A language model is the one where given an input sentence, the model outputs a probability of how correct that sentence is. This is extensively used in speech recognition, sentence generation and machine translation systems where it outputs the sentences that are likely.
Steps to build a language model:
- Build a training set using a large corpus of english text
- Tokenize each sentence to build a vocabulary
- Map each word in the sentence using any encoding mechanism
- Replace uncommon words with , in which case model the chance of the unknown word instead of the specific word.
- Build an RNN model where output is the softmax probability for each word in the dictionary

At t time step, RNN is estimating P(y| y<1>,y<2>,…,y<t−1>). Training set is formed in a way where x<2> = y<1> and x<3> = y<2> and so on. In short, the output sentence lags behind the input sentence by one time step. The optimization algorithm followed is always Stochastic Gradient Descent (one sequence at a time).
To get probability for a random sequence, break down the joint probability distribution P(y1, y2, y3, ...) as a product of conditionals, P(y1) * P(y2 | y1) * P(y3 | y1, y2).
NOTE: In vanilla language model as described above, word is a basic building block. In character level language model, the basic unit/ lowest level is a character, which makes building a dictionary very easy (finite number of characters)
Once the model is trained, we can sample new text(characters). The process of generation is explained below:
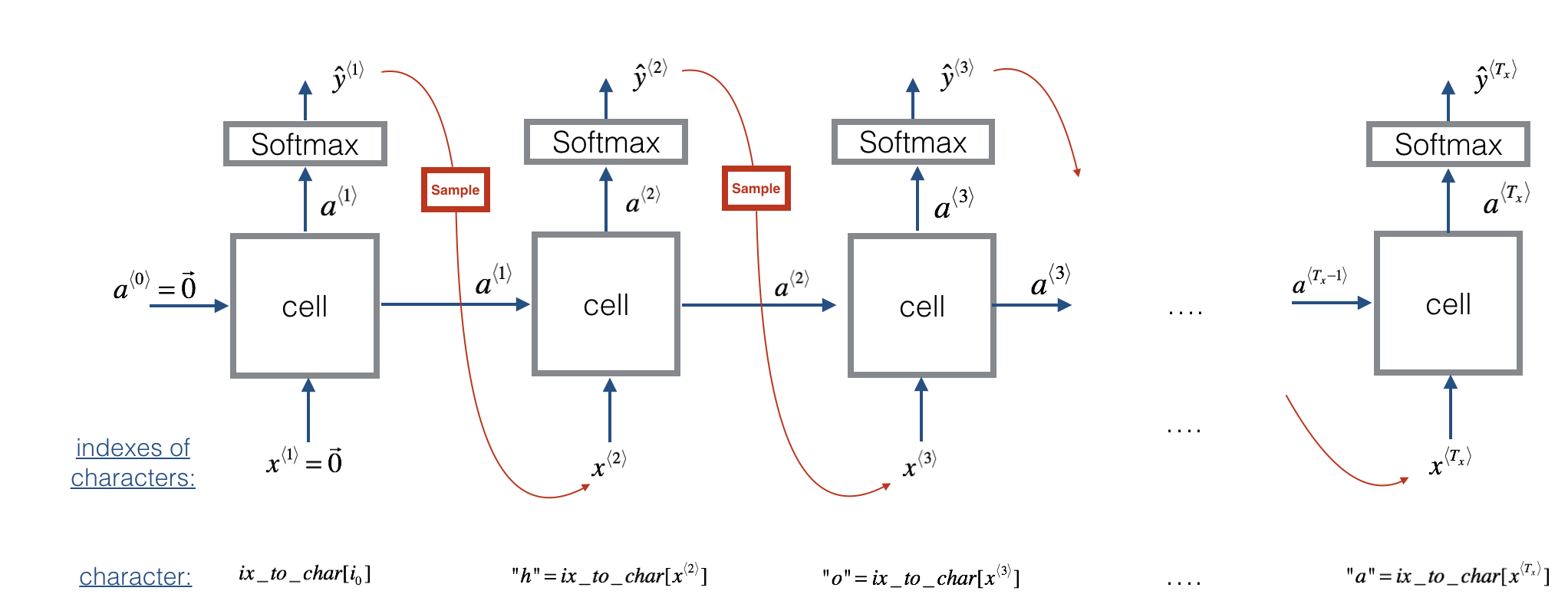
Steps:
- Pass the network the first "dummy" input x⟨1⟩=0 ⃗ (the vector of zeros). This is the default input before we've generated any characters. We also set a⟨0⟩=0 ⃗
- Use the probabilities output by the RNN to randomly sample a chosen word (using np.random.choice) for that time-step as y
- Pass this selected word to the next time-step as x<2>
Some of the names generated:
- Macaersaurus
- Edahosaurus
- Trodonosaurus
- Ivusanon
- Trocemitetes
If you observe carefully, our model has learned to capture saurus, don,aura, tor at the end of every dinosaur name
TODO: Use LSTM in-place of RNNs with help of Keras
Place the training data (dinosaur names) in-place of dinos.txt.
Run main.py, which follows 3 steps:
- Preprocessing the data
- Building a vocabulary
- Run the model
To generate the names out-of-the-box, run
python main.py