🚧
🚧

Viberary is a search engine that recommends you books based not on genre or title, but vibe by performing semantic search across a set of learned embeddings on a dataset of books from Goodreads and their metadata.
It returns a list of book recommendations based on the vibe of the book that you put in. So you don't put in "I want science fiction", you'd but in "atmospheric, female lead, worldbuilding, funny" as a prompt, and get back a list of books. This project came out of experiences I had where recommendations for movies, TV, and music have fairly been good, but book recommendations are always a problem.
Viberary is now in maintenance mode!
For much, much more detail see the how page on the project website.
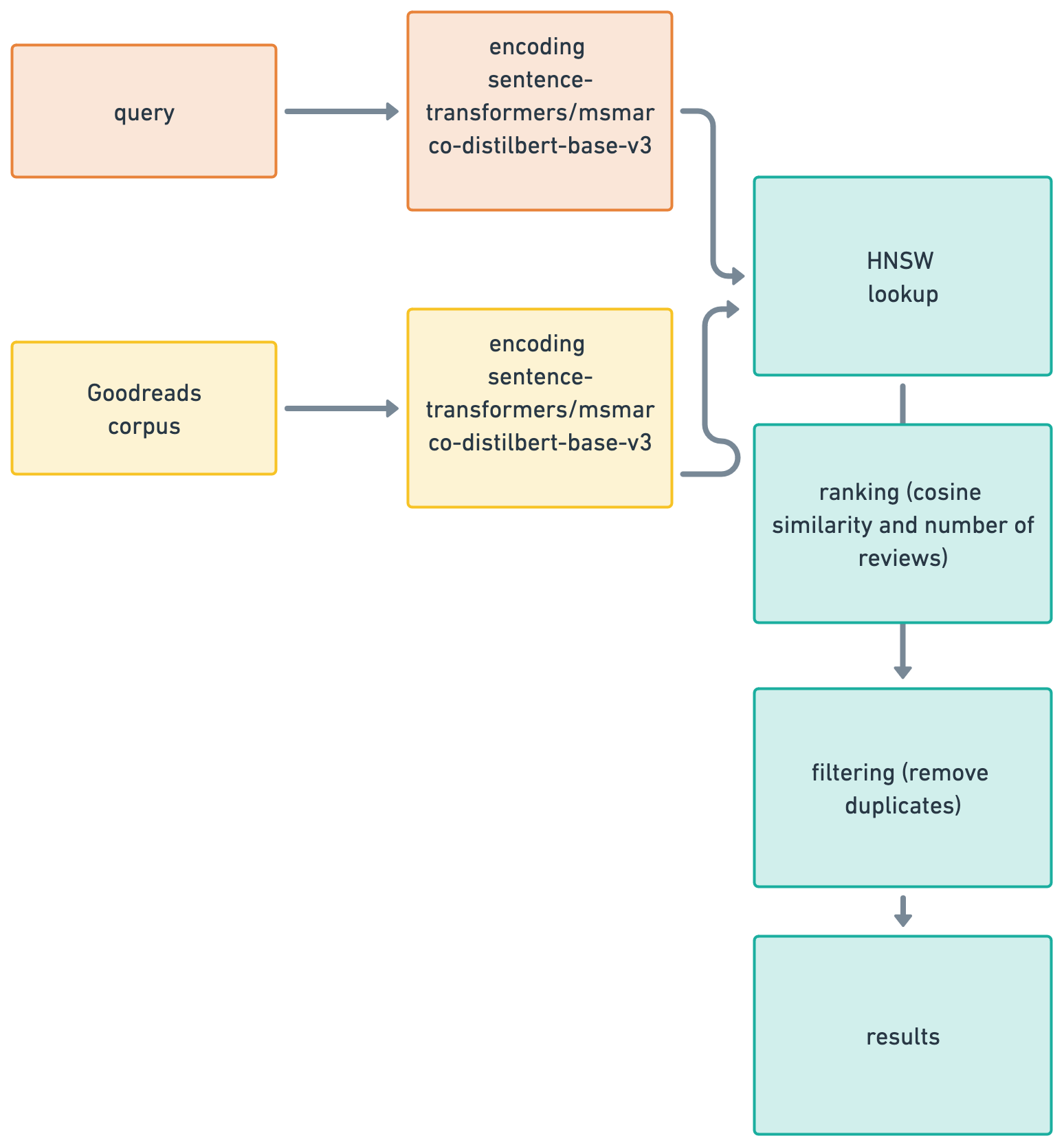
It's a two-tower semantic retrieval model that encodes both the query and the corpus using the Sentence Transformers pretrained asymmetric MSMarco Model.
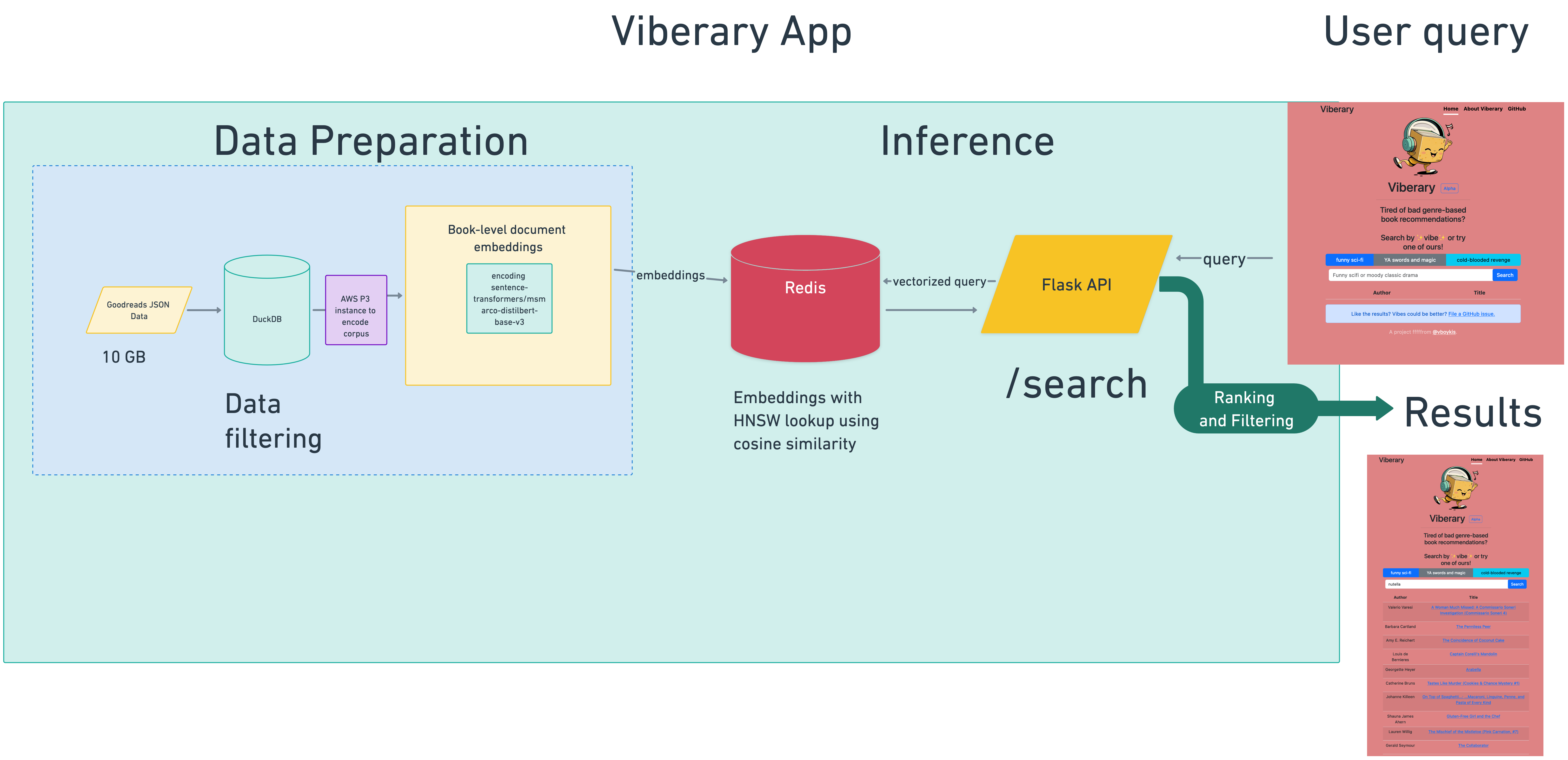
The training data is generated locally in DuckDB and the model is converted to ONNX for low-latency inference, with corpus embeddings learned on AWS P3 instances against the same model and stored in Redis and retrieved using the Redis Search module using the HNSW algorithm included as part of the Redis search module. Results are served through a Flask API running Gunicorn and served to a Bootstrap front-end.
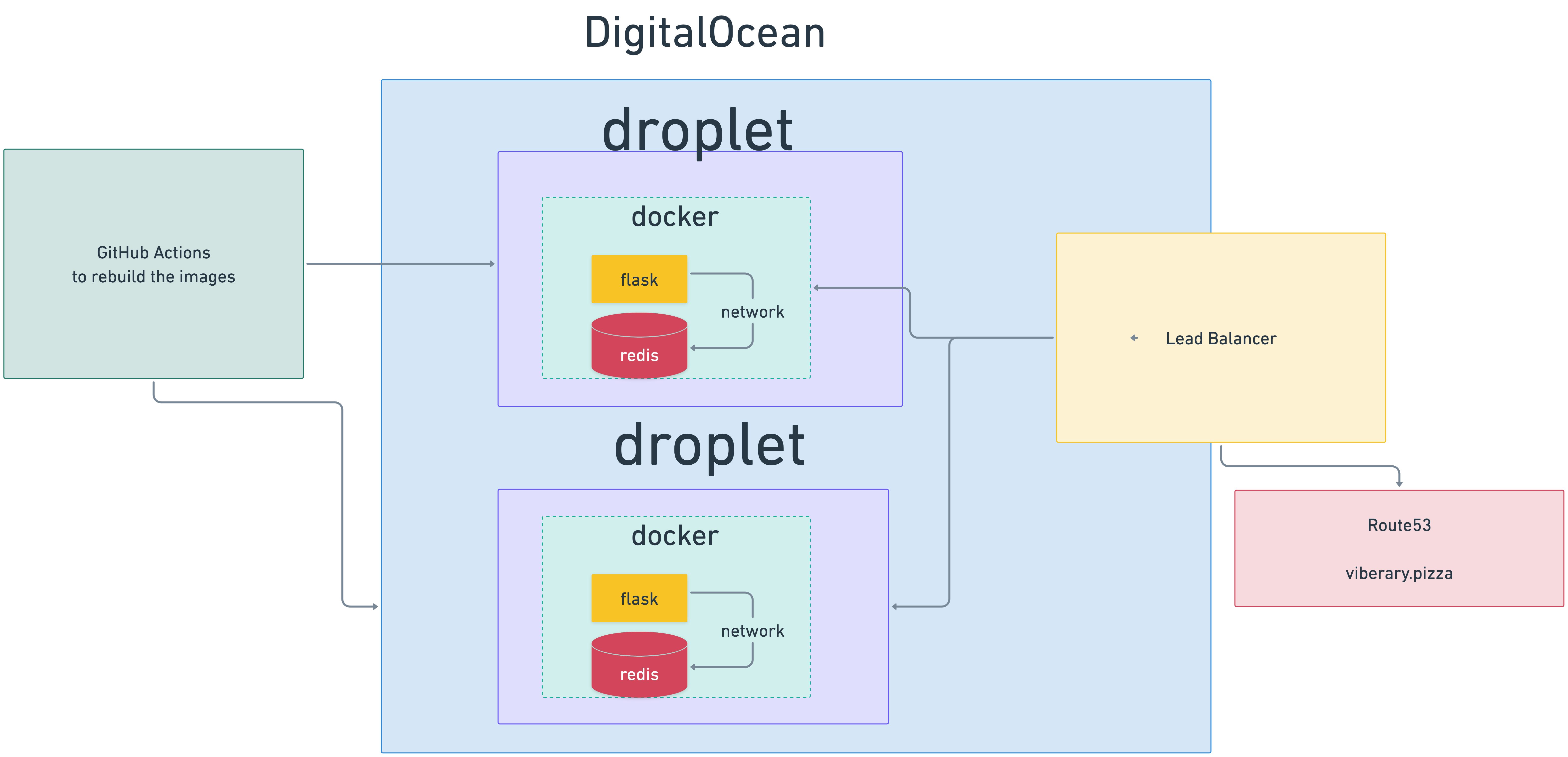
It's served from one Digital Ocean droplets behind a Digital Ocean load balancer and Nginx, as a Dockerized application with networking spun up through Docker compose between a web server and Redis image, with data persisted to external volumes in DigitalOcean, with AWS Route53 serving as the domain registrar and load balancer router.
The artifact is generated through GitHub actions on the main branch of the repo. I manually pull the new docker image on the droplet.
- Fork/clone the repo
- Go to the project root (
viberary) - Download the corpus embeddings file to
/viberary/src/training_data. - Go to the root of the repo and run
make onnxto generate the runnable model artifact. make build- Builds the docker imagemake up-arm (or make up-intel)- Docker compose running in background depending on your system architecturemake embed- indexes the embeddings once the web server is runninglocalhost:8000- Loads the web server
- Get model artifacts from here: https://github.com/veekaybee/viberary_model and add them to
sentence_transformers make build- Builds the docker imagemake up-arm( or make up-intel)- Docker compose running in background depending on your system architecturemake embed- indexes the embeddings once the web server is runninglocalhost:8000- Loads the web server
- cd
eval
make logs for logs
src- where all the code isapi- Flask sever that calls the model, includes a search endpoint. Eventually will be rewritten in Go (for performance reasons)training_data- generated training datamodel- The actual BERT model. Includes data generated for generating embeddings and also the code used to generate the embeddings, on an EC2 instance.indexincludes an indexer which indexes embeddings generated inmodelinto a Redis instance. Redis and the Flask app talk to each other through an app running viadocker-composeand theDockerfilefor the main app instance.search- performs the search calls from apistore- Small model store to interface with DO Spacesconf- There are some utilities such as data directory access, io operations and a separate indexer that indexes titles into Redis for easy retrieval by the applicationnotebooks- Exploration and development of the input data, various concepts, algorithms, etc. The best resource there is this notebook, which covers the end-to-end workflow of starting with raw data, processing in DuckDB, learning a Word2Vec embeddings model, (Annotated output is here.) and storing and querying those embeddings in Redis Search. This is the solution I eventually turned into the application directory structure.
docs- This serves and rebuildsviberary.pizza
Please follow instructions above for building and testing locally, make sure all unit tests pass and your branch passes locally before issuing a PR.
- My paper on embeddings and its bibliography
- Towards Personalized and Semantic Retrieval: An End-to-End Solution for E-commerce Search via Embedding Learning
- PinnerSage
- My Research Rabbit Collection
UCSD Book Graph, with the critical part being the user-generated shelf labels.. Sample row: Note these are all encoded as strings!
{
"isbn": "0413675106",
"text_reviews_count": "2",
"series": [
"1070125"
],
"country_code": "US",
"language_code": "",
"popular_shelves": [
{
"count": "2979",
"name": "to-read"
},
{
"count": "291",
"name": "philosophy"
},
{
"count": "187",
"name": "non-fiction"
},
{
"count": "80",
"name": "religion"
},
{
"count": "76",
"name": "spirituality"
},
{
"count": "76",
"name": "nonfiction"
}
],
"asin": "",
"is_ebook": "false",
"average_rating": "3.81",
"kindle_asin": "",
"similar_books": [
"888460"
],
"description": "Taoist philosophy explained using examples from A A Milne's Winnie-the-Pooh.",
"format": "",
"link": "https://www.goodreads.com/book/show/89371.The_Te_Of_Piglet",
"authors": [
{
"author_id": "27397",
"role": ""
}
],
"publisher": "",
"num_pages": "",
"publication_day": "",
"isbn13": "9780413675101",
"publication_month": "",
"edition_information": "",
"publication_year": "",
"url": "https://www.goodreads.com/book/show/89371.The_Te_Of_Piglet",
"image_url": "https://s.gr-assets.com/assets/nophoto/book/111x148-bcc042a9c91a29c1d680899eff700a03.png",
"book_id": "89371",
"ratings_count": "11",
"work_id": "41333541",
"title": "The Te Of Piglet",
"title_without_series": "The Te Of Piglet"
}See issues.