Explicación detallada e interactiva de la arquitectura Transformer.
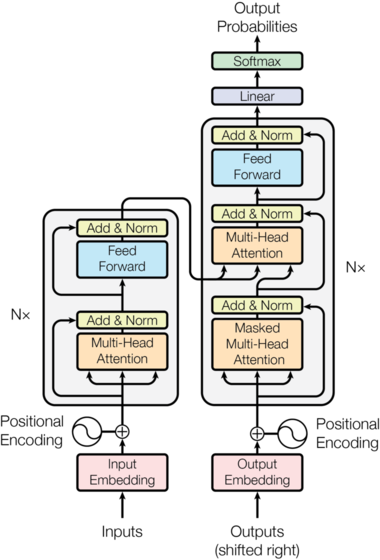
Basada en el notebook "The Annotated Transformer" de Harvard NLP, donde se explica e implementa el paper "Attention Is All You Need".

En primer lugar, nuestro objetivo es entender todas las piezas que componen la arquitectura Transformer. Para ello, vamos a explicar e implementar (de manera autocontenida) cada una de ellas:
- Positional Encoding
- Multi-Head Attention
- Masked Multi-Head Attention
- Feed Forward
- Add & Norm
- Linear
- Softmax
Una vez comprendida la arquitectura Transformer, nuestra intención es, por una parte, tener una serie de notebooks donde las piezas estén explicadas interactivamente y, por otra parte, una documentación en Read the Docs con la explicación de cada pieza, su implementación y enlaces interesantes.
¡Todo el mundo es bienvenido! Si todavía no formas parte de la organización, contacta a @mariagrandury.
Para contribuir al repositorio, primero clónalo y después crea una rama donde añadir tu aportación
(no modifiques main directamente).
Para facilitar la distribución de las tareas y poder visualizar el avance del proyecto, este repositorio está asociado a un tablero. Además tenemos un stand-up semanal los lunes a las 18h45 (15min) seguido de un debate abierto a toda la comunidad sobre papers relacionados con la arquitectura.
Para cada pieza de la arquitectura hay 4 tipos de issues:
- entender: compartir en los comentarios enlaces, papers relacionados con la pieza y discutir su implementación
- explicar: una vez entendido el funcionamiento de la pieza, crear un notebook donde explicarlo interactivamente
- implementar: implementar la pieza en un .py utilizando PyTorch o TensorFlow (implementación autocontenida)
- documentar: crear una sección en la documentación de Sphinx destinada a explicar la pieza utilizando todo lo aprendido en los issues anteriores
Para contribuir:
- Elige un issue en la columna "To Do" que todavía no esté asignado a nadie
- Crea una rama llamada
<pieza>/<tipo_issue>(e.g.positional_encoding/implementacion) - Abre una Pull Request cuando hayas terminado y añade un link al issue correspondiente (menú de la izquierda > "linked issues")
- Espera a que otro contribuyente revise tu aportación
- Listo, ¡gracias!