Now available on Huggingface https://huggingface.co/datasets/elenanereiss/german-ler
This work has been partially funded by the project Lynx, which has received funding from the EU's Horizon 2020 research and innovation programme under grant agreement no. 780602, see http://www.lynx-project.eu.

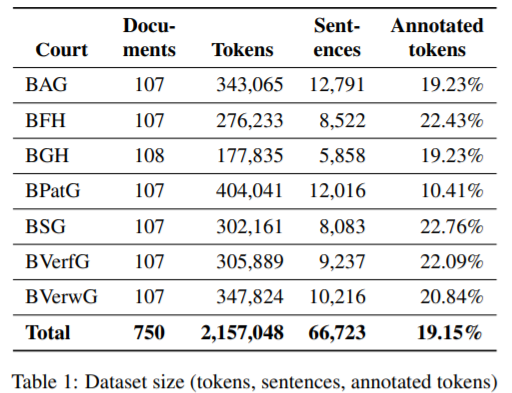
Court decisions from 2017 and 2018 were selected for the dataset, published online by the Federal Ministry of Justice and Consumer Protection. The documents originate from seven federal courts: Federal Labour Court (BAG), Federal Fiscal Court (BFH), Federal Court of Justice (BGH), Federal Patent Court (BPatG), Federal Social Court (BSG), Federal Constitutional Court (BVerfG) and Federal Administrative Court (BVerwG).
Annotation Guidelines (German)
The dataset consists of 66,723 sentences with 2,157,048 tokens. The sizes of the seven court-specific datasets varies between 5,858 and 12,791 sentences, and 177,835 to 404,041 tokens. The distribution of annotations on a per-token basis corresponds to approx. 19-23 %.
The dataset includes two different versions of annotations, one with a set of 19 fine-grained semantic classes and another one with a set of 7 coarse-grained classes. There are 53,632 annotated entities in total, the majority of which (74.34 %) are legal entities, the others are person, location and organization (25.66 %).

The dataset is freely available under the CC-BY 4.0 license. The output format is CoNLL-2002. Each line consists of two columns separated by a space. The first column contains a token and the second a tag in IOB2 format. The sentence boundary is marked with an empty line.
| Token | Tag |
|---|---|
| Am | O |
| 7. | O |
| März | O |
| 2006 | O |
| fand | O |
| ein | O |
| Treffen | O |
| der | O |
| saarländischen | B-INN |
| Landesregierung | I-INN |
| unter | O |
| Vorsitz | O |
| des | O |
| Ministerpräsidenten | O |
| Müller | B-RR |
| mit | O |
| Vertretern | O |
| der | O |
| Evangelischen | B-ORG |
| Kirche | I-ORG |
| im | I-ORG |
| Rheinland | I-ORG |
| und | O |
| der | O |
| Evangelischen | B-ORG |
| Kirche | I-ORG |
| der | I-ORG |
| Pfalz | I-ORG |
| statt | O |
| . | O |
- CRF-F with features
f; - CRF-FG with features und gazetteers
fg; - CRF-FGL with features, gazetteers and lookup table for word similarity
fgl.
- install sklearn-crfsuite and run (
modelName=f|fg|fgl):
python crf.py modelName trainPath testPath
- Models are saved in
models/.
- BiLSTM-CRF
crf; - BiLSTM-CRF with char embeddings from BiLSTM
blstm-crf; - BiLSTM-CNN-CRF with char embeddings from CNN
cnn-crf.
- install BiLSTM-CNN-CRF;
- copy
blstm.pyto folderemnlp2017-bilstm-cnn-crf/choose a model (modelName=crf|blstm-crf|cnn-crf) and run:
python blstm.py modelName trainPath devPath testPath
- Models are saved in
models/.
old version
absl-py==0.7.1
astor==0.8.0
bleach==3.1.0
gast==0.2.2
grpcio==1.23.0
h5py==2.9.0
html5lib==1.0.1
keras==2.2.4
keras-applications==1.0.8
keras-preprocessing==1.1.0
numpy==1.16.4
protobuf==3.9.1
pynif==0.1.4
scipy==1.2.1
six==1.12.0
sklearn-crfsuite==0.3.6
somajo==1.10.5
tensorboard==1.14.0
tensorflow==1.14.0
termcolor==1.1.0
werkzeug==0.15.4
Leitner, E. (2019). Eigennamen- und Zitaterkennung in Rechtstexten. Bachelor’s thesis, Universität Potsdam, Potsdam, 2.
@mastersthesis{mastersthesis,
author = {Elena Leitner},
title = {Eigennamen- und Zitaterkennung in Rechtstexten},
school = {Universität Potsdam},
year = 2019,
address = {Potsdam},
month = 2,}
Leitner, E., Rehm, G., and Moreno-Schneider, J. (2019). Fine-grained Named Entity Recognition in Legal Documents. In Maribel Acosta, et al., editors, Semantic Systems. The Power of AI and Knowledge Graphs. Proceedings of the 15th International Conference (SEMANTiCS2019), number 11702 in Lecture Notes in Computer Science, pages 272–287, Karlsruhe, Germany, 9. Springer. 10/11 September 2019.
@inproceedings{leitner2019fine,
author = {Elena Leitner and Georg Rehm and Julian Moreno-Schneider},
title = {{Fine-grained Named Entity Recognition in Legal Documents}},
booktitle = {Semantic Systems. The Power of AI and Knowledge
Graphs. Proceedings of the 15th International Conference
(SEMANTiCS 2019)},
year = 2019,
editor = {Maribel Acosta and Philippe Cudré-Mauroux and Maria
Maleshkova and Tassilo Pellegrini and Harald Sack and York
Sure-Vetter},
keywords = {aip},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
number = {11702},
address = {Karlsruhe, Germany},
month = 9,
note = {10/11 September 2019},
pages = {272--287},
pdf = {https://link.springer.com/content/pdf/10.1007%2F978-3-030-33220-4_20.pdf}}
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
