使用torch实现了百度在ACL2021上提出的纠错模型(结合拼音特征的Softmask策略的中文错别字纠错的下游任务网络)。
但是百度并没有开源它在这个任务上的预训练模型,所以这个项目只能直接拿的Ernie1.0和Ernie3.0来试一试,结果显示,效果一般。
- torch==1.10.1+cu102
- tqdm==4.48.2
- transformers==4.20.0
- scikit-learn==0.24.2
- onnx==1.10.2
- onnx-tf==1.9.0
- tensorflow-gpu==2.3.0
- pandas==1.3.5
- pypinyin==0.46.0
其他环境见requirements.txt
| 日期 | 版本 | 描述 |
|---|---|---|
| 2020-08-13 | v1.0.0 | 初始仓库 |

完成环境安装后,需要在config.py文件中修改配置,然后点击main.py运行即可
# [train, interactive_predict, test, convert2tf]
mode = 'train'
# 使用GPU设备
use_cuda = True
cuda_device = -1
configure = {
'test_file': 'datasets/sighan_test/sighan15.txt',
'checkpoints_dir': 'checkpoints',
'pretrained_model': 'nghuyong/ernie-1.0',
'optimizer': 'AdamW',
'max_sequence_length': 128,
'learning_rate': 5e-5,
'epochs': 30,
'batch_size': 20,
'model_name': 'ernie4csc-1.0.pkl',
# 是否进行warmup
'warmup': True,
# warmup方法,可选:linear、cosine
'scheduler_type': 'linear',
# warmup步数,-1自动推断为总步数的0.1
'num_warmup_steps': -1,
'print_per_batch': 200,
'is_early_stop': False,
'patient': 3,
}
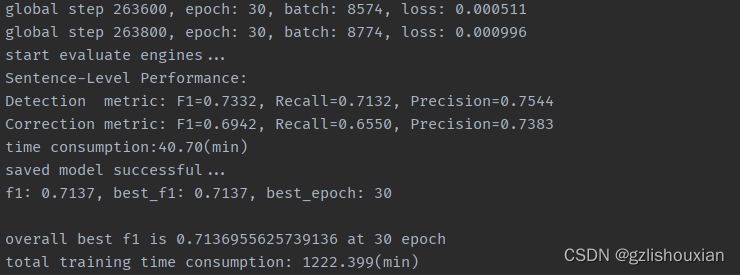
- 训练结果
# [train, interactive_predict, test, convert2tf]
mode = 'interactive_predict'
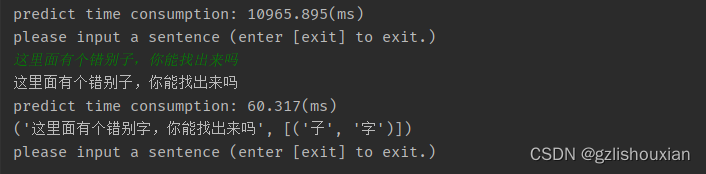
- 预测结果
GitHub:ERNIE for Chinese Spelling Correction
GitHub:orangetwo/ernie-csc
相关问题欢迎在公众号反馈:
