![]()
Topic modeling is your turf too.
Contextual topic models with representations from transformers.
- Provide simple, robust and fast implementations of existing approaches (BERTopic, Top2Vec, CTM) with minimal dependencies.
- Implement state-of-the-art approaches from my papers. (papers work-in-progress)
- Put all approaches in a broader conceptual framework.
- Provide clear and extensive documentation about the best use-cases for each model.
- Make the models' API streamlined and compatible with topicwizard and scikit-learn.
- Develop smarter, transformer-based evaluation metrics.
Note: This package is still work in progress and scientific papers on some of the novel methods (e.g., decomposition-based methods) are currently undergoing peer-review. If you use this package and you encounter any problem, let us know by opening relevant issues.
- Model Implementation
- Pretty Printing
- Implement visualization utilites for these models in topicwizard
- Thorough documentation
- Dynamic modeling (currently
GMMandClusteringTopicModelothers might follow) - Publish papers ⏳ (in progress..)
- High-level topic descriptions with LLMs.
- Contextualized evaluation metrics.
Basics (Documentation)
Turftopic can be installed from PyPI.
pip install turftopicIf you intend to use CTMs, make sure to install the package with Pyro as an optional dependency.
pip install turftopic[pyro-ppl]Turftopic's models follow the scikit-learn API conventions, and as such they are quite easy to use if you are familiar with scikit-learn workflows.
Here's an example of how you use KeyNMF, one of our models on the 20Newsgroups dataset from scikit-learn.
from sklearn.datasets import fetch_20newsgroups
newsgroups = fetch_20newsgroups(
subset="all",
remove=("headers", "footers", "quotes"),
)
corpus = newsgroups.dataTurftopic also comes with interpretation tools that make it easy to display and understand your results.
from turftopic import KeyNMF
model = KeyNMF(20).fit(corpus)Turftopic comes with a number of pretty printing utilities for interpreting the models.
To see the highest the most important words for each topic, use the print_topics() method.
model.print_topics()| Topic ID | Top 10 Words |
|---|---|
| 0 | armenians, armenian, armenia, turks, turkish, genocide, azerbaijan, soviet, turkey, azerbaijani |
| 1 | sale, price, shipping, offer, sell, prices, interested, 00, games, selling |
| 2 | christians, christian, bible, christianity, church, god, scripture, faith, jesus, sin |
| 3 | encryption, chip, clipper, nsa, security, secure, privacy, encrypted, crypto, cryptography |
| .... |
# Print highest ranking documents for topic 0
model.print_representative_documents(0, corpus, document_topic_matrix)| Document | Score |
|---|---|
| Poor 'Poly'. I see you're preparing the groundwork for yet another retreat from your... | 0.40 |
| Then you must be living in an alternate universe. Where were they? An Appeal to Mankind During the... | 0.40 |
| It is 'Serdar', 'kocaoglan'. Just love it. Well, it could be your head wasn't screwed on just right... | 0.39 |
model.print_topic_distribution(
"I think guns should definitely banned from all public institutions, such as schools."
)| Topic name | Score |
|---|---|
| 7_gun_guns_firearms_weapons | 0.05 |
| 17_mail_address_email_send | 0.00 |
| 3_encryption_chip_clipper_nsa | 0.00 |
| 19_baseball_pitching_pitcher_hitter | 0.00 |
| 11_graphics_software_program_3d | 0.00 |
Turftopic does not come with built-in visualization utilities, topicwizard, an interactive topic model visualization library, is compatible with all models from Turftopic.
pip install topic-wizardBy far the easiest way to visualize your models for interpretation is to launch the topicwizard web app.
import topicwizard
topicwizard.visualize(corpus, model=model)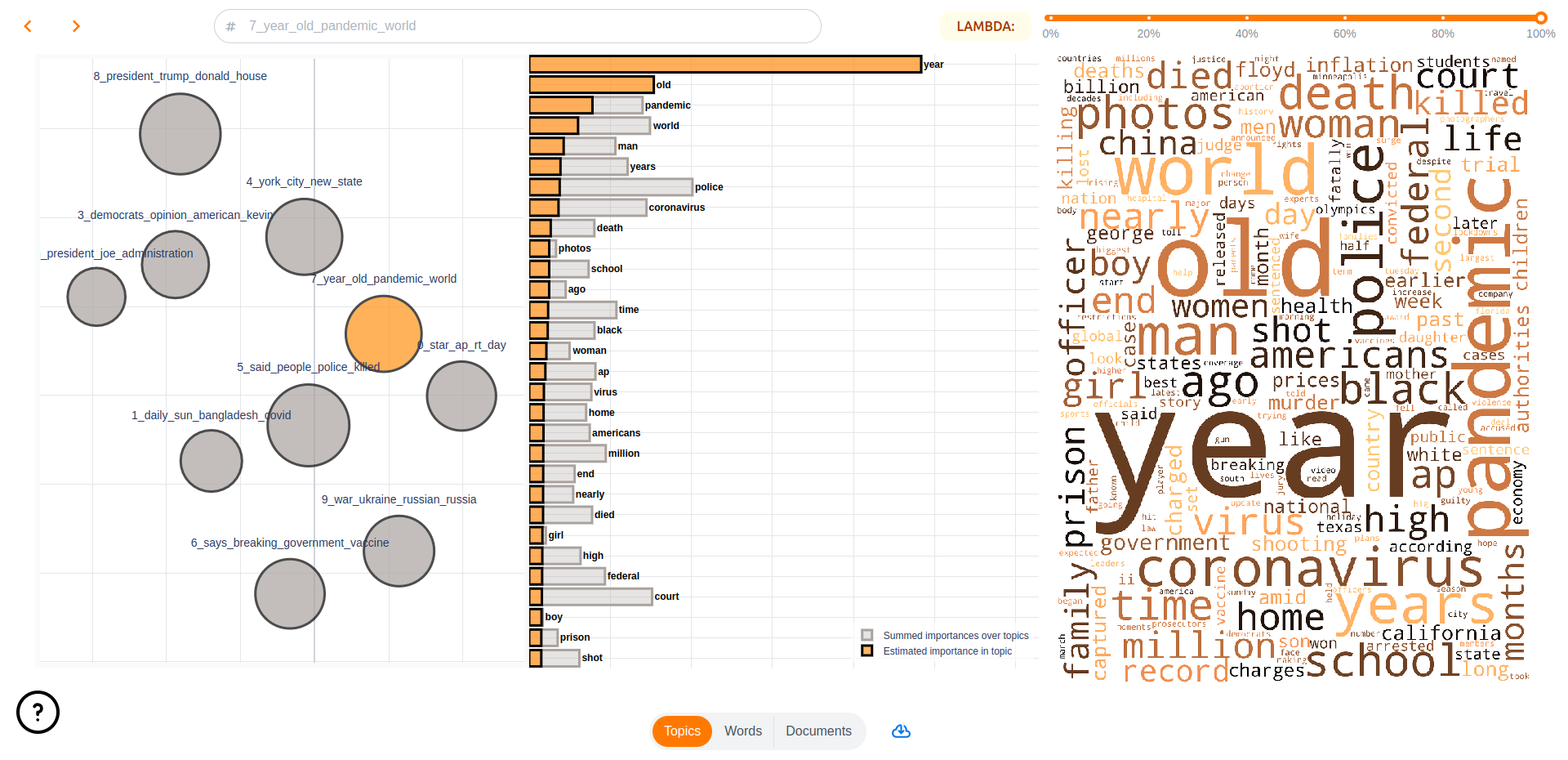
Alternatively you can use the Figures API in topicwizard for individual HTML figures.
| Model | Description | Usage |
|---|---|---|
| KeyNMF | Non-negative Matrix Factorization enhanced with keyword extraction using sentence embeddings | model = KeyNMF(n_components=10).fit(corpus) |
| GMM | Gaussian Mixture Model over contextual embeddings + post-hoc term importance estimation | model = GMM(n_components=10).fit(corpus) |
| S³ | Separates semantic signals, aka. axes of semantics in a corpus using independent component analysis. | model = SemanticSignalSeparation(n_components=10).fit(corpus) |
| Autoencoding Models | Learn topics using amortized variational inference enhanced by contextual representations. | model = AutoEncodingTopicModel(n_components=10, combined=False).fit(corpus) |
| Clustering Models | Clusters semantic embeddings, and estimates term importances for clusters. | model = ClusteringTopicModel(feature_importance="ctfidf").fit(corpus) |
For extensive comparison see our Model Overview.