With a strong educational foundation in Software Engineering, including a Master's degree from IIT, and a professional journey spanning over 6 years, I specialize in backend development, with proficiency in Golang, Python, and TypeScript/JavaScript. I have a deep understanding of cloud infrastructure management, having worked with Aliyun and AWS, leveraging services such as Lambda, EKS, ECS, ECR, EC2, SSM, Route 53, and ElasticCache.
Beyond my formal qualifications, I'm an enthusiastic server enthusiast who maintains a personal Kubernetes cluster that stretches across various cloud providers and local servers. This not only keeps my technical skills sharp but also reflects my unwavering commitment to continuous learning and innovation.
I'm not just a technologist; I'm also a contributor to the tech community. I share my knowledge and insights through technical articles on Medium, accessible at Medium Profile. This is my way of fostering a sense of community and demonstrating my genuine passion for technology.
2017-02-28 How to build a scaleable crawler to crawl million pages with a single machine in just 2 hours
2023-08-01 How to efficiently scrape millions of Google Businesses on a large scale using a distributed crawler
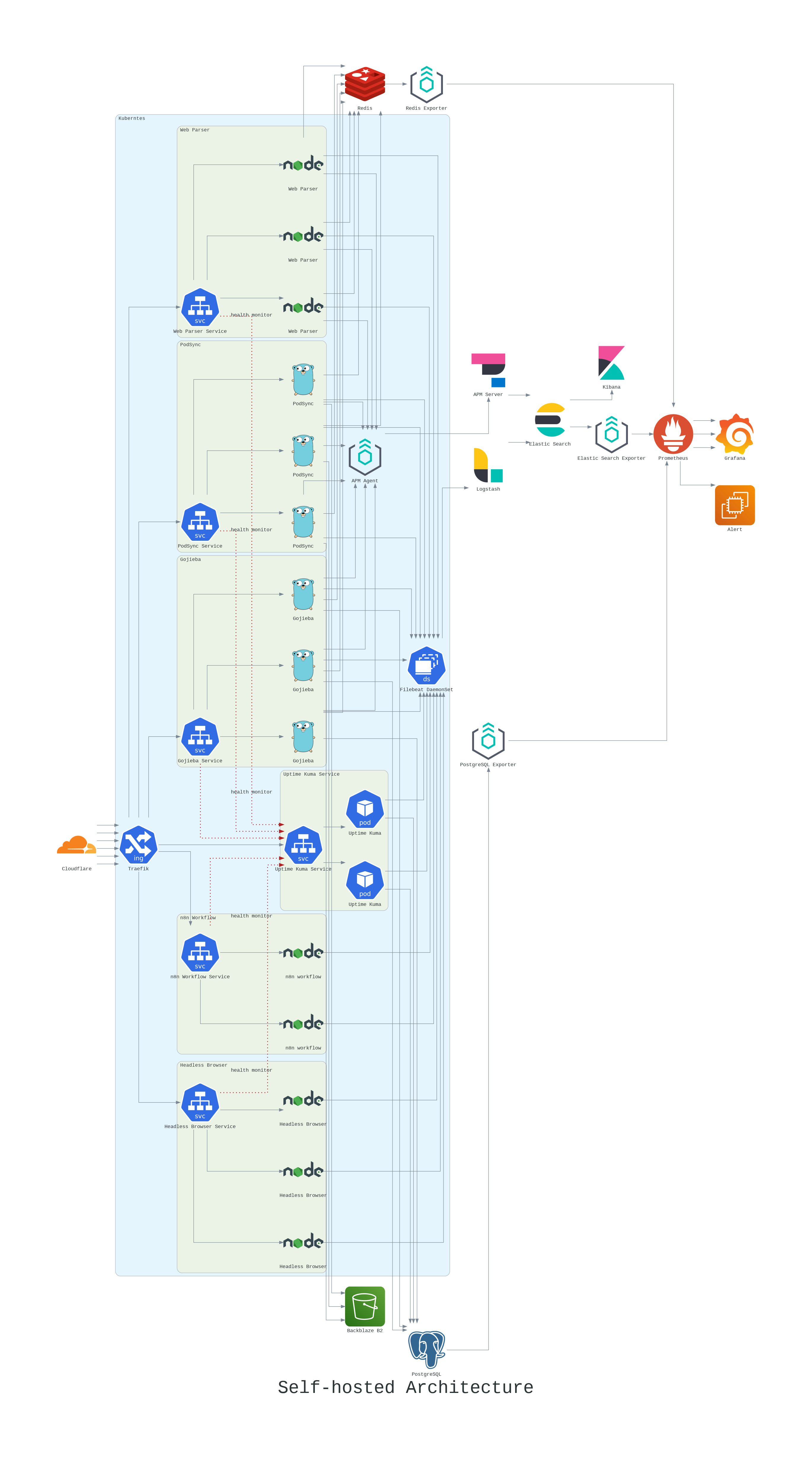
2023-10-13 The Architecture of a Web Crawler: Building a Google-Inspired Distributed Web Crawler. Part 1
2023-10-14 Web Crawling at Scale: Navigating Billions of URLs with Efficiency