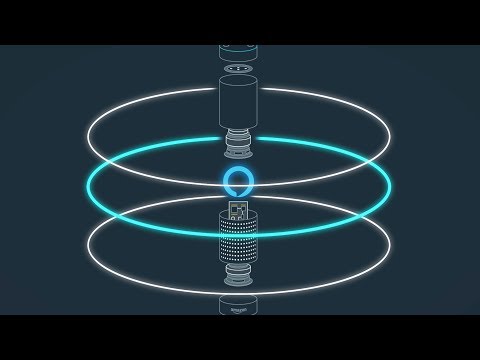
libalexavirtualization contains the Alexa Virtualization feature enabling multiple connected smart displays with mic and speaker to simultaneously access Alexa as unique Alexa devices and receive audio responses and music/content with complementary visuals.
This proof-of-concept prototype application demonstrates using FT900 microcontroller (MCU) as an Amazon Echo Dot device, where users can issue voice commands to Alexa and hear Alexa’s voice responses generated by Alexa’s complex Automatic Speech Recognition, Natural Language Processing and Text to Speech (Speech Synthesis) in the cloud.
To make Alexa on FT900 MCU possible, FT900 (Alexa client) communicates with a Raspberry PI 3B/3B+ (Alexa gateway), which relays voice requests and voice responses to and from the Alexa cloud. The RPI which runs a customized version of Amazon’s official open-source Alexa Voice Service (AVS) SDK, allows multiple FT900 MCUs to simultaneously access Alexa using single or multiple Amazon accounts.




This demo is targeted for FTDI/Bridgetek’s existing smart home devices, PanL Hub and PanL Display. Having Alexa built-in to PanL Smart Home allow customers to talk directly to Alexa via PanL without needing to buy Amazon Echo devices. Customers will have access to the built in capabilities of Alexa (like ask informations, play music/live news/audio book and set timers/alarms/notifications) including access to third-party skills (such as control smart home devices).
PanL Hub, which runs on RPI, acts as the Alexa Hub/Gateway while the PanL Display Controller, which runs on FT900 microcontroller, acts as the Alexa Client. Many PanL Displays can be connected to a PanL Hub at the same time. Customers will be able to use the PanL Hub and any of the connected PanL Display as an Amazon Echo Dot device.
The source codes are available at https://github.com/richmondu/FT900
-
FT900 Alexa Client - main documentation is here
Below is a block diagram showing the implemented components of the FT900 application.

- SD Card should be replaced with SPI Flash or I2C EEPROM on PanL display.
- Ethernet/WiFi should be replaced with RS485 MSTP on PanL display.
- Using WiFi is optional but requires ESP32 WiFi add-on module.
- Button is implemented as GPIO and UART. User can choose between the two.
- RTC library is used to measure time elapsed for performance measurement.
Below is a sequence diagram showing the basic interaction of components of the FT900 application.

- UART/GPIO interrupt service routine triggers Commander and Streamer task
- Commander task records and sends audio request data
- Streamer task receives and play audio data (response or audio content)
FT900 utilizes RPI server to access Alexa. RPI provides separate Alexa instance to each connected FT900 device as if each FT900 is an Echo Dot device, that is each FT900 is not dependent on other FT900s in terms of Alexa usage. Moreover, each FT900 can be configured to use different Amazon accounts.
Most of the audio processing is performed by RPI. The FT900 simply enables voice capture and audio playback.
The main component of the Alexa Demo on the FT900 side is the Alexa AVS library. I created the library to be reusable (for PanL Display) and easy to use (abstract the audio, the SD card and the network communication). SD Card should be replaced with SPI Flash or I2C EEPROM. The main functions include:
1. avs_connect() - Establishes connection with RPI and sends device information (device id, send capabalities, recv capabilities)
2. avs_disconnect() - Closes connection with RPI
3. avs_record_request() - Record voice request from microphone and save to SD card
4. avs_send_request() - Read voice request from SD card and send to RPI
5. avs_receive_response() - Receive voice response from RPI and save to SD card
6. avs_play_response() - Play voice response from SD card
7. avs_recv_and_play_response() - Receive and play voice response from RPI without saving to SD card (faster performance)
8. avs_recv_and_play_response_threaded() - Receive and play voice response from RPI in separate threads using overlapping io.
9. avs_set_volume(), avs_get_volume()
10. avs_init(), avs_free()
As you can see, there are three ways to process Alexa response. The first is the basic implementation while the 2nd and 3rd improves user experience by reducing delay or the waiting time to hear Alexa's response.
1. Receive and play response by completely receiving all data and save to memory before starting to play it.
2. Receive and play response immediately segment by segment.
3. Receive and play response in separate threads by utilizing some overlapped memory.
Device information is sent during avs_connect() function. This registers
1. device identification number
2. send audio device capabilities
3. recv audio device capabilities.
Sending device capabilities are useful for RPI to simultaneously support different MCU clients that may have different audio capabilities. Device capabilities include:
1. audio format (RAW, MP3, WAV, AAC, etc)
2. audio bit depth (8-bit, 16-bit, 24-bit, etc)
3. audio bit rate (16000 hz, 32000 hz, 44100 hz, 48000 hz, etc)
4. audio channel (mono, stereo)
FT900 captures audio in raw PCM 16-bit 16 kHz stereo (2 channel) format.
avs_record_request()
- Audio recorded (from mic): 16-bit PCM, 16KHZ, stereo (2-channels)
- Audio saved (to SD card): 16-bit PCM, 16KHZ, mono (1-channel)
avs_send_request()
- Audio read (from SD card): 16-bit PCM, 16KHZ, mono (1-channel)
- Audio sent (to RPI): 8-bit u-law, 16KHZ, mono (1-channel)
FT900 plays audio in raw PCM 16-bit 16 kHz stereo (2 channel) format.
avs_recv_response()
- Audio received (from RPI): 8-bit u-law, 16KHZ, mono (1-channel)
- Audio saved (to SD card): 16-bit PCM, 16KHZ, mono (1-channel)
avs_play_response()
- Audio read (from SD card): 16-bit PCM, 16KHZ, mono (1-channel)
- Audio played (to speaker): 16-bit PCM, 16KHZ, stereo (2-channels)
avs_recv_and_play_response()
- Audio received (from RPI): 8-bit u-law, 16KHZ, mono (1-channel)
- Audio played (to speaker): 16-bit PCM, 16KHZ, stereo (2-channels)
avs_recv_and_play_response_threaded()
- Audio received (from RPI): 8-bit u-law, 16KHZ, mono (1-channel)
- Audio played (to speaker): 16-bit PCM, 16KHZ, stereo (2-channels)
FT900 compresses audio sent to RPI and decompresses/expands audio received from RPI. This reduces the data bandwidth without affecting audio quality.
- G711 u-law lossless companding (compression/expanding) algorithm is used to convert data stream from 16-bit to 8-bit and vice versa.
- Converting stereo data stream to mono data stream is done by averaging the consecutive left and right 16-bits WORDS.
The format of audio received by FT900 from RPI is raw/PCM format. RPI performs the decoding to raw/PCM from MP3, AAC or other formats.
- TODO: Investigate if FT900 can do the MP3/AAC decoding. Utilize libMAD open source MPEG Audio Decoder library.
FT900 sends/receives audio to/from RPI in raw PCM 8-bit 16 kHz mono (1 channel) format.
To communicate with Alexa, FT900 communicates with RPI using Ethernet, WiFi or RS485.
- Ethernet: using LWIP embedded TCP/IP library
- WiFi: using ESP32 WiFi accessed using AT commands over UART
- RS485 MSTP: TODO
The audio hardware chip for the FT900 RevC evaluation board is a Wolfson WM. I2C is used to configure the settings while I2S is used to capture and play audio.
- The I2S Master Example 1 and 2 shows how to use the codec.
- It only supports 44.1 KHz.
- It does not provide an easy to use reusable interface.
So I had to create an audio module to abstract I2S/I2C details, provide simple to use audio interface and support 32 KHz and 16 KHz. As well as several other features, including volume control, channel conversion, 8-bit compression and etc.
The FT900 application provides option to choose from any pre-recorded audio for testing convenience.
A Python script application named FT900 Alexa Simulator is also provided to simulate the behavior of FT900 on a Windows machine.
These tester and simulator can be a very useful tool as you don't have to speak to the microphone everytime.

The FT900 application currently does not support Wakeword detection. To trigger FT900 to start recording voice, user has to press down a button. To stop recording, user has to release the button. This works similar to the remote control for Amazon's Firestick TV.
The demo provides two ways to trigger voice recording:
- UART Mode: Press 'r' key on UART terminal
- GPIO Mode: Press hardware button connected to GPIO 31
To support Wakeword detection feature on FT900, external MCUs can be integrated as slave devices to handle wakeword detection. SparkFun's board is an example board that can be used for wakeword detection.
The FT900 application uses Ethernet connection to communicate with the RPI server. It can be configured to use WiFi connection by defining COMMUNICATION_IO==2. Using WiFi requires adding an ESP32 WiFi development board as a slave module. FT900 communicates with the ESP32 WiFi via AT commands and UART interface.
1. COMMUNICATION_IO==1 : Ethernet
2. COMMUNICATION_IO==2 : WiFi
3. COMMUNICATION_IO==3 : RS485
Below is how to connect the ESP32 WiFi development board to FT900.
ESP32 GPIO15 (UART1 CTS) - FT900 CN3 3 (UART1 RTS) // Red wire
ESP32 GPIO17 (UART1 TXD) - FT900 CN3 7 (UART1 RXD) // Orange wire
ESP32 GPIO16 (UART1 RXD) - FT900 CN3 9 (UART1 TXD) // Yellow wire
ESP32 GPIO14 (UART1 RTS) - FT900 CN3 11(UART1 CTS) // Green wire
Performance using WiFi connection is currently slow resulting to jittery audio playback. This is either caused by UART bandwidth or UART ringbuffer implementation.
Amazon provides an official Alexa Voice Service (AVS) SDK, (written in C++). The version supported is v1.12.1 AVS SDK. Instructions to install the AVS SDK on RPI can also be found on the github link.
Below is a system diagram of AVS SDK.

Below is a block diagram showing the implemented components of the RPI application.


Below is a sequence diagram showing the basic interaction of components of the RPI application.

- Note that this diagram is only applicable for Dialogue responses.
- For Contents (music, live news, audio book) and Alerts (alarms, timers), MediaPlayer is hooked instead of SpeechSynthesizer.
1. A ConnectionHandler thread is initialized in the main function of the AVS SDK SampleApplication.
2. The ConnectionHandler thread waits for an FT900 connection.
3. Once an FT900 connected, a ClientHandler thread is created.
4. The ClientHandler thread initializes two worker threads, FT900RequestHandler and FT900ResponseHandler.
5. FT900RequestHandler handles the processing of Alexa requests from FT900.
6. FT900ResponseHandler handles the processing of Alexa responses to FT900.
7. Multiple FT900s can connect at a time.
8. FT900RequestHandler receives Alexa request (8-bit compressed using ulaw algorithm) from FT900 and saves it to a file.
9. FT900RequestHandler queues the file for FT900RequestManager.
10. FT900RequestManager dequeues the file.
11. FT900RequestManager decompresses/expands the Alexa request from 8-bit to 16-bit.
12. FT900RequestManager copies the data stream to the microphone input data buffer in PortAudioMicrophoneWrapper.
13. The Alexa request is then sent to the cloud and receives the Alexa response which is in MP3 format.
14. SpeechSynthesizer copies the data stream to an MP3 file.
15. SpeechSynthesizer converts the Alexa response from MP3 format to raw PCM format in a separate thread.
16. SpeechSynthesizer does not play the response since the request is from FT900.
17. FT900ResponseHandler compresses the Alexa response to 8-bit from 16-bit.
18. FT900ResponseHandler sends the Alexa response (8-bit compressed using ulaw algorithm) to FT900.
19. The FT900ClientHandler thread waits until FT900RequestHandler and FT90ResponseHandler terminates.
20. The FT900ClientHandler thread closes the socket once FT900RequestHandler and FT900ResponseHandler threads terminate.
AVS SDK supports 3 major capabilities: Dialogs, Alerts and Contents.
1. Dialogs - for dialog/speech/user-interaction directives (SpeechSynthesizer)
2. Alerts - for timer/alarm directives (Alerts)
3. Contents - for content/music directives (AudioPlayer)
Previously, only #1 is working on FT900 since I've only hooked into SpeechSynthesizer class of AVS SDK. That is, if you command FT900 to set an alert or play music, the alarm and music is played on RPI, not on FT900.
To support #2 and #3 on FT900, I hooked into the MediaPlayer class of AVS SDK in RPI. So now, if music is playing in FT900 and then some alerts arrive or user speaks in microphone, then music will be paused to give way for those 2.
Three main differences on the new approach:
1. I'm now hooking on the lower stack of AVS SDK.
By doing this, I'm able to hook all - Dialogs, Alerts and Contents.
Previously, I was hooking into Speech Synthesizer which is up in the stack.
2. I'm now decoding MP3 to RAW chunk by chunk.
Previously for Dialogs, I save dialog responses completely before decoding as a file.
This method is not possible with Alerts and Contents, which are streamed, so size cannot be pre-determined.
3. Connection to RPI is now persistent.
Previously, connection to RPI was only established when requests are sent.
This method is no longer possible as Alerts are not active and Contents are long.
Below is an experiment that demonstrates the prioritization of Alexa on dialogues responses, alarms and audio content.

1. REQUEST_play_music.raw
I asked Alexa to play music on TuneIn Radio. Music plays.
2. REQUEST_what_time_is_it.raw
While music is playing, I asked Alexa what time is it?
Music turned off. Alexa replies. Music turned back on.
3. REQUEST_set_alarm.raw
While music is playing, I asked Alexa to set alarm in 10 seconds.
Music turned off. Alexa replies. Music turned back on.
After 10 seconds, music turned off. Alarms starts running.
4. REQUEST_what_time_is_it.raw
While alarm is running, I asked Alexa what time is it?
Alarm turned off. Alexa replies. Alarm turned back on.
5. REQUEST_stop.raw
While alarm is running, I asked Alexa to stop alarm.
Alarm turned off. Music turned back on.
6. REQUEST_stop.raw
While music is playing, I asked Alexa to stop music.
Music turned off.
Various audio content are now working on FT900 MCU: music radio, live news and audio books.
1. music radio - TuneIn: OK
2. live news - FoxNews: OK
3. audio book - Audible: OK
To support audio book playback, I had to replace libsox with ffmpeg as libsox does NOT support AAC audio format.
[UPDATE] GStreamer is now used to decode the data instead of FFMPEG. That is, raw decoded data is now being hook beneath the GStreamer pipeline so FFMPEG is no longer used.
Access to other audio services are restricted by Amazon on AVS-SDK. Need to request access to test Spotify, Amazon Music, etc.

In addition to the new modules implemented described in the block diagram and sequence diagram, the primary modifications for the AVS SDK application are contained in PortAudioMicrophoneWrapper class, SpeechSynthesizer class and MediaPlayer classes.
- PortAudioMicrophoneWrapper: PortAudioCallback() contains the data stream for Alexa request
- SpeechSynthesizer: startPlaying() contains the data stream for Dialog (speech response)
- MediaPlayer: contains the data stream for all audio content including Contents and Alerts
Below is a list of files modified:
- SampleApplication.cpp: To initialize FT900ConnectionHandler in separate thread.
- PortAudioMicrophoneWrapper.cpp: To feed in request data to microphone datastream.
- SpeechSynthesizer.cpp: To hook speech/dialogue response.
- MediaPlayer.cpp: To fix audiosink issue.
- IStreamSource.cpp, AttachmentReaderSource.cpp, BaseStreamSource.cpp: to hook contents (music, live news, audio book) and alerts (alarms, timers)
- DefaultClient.h: To provide access to Speech Synthesizer handle.
- UIManager.h: To access connection status and dialog state.
- UserInputManager.cpp: To test pre-recorded audio requests.
Below is a list of files created:
- FT900ConnectionHandler.cpp
- FT900ClientHandler.cpp
- FT900RequestHandler.cpp
- FT900RequestHook.cpp
- FT900RequestManager.cpp
- FT900ResponseHandler.cpp
- FT900ResponseHook.cpp
- FT900ResponseManager.cpp
- FT900AudioCompression.cpp
- FT900AudioCompressionHelper.cpp
- FT900AudioDecoding.cpp
- FT900AudioRateConversion.cpp
All of new files starts with FT900 to easily distinguish it from original AVS SDK files.
After modifications, the total size of the binary executable is 16.2MB.
Below is a description of how the audio is processed on RPI.
avs_request()
- Audio received (from FT900): 8-bit u-law, 16KHZ, mono (1-channel)
- Audio sent (to Alexa cloud): 16-bit PCM, 16KHZ, mono (1-channel)
avs_response()
- Audio received (from Alexa cloud): MP3
- Audio sent (to FT900): 8-bit u-law, 16KHZ, mono (1-channel)
Notes
- G711 u-law lossless companding (compression/expanding) algorithm is used to convert data stream from 16-bit to 8-bit and vice versa. Compressing the data before transmission reduces the data bandwidth usage by half.

I'm now hooking "RAW decoded" audio data from the GStreamer pipeline. AVS SDK uses GStreamer for audio streaming, decoding and playback.
Previously, I was hooking "MP3/AAC" audio encoded data at the top of the GStreamer pipeline. That is, I was hooking the encoded audio data and then manually decoding it using third-party library FFMPEG that I manually added. At the same time, the GStreamer pipeline is also decoding the audio data for speaker playback. As such, there were 2 "decoding" happening causing intense CPU spikes when running multiple Alexa instances.
Now I am hooking beneath the GStreamer pipeline and so I'm getting the "decoded" data already. So, there is no more FFMPEG or SoX dependency. To do get the decoded data, I modified the GStreamer pipeline to:
1. add tee branch to output decoded data to both audiosink and appsink
2. replace audiosink with fakesink to disable audio playback in RPI
Refer to https://gstreamer.freedesktop.org/documentation/tutorials/basic/short-cutting-the-pipeline.html for an example on how to use "tee" to retrieve output data from a GStreamer pipeline.
Removing the redundant "decoding" also fixes the 50-100% CPU problem occuring when 8 FT900 devices are simultaneously playing music using separate Alexa instances/accounts.
Now, with 8 FT900 devices simulataneously playing music, CPU is now just 40-50%.

Previously, multiple FT900 devices share a single Alexa instance. Each FT900 can send information request to Alexa simultaneously. But each FT900 cannot simultaneously play music or any audio content.
To solve this problem, multiple instances of the Alexa application can be executed. That is each FT900 device is connected to a unique Alexa instance.
To do this, each application instance will:
1. Listen to a different port
2. Use a different Alexa configuration file
3. Use a different database location
I created a Python script named RPIAlexaManager.py that automates the configuration and execution of multiple Alexa application instances.
Below is the mapping of FT900 device id to the RPI Alexa instance.
FT900 device 1 connects to port BASE_PORT+0
FT900 device 2 connects to port BASE_PORT+1
FT900 device X connects to port BASE_PORT+X-1
RPI app instance for account 1 listens to port BASE+0
RPI app instance for account 2 listens to port BASE+1
RPI app instance for account X listens to port BASE+X-1
RPI app instance for account 1 uses configuration 1 and database 1.
RPI app instance for account 2 uses configuration 2 and database 2.
RPI app instance for account X uses configuration X and database X.
RPI Alexa server now sends "display cards" data, including attached images, to clients. Currently tested with the Device Simulator Python application [not yet implemented on FT900 and ESP32].
Display cards can contain 0, 1 or many source image URLs to be used for rendering of Display Cards. RPI Alexa server parses the image URLs from the Display Card data using rapidJSON and then uses libcURL to download the images. The downloaded images is sent to the client as well.
TODO: Update client to display the "display cards" data and images based on the UI template guidelines. Currently, the received data is just printed.
The following questions produces the 5 different Alexa display cards templates.
BodyTemplate1 "One plus one"
BodyTemplate2 "Who is Lebron James?"
ListTemplate1 "What's on my TODO list?"
WeatherTemplate "What is the weather in San Francisco?"
PlayerTemplate "Play Bad Song Radio music from TuneIn"
Alexa Voice Service supports Display Cards for devices with Alexa built-in. The Display Cards feature enables screen-based product to show visual content to complement voice responses from Alexa. There are 5 display card templates Alexa supports:
BodyTemplate1 : text only template, Wikipedia entries without images
: title/mainTitle
: title/subTitle
: textField
BodyTemplate2 : body text and a single image, Wikipedia entries with images.
: title/mainTitle
: title/subTitle
: textField
: image/sources/[size, url]
ListTemplate1 : template for lists and calendar entries, Shopping lists, to do lists, and calendar entries.
: title/mainTitle
: title/subTitle
: listItems/[leftTextField, rightTextField]
WeatherTemplate : template designed to display weather data, Weather information
: title/mainTitle
: title/subTitle
: currentWeather
: currentWeatherIcon/sources/[size, widthPixels, heightPixels, url, darkBackgroundUrl]
: highTemperature/value
: highTemperature/arrow/sources/[size, widthPixels, heightPixels, url, darkBackgroundUrl]
: lowTemperature/value
: lowTemperature/arrow/sources/[size, widthPixels, heightPixels, url, darkBackgroundUrl]
: weatherForecast/[day, highTemperature, lowTemperature,
image/sources/[size, widthPixels, heightPixels, url, darkBackgroundUrl]]
PlayerTemplate : RenderPlayerInfo directive, "Now Playing" template for music.
: content/title
: content/titleSubtext1
: content/titleSubtext2
: content/provider/name
: content/provider/logo/sources/[url]
: content/art/sources/[size, url]
: controls/[name, type, enabled, selected]
Refer to https://developer.amazon.com/docs/alexa-voice-service/display-cards-tablets.html for more information about Display Cards.
Below are the major performance optimization efforts implemented for the demo.
1. 8-bit ulaw audio compression
- audio is compressed from 16-bit to 8-bit using G711 ulaw lossless algorithm before transmitting to FT900 or RPI.
2. 16khz audio sampling rate
- sample i2s master applications only support 44.1khz and 48khz. size of 48khz is 3 times as much as 16khz.
3. receive and play Alexa response without saving to SD card
- this improved FT900-RPI-AVS-RPI-FT900 round trip from 6-7 seconds to 4 seconds.
- audio quality did not degrade because FIFO size of i2s master is maximized
4. disable playback of response on RPI when request is from FT900
- RPI should only play response when the request is from RPI microphone.
One round trip of Alexa request and Alexa response on the RPI side (RPI-AVS-RPI) is about 3.2 seconds (now optimized to 2.6 seconds). This is for a simple command, "What time is it?". This measures the time RPI accepts FT900 connection until it closes the connection.

Note that the logs correspond to the sequence diagram above.
One round trip of Alexa request and Alexa response on the FT900 side (FT900-RPI-AVS-RPI-FT900) is 5-6 seconds. This has been optimized from 6-7 seconds. This measurement is for a simple command, "What time is it?". This measures the time FT900 sends the Alexa request to RPI until it finishes playing Alexa response. It takes 4.0 seconds to wait and receive the Alexa response. On RPI side, this is 3.2 seconds so it means FT900 consumes 0.8 second processing overhead.

Since the delay is in the processing of Alexa response, one alternative solution is to play the audio stream directly to the speaker without saving it to the SD card. By doing this, performance on the FT900 side (FT900-RPI-AVS-RPI-FT900) has been optimized to 4-5 seconds. This is a major performance improvement. And audio quality is actually very good. Audio quality did not degrade or cause jittering.

Below are the three modes supported for processing Alexa responses.
1. recv and play by completely saving response to sd card before playing
- good. (performance 7seconds)
#define USE_RECVPLAY_RESPONSE 0
2. recv and play directly without saving to SD card
- good and faster. default (performance 4seconds)
#define USE_RECVPLAY_RESPONSE 1
3. recv and play in separate threads
- new; not so good (performance 5-6seconds)
#define USE_RECVPLAYTHREADED_RESPONSE 1
Playback of Alexa response on connected speaker is very very good. There is no noise or jittering. It is very smooth.
This was made possible by maximizing the FIFO buffer sizes for both SD Host (4KB) and I2S Master (2KB). 4KB data is read from SD card then segmented into 4 1KBs. Each 1KB data is converted from mono (1-channel) to stereo (2-channels). This results to 2KB stereo data which is then written to I2S Master speaker. The process is repeated until the recorded audio file is completely processed.
When streaming the Alexa response directly to the speaker without saving to SD card, 512 bytes is received from RPI, then expanded from 8-bit to 16-bit (1KB), then converted mono to stereo (2KB). This is an efficient transfer because I2S Master FIFO size is only 2KB.
Recording of Alexa request on FT900 microphone is good. Background noise can be heard but voice pops out when user speaks very near to microphone.
The demo currently uses Ethernet for communication between RPI and FT900. For PanL, where communication medium is RS485, bandwidth is smaller, about 92KBps only. This is one of the major concerns for adoption of the solution to PanL Smart Home Solution. Below is an analysis that answers this concern.
The size of an 8-bit 16khz response for a simple question "What time is it?" is less than 32kb. This is sent in 2ms. 30720bytes *1000/2ms=15360000 (14.6 MBps)
To simulate RS485 slowness, I added delay between each send (note that 32kb is sent in chunks as it is compressed in chunks). Results:
1) 20ms delay => response is sent in about 1sec instead of 2ms. (32k bytes/sec) *causes stutter
2) 13ms delay => response is sent in about 660ms instead of 2ms. (48k bytes/sec)
3) 10ms delay => response is sent in about 500ms instead of 2ms. (64k bytes/sec)
4) 6ms delay => response is sent in about 330ms instead of 2ms. (96k bytes/sec)
The 20ms added delay sometimes causes a stutter for recv_and_play_no_sdcard option as sender becomes slow. Meaning, using SD card to save response is necessary when sender rate is around 32KBps only.
But since the acceptable computed rate for RS485 is 64KBps (70% of 92KBps), then not using SD card to save response is still OK. If we use SD card to save response, then RS485 is not a even problem.
Note that the demo solution provides both options to save or not to save response to SD card. (Saving response to SD card is 1-2 seconds slower than NOT saving response to SD card.)
Another concern is the CPU usage consumed by the application on RPI.
Based on observation, the CPU usage jumps to 20-30% for a split second when processing a request. This is OK. Note that no AI is done on the RPI. The Alexa SDK only forwards the request on the cloud where the AI-generated response is created. So the Alexa application on RPI does NOT and can NOT hog the CPU.
A. RPI
1. RPI 3B or RPI 3B+ (Both tested)
2. (Optional) Headphone or speaker
3. (Optional) USB microphone https://circuit.rocks/usb-mini-microphone.html
B. FT900
1. FT900 Rev C board (mm900ev1b)
2. SD card (class-6 or 10, ush-1, <= 32gb) https://www.lazada.com.ph/-i7948043-s10125616.html?urlFlag=true&mp=1
3. Headphone or speaker
4. (Optional) Button https://circuit.rocks/button-digital (for GPIO mode)
Note you can issue voice commands to either RPI or FT900.
Download the latest RPI Alexa Gateway code.
A. Install AVS SDK (latest version is AVS SDK 1.12.1 [04-02-2019])
1. Install the original AVS SDK on RPI using the official installation guide on RPI.
https://github.com/alexa/avs-device-sdk/wiki/Raspberry-Pi-Quick-Start-Guide-with-Script
2. Run and verify everything is working as expected.
Note: Say 'Alexa' to trigger voice recording. Alternatively, press 't' key followed by Enter key to trigger recording.
First run requires authorization. Go to https://amazon.com/us/code and type the code displayed in the logs.
B. Integrate AVS SDK modifications (supports AVS SDK 1.12.1 [04-02-2019])
1. The RPI Alexa Gateway is a customized AVS SDK.
Replace the original avs-device-sdk folder with this modified avs-device-sdk.
2. [OBSOLETED] Install FFMPEG or SOX utility
sudo apt-get install ffmpeg
sudo apt-get install sox libsox-fmt-mp3 libsox-fmt-all libsox-dev
3. Compile and run.
cd /home/..../alexa/build/SampleApp/src
sudo ./SampleApp "/home/.../alexa/build/Integration/AlexaClientSDKConfig.json" "/home/.../alexa/third-party/alexa-rpi/models" INFO
Note: You should see logs containing 'FT900'.
Note: Verify everything is working as expected.
Note: Say 'Alexa' to trigger voice recording. Alternatively, press 't' key followed by Enter key to trigger recording.
4. Setup and run FT900.
Download the latest FT900 Alexa Client code.
1. Change AVS Configuration values in avs_config.h:
AVS_CONFIG_SERVER_ADDR - IP address of the RPI
AVS_CONFIG_DEVICE_ID - Device ID of the FT900; modify if running multiple FT900 clients
AVS_CONFIG_DIFFERENT_ACCOUNT - Flag to indicate if using different Alexa account/instance
2. Copy request1.raw, request2.raw, ..., request8.raw from test folder to SD card.
REQUEST1.RAW - ask current time.
REQUEST2.RAW - play music from TuneIn radio.
REQUEST3.RAW - play live news from Fox News
REQUEST4.RAW - set alarm in 10 seconds.
REQUEST5.RAW - tell stop.
REQUEST6.RAW - tell yes.
REQUEST7.RAW - ask who is Lebron James.
REQUEST8.RAW - play audio book from Audible.
3. Compile and run.
4. Type a key to trigger voice recording or sending of pre-recorded audio
Usage:
Press 'r' to start/stop voice recording.
Press 't' to ask current time.
Press 'p' to ask who is Lebron James.
Press 'm' to play music from TuneIn radio.
Press 'n' to play live news from Fox News.
Press 'b' to play audio book from Audible.
Press 'a' to set alarm in 10 seconds.
Press 's' to tell stop.
Press 'y' to tell yes.
Press 'q' to quit and restart.
Below are the action items for the Alexa Demo.
1. Test and support Alexa notifications using QuoteMaker.
2. Support "ESP32 Alexa Client".
[ongoing, can send/recv data to/from Alexa server already. but no playback and recording yet.]
3. Support "Alexa Display Cards" since FT900 can be connected to a FT800 display.
[ongoing, rpi forwards the display card data to clients already. but need to forward images as well given URLs]
4. Create a fully "Automated Voice Testing" framework.
5. Support "FT900 libMAD MP3 decoder" and provide RPI option to send MP3 instead of PCM/raw.
6. Support "FT900 Wake-Word detection". Currently, user has to press down a button to start voice recording.
7. [BUG] RPI AVS SDK audio playback is disabled. Current code assumes that only FT900 clients can use Alexa.
Below are the essential links to familiarize with Alexa and audio terminologies needed for FT900 Alexa Demo.