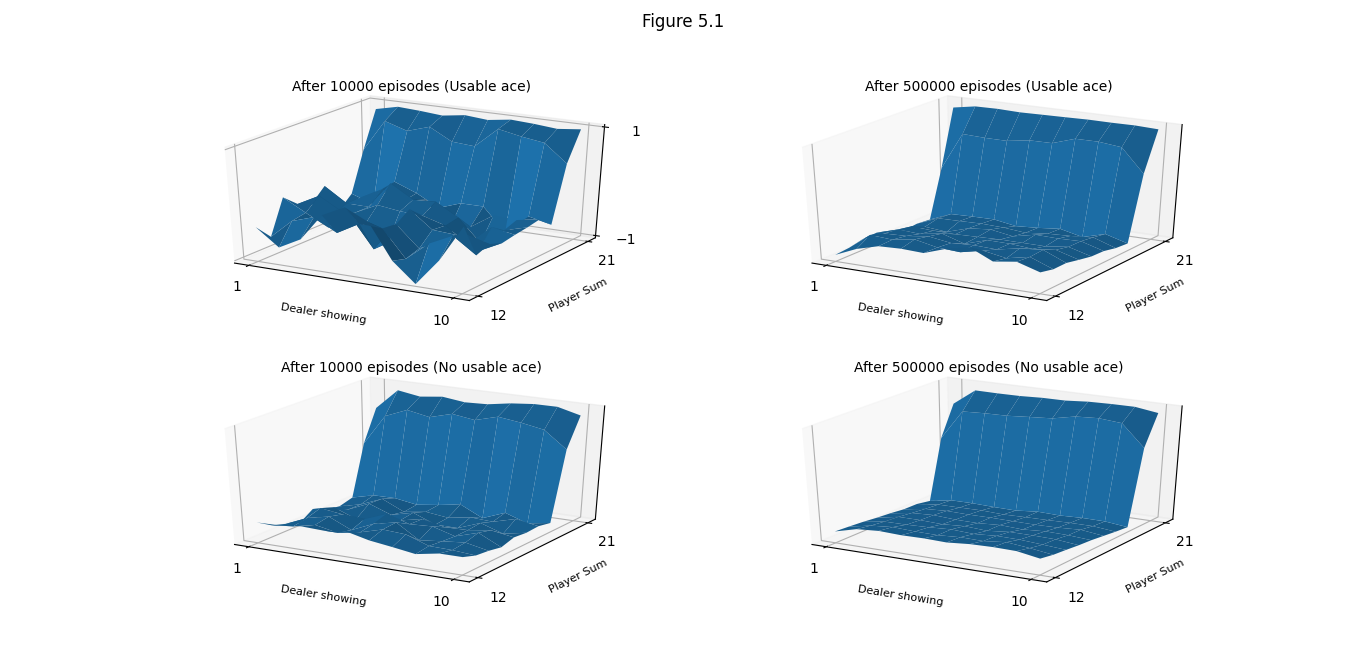
- Figure 5.1: Approximate state-value functions for the blackjack policy
- Figure 5.2: The optimal policy and state-value function for blackjack found by Monte Carlo ES
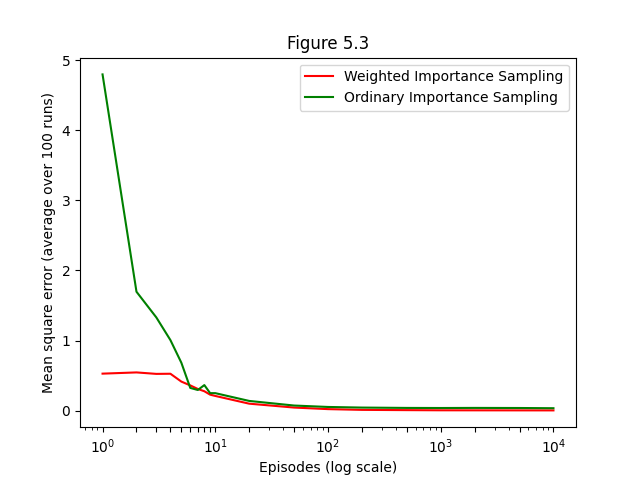
- Figure 5.3: Weighted importance sampling
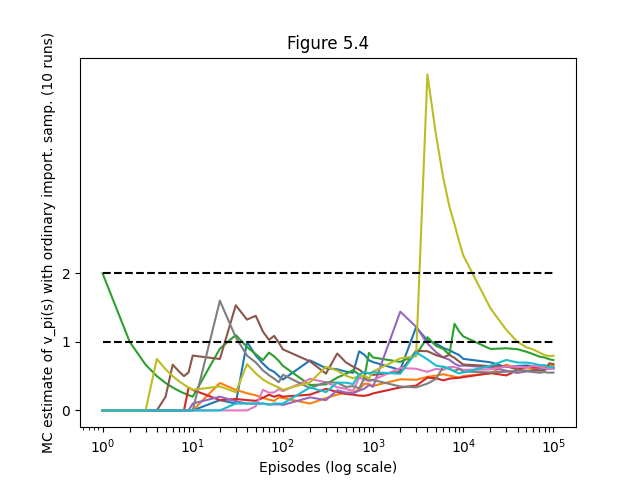
- Figure 5.4: Ordinary importance sampling with surprisingly unstable estimates
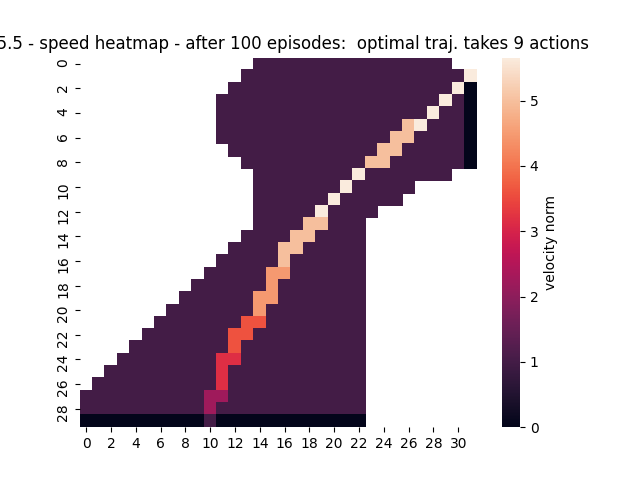
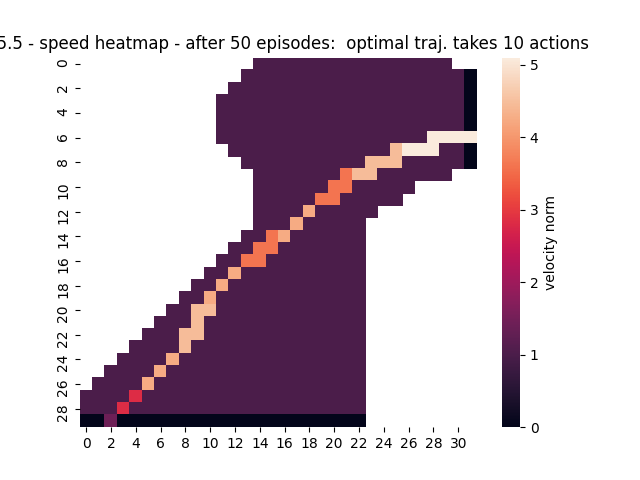
- Figure 5.5: A couple of right turns for the racetrack task (1, 2, 3)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
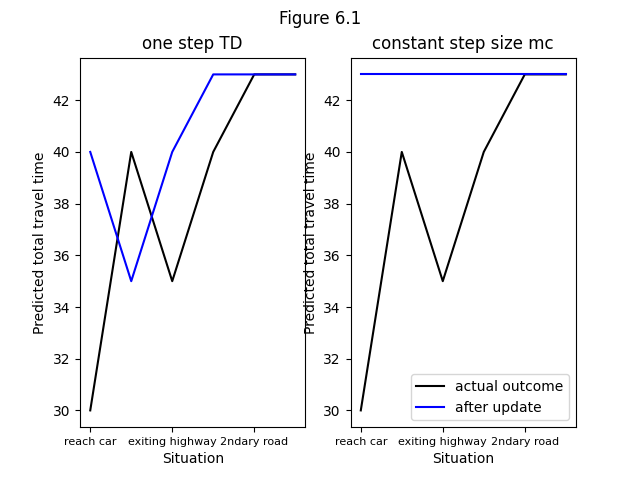
- Figure 6.1: Changes recommended in the driving home example by Monte Carlo methods (left) and TD methods (right)
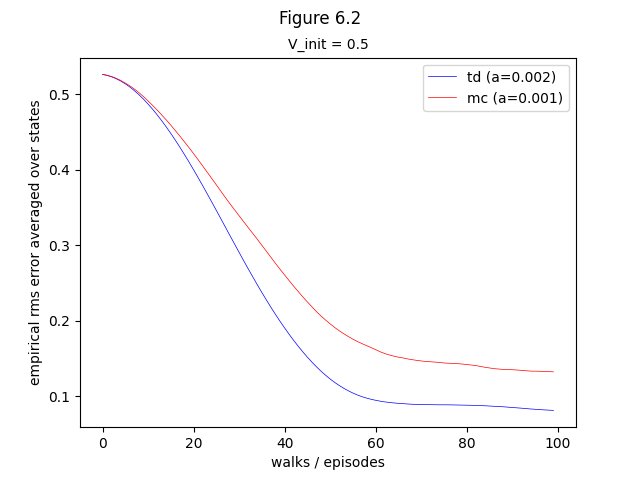
- Example 6.2: Random walk (comparison)
- Figure 6.2: Performance of TD(0) and constant MC under batch training on the random walk task
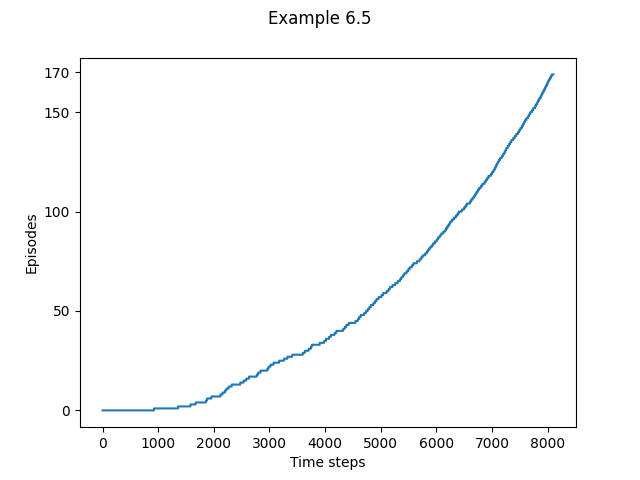
- Example 6.5: Windy Gridworld
- Example 6.6: Cliff Walking
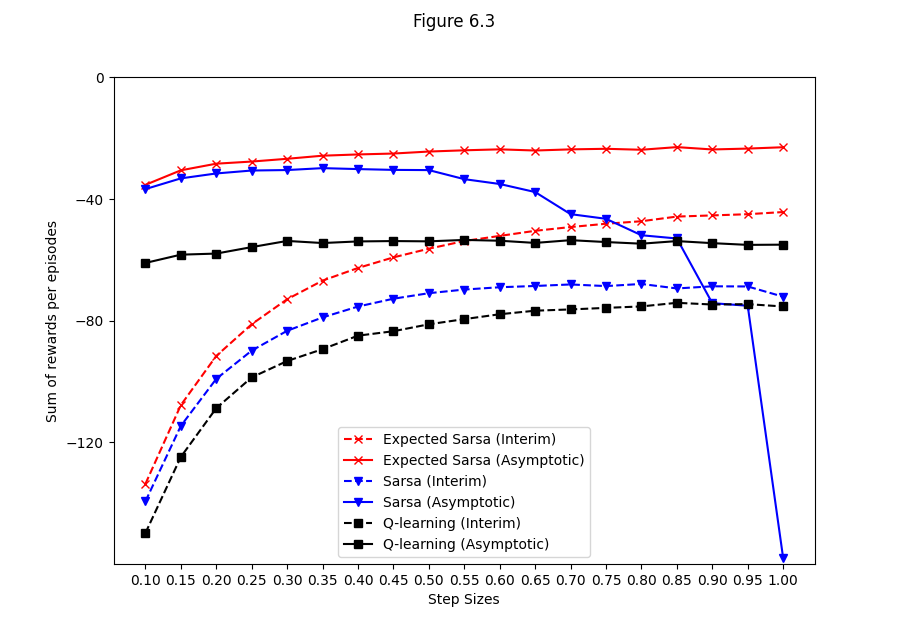
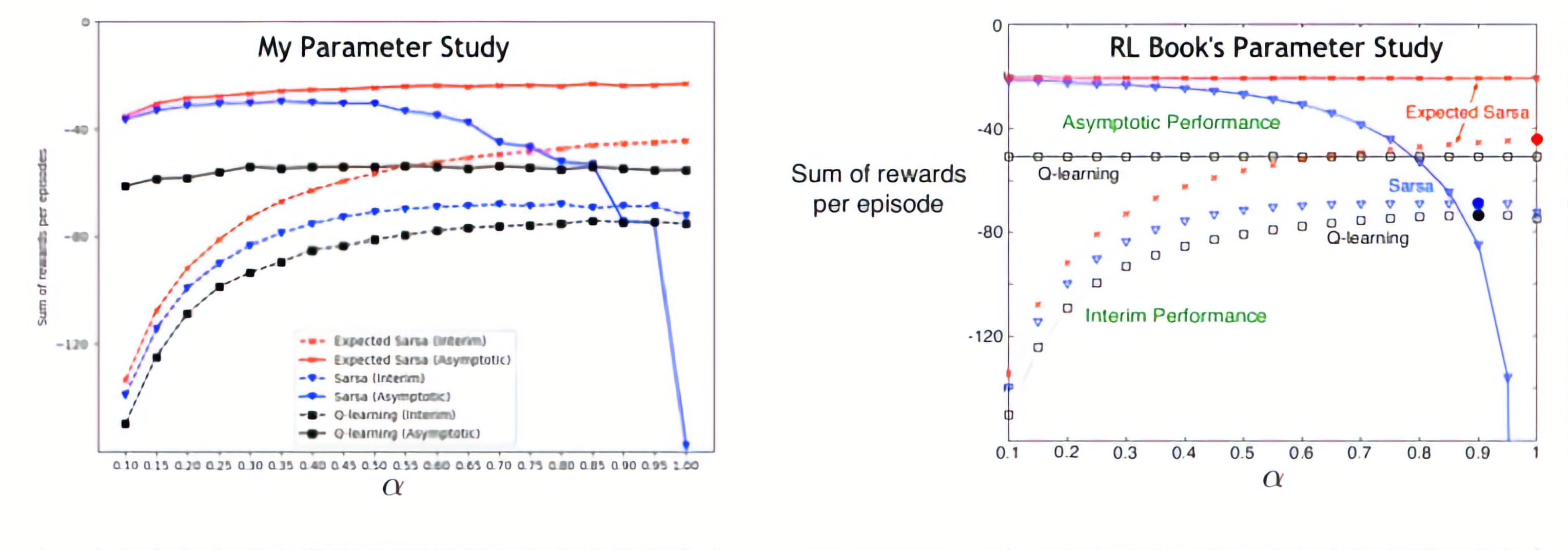
- Figure 6.3: Interim and asymptotic performance of TD control methods (comparison)
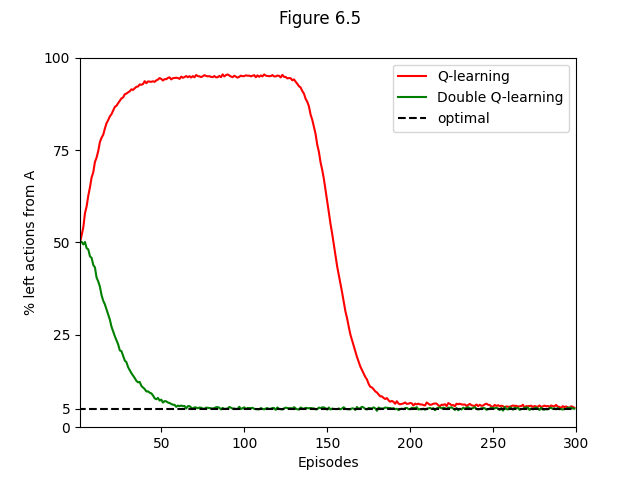
- Figure 6.5: Comparison of Q-learning and Double Q-learning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
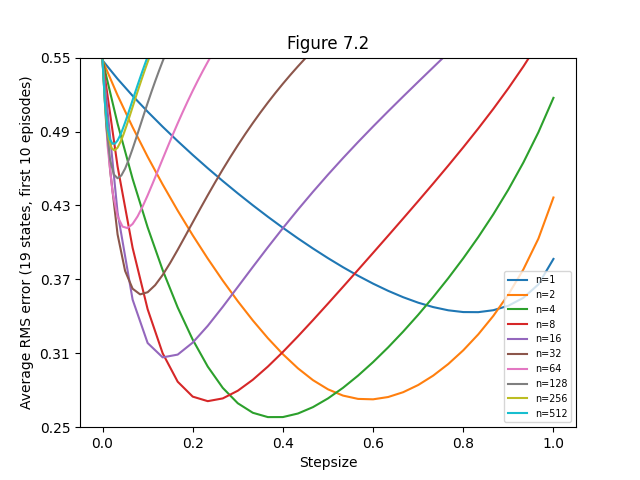
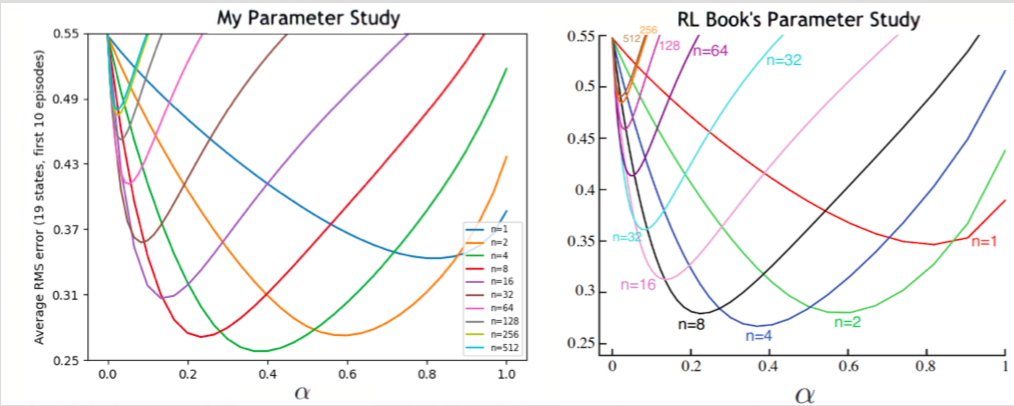
- Figure 7.2: Performance of n-step TD methods on 19-state random walk (comparison)
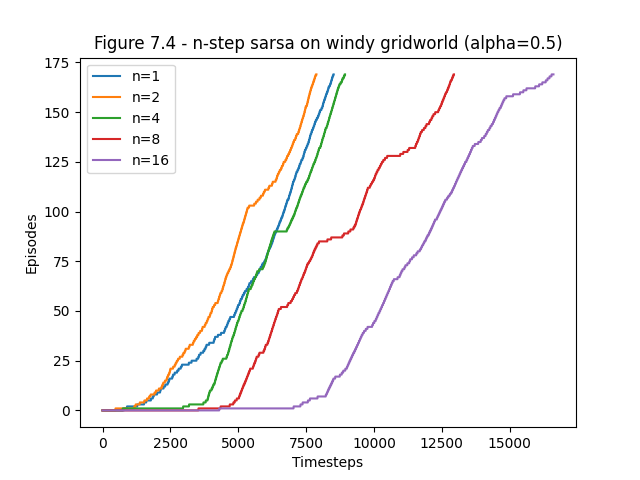
- Figure 7.4: Gridworld example of the speedup of policy learning due to the use of n-step methods
{kind=link}
{kind=link}
{kind=link}
- Figure 8.2: Average learning curves for Dyna-Q agents varying in their number of planning steps
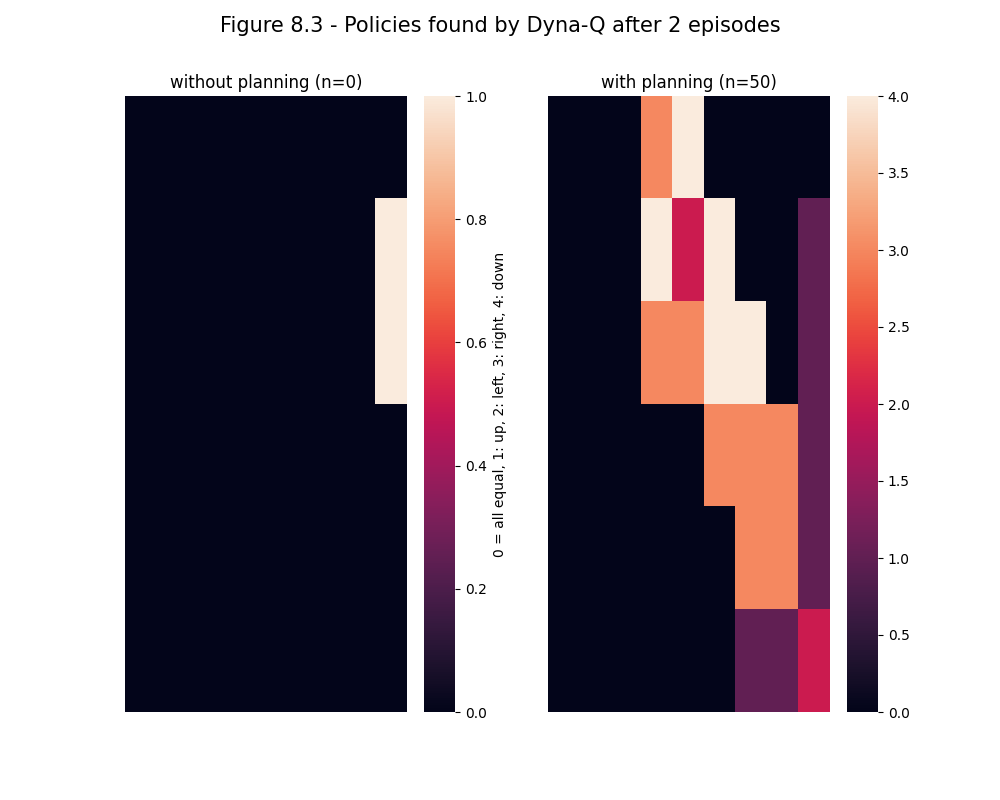
- Figure 8.3: Policies found by planning and nonplanning Dyna-Q agents
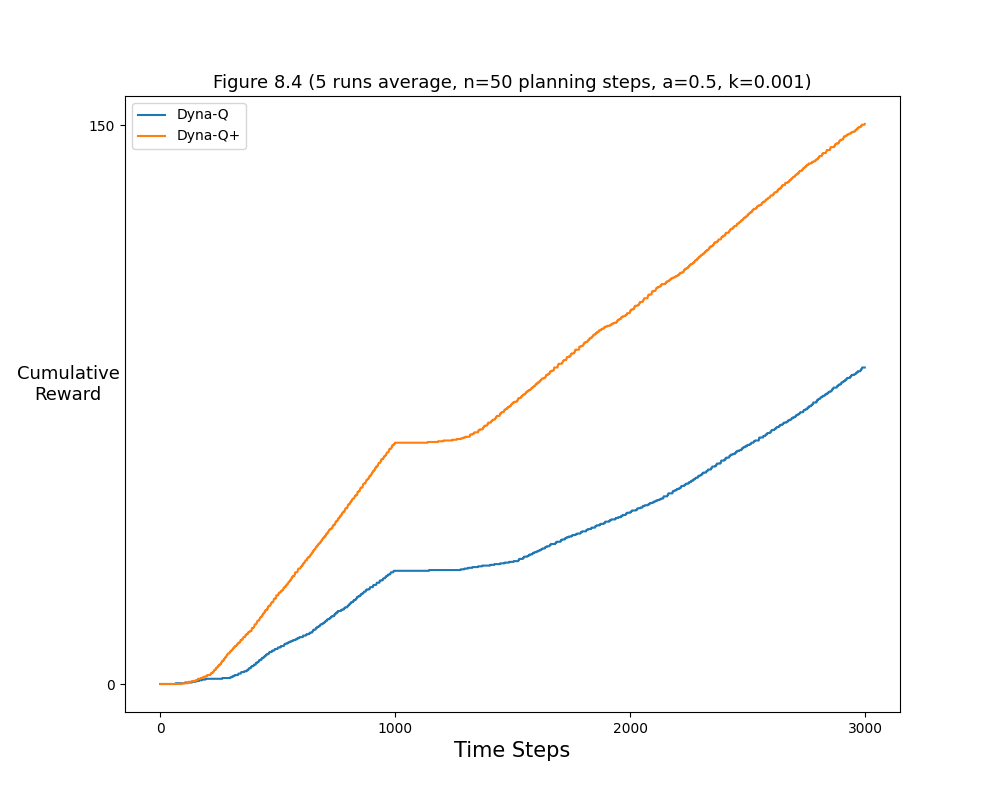
- Figure 8.4: Average performance of Dyna agents on a blocking task
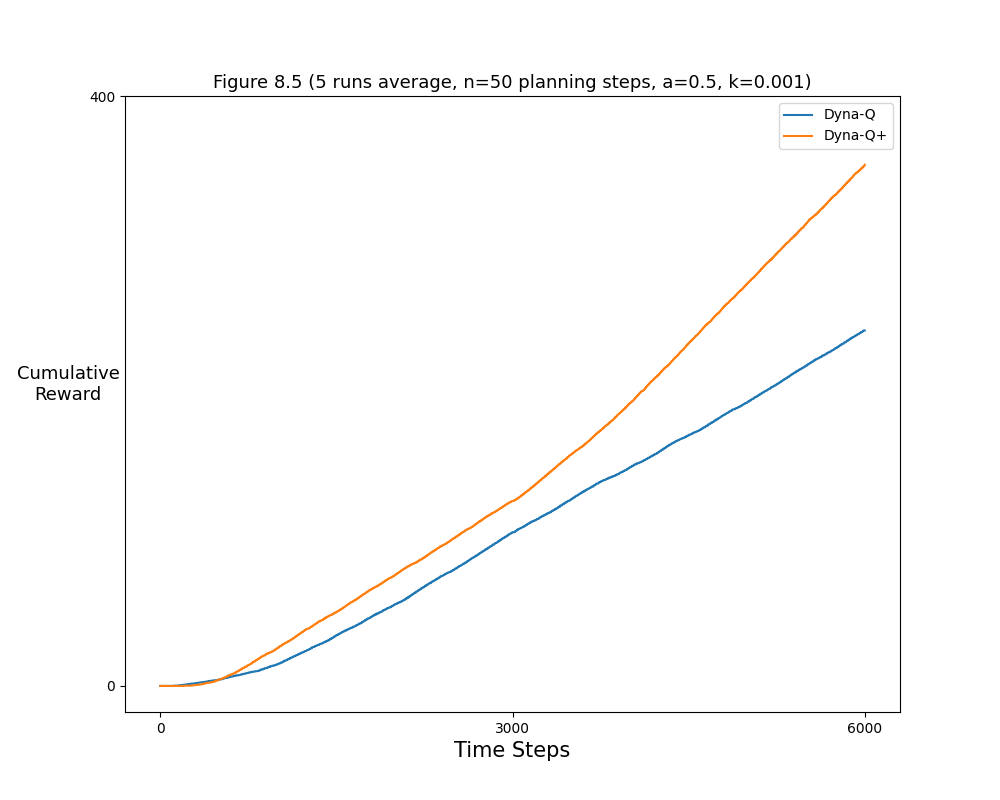
- Figure 8.5: Average performance of Dyna agents on a shortcut task
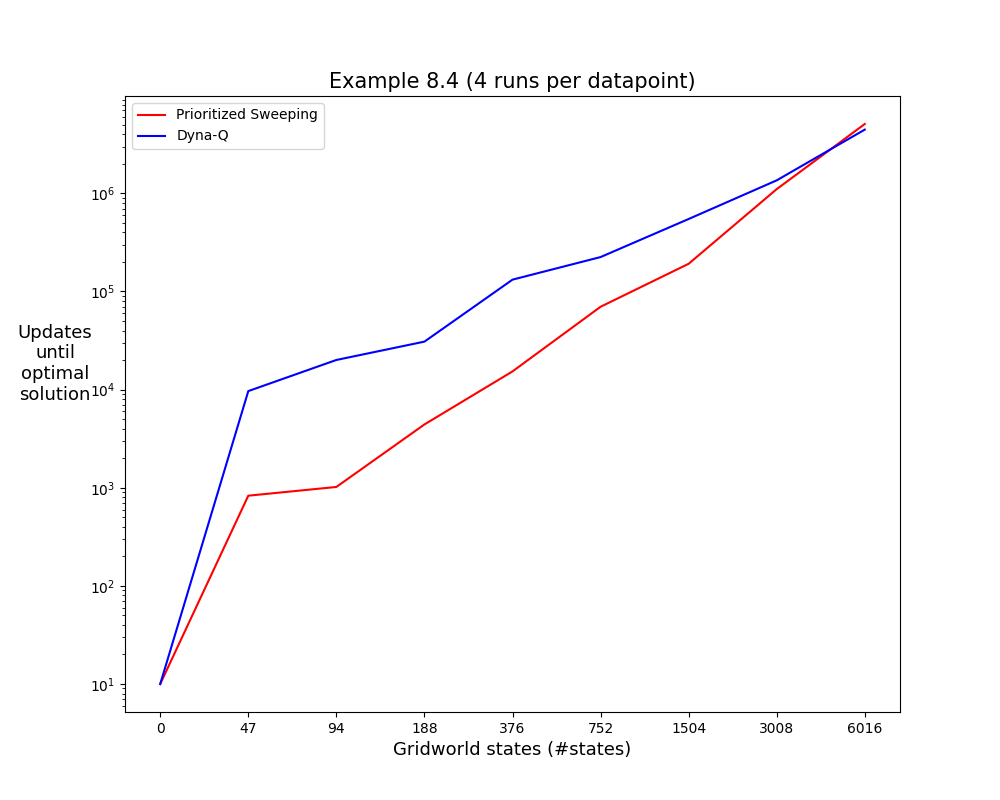
- Example 8.4: Prioritized sweeping significantly shortens learning time on the Dyna maze task
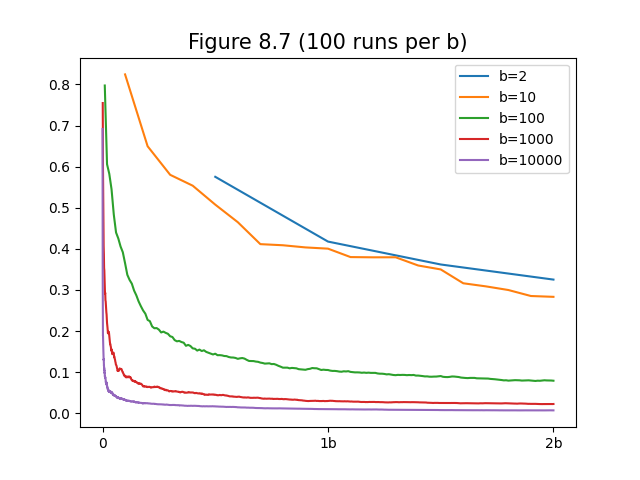
- Figure 8.7: Comparison of efficiency of expected and sample updates
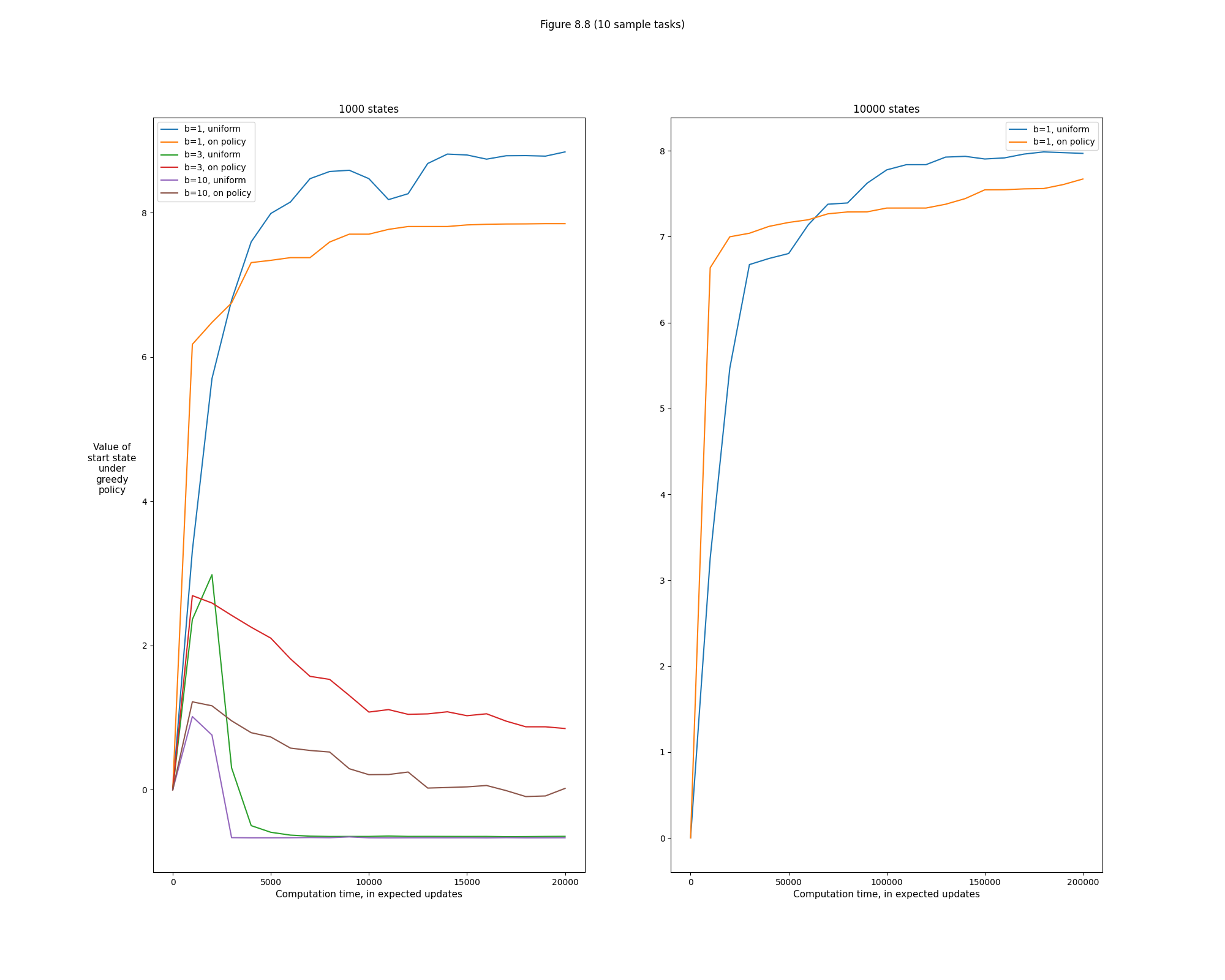
- Figure 8.8: Relative efficiency of different update distributions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
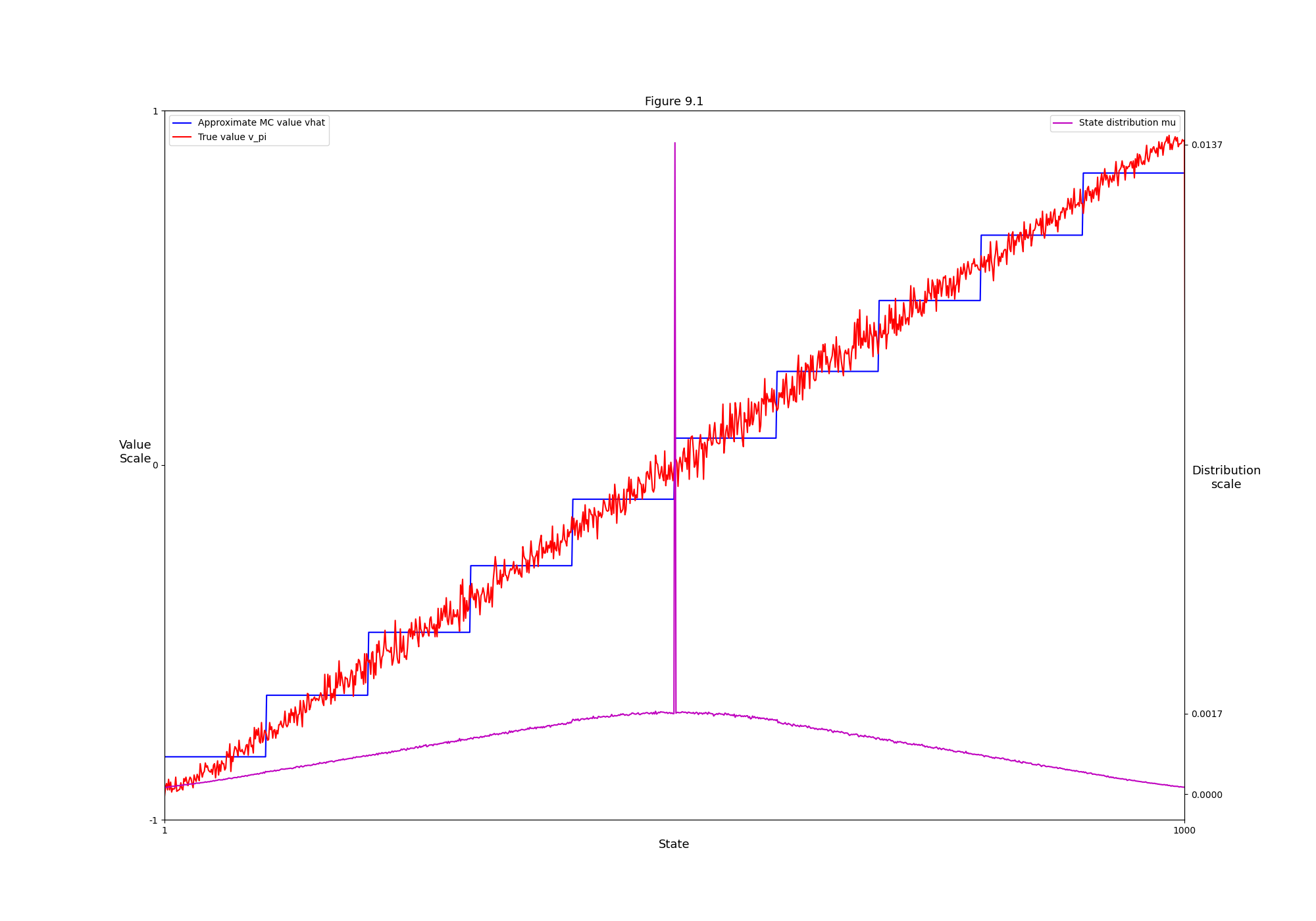
- Figure 9.1: Gradient Monte Carlo algorithm on the 1000-state random walk task
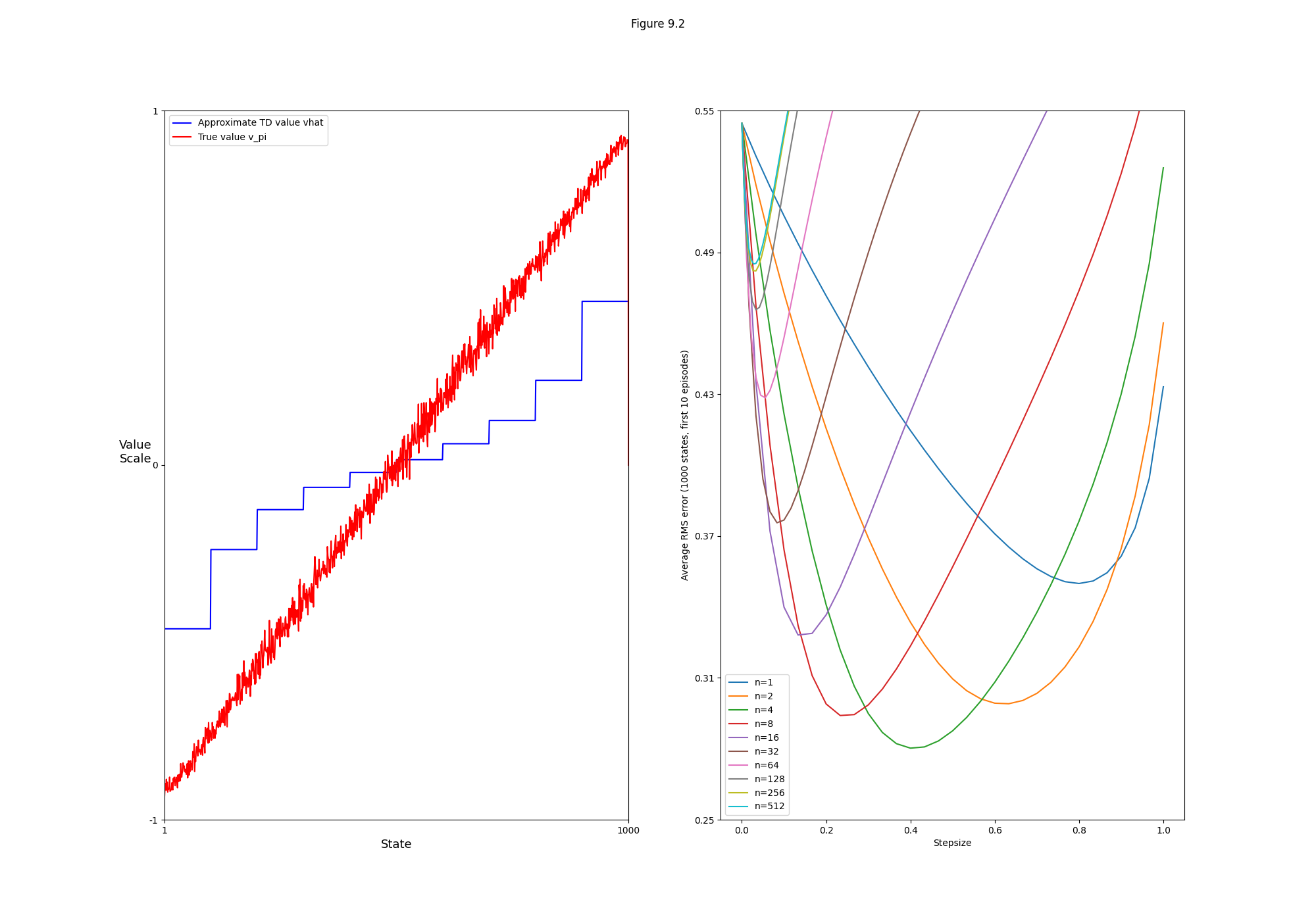
- Figure 9.2: Semi-gradient n-steps TD algorithm on the 1000-state random walk task
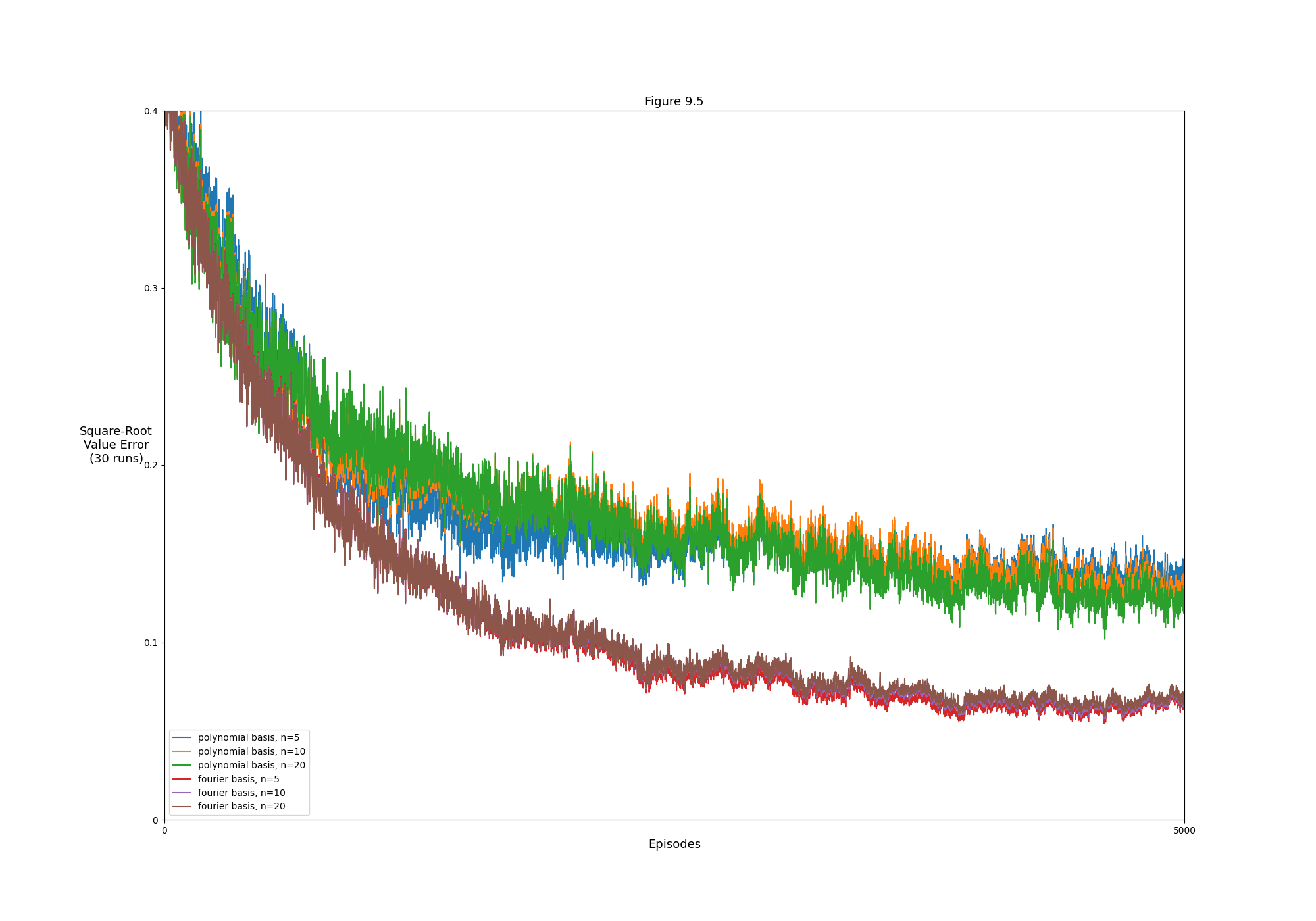
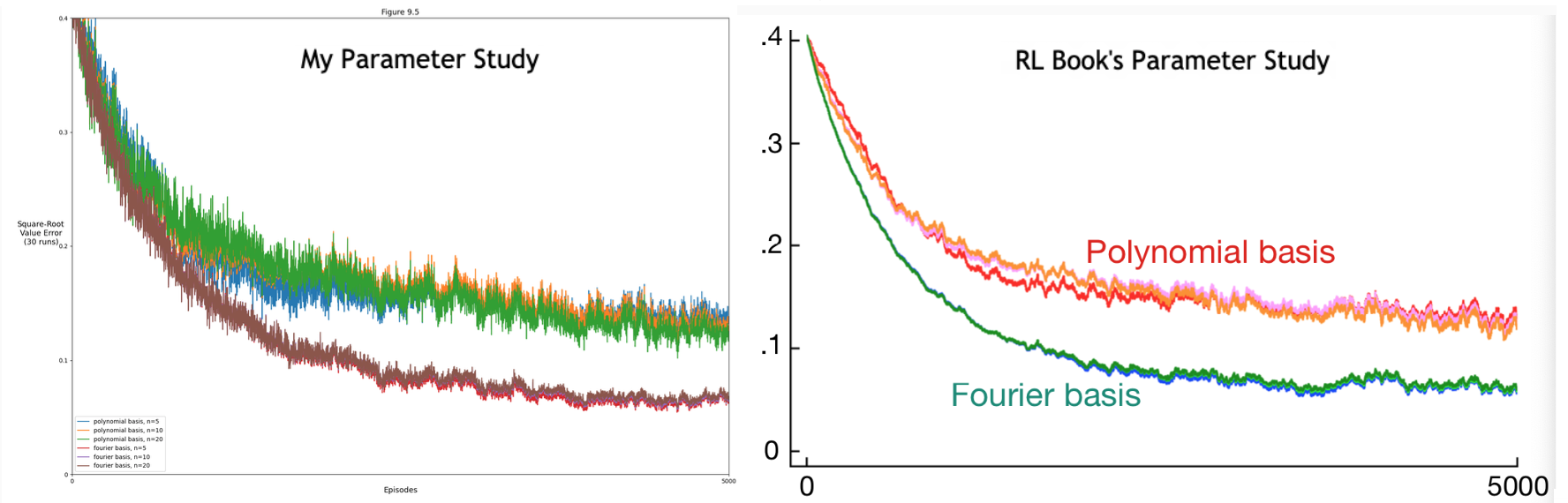
- Figure 9.5: Fourier basis vs polynomials on the 1000-state random walk task (comparison)
- Figure 9.10: State aggregation vs. Tile coding on 1000-state random walk task (comparison)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
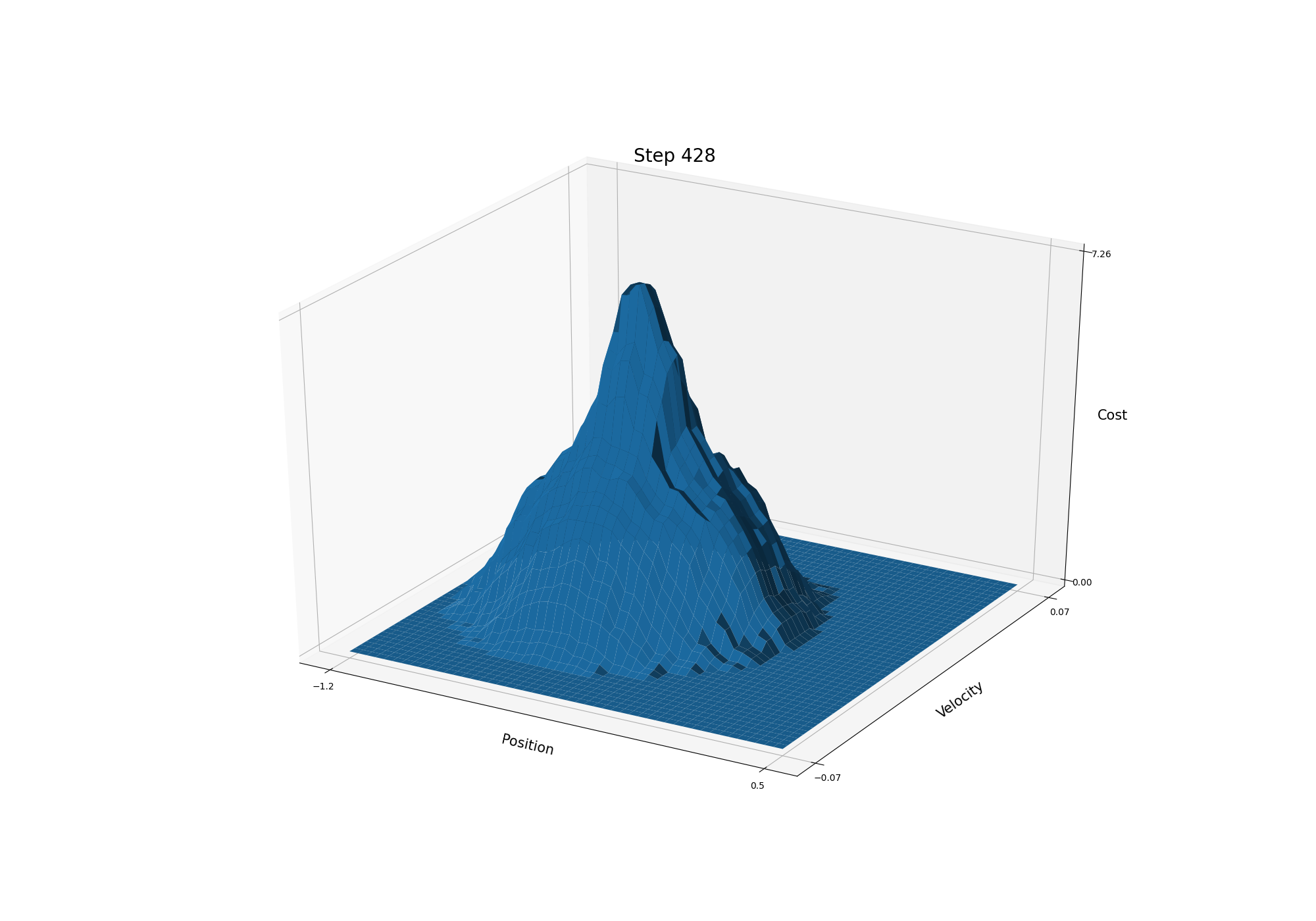
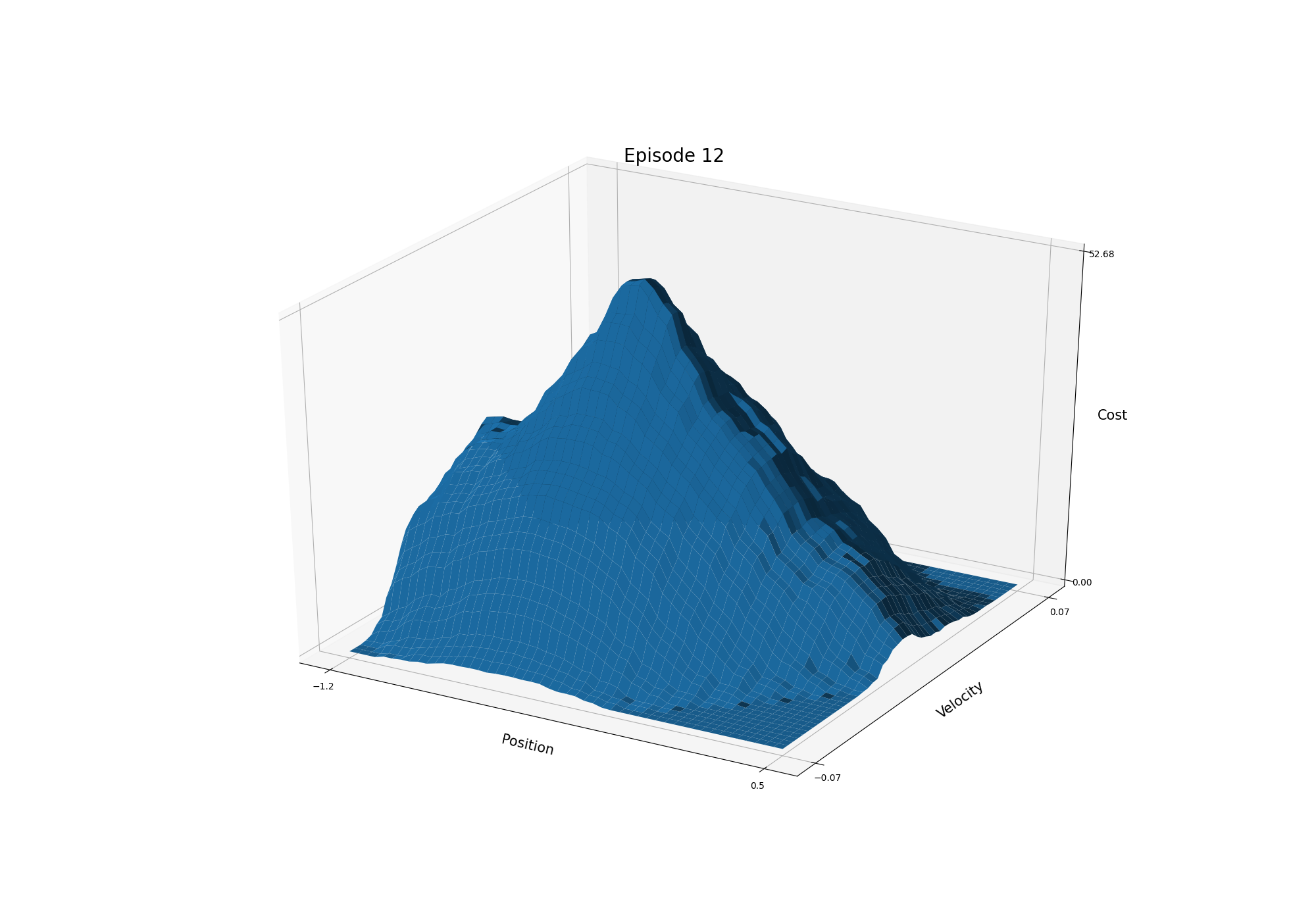
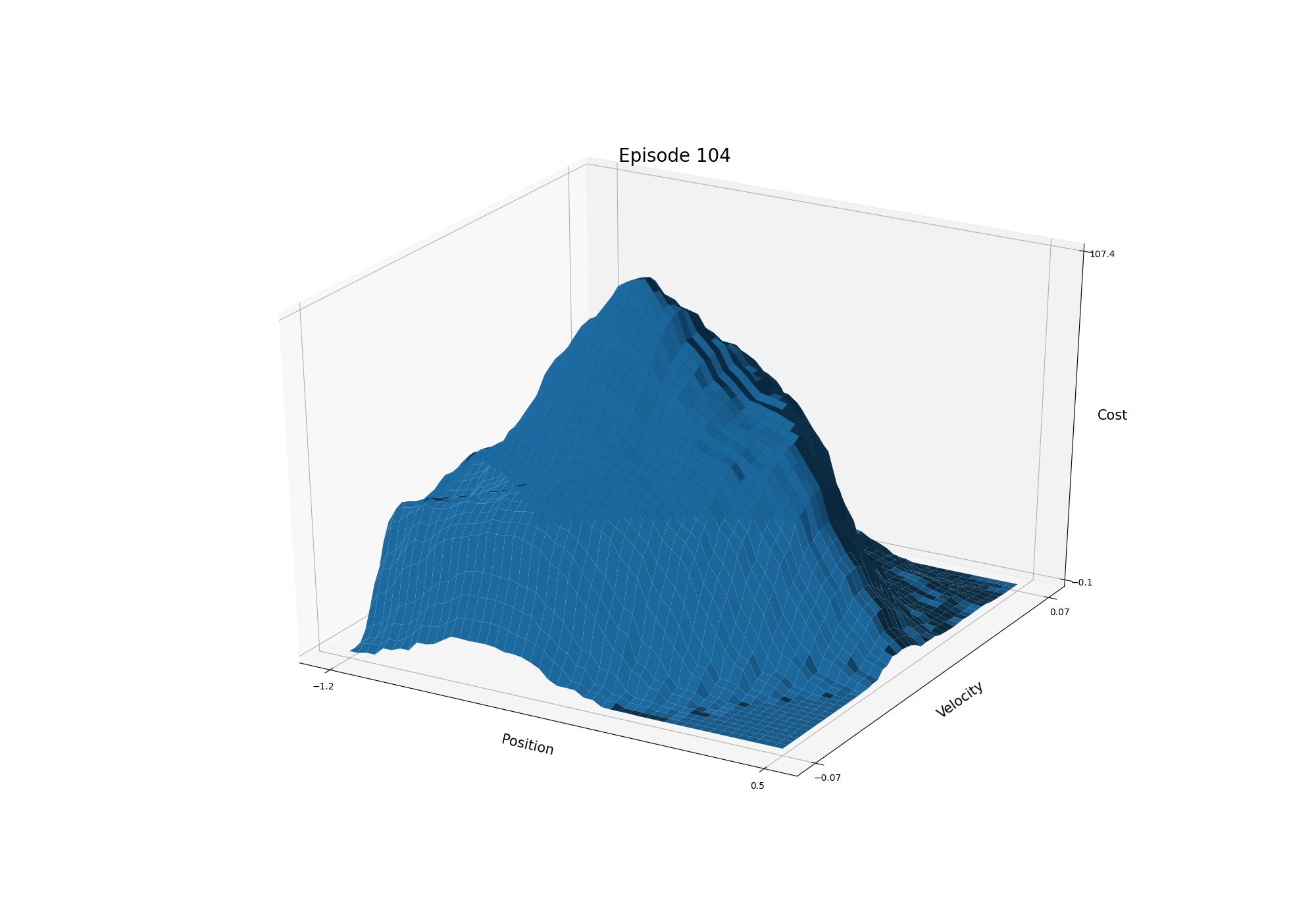
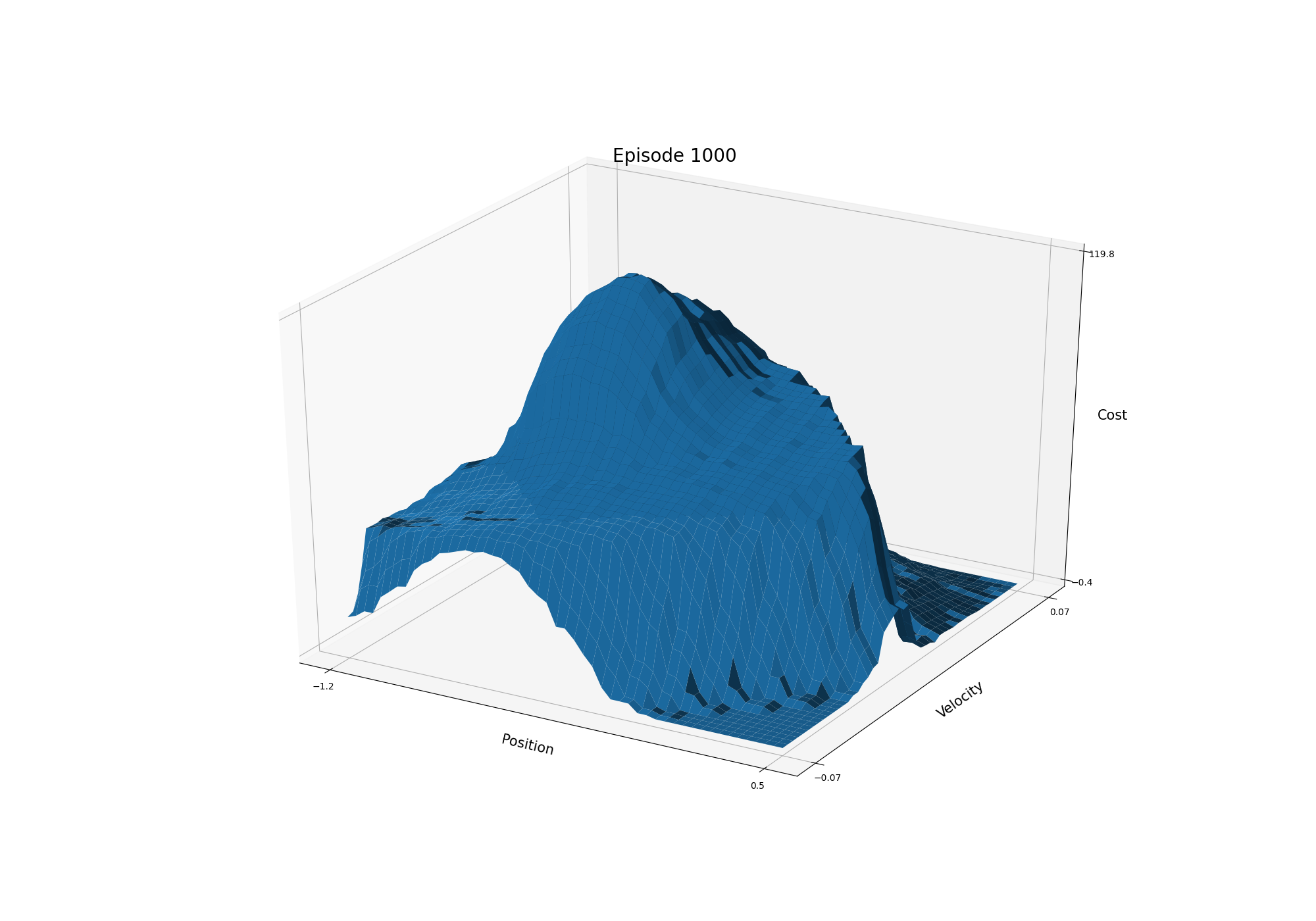
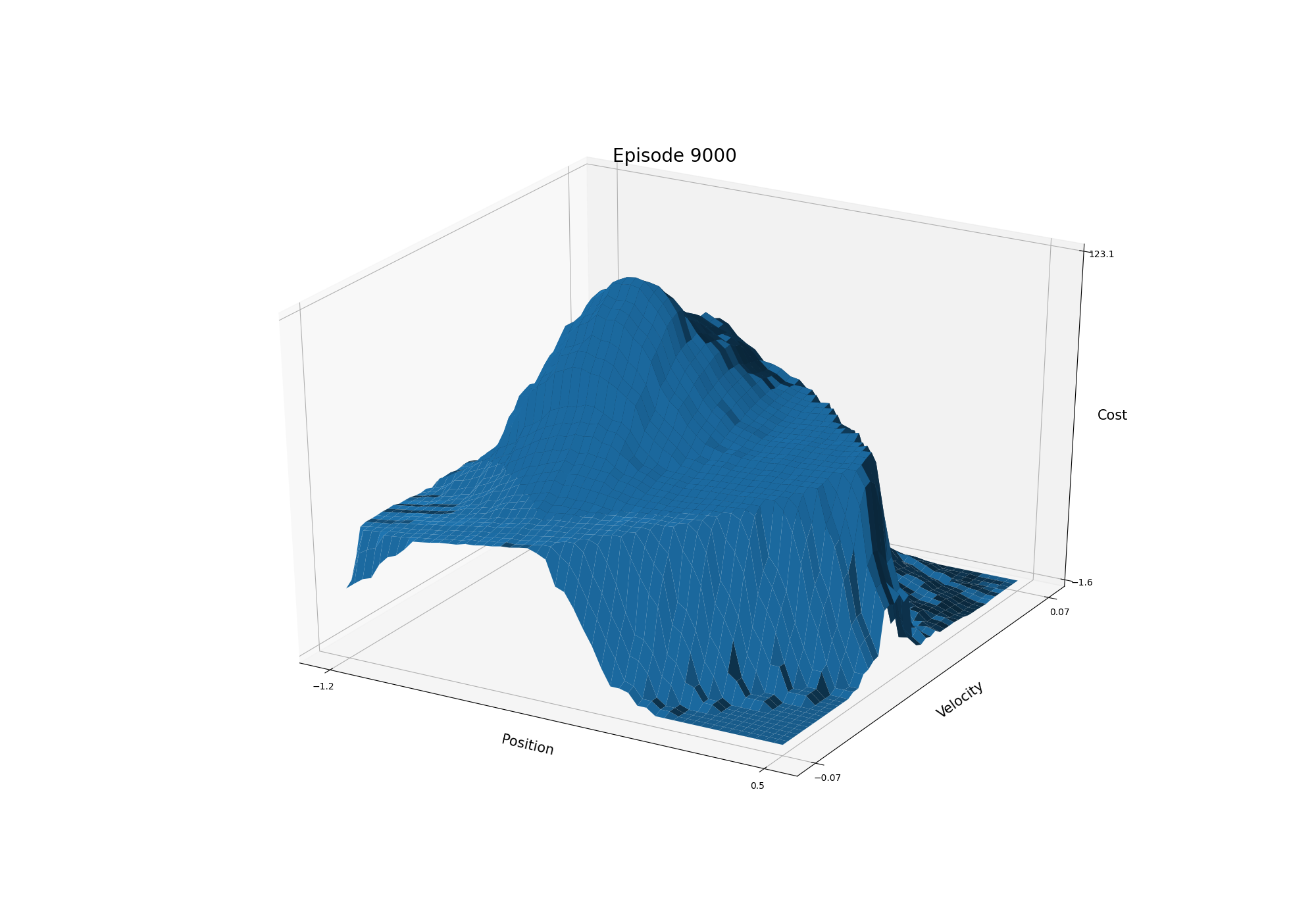
- Figure 10.1: The cost-to-go function for Mountain Car task in one run (428 steps; 12, 104, 1000, 9000 episodes)
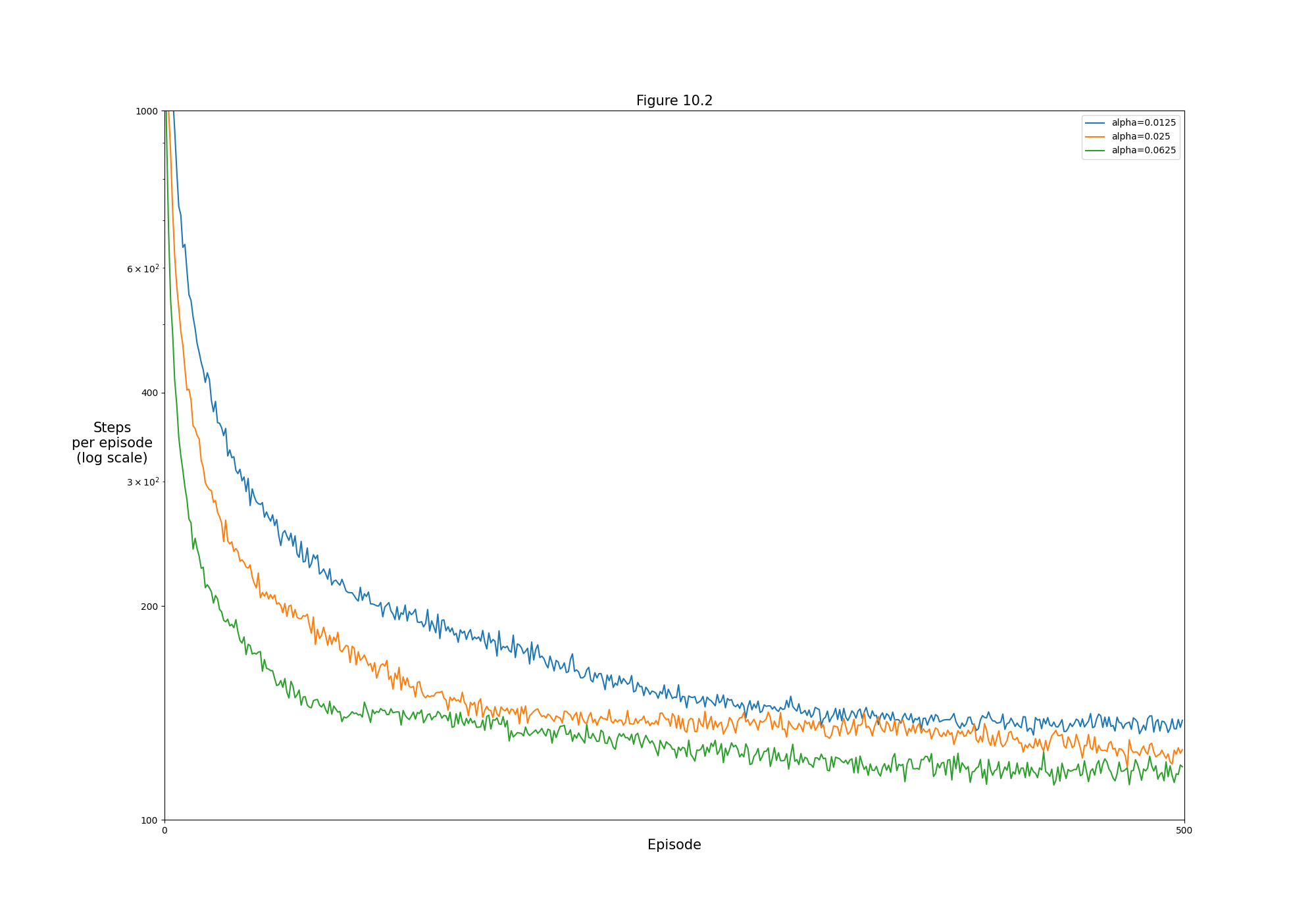
- Figure 10.2: Learning curves for semi-gradient Sarsa on Mountain Car task
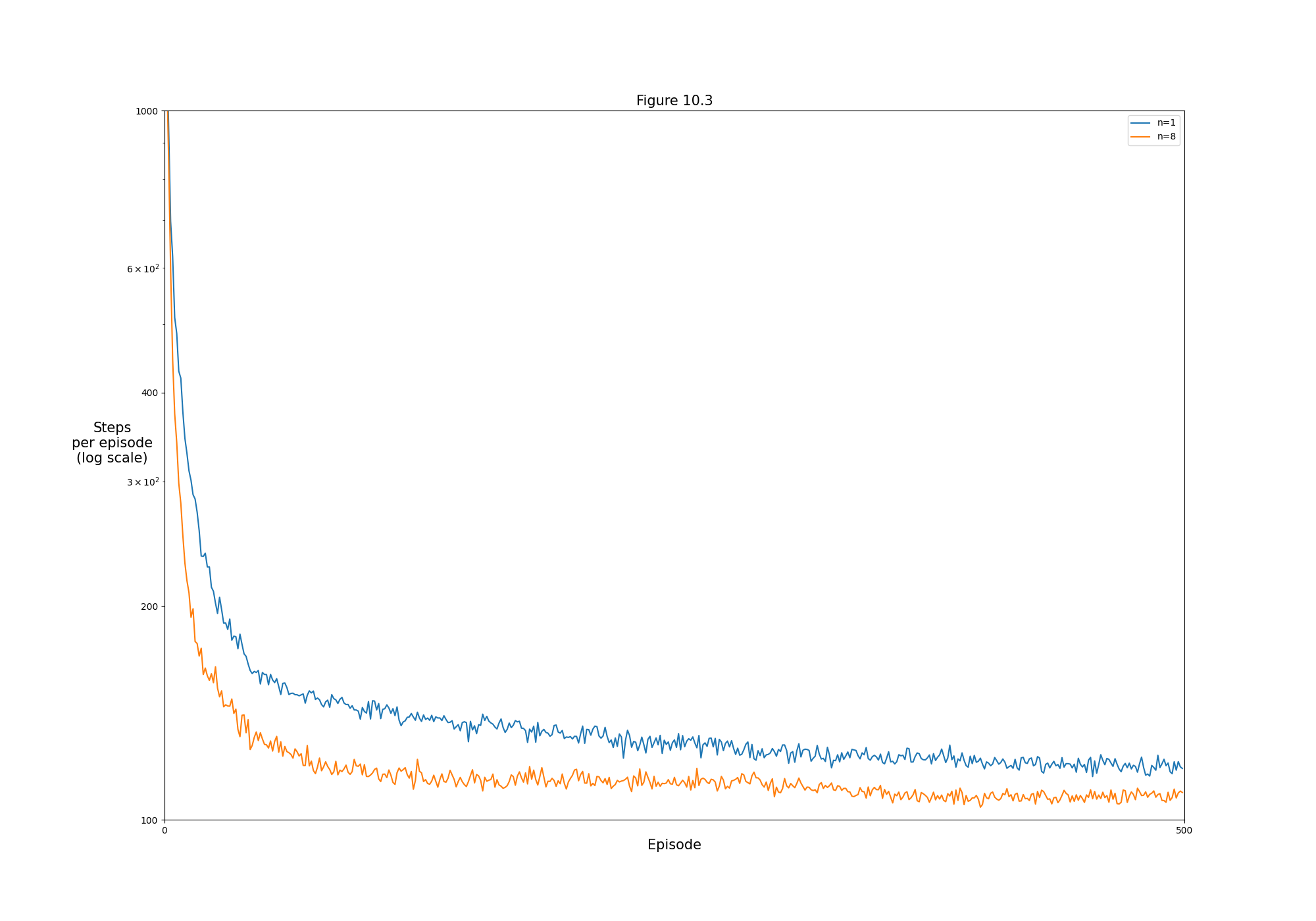
- Figure 10.3: One-step vs multi-step performance of semi-gradient Sarsa on the Mountain Car task
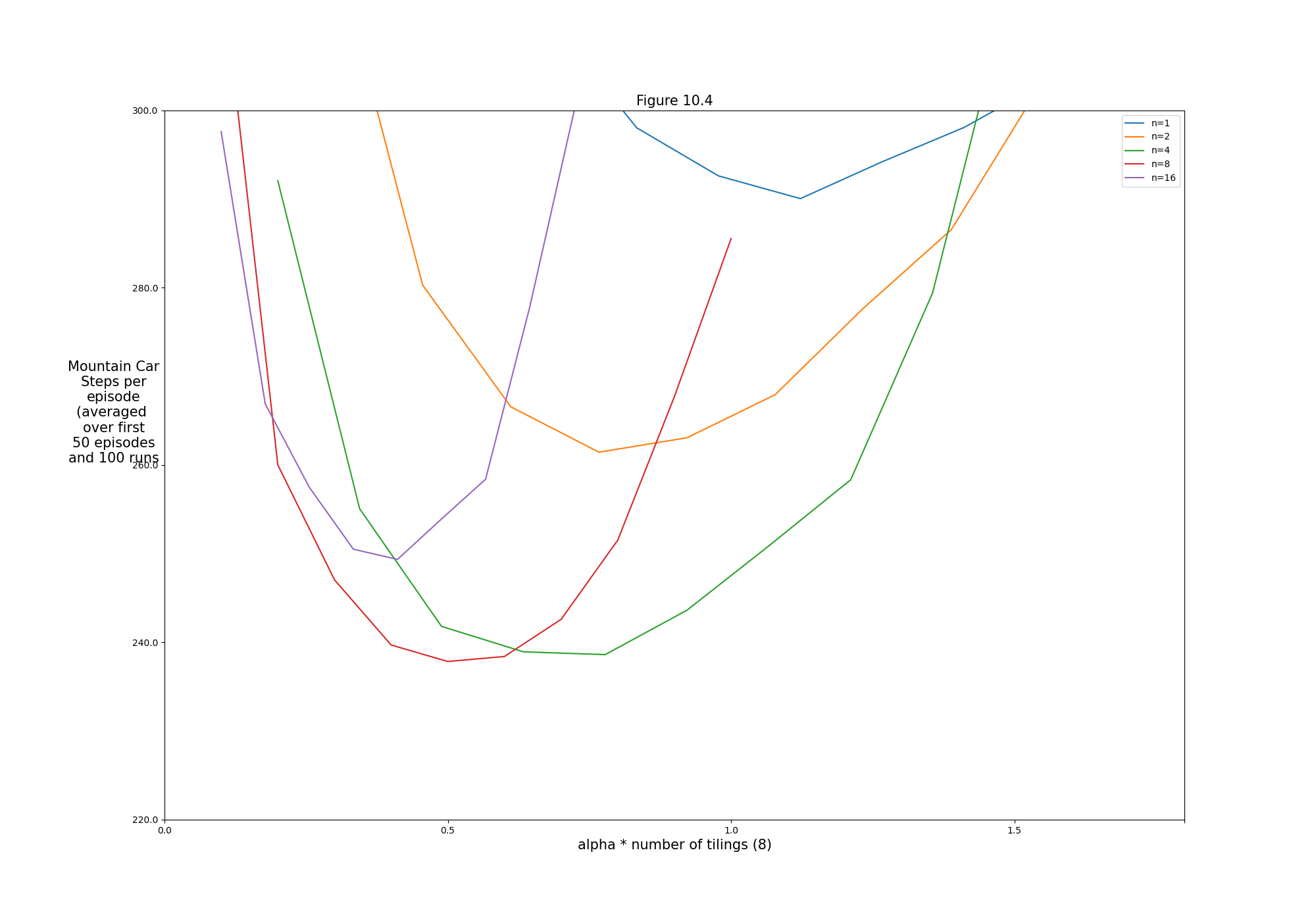
- Figure 10.4: Effect of the alpha and n on early performance of n-step semi-gradient Sarsa
- Figure 10.5: Differential semi-gradient Sarsa on the access-control queuing task
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
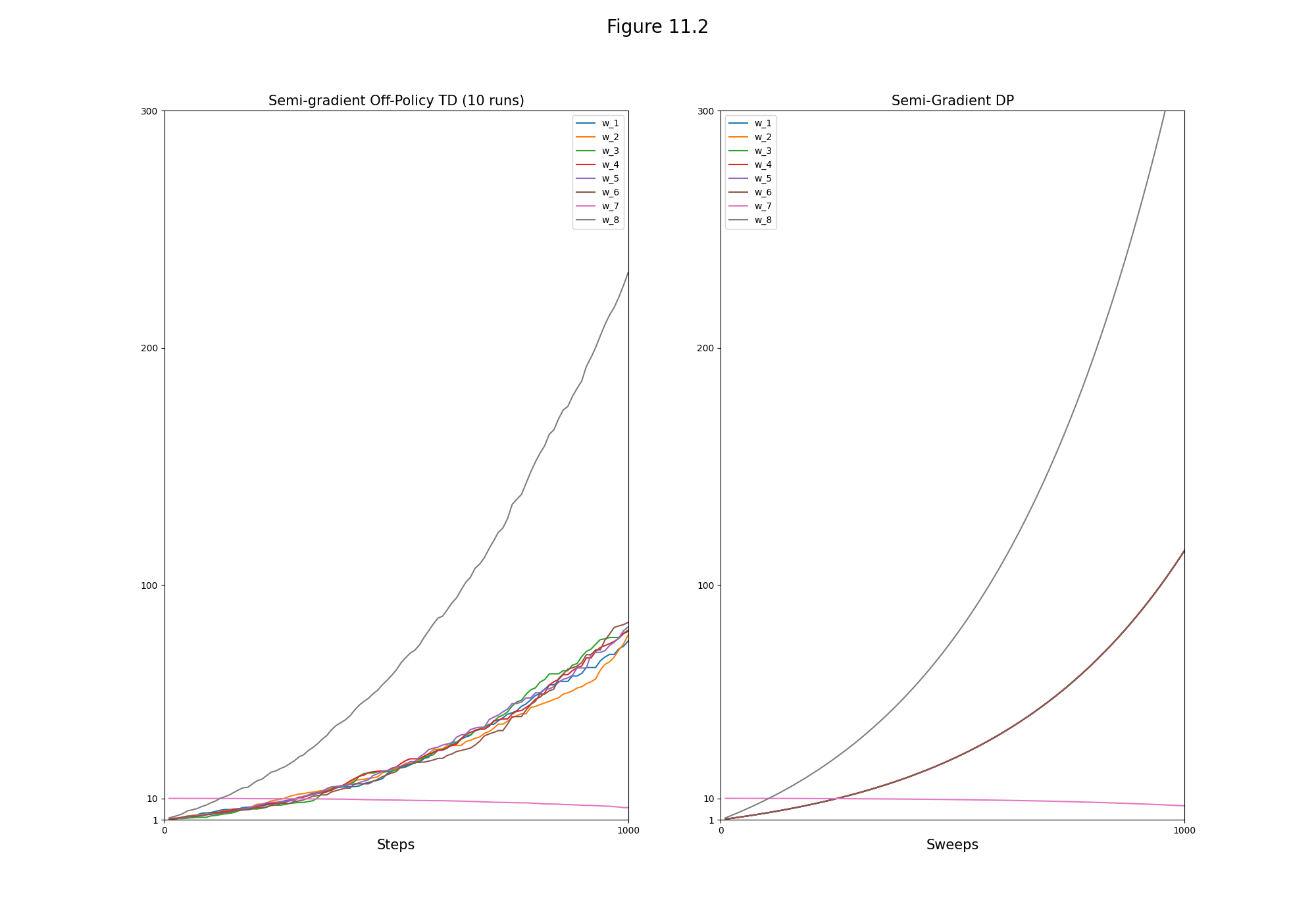
- Figure 11.2: Demonstration of instability on Baird’s counterexample
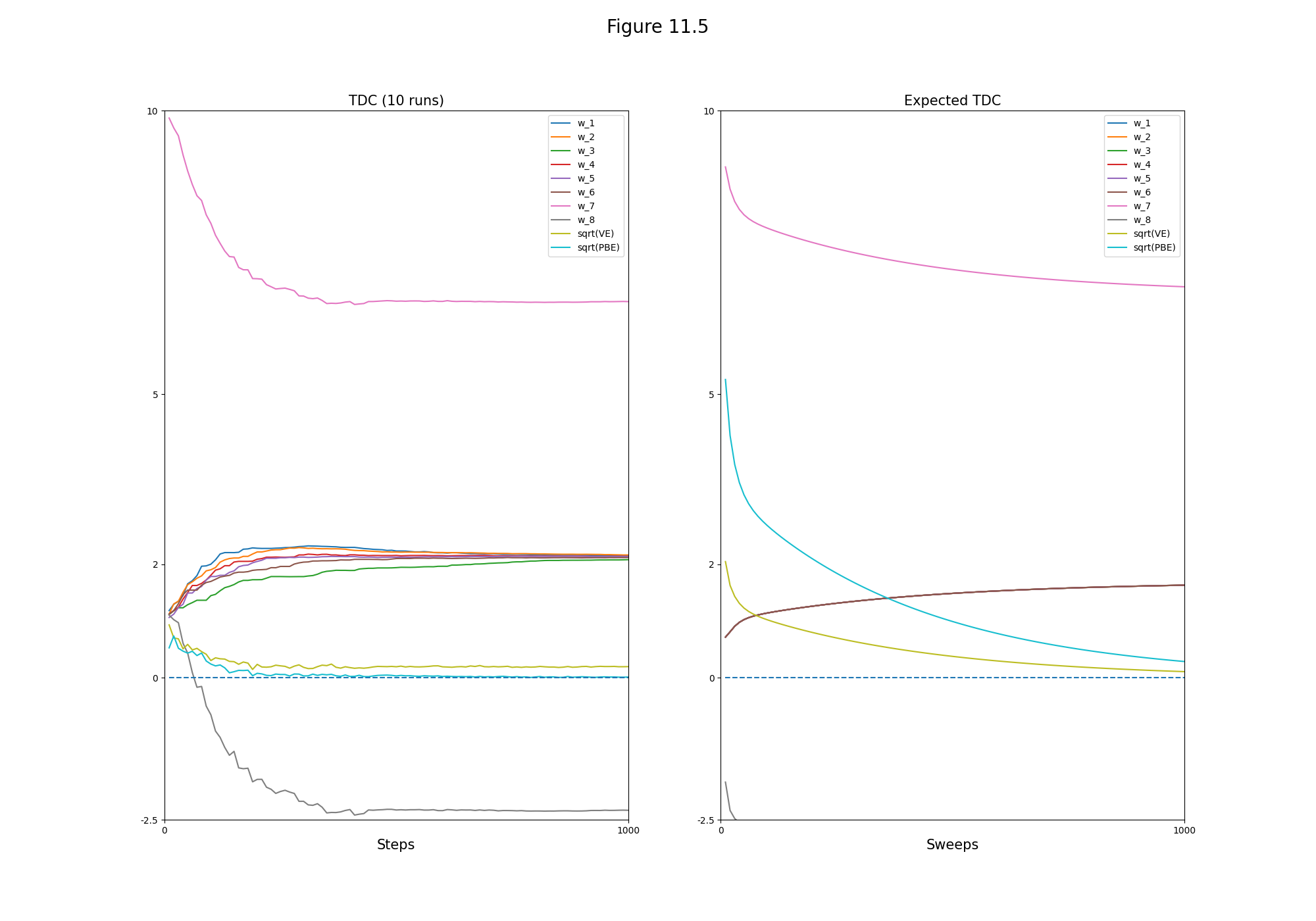
- Figure 11.5: The behavior of the TDC algorithm on Baird’s counterexample
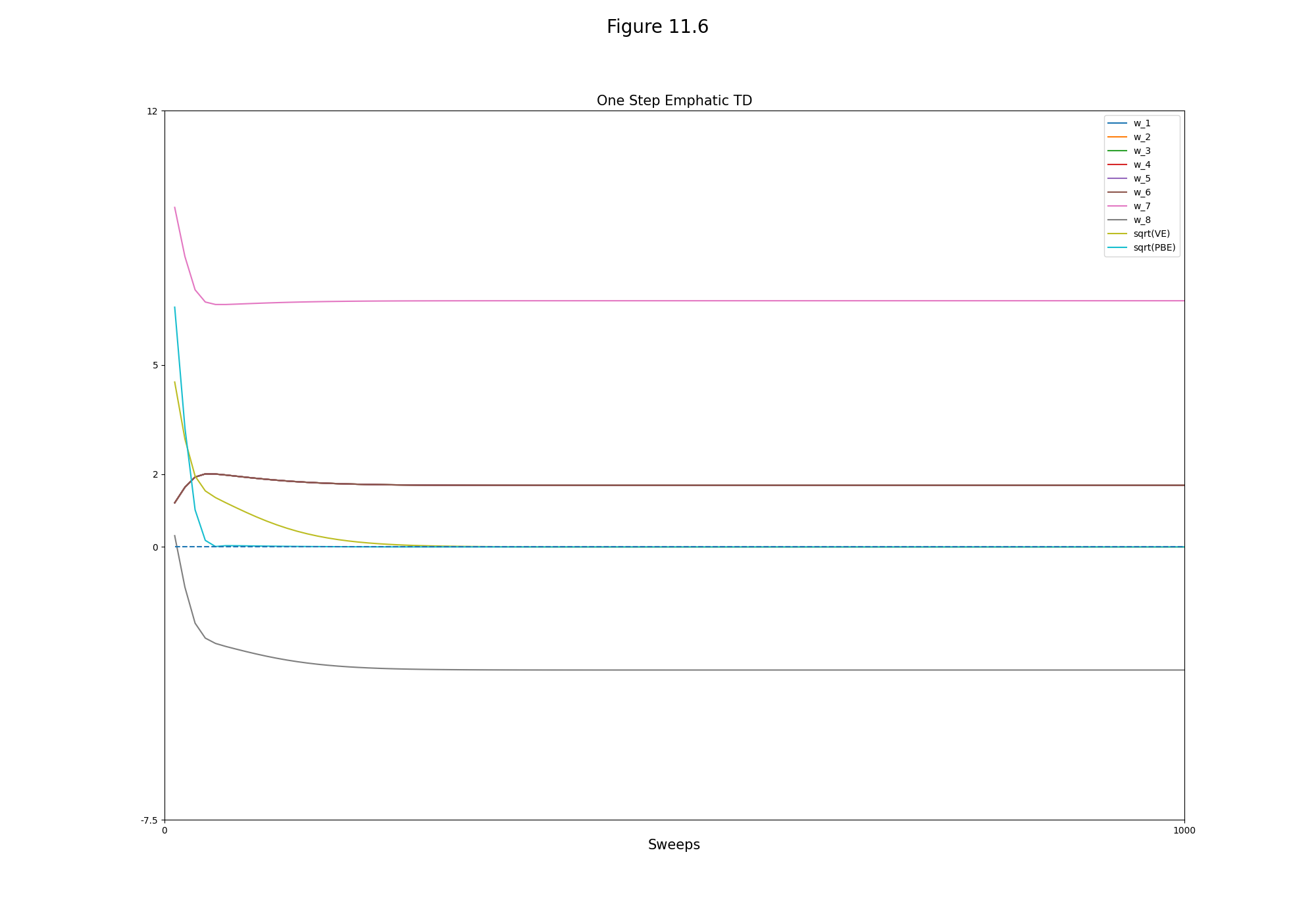
- Figure 11.6: The behavior of the ETD algorithm in expectation on Baird’s counterexample
{kind=link}
{kind=link}
{kind=link}
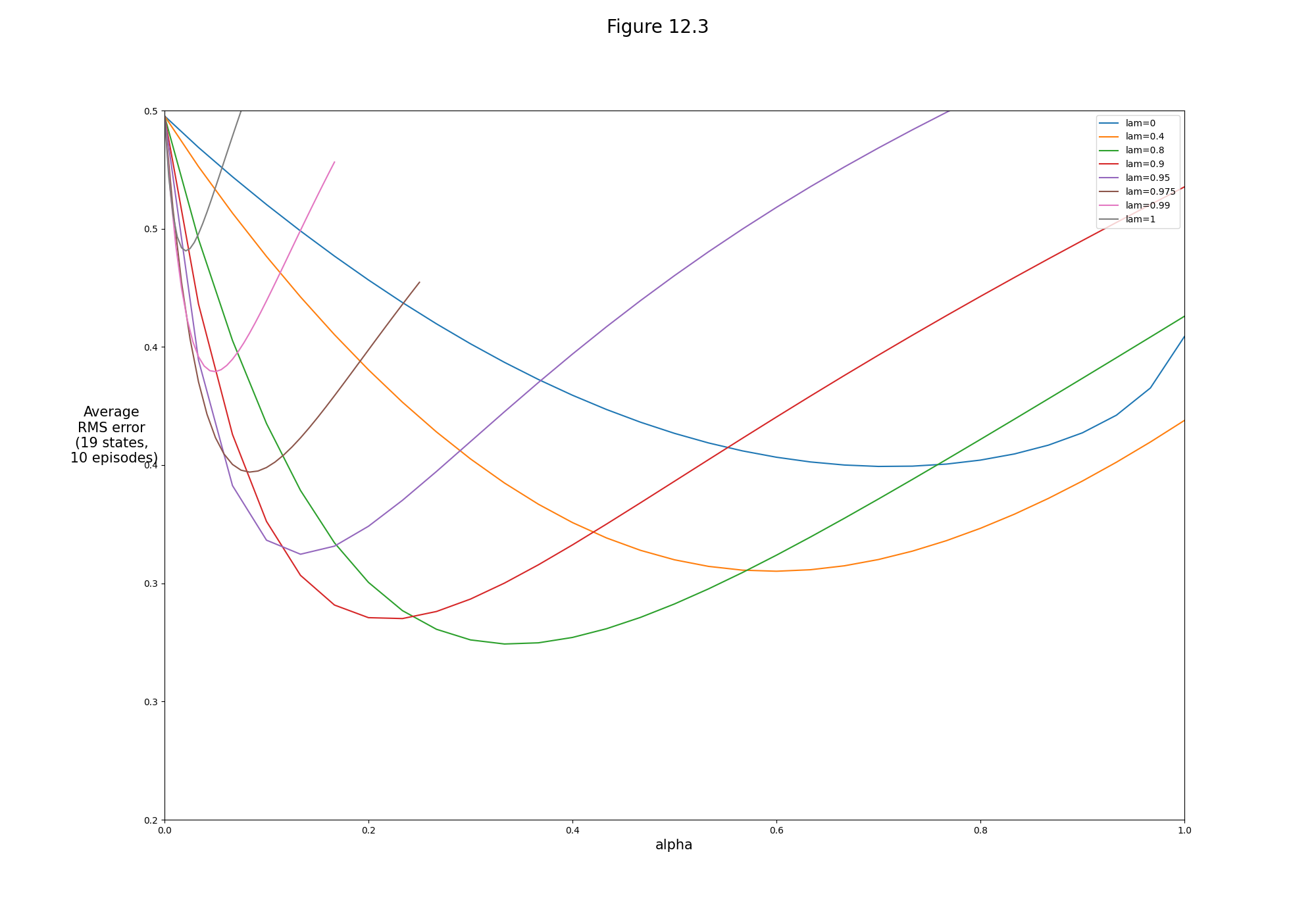
- Figure 12.3: Off-line λ-return algorithm on 19-state random walk
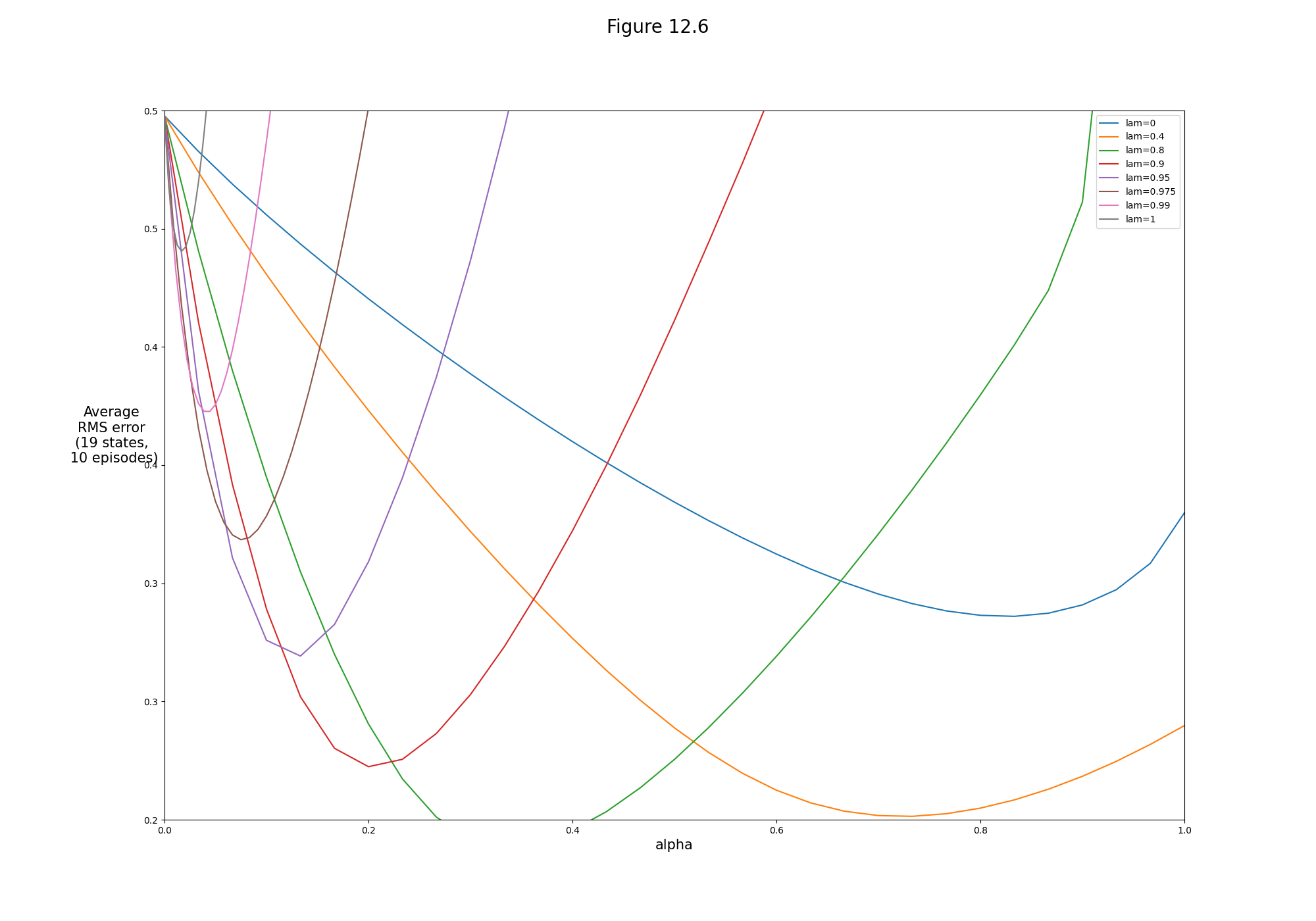
- Figure 12.6: TD(λ) algorithm on 19-state random walk
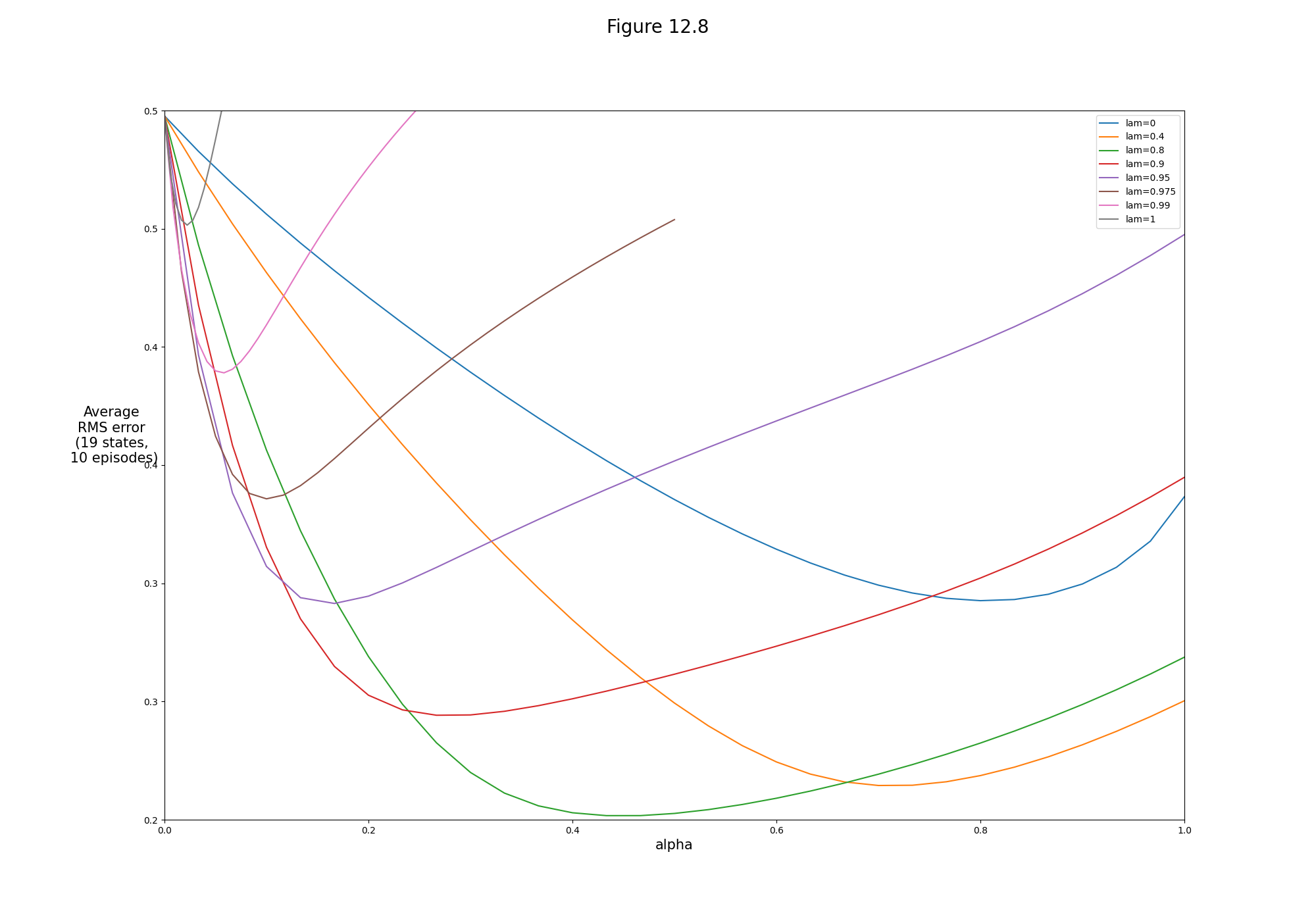
- Figure 12.8: True online TD(λ) algorithm on 19-state random walk
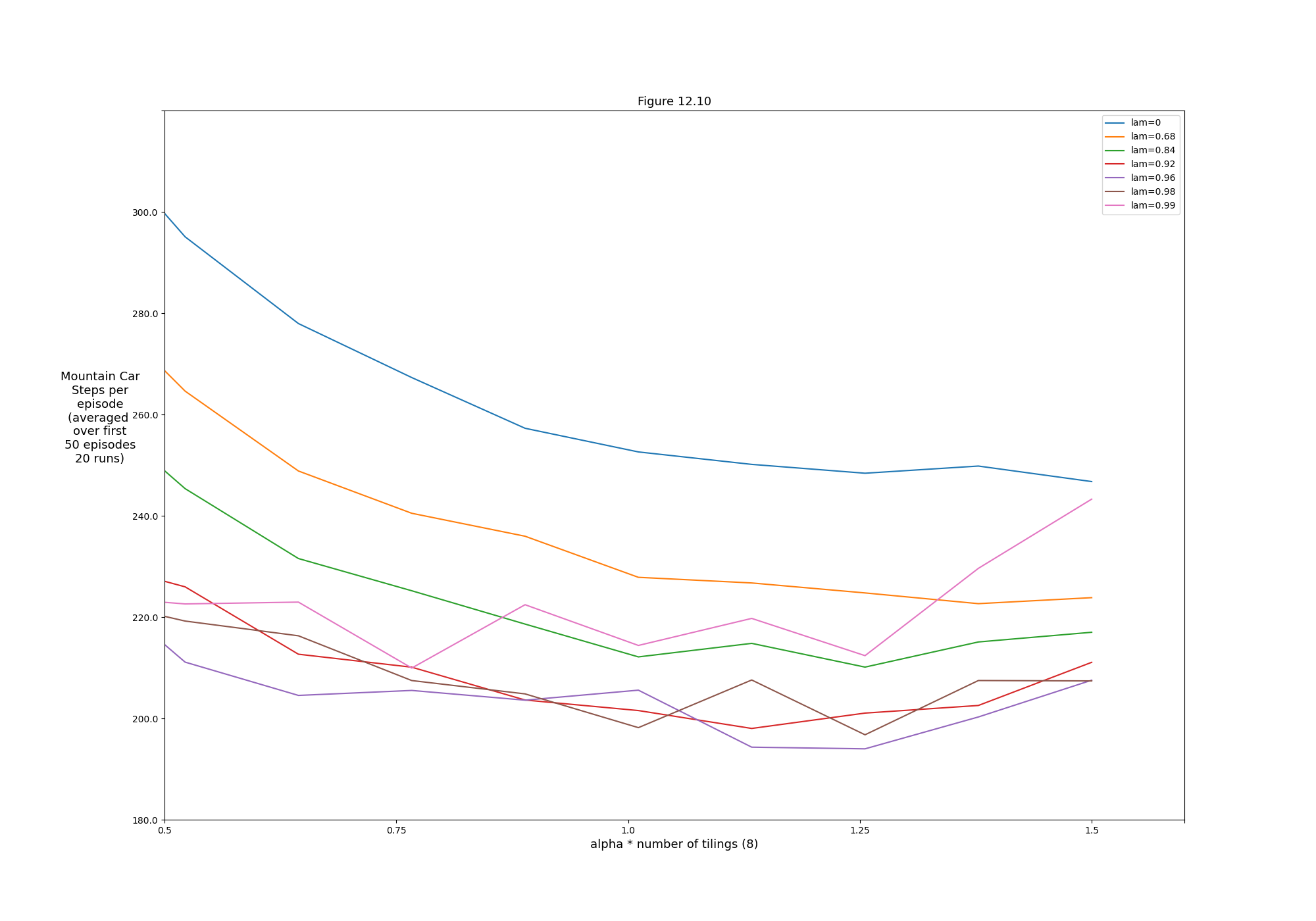
- Figure 12.10: Sarsa(λ) with replacing traces on Mountain Car
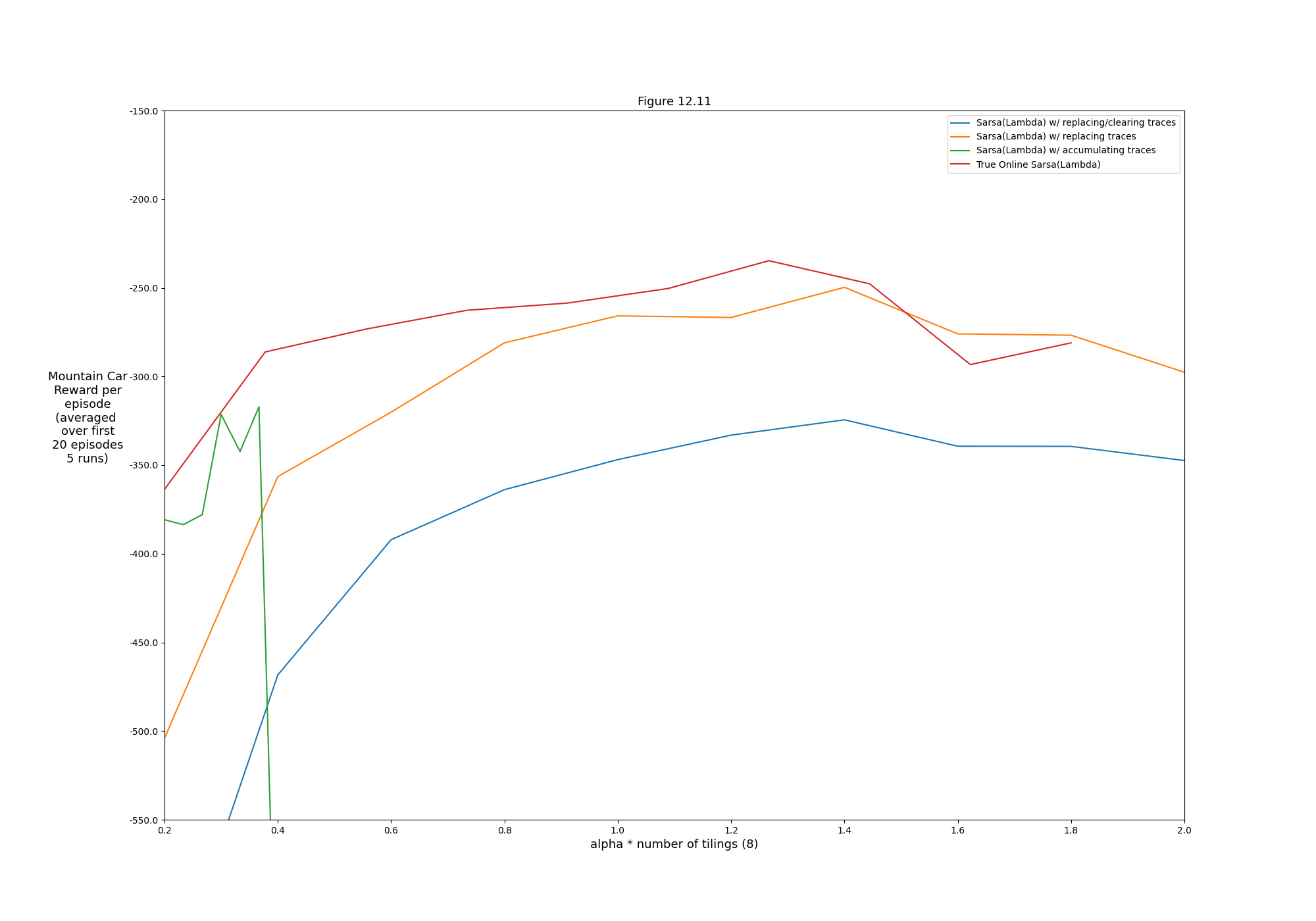
- Figure 12.11: Summary comparison of Sarsa(λ) algorithms on Mountain Car
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
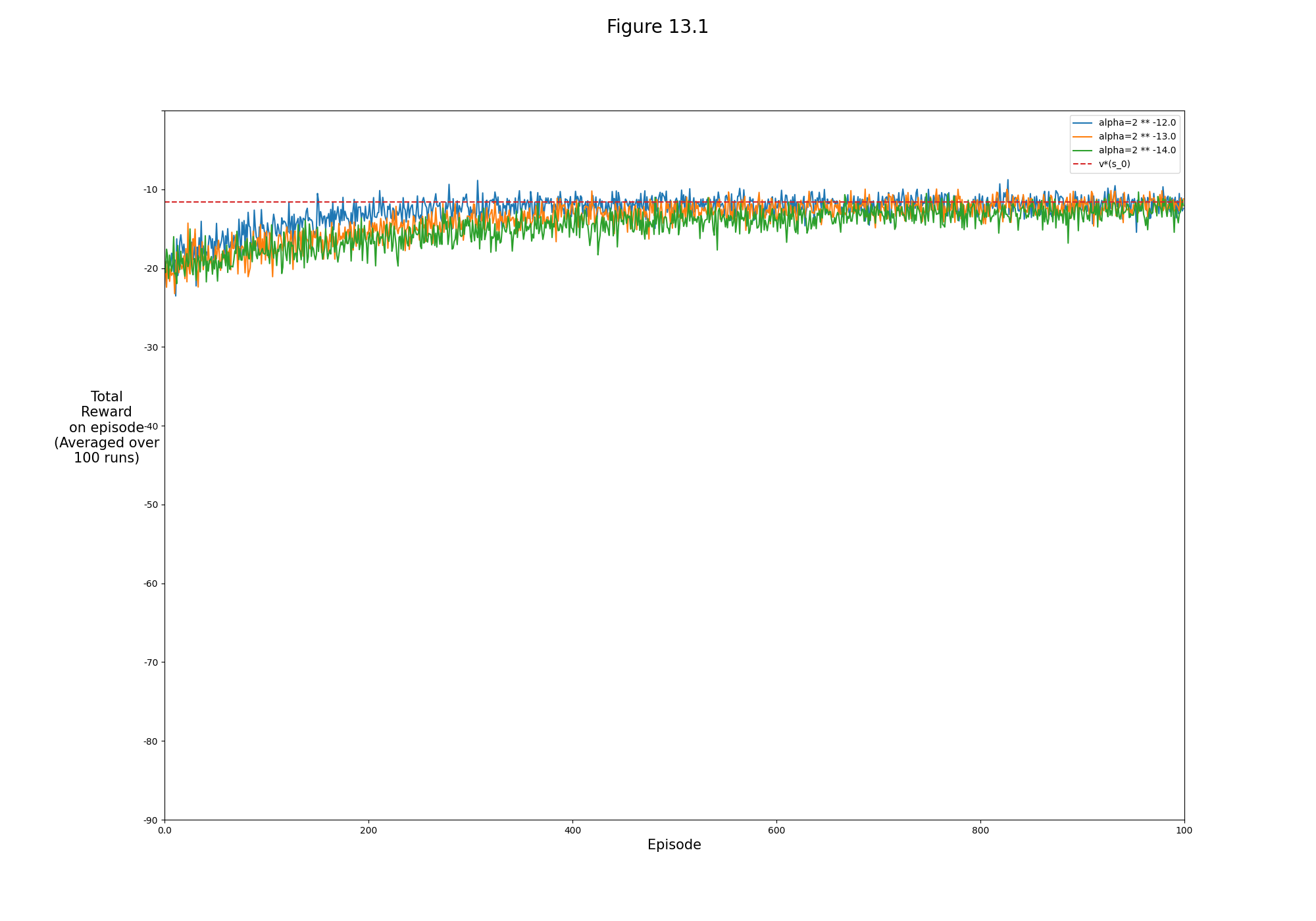
- Figure 13.1: REINFORCE on the short-corridor grid world
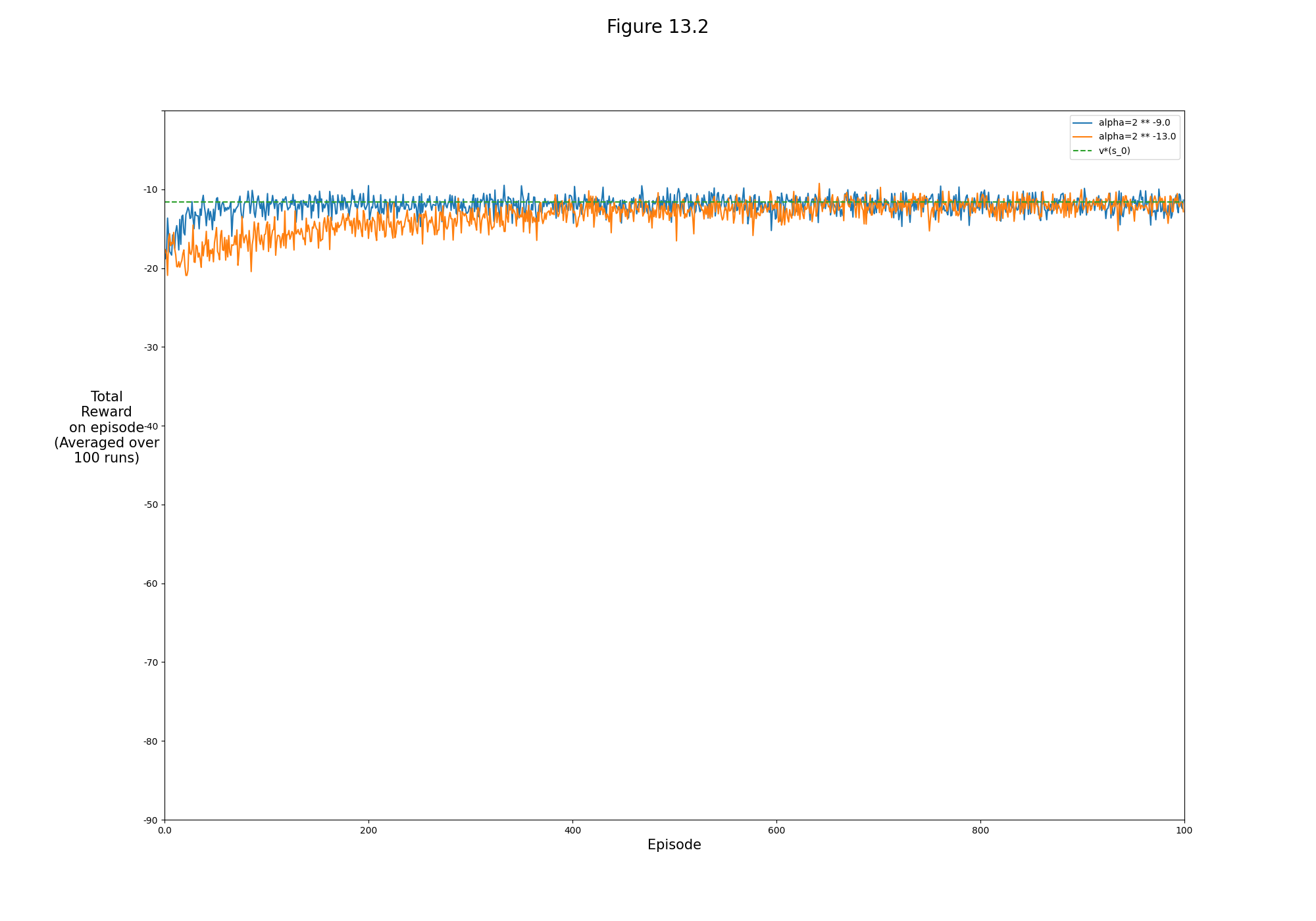
- Figure 13.2: REINFORCE with baseline on the short-corridor grid-world
{kind=link}
{kind=link}
2. Solution to all of the exercises (text answers)
To reproduce the results of an exercise, say exercise 2.5 do:
cd chapter2
python figures.py ex2.5-
Exercise2.5: Difficulties that sample-average methods have for nonstationary problems
-
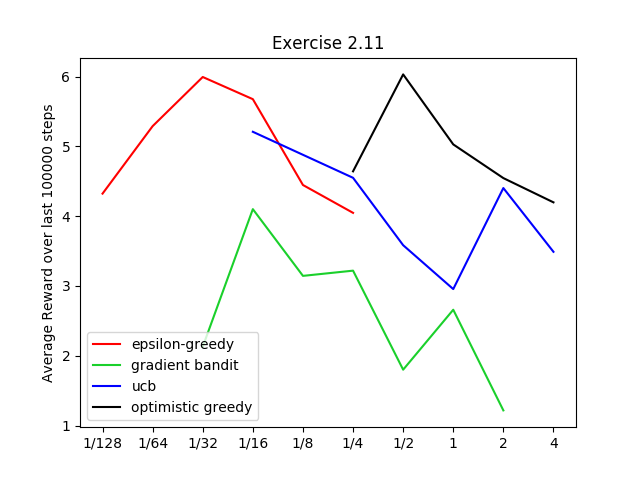
Exercise2.11: Figure analogous to Figure 2.6 for the nonstationary case
{kind=link}
{kind=link}
-
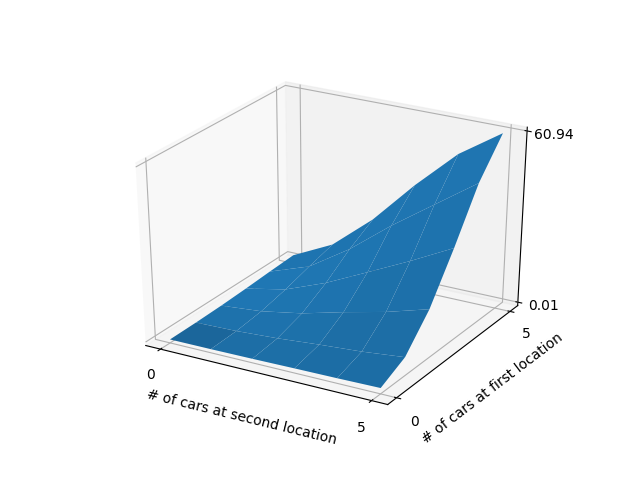
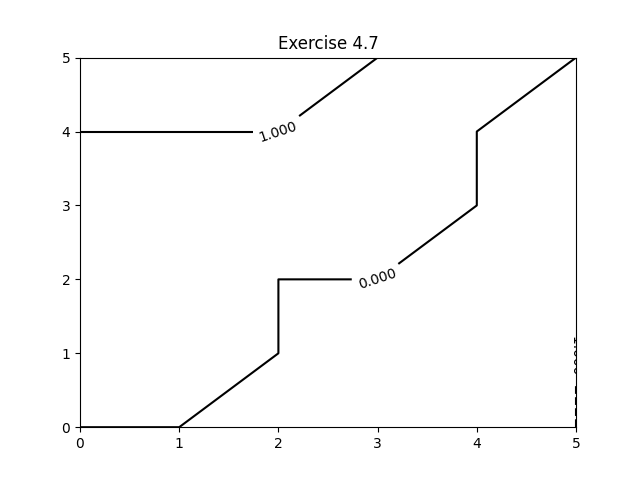
Exercise 4.7: Modified Jack's car rental problem (value function, policy)
-
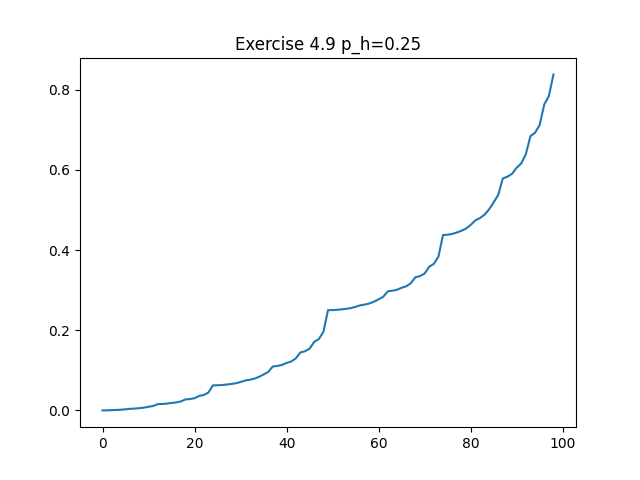
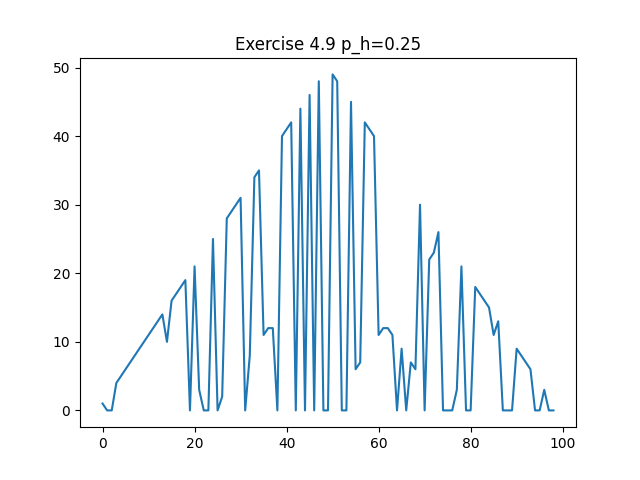
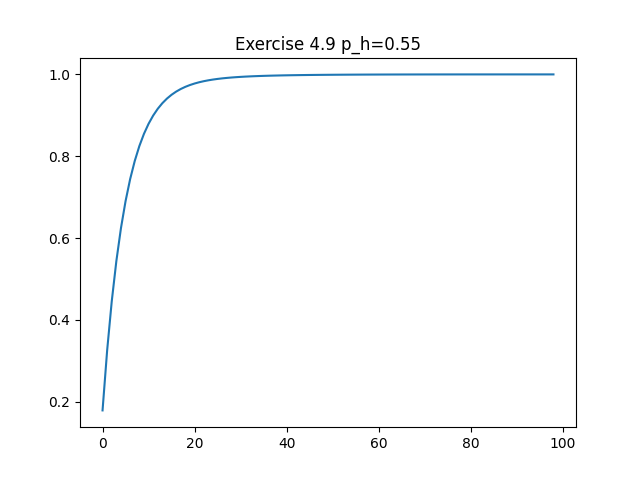
Exercise 4.9: Gambler’s problem with ph = 0.25 (value function, policy) and ph = 0.55 (value function, policy)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
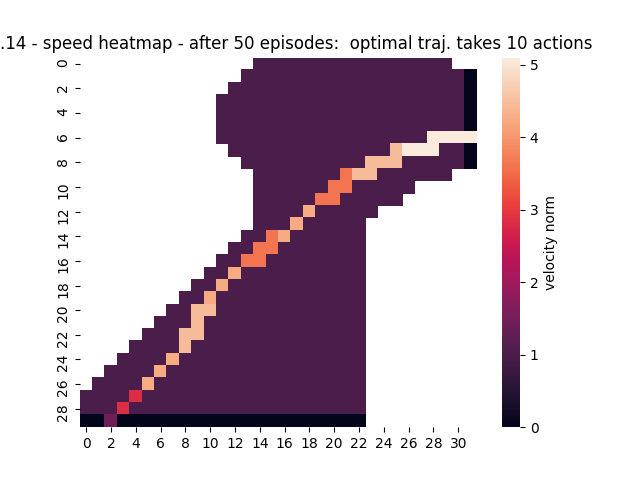{kind=link}
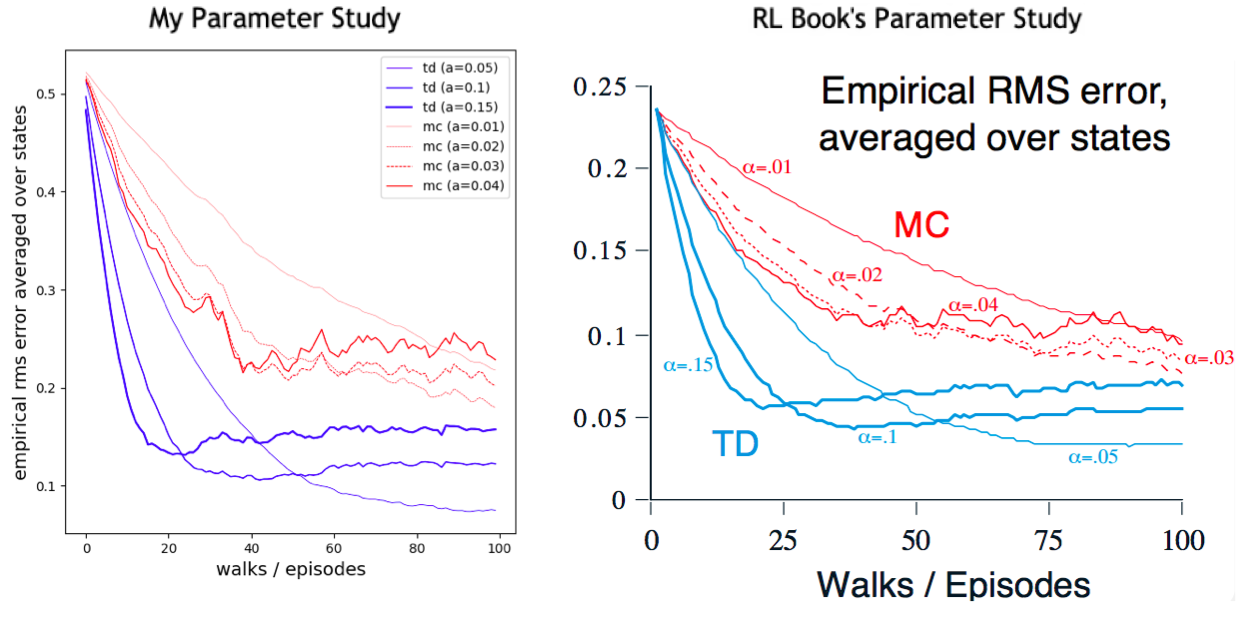
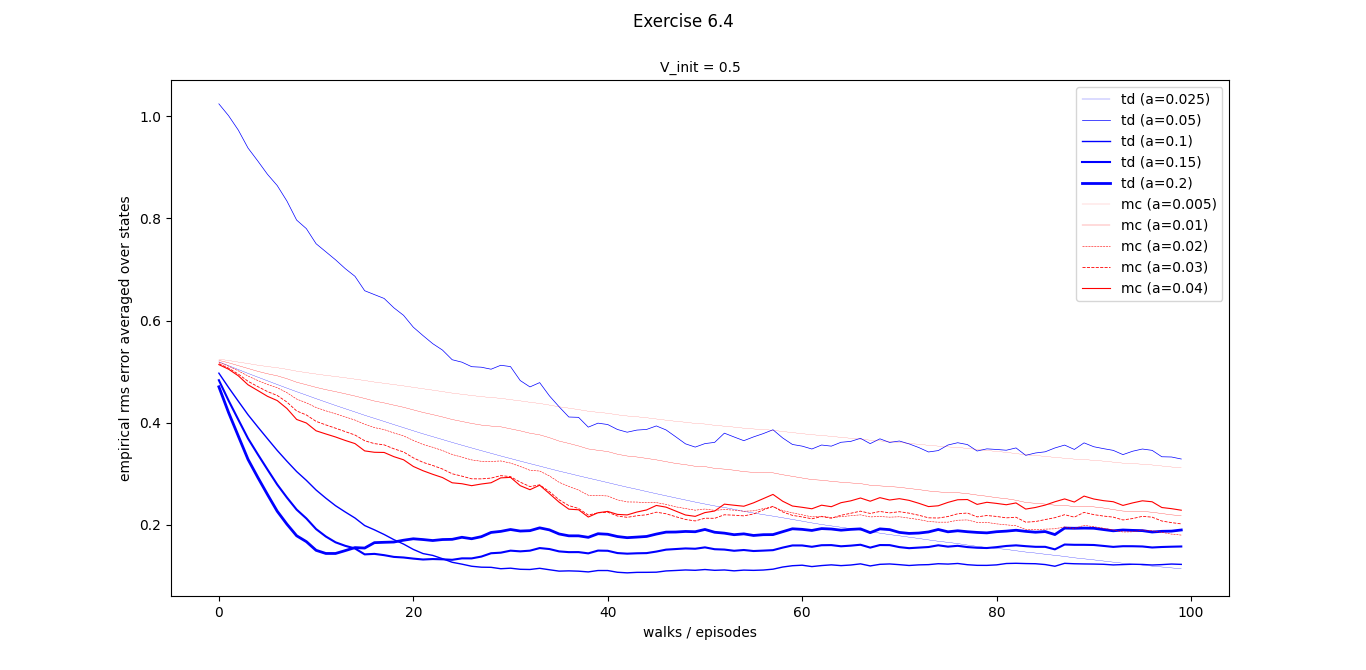
- Exercise 6.4: Wider range of values alpha
- Exercise 6.5: High alpha, 99ffect of initialization
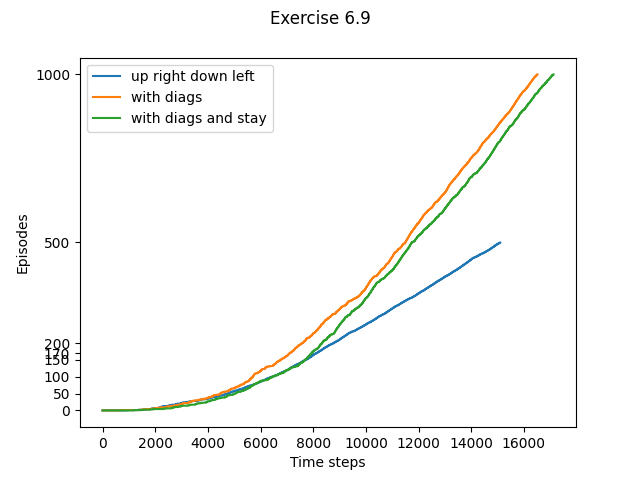
- Exercise 6.9: Windy Gridworld with King’s Moves
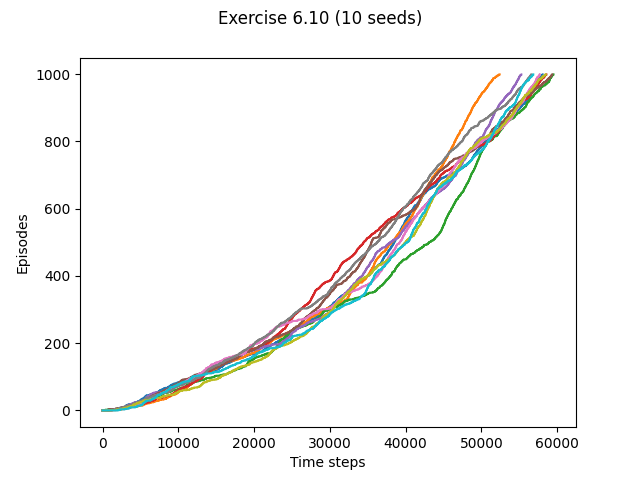
- Exercise 6.10: Stochastic Wind
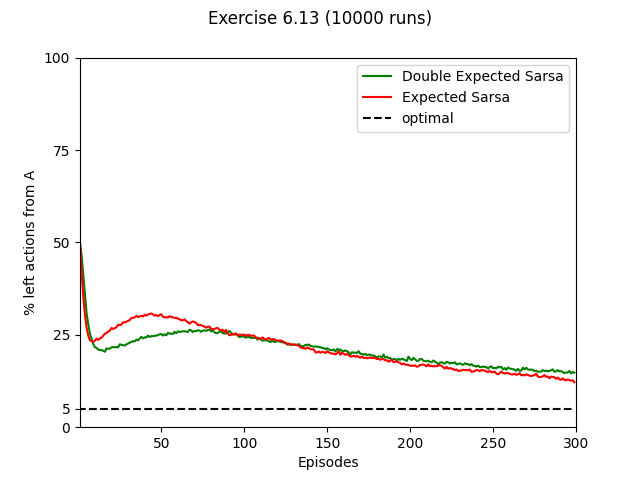
- Exercise 6.13: Double Expected Sarsa vs. Expected Sarsa
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Exercise7.2: Sum of TD error vs. n-step TD on 19-states random walk
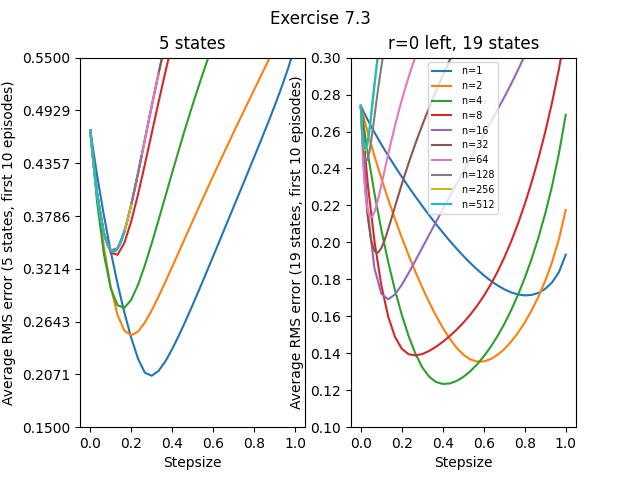
- Exercise7.3: 19 states vs. 5 states, left-side outcome of -1
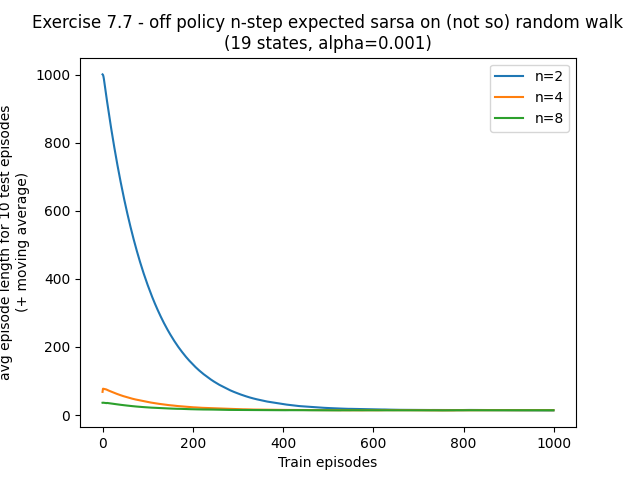
- Exercise7.7: Off-policy action-value prediction on a not-so-random walk
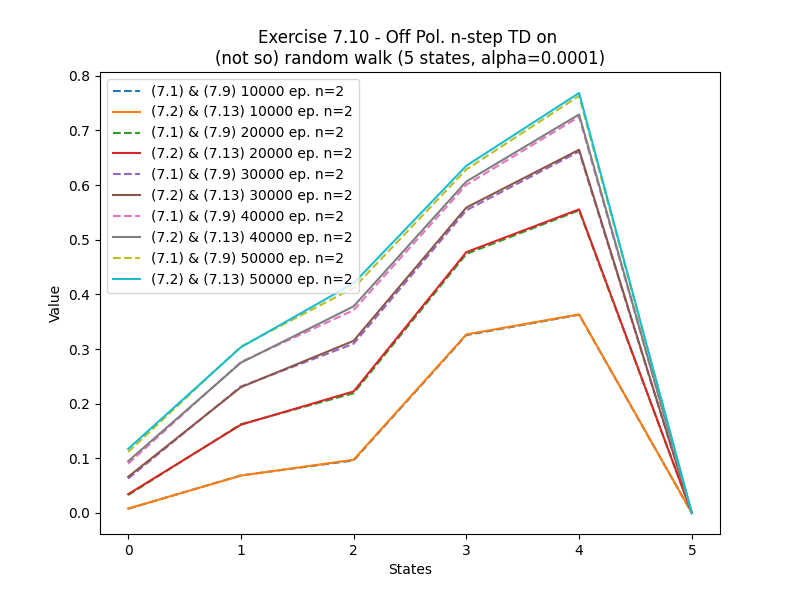
- Exercise7.10: Off-policy action-value prediction on a not-so-random walk
{kind=link}
{kind=link}
{kind=link}
{kind=link}
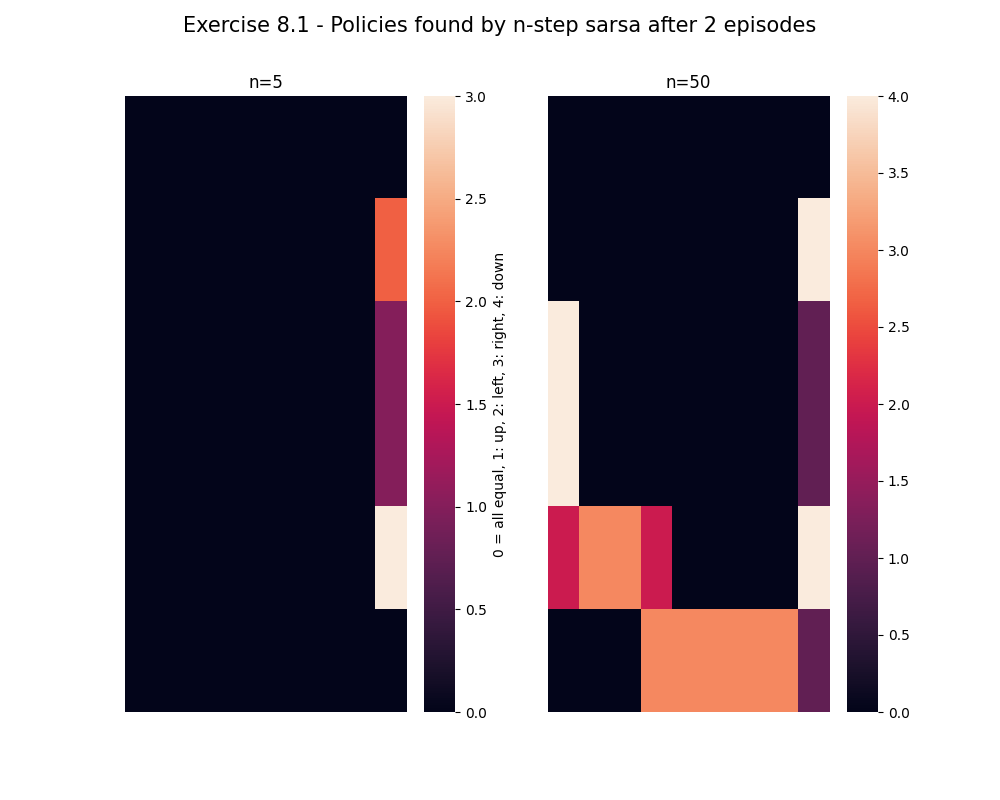
- Exercise8.1: n-step sarsa on the maze task
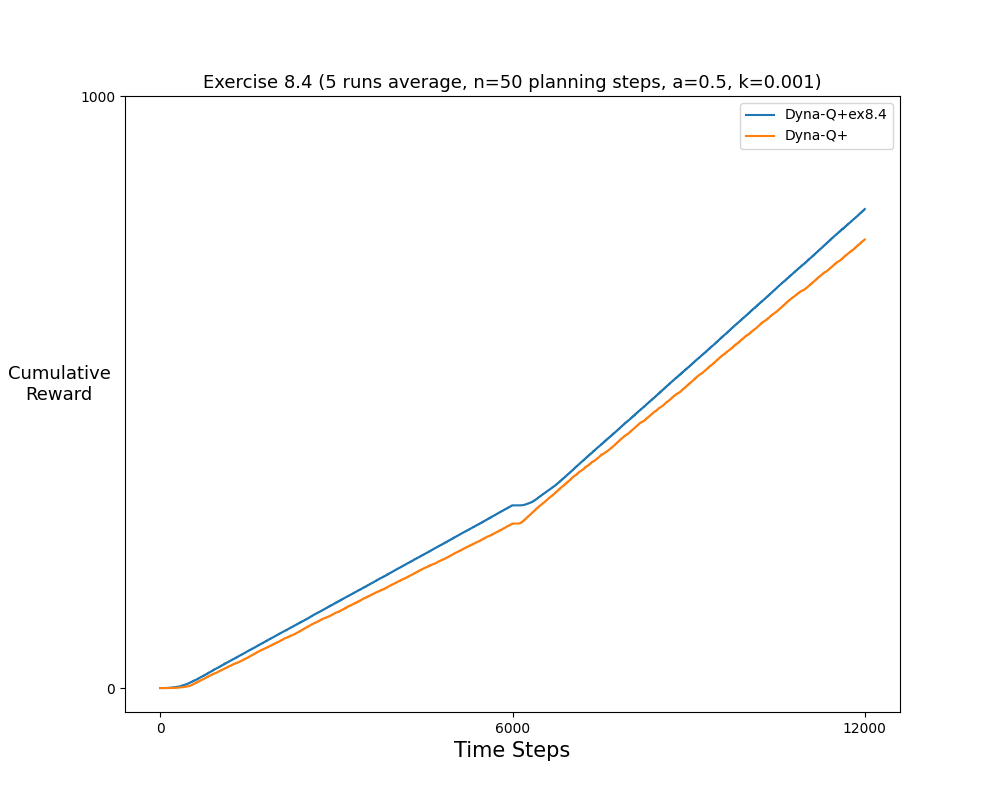
- Exercise8.4: Gridworld experiment to test the exploration bonus
{kind=link}
{kind=link}
{kind=link}
3. Anki flashcards (cf. this blog)
numpy
matplotlib
seabornAll of the code and answers are mine, except for mountain car's tile coding (url in the book).
This README is inspired from ShangtongZhang's repo.
- All of the chapters are self-contained.
- The environments use a gym-like API with methods:
s = env.reset()
s_p, r, d, dict = env.step(a)The entire thing (plots, exercises, anki cards (including reviewing)) took about 400h of focused work.