{kind=link}
{kind=link}
{kind=link}
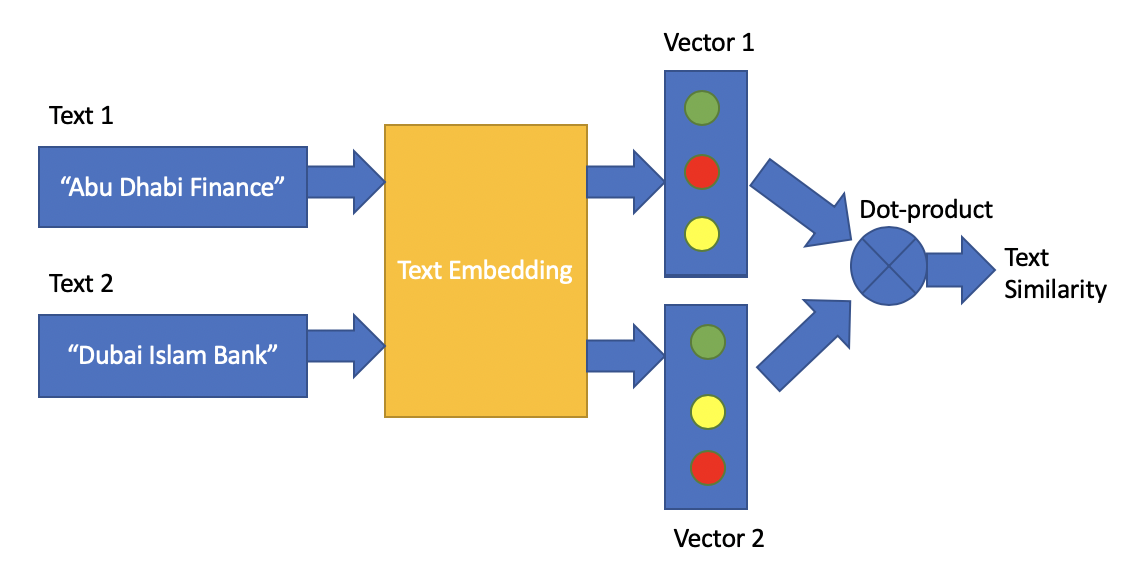
Embedding a text to a vector by pre-trained BERT word embeddings and pooling layers
Using the ebedding vectors of two texts to measure the their similarity, by the dot-product of the two vectors

git clone https://github.com/gaoyuanliang/bert_text_embedding.git
cd bert_text_embedding
pip3 install -r requirements.txt
wget https://storage.googleapis.com/bert_models/2019_05_30/wwm_uncased_L-24_H-1024_A-16.zip
unzip wwm_uncased_L-24_H-1024_A-16.zipWithin one line of code, you can convert a text to a list of 2048 numbers. We call this list the embedding vector.
>>> import numpy
>>> from jessica_text_embedding import text_embedding
>>>
>>> x1 = text_embedding(u"Abu Dhabi Finance")
>>> x2 = text_embedding(u"Dubai Islam Bank")
>>> x3 = text_embedding(u"This is a negative")check the embedding vector and the length of the vector
>>> print(x1)
[0.01866205781698227, 0.20125442743301392, -0.2105996310710907, -0.5797083973884583, 0.5044286847114563, -0.00011515617370605469, -0.9871041178703308, 0.45565372705459595,..., 1.3363279104232788]
>>> len(x1)
2048check the similarity of (x1,x2) and (x1,x3) measured by the dot-product
>>> numpy.dot(numpy.array(x1), numpy.array(x2))
626.4380145019333
>>> numpy.dot(numpy.array(x1), numpy.array(x3))
591.97747068839The similarity between "Abu Dhabi Finance" and "Dubai Islam Bank" is largher than its similarity to "This is a negative". Since these three texts have no overlapping words at all, why "Abu Dhabi Finance" is more similar to "Dubai Islam Bank" than "This is a negative"? Because the BERT word embedding has the semantic similarities.
build docker image
git clone https://github.com/gaoyuanliang/bert_text_embedding.git
cd bert_text_embedding
docker build -t jessica_text_embedding:1.0.1 .run the docker image
docker run -it -p 5573:9000 --memory="256g" [DOCKER IMAGE ID]check the service at http://localhost:5573/

Building more layers on top of the embedding of words to train these layers by supervision of similar/dissimilar pairs of texts.
If you are working on similar projects, I am happy to help. Contact me by yanliang.kaust@gmail.com